数据结构常见的算法排序
1.排序的简单介绍
1.排序的概念
排序就是一系列数据,按照某个关键字(例如:销量,价格),进行递增或者递减的顺序排列起来.
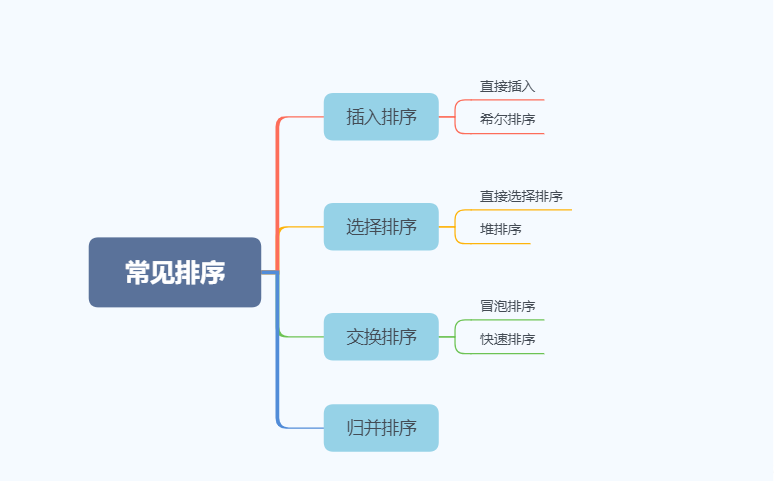
2.排序的分类
3.排序的性能比较
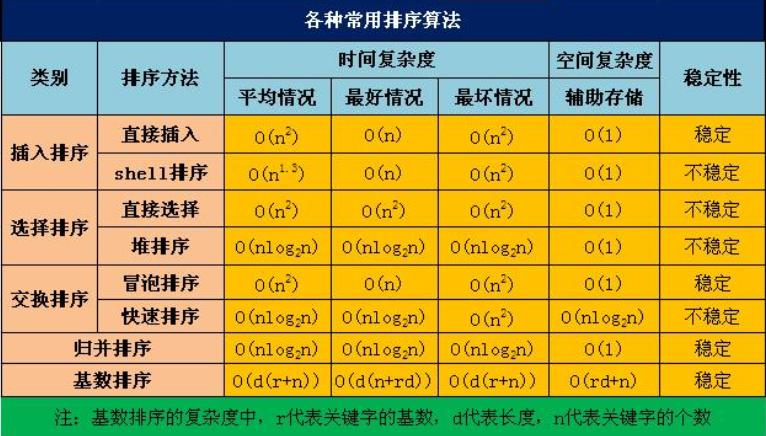
从平均情况看:堆排序、归并排序、快速排序胜过希尔排序。
从最好情况看:冒泡排序和直接插入排序更胜一筹。
从最差情况看:堆排序和归并排序强过快速排序。
虽然直接插入排序和冒泡排序速度比较慢,但是当初始序列整体或局部有序是,这两种算法的效率比较高。当初始序列整体或局部有序时,快速排序算法效率会下降。当排序序列较小且不要求稳定性是,直接排序效率较好;要求稳定性时,冒泡排序法效率较好。
2.排序算法的分析与实现
1.插入排序
分析过程:
插入排序的主要思想是每次取一个列表元素与列表中已经排序好的列表段进行比较,然后插入从而得到新的排序好的列表段,最终获得排序好的列表。比如,待排序列表为[49,38,65,97,76,13,27,49],则比较的步骤和得到的新列表如下:(带有背景颜色的列表段是已经排序好的,红色背景标记的是执行插入并且进行过交换的元素)

代码实现
# 方式一; def insert_sort(alist): for i in range(1, len(alist)): while i > 0: if alist[i] < alist[i - 1]: alist[i], alist[i - 1] = alist[i - 1], alist[i] i -= 1 else: break return alist alist = [49,38,65,97,76,13,27,49] print(insert_sort(alist))
# 方式二; def insert_sort(alist): # 遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始 for num in range(1,len(alist)): # 将该元素与已排序好的前序数组依次比较,如果该元素小,则交换 # range(x-1,-1,-1):从x-1倒序循环到0 for i in range(num-1,-1,-1): # 判断符合条件则交换 if alist[i] > alist[i + 1]: alist[i], alist[i + 1] = alist[i + 1], alist[i] return alist alist = [49,38,65,97,76,13,27,49] print(insert_sort(alist))
2.希尔排序
希尔排序也称为“缩小增量排序”,基本原理是:首先将待排序的元素分为多个子序列,使得每个子序的元素个数相对较少,对各个子序分别进行直接插入排序,待整个待排序序列“基本有序后”,再对所有元素进行一次直接插入排序。
分析过程:

代码实现:
def hill_sort(alist): gap = len(alist) // 2 # gap第一次设置为总长度为2 # 当gap的值大于等于1的时候 # 根据插入排序的原理给各个gap下分出的数组排序 while gap >= 1: # 将增量设置成gap for i in range(gap,len(alist)): while i > 0: if alist[i] < alist[i-gap]: alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break # 排序完当前下根据gap的分组,gap = gap // 2 gap //= 2 return alist alist = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0] print(hill_sort(alist))
3.选择排序
分析过程:
对于给定的一组记录,经过第一轮比较后得到最小的记录,然后将记录与第一个记录的位置进行交换;接着对不包括第一个记录以外的其他记录进行第二轮排序,得到最小的记录并与第二个记录进行位置交换;重复该过程,直到进行比较的记录只有一个为止。
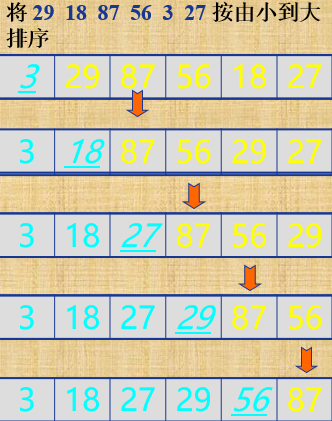
代码实现;
def choose_sort(alist): # 外层循环根据列表长度控制循环进行次数 for j in range(0, len(alist) - 1): max_index = 0 # 当前循环最大元素的索引 # 里层循环找出第j大的元素的索引,并赋值给max_index for i in range(1, len(alist) - j): # 俩俩比较 if alist[max_index] < alist[i]: max_index = i # 互换当前循环最大值元素与列表len(alist)-1-j元素位置 alist[max_index], alist[len(alist) - 1 - j] = alist[len(alist) - 1 - j], alist[max_index] return alist alist = [29, 18, 87, 56, 3, 27] print(choose_sort(alist))
alist = [29, 18, 87, 56, 3, 27] def choose_sort(alist): # 依次遍历序列中的每一个元素 for x in range(0, len(alist)): # 将当前位置的元素定义此轮循环当中的最小值 minimum = alist[x] # 将该元素与剩下的元素依次比较寻找最小元素 for i in range(x + 1, len(alist)): if alist[i] < minimum: alist[i], minimum = minimum,alist[i] # 将比较后得到的真正的最小值赋值给当前位置 alist[x] = minimum return alist print(choose_sort(alist))
4.冒泡排序
分析过程:
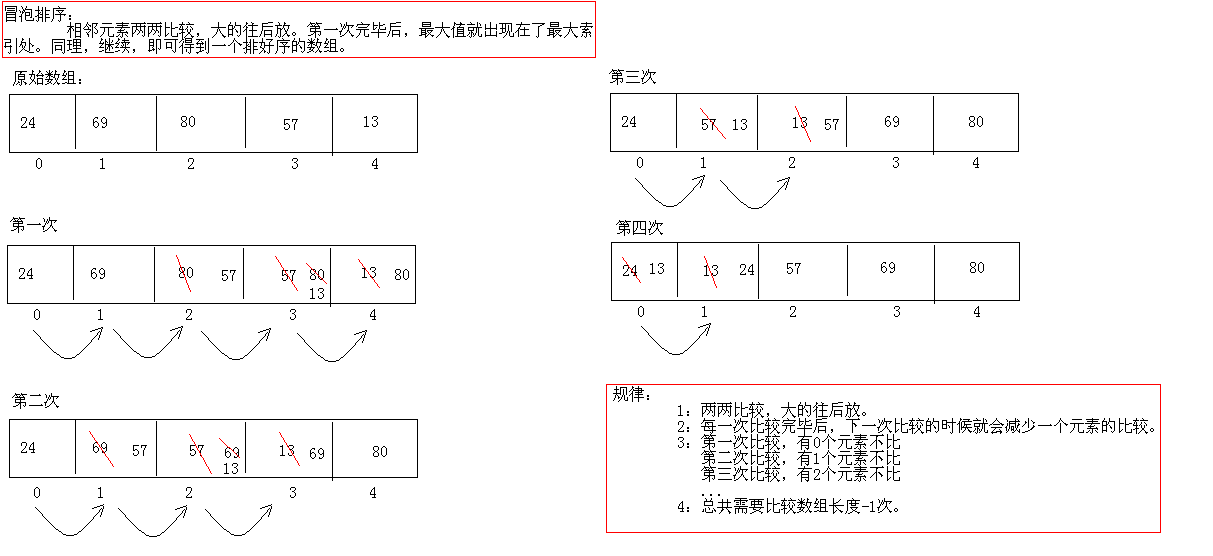
代码实现:
# 逐渐将乱序序列的最大值找出放置在乱序序列的尾部 def bubble_sort(alist): # 外层循环根据列表长度控制循环次数 for j in range(len(alist) - 1): # 对于每一轮交换,都将序列当中的左右元素进行比较 # 每轮交换当中,由于序列最后的元素一定是最大的,因此每轮循环到序列未排序的位置即可 for i in range(len(alist) - 1 - j): if alist[i] > alist[i + 1]: alist[i], alist[i + 1] = alist[i + 1], alist[i] return alist alist = [24, 69, 80, 57, 13] print(bubble_sort(alist))
冒泡排序的交换次数为n(n-1)/2
5.快速排序
分析过程;
原理:对于一组给定的记录,通过一趟排序后,将原序列分为两部分,其中前部分的所有记录均比后部分的所有记录小,然后再依次对前后两部分的记录进行快速排序,递归该过程,直到序列中的所有记录均为有序为止。
- 将列表中第一个元素设定为基准数字,赋值给mid变量,然后将整个列表中比基准小的数值放在基准的左侧,比基准大的数字放在基准右侧。然后将基准数字左右两侧的序列在根据此方法进行排放。
- 定义两个指针,low指向最左侧,high指向最右侧
- 然后对最右侧指针进行向左移动,移动法则是,如果指针指向的数值比基准小,则将指针指向的数字移动到基准数字原始的位置,否则继续移动指针。
- 如果最右侧指针指向的数值移动到基准位置时,开始移动最左侧指针,将其向右移动,如果该指针指向的数值大于基准则将该数值移动到最右侧指针指向的位置,然后停止移动。
- 如果左右侧指针重复则,将基准放入左右指针重复的位置,则基准左侧为比其小的数值,右侧为比其大的数值。
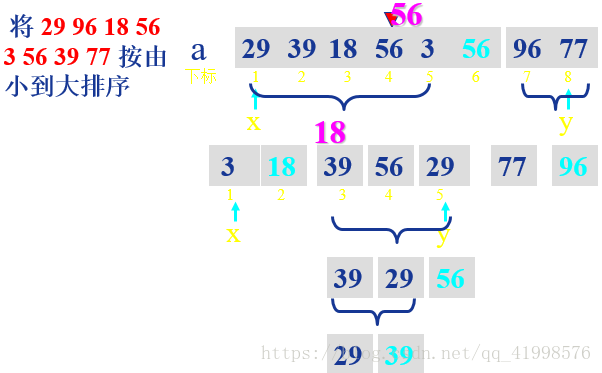
代码实现:
def sort(alist, start, end): # 基数 low = start high = end # 递归结束的条件 if low > high: return mid = alist[start] while low < high: # 偏移high while low < high: if alist[high] > mid: # 向左偏移high high -= 1 else: alist[low] = alist[high] break # 偏移low while low < high: if alist[low] < mid: # 向右偏移low的值 low += 1 else: alist[high] = alist[low] break # 结束最外层的循环条件 if low == high: alist[low] = mid break # 作用到左侧 sort(alist, 0, high - 1) # 左右到右侧 sort(alist, low + 1, end) return alist alist = [29,96,18,56,3,56,39,77] print(sort(alist, 0, len(alist) - 1))
待续

 ヾ(≧O≦)〃嗷~
ヾ(≧O≦)〃嗷~