模块的初始
1.模块是什么?
-
举例 :抖音20万行代码全部放在一个py文件中?
-
为什么不行?
-
代码太多,读取代码耗时太长
-
-
-
所以如何去做?
-
一个py文件拆分成100个文件,
-
-
-
模块就是一个py文件,常用的相似的功能集合。
2.为什么要有模块?
-
拿来主义,提高开发效率
-
便于管理维护,
-
-
脚本就是py文件,长期保存代码的文件
3. 模块的分类
-
-
python解释器自带的模块有200种左右,time,os,sys,hashlib等等
-
-
第三方模块
-
pip install需要这个指令安装的模块
-
-
自定义模块
-
自己写的一个py文件
-
4. import的使用
1. import 模块先要怎么样?
第一次引用tbjx这个模块,会将这个模块里面的所有代码加载到内存,只要你的程序没有结束,接下来你在引用多少次,它会先从内存中寻找有没有此模块,如果已经加载到内存,就不在重复加载.
2.第一次导入模块执行三件事
-
-
第二:执行此tbjx空间所有的可执行代码(将模块中的所有的的变量与值的对应关系加载到这个名称空间)
-
第三:通过此模块名+.的方式引用该模块里面的内容。
3. 重复导入会直接引用内存中已经加载好的结果
# 模块a中的代码 print("123456") name = "太白" def func(): print("in func") def func1(): pass import a import a import a # 输出结果 # 123456
4. 被导入模块有独立的名称空间
实例一
# 模块名a中内容 print("123456") name = "小白" def func(): print("in func") def func1(): print("145") def index(): global name name = "xiaohei" print(name) # 导入模块a import a name = "barry" print(a.name) a.index() print(a.name) print(name) # 输出结果 # 小白 # 小黑 # barry
实例二
# 模块a中的代码 name = '太上老君' def read1(): print('tbjx模块:', name) def read2(): print('tbjx模块') read1() def change(): global name name = 'barry' import a def read1(): print(666) a.read1() # tbjx模块: 太上老君
分析思路;

实例三
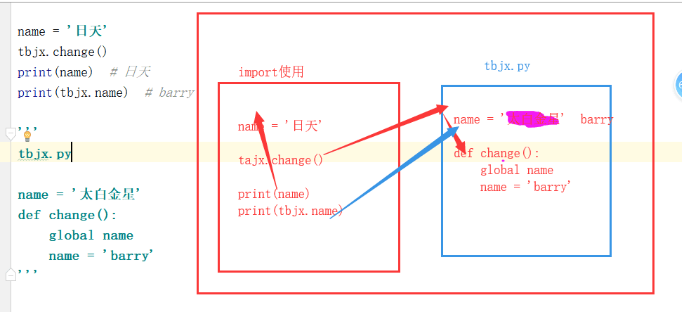
# 模块a中的代码 name = '太白金星' def read1(): print('tbjx模块:', name) def read2(): print('tbjx模块') read1() def change(): global name name = 'barry' import a name = "日天" a.change() print(name) # 日天 print(a.name) # barry
分析思路
5. 为模块起别名
1.简单,便捷
import asasdfgh as as print(as.name)
2.有利于代码的简化
# 对具有相似功能的模块,进行调用时,可以用为模块起别名的方法 # 原始写法 result = input("请输入") if result == "mysql": import mysql2 mysql2.mysql() elif result == "oracle" import oracle2 oracle2.oracle() # 起别名的写法 result = input("请输入") if result == "mysql": import mysql2 as sm elif result == "oracle" import oracle2 as sm sm.db()
# 统一接口,归一化思想
6.导入多个模块
import time,os,sys # 不建议这种写法,不规范 # 导入多个模块,应该使用一下这些方法 import time import os import sys
5. from ... import ...
1.from ... import ... 的使用
from a import name from a import read1 from a import read2 print(name) print(globals) read1()
2. from ...import ...与import对比
#唯一的区别就是:使用from...import...则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了、无需加前缀:tbjx. #from...import...的方式有好处也有坏处 好处:使用起来方便了 坏处:容易与当前执行文件中的名字冲突
3. 一行导入多个模块
from a import name,read1,read2 # 不建议这样写,不符合规范 from a import name from a import read1
4 from ...import * 导入所有的模块中的所有方法
使用from ... import * 导入模块中所有的方法,使用__all__ 就会把模块中自己想要使用的模块中的方法导入, from a import * __all__ = ['name',"read1"] # 配合*使用 # 就只会导入模块中的name,read1的方法
# 模块a中的内容 name = '太上老君' def read1(): print('tbjx模块:', name) def read2(): print('tbjx模块') def change(): global name name = 'barry' print(name) print(__name__) # 打印模块的名字 #当a.py做脚本:__name == __main__ 返回True # 当a.py做模块被别人引用是:__name__ == a # __name__根据文件的扮演的角色(脚本,模块) 不同而得到不同的结果 1.模块需要调试时,加上 if __name__ =="main": import a # 测试代码 if __name__ == "__main__": a() 2.作为项目的启动文件需要用。
5. 模块的搜索路径
-
-
模块的查找顺序
-
第一次导入某个as模块时,会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用(ps:python 解释器在启动是会自动加载一些模块的内存中,可以使sys.modules查看)
-
如果没有,解释器则会查找同名的内置模块
-
如果还没有找到就从sys.path给出的目录列表中依次寻找a.py文件。
-
待续


 ヾ(≧O≦)〃嗷~
ヾ(≧O≦)〃嗷~