真正“搞”懂HTTP协议12之缓存代理
我们在前两篇的内容中分别学习了缓存和代理,大致了解了缓存有哪些头字段,代理是如何服务于服务器和客户端的,那么把两者结合起来,代理缓存,也就是说代理服务器也可以缓存,当客户端请求数据的时候,未必一定要追溯到源服务器上,代理服务器就可以直接把缓存的数据返回给客户端。并且,HTTP的缓存,大多数其实都是由代理服务器来实现,虽然源服务器也有各种缓存,比如大家可能听过的Redis,还有Memcache、Varnish等等,但是基本上跟HTTP没啥关系。
如果没有代理缓存,代理服务器仅仅只是一个中专作用,转发客户端和服务器的豹纹,中间不会存储任何数据。但是一旦给代理加上缓存后,事情就有些变化了。它在转发报文的同时,还要把报文存入自己的Cache里。下一次再有同样的请求,代理服务器就可以自己决断,从自己的缓存中取出数据返回给客户端,就无需再去源服务器获取。这样就降低了用户的等待时间,同时也节约了源服务器的网络带宽。
在HTTP的缓存体系中,缓存代理的身份十分特殊,它既是客户端,又是服务器,同时呢,它也既不是客户端,又不是服务器。因为代理面向客户端,就是服务器,面向服务器就表现为客户端,但是实际上代理又只是个中转,并不是真正的数据消费者和生产者,所以我们需要学一些新的Cache-Control属性来对它做些额外的约束。
嗯,这些新的属性就是本篇的重点了。建议大家对比着缓存那篇文章来看~
一、源服务器的缓存控制
源服务器的缓存控制,额……原谅我重复了一遍标题,在有代理服务器的场景下,它控制了哪些设备或者说终端或者说客户端呢?首先源服务器链路前的所有设备,包括代理服务器,对于源服务器来说都是客户端。那么问题来了,当有多个同样角色的时候,我们要怎么区分它们,针对不同的角色,设置不同的头字段属性呢?
我们在缓存那一章所学的Cache-Control的四个属性,对于代理服务器来说也是可以使用的,但是客户端和代理服务器肯定是不一样的,客户端只是自己使用,但是代理服务器,可能会分发给很多客户端使用。所以,第一,我们要做的就是对代理服务器和源服务器的HTTP数据做不同的标识。
首先,我们可以使用“private”和“public”来区分代理服务器和客户端上的缓存。比如像cookie这种私有性很强的数据,只能存储在客户端,不然被黑进了代理获取了用户的私有数据那可是很严重的问题了。
还有相对于“must-revalidate”是只要缓存过期,就要去源服务器验证,而“proxy-revalidate”只要求代理的缓存过期后必须验证,不必回溯到源服务器,只验证代理的缓存就可以了。
再次,缓存的生存时间可以使用“s-maxage”,其实就是share-maxage的简写,用它来限定在代理上能够存活多久,而客户端扔就使用“max-age”。
还有一个代理专用的属性,“no-transform”。代理有的时候会对缓存下来的数据做一些优化,比如把图片生成如png、webp等各种格式,方便今后的请求,而“no-transform”就会禁止这样的转换。
最后,大家一定要注意,源服务器在设置完Cache-Control字段后,必须要为报文加上“Last-Modified”或者“ETag”属性,否则客户端和代理后面就无法使用条件请求来验证缓存是否有效。
最后的最后我们基于缓存那一章的流程图,把代理服务器的验证逻辑也加进去。
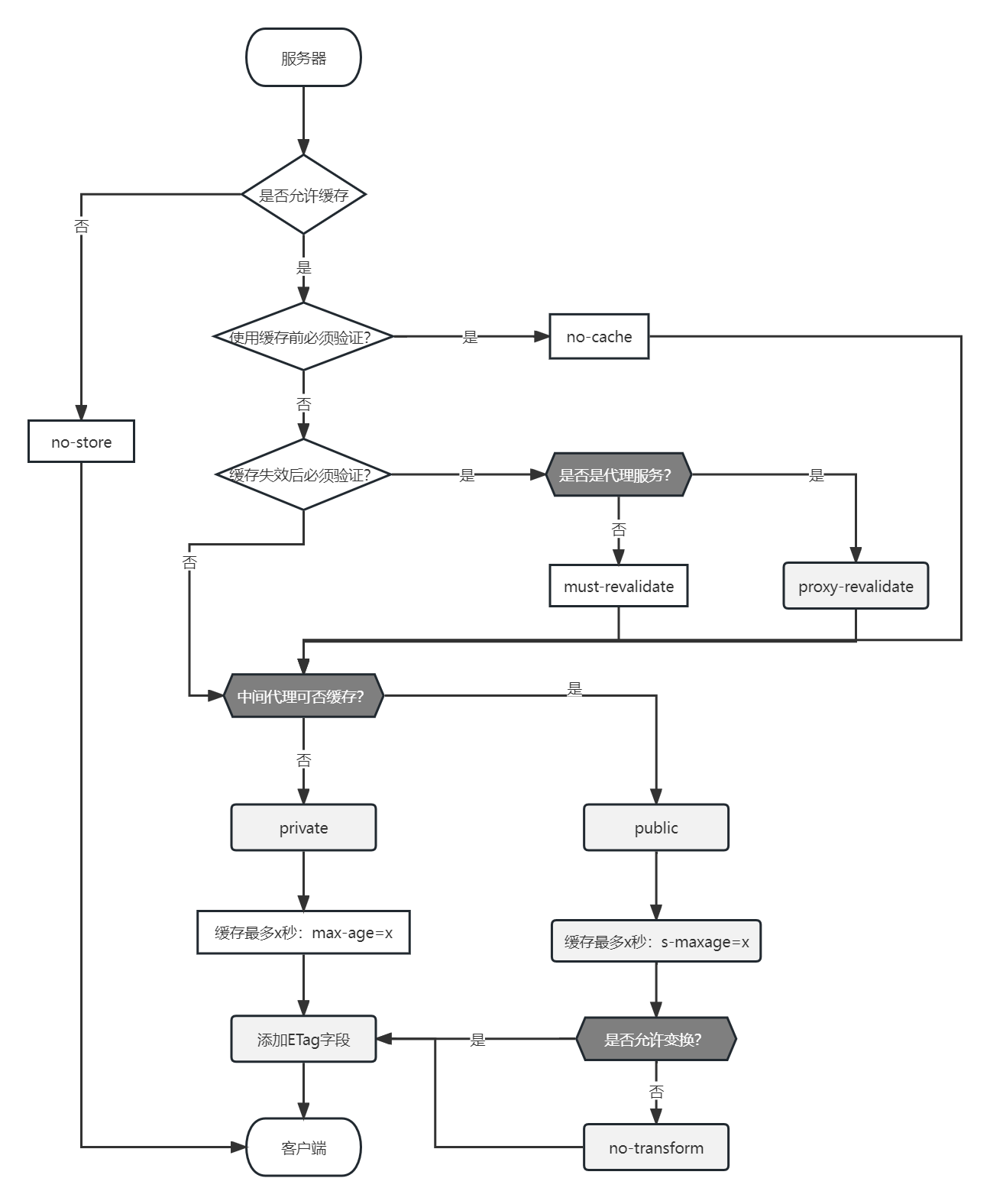
我们仔细来看一下这张图,在缓存失效后的验证节点,如果需要验证的话,会额外的去查看是否是代理缓存,并决定后续是查询代理还是查询源服务器。继而判断中间代理的缓存逻辑,是private还是public。然后继续判断各自路径的maxage。
仔细看完这张图后,我们发现,整个验证的核心节点和关键步骤其实是没有什么变化的,只是在判断的节点中额外的加入了是否需要代理的逻辑罢了。大家好好消化,仔细区分。
二、客户端的缓存控制。
客户端的缓存控制相比于源服务器的缓存控制,在加入了代理的场景下要相对简单一些。对于客户端来说,代理服务器就是服务器,所以max-age、no-store、no-cache这三个属性,跟面向源服务器时是一样的。
但是关于缓存的生存时间,在代理服务器上的约束和条件则多了两个新的属性“max-stale”和“min-fresh”。
“max-stale”的意思是如果代理上的缓存过期了也可以接受,但不能过期太多,超过 x 秒也会不要。“min-fresh”的意思是缓存必须有效,而且必须在 x 秒后依然有效。
有的时候客户端还会发出一个特别的“only-if-cached”属性,表示只接受代理缓存的数据,不接受源服务器的响应。如果代理上没有缓存或者缓存过期,就应该给客户端返回一个 504(Gateway Timeout)。
我们还是来看张图巩固下、串联一下这些知识:

这张图就是完整的客户端设置缓存约束的判定流程,大家一定要对比着有代理和没代理有啥区别来对照着学习。
三、小结
代理服务器可能会在响应报文中加入X-Cache、X-Hit等自定义的头字段,标识缓存是否命中和命中率,方便观察缓存代理的工作情况。
另外,大家还记得Vary这个头字段么,我们在之前的章节中学到过,它是内容协商后的结果,相当于报文的一个版本标记,缓存代理必须要存储这些不同的版本,当再收到相同的请求时,代理就会读取缓存里的Vary,对比请求头里的字段判断是否一致,是否可以返回缓存的数据。
还有一个“Purge”问题,也就是“缓存清理”,他对于代理也是非常重要的功能,比如:过期的数据、版本老旧、缓存危险数据等等。通常情况下,会使用一个自定义的PURGE方法,来删除对应连接的缓存数据。
好啦~到这里,我们学完了缓存代理的相关头字段,其实并不怎么复杂,只是在原有的缓存的头字段的基础上,加上了一些源服务器和客户端设置的头字段属性,让我们得控制缓存的细粒度更精细一些。
最后,我再次强调,大家要对比着和缓存那一章节来看图学习。
有关于HTTP/1.1的内容基本上就告一段落了。下一篇我们一起去领略一下HTTP/2的风采。
本文来自博客园,作者:Zaking,转载请注明原文链接:https://www.cnblogs.com/zaking/p/17101646.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号