Python格式化的输出,运算符和编码的初始
1.格式化的输出
当你遇到这样的需要:字符串中想让某些位置变成动态可传入的,首先考虑用格式化输出
1.格式化输出:%

- %s 表示字符串 - %d 表示整型 - %% 在打印时,需要打印%时,就需要写%% 实例: name = input("姓名") age = input("年龄") job = input("工作") happy = input("爱好") mag = "我叫%s,年龄%s,工作%s,爱好%s" %(name,age,job,happy) print(mag)
2.运算符
1.算数运算符
a = 10,b = 20

2.赋值运算符
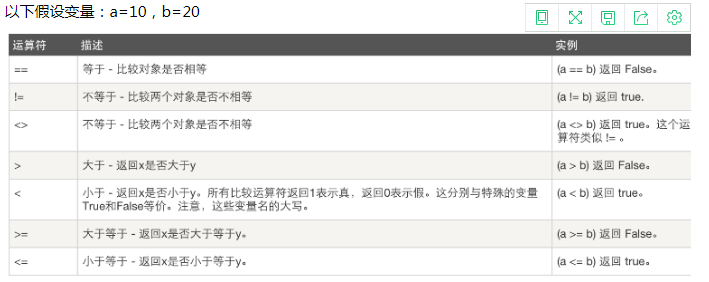
3.比较运算符
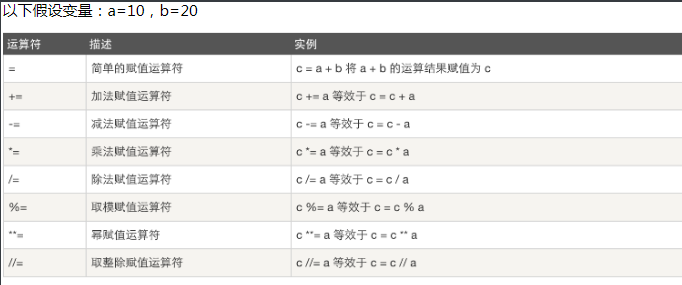
4.逻辑运算符

5. Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
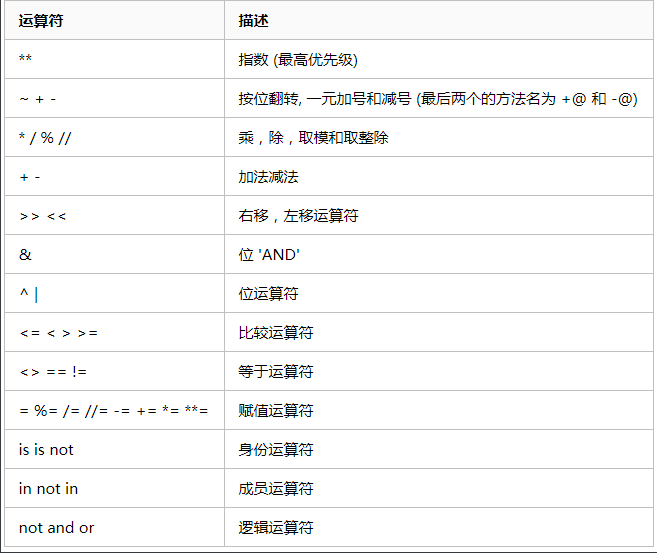
实例:
练习题1: 1 > 1 or 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 False or True or False and True and True or False False or True or False or False True
练习题2: 8 or 4 8 练习题3: 0 or 4 and 3 or 7 or 9 and 6 0 or 3 or 7 or 6 3
3.编码
1. ASCII码:
只包含:英文单词,数字,特殊字符,八位表示一个字符
2. gbk:包含字母,数字,特殊字符和中文。
-
一个英文字母 : 用一个字节表示
-
3.Unicode:万国码
表示世界上所有的文字,用四个字节表示一个字符
4. UTF-8:
是对unicode的压缩版。至少用一个字节表示一个字符
-
-
欧洲文字 :用两个字节表示
-
中文: ;用三个字节表示
不同的编码之间能否互相识别?
不能,会出现乱码或者报错
数据在内存中全部是以Unicode编码的,但是当你的数据用于网络传输或者存储到硬盘中,必须是以非Unicode编码(utf-8,gbk等等)。
英文: str: 'hello ' 内存中的编码方式: Unicode 表现形式: 'hello' bytes : 内存中的编码方式: 非Unicode 表现形式:b'hello' 中文: str: 内存中的编码方式: Unicode 表现形式:'中国' bytes : 内存中的编码方式: 非Unicode # Utf-8 表现形式:b'\xe4\xb8\xad\xe5\x9b\xbd'
str 与 bytes之间的转换
# str ---> bytes\ s1 = '中国' b1 = s1.encode('utf-8') # 编码 print(b1,type(b1)) # b'\xe4\xb8\xad\xe5\x9b\xbd' <class 'bytes'> b1 = s1.encode('gbk') # 编码 print(b1,type(b1)) # b'\xd6\xd0\xb9\xfa' <class 'bytes'> # bytes---->str b1 = b'\xe4\xb8\xad\xe5\x9b\xbd' s2 = b1.decode('utf-8') # 解码 print(s2)
应用
# gbk ---> utf-8 b1 = b'\xd6\xd0\xb9\xfa' s = b1.decode('gbk') # print(s) b2 = s.encode('utf-8') print(b2) # b'\xe4\xb8\xad\xe5\x9b\xbd'
待续
 ヾ(≧O≦)〃嗷~
ヾ(≧O≦)〃嗷~
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步