常用模块time/datetime/os/sys/json/random/hashlib
1. time 和时间相关的
1. time模块的三大对象
-
时间戳
-
字符串
-
time.time(): 获取时间戳
time.gmtime():获取格式化的时间对象,是由九个字段组成的
time.localtime():获取当地时间对象,是由九个字段组成
time.mktime():时间对象转换成时间戳
time.strftime(format[,t]):把时间对象格式化成字符串
time.strptime(str,format):把时间字符串转换成时间对象
3. 表示时间的三种方式
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串
1. 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.格式化的时间字符串(Format String): ‘1999-12-06’
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(0000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
3.元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
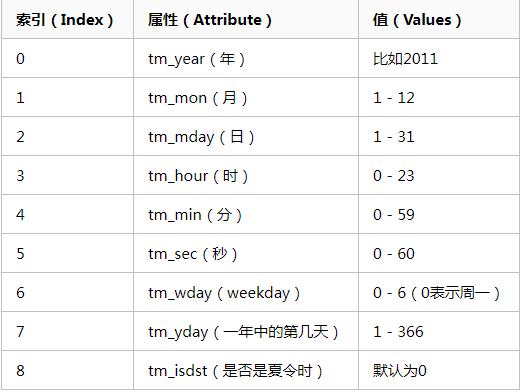
4. 如何获取时间戳(常用方法)
# 时间戳的:从时间元年(1970年1月1日 0。0:00:00到现在经过的秒数) import time print(time.time()) # 1578901840.0911853
5.获取格式化时间对象,是由九个字段组成的(默认参数是当前系统时间的时间戳)
1. time.gmtime() 获取的是格林尼治时间
import time print(time.gmtime()) # time.struct_time(tm_year=2020, tm_mon=1, tm_mday=13, tm_hour=7, tm_min=52, tm_sec=37, tm_wday=0, tm_yday=13, tm_isdst=0)
2. time.localtime() 获取当地的时间对象
print(time.localtime()) # time.struct_time(tm_year=2019, tm_mon=5, tm_mday=20, tm_hour=18, tm_min=15, tm_sec=23, tm_wday=0, tm_yday=140, tm_isdst=0)
3. time.gmtime(1) 时间元年过一秒后,对应的时间对象
print(time.gmtime(1)) # time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=1, tm_wday=3, tm_yday=1, tm_isdst=0)
5.time模块的三大对象转换

# 格式化时间 ----> 结构化时间 ft = time.strftime('%Y/%m/%d %H:%M:%S') st = time.strptime(ft,'%Y/%m/%d %H:%M:%S') print(st) # 结构化时间 ---> 时间戳 t = time.mktime(st) print(t) # 时间戳 ----> 结构化时间 t = time.time() st = time.localtime(t) print(st) # 结构化时间 ---> 格式化时间 ft = time.strftime('%Y/%m/%d %H:%M:%S',st) print(ft)
6.time.sleep(x) 程序暂停x秒(常用方法)
import time for i in range(10): print(i) time.sleep(1)
2. datetime 时间日期相关
1.包含了时间日期相关的类
date: 需要年,月,日三个参数
time: 需要年,月,日三个参数
datetime:需要年,月,日,时,分,秒六个参数
timedelta:需要一个时间段,可以是天,秒,微秒获取数据后,主要用于和时间段进行数学计算
2. date()
import datetime d = datetime.date(2010,10,10) print(d) # 2010-10-10 # 获取年 print(d.year) # 2010 # 获取月 print(d.month) # 10 # 获取日 print(d.day) # 10
3. time()
import datetime t = datetime.time(10,42,52) print(t) # 10:42:52 print(t.hour) # 10 print(t.minute) # 42 print(t.second) # 52
4. datetime()
import datetime dt = datetime.datetime(2010,11,12,11,12,13) print(dt) # 2010-11-12 11:12:13
5. timedelta:时间的变化量
import datetime td = datetime.timedelta(days=1) print(td) # 1 day, 0:00:00 # 时间变化量的计算是会产生进位 t = datetime.datetime(2010,10,10,10,10,00) td = datetime.timedelta(seconds=3) res = t + td print(res) # 2010-10-10 10:10:03
和时间段进行运算的结果 类型:和另一个操作数保持一致
d = datetime.date(2010,10,10) td = datetime.timedelta(days = 1) res = d + td print(type(res)) # <class 'datetime.date'> d = datetime.datetime(2010,10,10,10,10,10) td = datetime.timedelta(days=1) res = d + td print(type(res)) # <class 'datetime.datetime'>
练习题
显示任意一年的二月份有多少天 import datetime # 用datetime模块, year = int(input("请输入年份")) # 首先创建出指定年份的3月份第一天,然后让它往走一天 # 创建指定年份的date对象 d = datetime.date(year,3,1) # 创建一天的时间段 td = datetime.timedelta(days=1) res = d - td print(res.day)
3.os. 与操作系统相关的模块
#当前执行这个python文件的工作目录相关的工作路径 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') #和文件夹相关 os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 # 和文件相关 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 # 和操作系统差异相关 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' # 和执行系统命令相关 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.environ 获取系统环境变量 #path系列,和路径相关 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
os模块的详情介绍:https://www.runoob.com/python3/python3-os-file-methods.html
4. sys
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 *** sys.platform 返回操作系统平台名称
5. random 随机
1.random.random():获取[0.0,1.0]范围的随机浮点数
import random
print(random.random())
# 0.9393633860440838
2.random.uniform(a,b):获取[a,b)范围内的浮点数
import random
print(random.uniform(1, 10)) # 7.295525731978065
3.random.randint(a,b): 获取[a,b]范围内的一个整数
import random
print(random.randint(1,10)) # 10
print(random.randint(10)) # TypeError: randint() missing 1 required positional argument: 'b' # 翻译过来:缺少一个必需的位置参数:'b'
4. random.randrange(stop) :从指定范围内,按指定基数递增的集合中 获取一个随机数
import random
print(random.randrange(4)) #返回0~3的随机整数 # 1 print(random.randrange(1, 9)) #返回1~8的随机整数 # 8 print(random.randrange(1, 11, 2)) #返回1~10的随机奇数 # 3
5. random.shuffle(x):把参数指定的数据中的元素打乱,参数必须是一个可变的数据类型。
import random p = ['A' , 'B', 'C', 'D', 'E' ] random.shuffle(p) print (p) # ['B', 'D', 'A', 'C', 'E']
6.random.sample(x,k):从x中随机抽取k个数据,组成一个列表返回。
import random alist = [1, 2, 3, 4, 5, 6, 7, 8, 9] print(random.sample(alist, 5)) # [3, 1, 9, 8, 7] aset = {1, 2, 3, 4, 5, 6, 7} print(random.sample(aset, 6)) # [6, 3, 4, 1, 2, 7]
7.random.choice(seq):从非空序列中返回一个随机元素
import random print(random.choice("dfghjkldfghjk125") # k print(random.choice(['相恋', '沦陷', '遥远'])) #返回列表中一个随机一个元素 # 遥远 print(random.choice(('手掌心', '北极星', '红尘'))) #返回元组中一个随机元素 # 北极星 print(random.choice()) # TypeError: choice() missing 1 required positional argument: 'seq' # 翻译过来就是:缺少1个必需的位置参数:'seq'
6.json 模块
1. 序列化与反序列化的概念:
-
序列化:将其他数据格式转换成json字符串的过程
-
反序列化:将特殊的序列转换原来的数据结构

2.序列化的目的:
-
以某种存储形式是自定义对象持久化
-
将对象从一个地方传递到另一个地方
-
3.Python可序列化的数据类型

4. json模块的相关方法
# dumps loads 主要用于网络传输,但是也可以读写文件 import json dic = {'username': '小白', 'password': 123,'status': True} st = json.dumps(dic,ensure_ascii=False) print(st,type(st)) # {"username": "小白", "password": 123, "status": true} <class 'str'> # 反转回去 dic1 = json.loads(st) print(dic1,type(dic1)) # {'username': '小白', 'password': 123, 'status': True} <class 'dict'> # 写入文件 l1 = [1, 2, 3, {'name': 'cainiao'}] # 转换成特殊的字符串写入文件 with open("json文件",encoding="utf-8",mode ="w") as f: st = json.dumps(l1) f.write(st) # 读出来还原回去 with open("json文件",encoding="utf-8",mode ="r") as f: ret = f.read() l1 = json.loads(ret) print(l1,type(l1)) # [1, 2, 3, {'name': 'cainiao'}] <class 'list'> l1 = [1, 2, 3, {'name': 'cainiao'}] # dump load 只能写入文件,只能写入一个数据结构 with open('json文件1',encoding='utf-8',mode='w') as f1: json.dump(l1,f1) # 读取数据 with open('json文件1',encoding='utf-8') as f2: l1 = json.load(f2) print(l1,type(l1)) # 一次写入文件多个数据怎么做? dic1 = {'username': 'cainiao'} dic2 = {'username': '小白'} dic3 = {'username': '小黑'} with open('json文件1',encoding='utf-8',mode='w') as f1: f1.write(json.dumps(dic1) + '\n') f1.write(json.dumps(dic2) + '\n') f1.write(json.dumps(dic3) + '\n') with open('json文件1',encoding='utf-8') as f1: for i in f1: print(json.loads(i))
7. pickle 模块
只能是Python语言遵循的一种数据转化格式,只能在python语言中使用。
支持Python所有的数据类型包括实例化对象。
l1 = [1,2,3,{"name":"cainiao"}]
dumps loads 只能用于网络传输
import pickle
st = pickle.dumps(l1)
print(st) #bytes
l2 = pickle.loads(st)
print(l2,type(l2))
dump load 直接写入文件
import pickle
dic1 = {"name":"cainiao"}
8.hashlib 模块
包含很多的加密算法,MD5,和sha系列,sha1 ,sha256,sha512,,,
1. 应用场景:
1. 数据加密
2. 文件的校验
2.数据加密的三大步骤
-
获取一个加密对象
-
使用加密对象的update,进行加密,update方法可以调用多次
-
通常通过hexdigest获取加密结果,或digest()方法.
3.数据加密的特点
-
把一个大的数据,切分成不同的块,分别对不同的块进行加密,在汇总的结果,和直接对整体数据加密的结果是一致的
-
-
原始数据的一点小的变化,将导致结果非常大的差异,也称"雪崩效应"
4. 普通加密
import hashlib # 获取一个加密对象 m = hashlib.md5() # 使用加密对象的update进行加密 m.update('abc中文'.encode('utf-8')) # 通过hexdigest 获取加密结果 res = m.hexdigest() print(res, len(res)) # 1af98e0571f7a24468a85f91b908d335 32 # 也可以通过digest()方法.获取加密结果 res = m.digest() print(res) # b'\x1a\xf9\x8e\x05q\xf7\xa2Dh\xa8_\x91\xb9\x08\xd35'
5. 加盐加密
import hashlib # 获取一个加密对象,可以指定参数,称之为salt。 m = hashlib.md5("小白".encode("utf-8")) # 使用加密对象的update进行加密 m.update('abc中文'.encode('utf-8')) # 通过hexdigest 获取加密结果 res = m.hexdigest() print(res, len(res)) # 62648f6ff8cfddb31b9064fbd9d0568d 32 # 也可以通过digest()方法.获取加密结果 res = m.digest() print(res) # b'bd\x8fo\xf8\xcf\xdd\xb3\x1b\x90d\xfb\xd9\xd0V\x8d'
动态的加盐
import hashlib m = hashlib.md5("为此江湖少年狂"[::2].encode("utf-8")) m.update('abc中文'.encode('utf-8')) res = m.hexdigest() print(res, len(res)) # d80c5be4c4a26db54d02e32c7595de2d 32 res = m.digest() print(res) # b'\xd8\x0c[\xe4\xc4\xa2m\xb5M\x02\xe3,u\x95\xde-'
# 注册与登陆加密简单练习 import hashlib def get_md5(username, password): """ 加密 :return: """ m = hashlib.md5() m.update(username.encode("utf-8")) m.update(password.encode("utf-8")) return m.hexdigest() def login(username, password): """ 登录; :param username: :param password: :return: """ res = get_md5(username, password) with open("a.txt", mode="r", encoding="utf-8") as f: for i in f: if res == i.strip(): return True else: return False def register(username, password): """ 注册 :param username: :param password: :return: """ res = get_md5(username, password) with open("a.txt", mode="a", encoding="utf-8") as f: f.write(res + "\n") while True: print("1:注册,2:登录,3:退出") num = int(input("请输入序号")) if num == 3: break elif num == 1: username = input("请输入用户名:").strip() password = input("请输入密码").strip() register(username, password) elif num == 2: username = input("请输入用户名:").strip() password = input("请输入密码").strip() res = login(username, password) if res: print("登录成功") else: print("登录失败")
实例二:文件校验
# low版 def hashlib_sha256(path): ret = hashlib.sha256() with open(path,mode="rb") as f: ret.update(f.read()) return ret.hexdigest() result = hashlib_sha256("pycharm-professional-2019.1.2.exe") print(result) # 6217ce726fc8ccd48ec76e9f92d15feecd20422c30367c6dc8c222ab352a3ec6 # 进阶版 import hashlib def hashlib_sha256(path): ret = hashlib.sha256() with open(path,mode="rb") as f: while 1: content = f.read(1024) if content: ret.update(content) else: return ret.hexdigest() result = hashlib_sha256("pycharm-professional-2019.1.2.exe") print(result) # 6217ce726fc8ccd48ec76e9f92d15feecd20422c30367c6dc8c222ab352a3ec6

 ヾ(≧O≦)〃嗷~
ヾ(≧O≦)〃嗷~