正则相关知识点
1.正则表达式
1.什么是正则表达式
一套规则 与匹配字符串的一套规则
2.能做什么?
1.检测一个输入的字符串是否合法。
-
-
-
能够提高程序的效率并且减轻服务器的压力
-
2.从一个大文件中找到符合规则的内容
-
- 能够高效的从一大段文字中快速找到符合规则的内容
3.正则规则
- 所有的规则中的字符就可以刚好匹配到字符串中的内容
4.字符串
- 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
- 接受范围,可以描述多个范围,连着写就可以了
- [abc] 一个中括号只表示一个字符位置(匹配a或者b或者c)
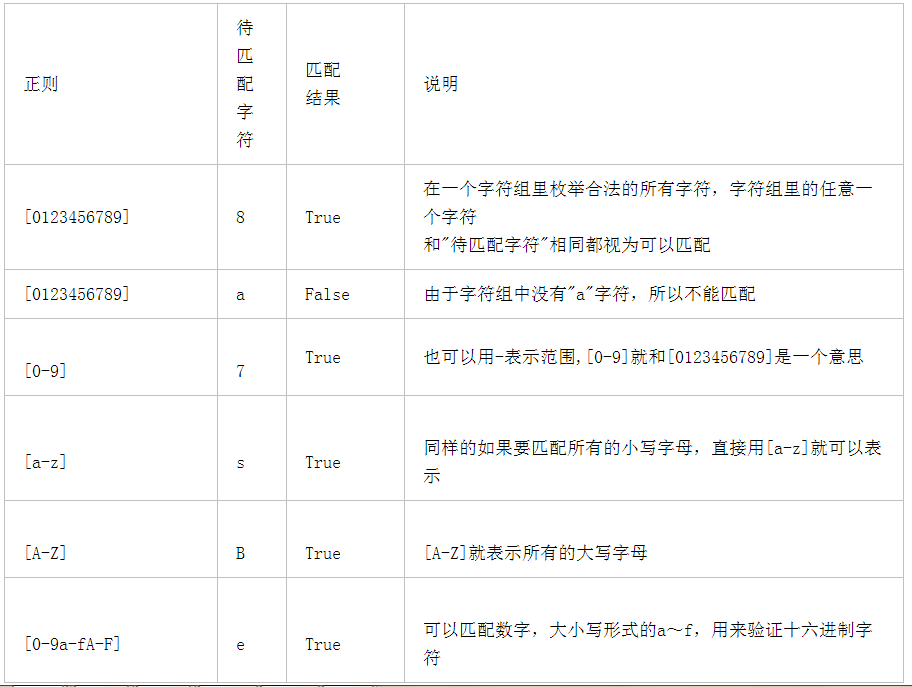
2.所有的元字符
\d 表示匹配所有的数字 \w 表示匹配数字,字母,下换线 \s 表示匹配所有的空白 \t 表示匹配制表符tab \n 表示匹配换行符\n 回车键 \D 表示匹配非数字 \W 表示匹配非数字,字母,下换线 \S 表示匹配非空白 . 除\n以外所有的 [] 匹配字符组中的字符 [^] 匹配除字符组中字符的所有字符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 ( ) 匹配括号内的表达式,也表示一个组 a|b 匹配字符a或者字符b
3.量词
? 重复零次或者一次 + 重复一次或更多次 * 重复零次或者多次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n次或m次
4.贪婪匹配与非贪婪匹配
# 贪婪匹配 在量词范围允许的情况下,尽量多的匹配内容 . *x 表示匹配任意字符,任意次数,遇到最后一个x才停下来 # 非贪婪匹配 . *?x 表示匹配任意字符,任意多次数,但是一旦遇到x就停下来
5.转义符
原本有特殊意义的字符,为了表达它本身的意义的时候,需要转义
有一些有特殊 意义的内容,放在字符组中,会取消它的特殊意义
[().*+?] 所有的内容在字符组中会取消它的特殊意义
[a-c] -在字符组中表示范围,如果不希望它表示范围,需要转义,或者放在字符组的最前面\最后面
练习题:
18位或者15位的身份证号 # 15位 [1-9]\d{14} # 18位 [1-9]\d{16}[\dx] [1-9]\d{16}[0-9x] 18位或者15位 # ^([1-9]\d{16}[\dx])$|^([1-9]\d{14})$ # ^[1-9]\d{14}(\d{2}[\dx])?$
6.re模块常用的方法
findall (正则,待匹配字符串flag):返回所有匹配项的
import re ret = re.findall("d+","19740ash93010uru") # 返回所有满足匹配条件的结果,放在列表里 print(ret) # ['19740', '93010']
search:返回一个变量,通过group取到的是一个匹配的项
ret = re.search('\d+','19740ash93010uru') if ret: print(ret.group()) # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 # 19740 ret = re.search('9(\d)(\d)','19740ash93010uru') print(ret) # 变量 # <_sre.SRE_Match object; span=(1, 4), match='974'> if ret: print(ret.group()) print(ret.group(1)) print(ret.group(2)) # 输出结果展示 974 7 4 # search 只取第一个符合条件的,没有优先显示这件事,得到的结果是一个变量。 # 变量.group() 的结果完全和变量.group(0)的结果一致 # 变量.group(n) 的形式指定获取第n个分组中匹配到的内容
为什么在search 中不需要分优先级,而在findall中需要?
加上括号是为了对真正需要的内容进行提取
import re ret = re.findall('<\w+>(\w+)</\w+>','<h1>askh930s02391j192agsj</h1>') print(ret) # ['askh930s02391j192agsj'] ret = re.search('<(\w+)>(\w+)</\w+>','<h1>askh930s02391j192agsj</h1>') print(ret.group()) print(ret.group(1)) print(ret.group(2)) # <h1>askh930s02391j192agsj</h1> # h1 # askh930s02391j192agsj
为什么要用分组,以及fildall的分组优先到底有什么好处
import re exp = "2-3*(5+6)" # a+b 或者是 a-b 并且计算他们的结果 ret = re.search("\d+[+,-]\d",exp).group() print(ret,type(ret)) if ret[1] == "-": a, b = ret.split("-") print(int(a) + int(b)) else: a, b = ret.split("+") print(int(a) + int(b))
# 输出结果为: 5
# 利用正则表达式 ret = re.search('(\d+)[+](\d+)',exp) print(int(ret.group(1)) + int(ret.group(2)))
# 输出结果: 5
分组和findall的现象
# 分组和findall的现象 # 为什么要用分组? # 把想要的内容放分组里
# 如何取消分组优先 # 如果在写正则的时候由于不得已的原因,导致不要的内容也得写在分组里 # (?:) 取消这个分组的优先显示
macth:从头开始找第一个,其他和search一样
import re ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) # 'a' # 用户输入的内容匹配的时候,需要用户输入11位数手机号码,^手机号码$match("手机号正则$","123eva456taibai")search("^手机号正则$","123eva456taibai")
compile(正则):同一个正则表达式需要多次使用的时候提前编译来节省时间
# 假如同一个正则表达式要被使用多次,使用compile节省了多次解析同一个正则表达式的时间 ret = re.compile("\d+") res1 = ret.search("alex37176") res2 = ret.findall("alex37176") print(res1) print(res2) # <_sre.SRE_Match object; span=(4, 9), match='37176'> # ['37176']
finditer :返回一个迭代器,通过迭代器取到的是一个变量,通过group取值(节省空间)
ret = re.finditer('\d+','agks123ak018g093') for i in ret: print(i.group()) # 123 # 018 # 093 # 通过compile节省时间,在通过finditer节省空间 ret = re.compile("\d+") res = ret.finditer('agks123ak018as093') for i in res: print(i.group()) # 123 # 018 # 093
split:通过正则表达式匹配的内容进行分割
import re ret = re.split("\d+","eva3egon4yuan") print(ret) # ['eva', 'egon', 'yuan'] ret = re.split("(\d+)",,"eva3egon4yuan") print(ret) # ['eva', '3', 'egon', '4', 'yuan'
在匹配部分加上()之后所切出的结果是不同的,没有 () 的没有保留所匹配的项,但是有 () 的却能够保留了匹配的项,这个在某些需要保留匹配部分的使用过程是非常重要的。
sub:替换,通过正则表达式匹配的内容进行替换
import re ret = re.sub("\d+","H","aas123dfghj147") print(ret) # aasHdfghjH ret = re.sub("\d+","H",,"aas123dfghj147",1) # 替换一个 print(ret) # "aasHdfghj147
subn 替换,在sub的基础上,返回一个元组,第一个内容是替换结果,第二个是替换次数
import re ret = re.subs("\d+","H",'alex123wusir456') print(ret) # ('alexHwusirH', 2)
7.分组命名
1.分组命名
import re ret = re.search('\d(\d)\d(?P<name3>\w+?)(\d)(\w)\d(\d)\d(?P<name1>\w+?)(\d)(\w)\d(\d)\d(?P<name2>\w+?)(\d)(\w)','123abc45678agsf_123abc45678agsf123abc45678agsf') print(ret.group("name1")) # agsf_123abc print(ret.group("name2")) # agsf 分组命名的基本格式 # (?P<名字>正则表达式) # ret.group('名字')
2.分组命名的引用
import re exp= '<abc>akd7008&(&*)hgdwuih</abc>008&(&*)hgdwuih</abd>' ret= re.search('<(?P<tag>\w+)>.*?</(?P=tag)>',exp) print(ret.group()) # <abc>akd7008&(&*)hgdwuih</abc> import re exp= '<abc>akd7008&(&*)hgdwuih</abc>008&(&*)hgdwuih</abd>' ret= re.search(r'<(\w+)>.*?</\1>',exp) ret= re.search('<(\w+)>.*?</\\1>',exp) print(ret)
练习题:
匹配出所有的整数部分 import re ret=re.findall(r"\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))") ret = filter(lambda n:n,ret) print(list(ret)) # ['1', '2', '60', '5', '4', '3'] # 分组命名(?P<组名>正则 (?p=组名)) # 有时候我们要匹配的内容是包含在不想要的内容之中的,只能先把不想要的内容匹配出来,然后再想办法从结果中去掉
待续


 ヾ(≧O≦)〃嗷~
ヾ(≧O≦)〃嗷~