损失函数(均方误差、交叉熵)
前言
损失函数是一种将一个事件(再一个样本空间中的一个元素)映射到一个表达与其事件相关的成本的实数上的一个函数,通常在最优化、统计学、机器学习等领域中有所应用,且在不同领域下应用的方式不同。
一个最佳化的问题是将损失函数最小化,即通过最小化损失函数求解和评估模型
在这里就只简单记录线性回归问题中常用的均方误差损失函数和分类问题中常用到的交叉熵损失函数
均方误差损失函数
首先其具体形式为:
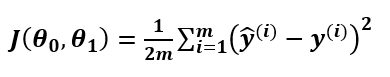
总的来说就是预测值与真实值之间的方差
注:
中的2的作用是为了简化求导过程,损失函数的目的是为了最小化,所以除以2并不会影响最优化结果

至于损失函数是如何工作的,不妨去吴恩达机器学习中关于代价函数的讲解中学习,视频会比单纯的文字加图像更为清晰,视频资源可自行上b站搜索《吴恩达机器学习》或点此跳转
至于如何在损失函数中求出最小值所对应的参数,可通过梯度下降算法实现。
交叉熵损失函数
首先其中一种常见的形式为:
![]()
对应参数解释同上。
简单列举几个关于交叉熵的要点:
- 了解交叉熵首先要明白什么是信息量,即

- 交叉熵的公式可通过相对熵(KL散度)转换而来,即
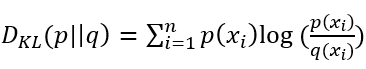 (其中p为真实值,q为预测值)
(其中p为真实值,q为预测值) - 对于机器学习中关于损失函数的定义:
- 了解交叉熵首先要明白什么是信息量,即
a) 在单分类问题中,对应于一个batch的loss为:
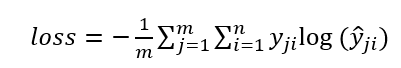
b)
在多分类问题中,对应于一个batch的loss为:
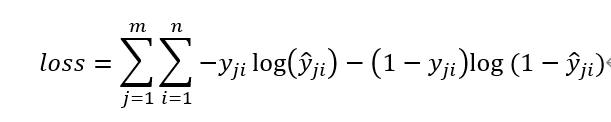
上两式中m为当前batch中的样本量,n为类别数,且这里的单分类指图像中只有一种类别,这里的多分类指图像中有多个类别
注:这里log函数指的是ln函数
关于公式的推导过程及详细讲解这里推荐两个讲的非常详细的文章
https://blog.csdn.net/red_stone1/article/details/80735068
https://blog.csdn.net/tsyccnh/article/details/79163834

 浙公网安备 33010602011771号
浙公网安备 33010602011771号