真正“搞”懂HTTP协议10之缓存控制
HTTP缓存相关的问题好像是前端面试中比较常见的问题了,上来就会问什么cache-control字段有哪些,有啥区别啥的。嗯……说实话,我觉得至少在本篇来说,HTTP缓存还算不上复杂,只是字段稍微多了点,大家用心记一下就好啦。
缓存的概念,其实在你访问互联网中的任何资源其所产生的任何链路中的每一个节点几乎都会进行缓存,整个缓存体系和细节十分复杂。比如浏览器缓存,服务器缓存,代理服务器缓存,CDN缓存,等等等等。
但是缓存又十分重要,不可缺少,为啥这么说呢?由于HTTP请求的链路漫长,环境复杂,把一些必要的信息在关键的节点进行缓存,下次请求的时候可以尽可能的复用数据,就可以节省一部分资源的消耗,减少HTTP请求-应答的成本,节约带宽,加快响应速度。
那么,基于请求-应答模式的特点,缓存大致可以分为服务器缓存和客户端缓存,而服务器缓存经常与代理服务关联在一起,所以,我们今天讲的缓存,其实主要聊的就是客户端缓存,也就是浏览器缓存。下一篇,下下篇就会讲代理和代理缓存。嗯……代理其实也不复杂,但是往往两个东西组合起来的就会复杂一些。
那我们就来看看浏览器是咋缓存的吧。
一、服务器的缓存控制
假设,现在没有缓存,我们想象一下获取资源的方式是什么样的?客户端请求资源,服务器返回资源,等下一次想要获取同样资源的时候,哪怕服务器的资源并没有更新,还是要重新走一遍网络请求,然后服务器返回资源的完整链路。
那,如果有了缓存,在客户端第一次获取到请求的资源后,把资源缓存到本地,下次再去请求的时候,发现本地有这个资源,直接拿来用就好了,完全不用去走网络请求。有缓存的简易流程大概是这样的:
- 浏览器发现请求的该资源无缓存,直接发送请求,获取服务器资源。
- 服务器收到请求后,响应该请求并返回资源,同时标记资源的有效期。
- 浏览器缓存资源,等待下次使用。
我们仔细的阅读一下这个简单的缓存资源请求流程,发现其中有几个重要的节点。首先,服务器在返回该资源时,要标记该资源的有效期。然后,浏览器初次请求肯定是没缓存的,再次请求的时候,它要根据该资源的有效期来判断下一步该怎么办。OK,我们再简单一点,如果我们试图去获取缓存资源,其实是要看服务器的标记的。
那么换句话说,服务器标记缓存资源,浏览器会验证该缓存资源的标记。
1、Cache-Control
这个字段想必大家非常熟悉了吧,就是服务器用来标记资源缓存有效期的头字段。我们可以这样来标记资源的有效时间:
Cache-Control: max-age=30
啥意思呢,就是该资源的有效期是30秒。这是一个相对时间,时间计算的起点是报文创建的时刻,也就是Date头字段的时间,是指资源离开服务器的时刻,而不是客户端收到报文的时候,换句话说,假设我们设置的时间是5秒,但是链路请求很长,花费了4秒的时间,那么缓存对于浏览器的有效时间只是1秒。那你可能会说,就这一秒有啥用啊~~假设你网站的访问量特别大,每秒有上百万的访问,那你可以想象到这仅仅一秒的时间能节省服务器多大的压力了吧。当然,只是举个极限的例子~
除了max-age这个最常用的属性以外,还有三个属性可以更精确的指示浏览器如何使用缓存:
- no-store:不允许缓存,用于某些变化非常频繁的页面,比如拼多多秒杀页面。
- no-cache:它的字面意思和no-store很容易搞混,实际上它的意思并不是不允许缓存,而是可以缓存,但是在使用之前必须要去服务器验证是否过期,是否有最新的版本。
- must-revalidate:和no-cache又很相似,它的意思是缓存不过期就可以继续使用,但是过期了如果还想用就必须去服务器验证一下。
cache-control的这几个字段的差别十分细微,大家要稍微认真记一下。
我们学了四个Cache-Control头字段的属性,我们来看张图,巩固一下这些细微的差别:
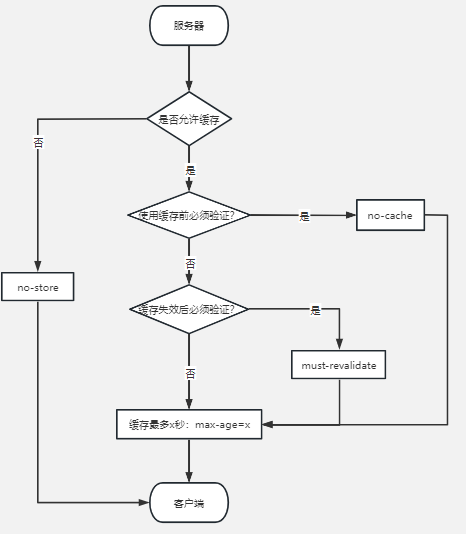
我们来过下整张图的流程,首先服务器要通过no-store属性设置该资源是否允许缓存,如果允许缓存,那么继续设置是否在使用缓存前去验证,需要验证的话就直接设置max-age,否则还要再去设置must- revalidate属性,缓存失效后是否需要验证。
二、客户端的缓存控制
我们刚刚学习了Cache-Control头字段,并且学习了服务器是怎么控制该字段的相关属性的。不仅仅是服务器可以控制缓存,客户端也可以控制缓存,客户端是怎么控制的呢?
当你点击浏览器的刷新按钮的时候,实际上,浏览器就在HTTP请求中夹带了"Cache-Control:max-age=0",之前说过,max-age是生存时间,纪录的是从服务器生成的那一刻的有效期,而浏览器本地的资源,肯定不可能是0,所以当浏览器加上了max-age=0的时候,每次都会向服务器请求最新的资源。而当你使用Control+F5强制刷新的时候其实是浏览器发了一个“Cache-Control: no-cache”。基本上和max-age=0差不多一样的效果,但是含义肯定是不一样的,就看服务器要怎么理解和处理不同的字段。
那么什么时候缓存才能派上用场呢?当我们点击浏览器的前进后退按钮的时候,就会直接从缓存中获取数据,另外,重定向的时候,也可能会使用到缓存。那这两类操作有啥区别呢。其实本质上来说,就是前进、后退、跳转这样的操作,浏览器不会私自加上Cache-Control字段,并且会清空If-Modified-Since 和 If-None-Match字段(后面会说条件请求),所以就会检查缓存,直接利用之前的资源,不再进行网络通信。
我们可以在稍后的例子中试一下~
三、条件请求
仅仅只是Cache-Control字段,只能做到刷新数据,不能很好的利用缓存数据,由于缓存数据可能会失效,所以每次使用缓存前还必须去服务器验证一下。有点麻烦~
那咋整呢?我们可以先发一个HEAD请求,或许服务器资源的一些基本信息,然后和缓存的数据做比较,如果没有改动就使用缓存,否则呢,就去服务器获取最新的资源。
但是这样的两个网络请求成本太高了,所以HTTP就定义了一些If开头的“条件请求”字段,专门用来验证资源是否过期,把两个请求合并到一个请求中,验证的职责也交给服务器,客户端只要坐享其成就可以了。
条件请求一共有五个字段,我们最常用的只有“if-Modified-Since”和“If-None-Match”这两个。需要第一次请求的时候,服务器预先提供“Last-modified”和“ETag”,当第二次请求的时候就可以带上缓存里的原值,验证资源是否是最新的。
如果资源没有变化,那么服务器返回个304,更新下资源的有效时间,使用缓存就可以了。
Last-modified很好理解,就是最后一次修改文件的时间。那ETag是啥呢?ETag 是“实体标签”(Entity Tag)的缩写,是资源的一个唯一标识,主要是用来解决修改时间无法准确区分文件变化的问题。
比如,文件的修改时间是秒级甚至更短的,所以一秒内的新版本是无法区分的,再比如,一个文件定期更新,但有时内容没有变化,用修改时间就会以为发生了变化,发送给客户端以为是新的资源,浪费带宽。
使用ETag就可以精确的识别资源的变动情况,让浏览器更有效地利用缓存。
ETag还有强弱之分。
强 ETag 要求资源在字节级别必须完全相符,弱 ETag 在值前有个“W/”标记,只要求资源在语义上没有变化,但内部可能会有部分发生了改变(例如 HTML 里的标签顺序调整,或者多了几个空格)。至于是强还是弱,其实是由服务器自主决定的。弱也可以强,强也可以弱。
条件请求里其他的三个头字段是“If-Unmodified-Since”“If-Match”和“If-Range”,其实只要你掌握了“if-Modified-Since”和“If-None-Match”,可以轻易地“举一反三”。
四、示例
我们先搞个max-age的小例子,看看缓存能否生效:
res.setHeader("Cache-Control", "max-age=20");
就很简单,我们可以看到在响应头中返回了我们设置好的缓存字段:
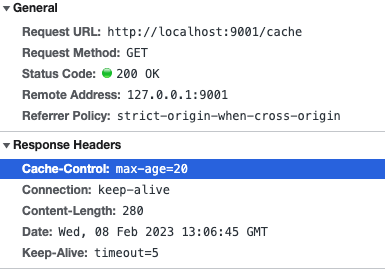
大家还可以自己尝试设置no-store,no-cache等字段。当你设置了no-store属性后,你会发现,哪怕使用浏览器的前进,后退按钮,每次也是重新从服务器获取资源,但是no-cache和max-age则会使用缓存。
简单的例子就这样啦~
五、小结
本篇到这里就结束啦~我们稍稍回顾一下,都学了哪些内容,其实就一个字段Cache-Control,并且稍微涉及到了一点关于浏览器可能会夹带的私货是怎样的。并且我们还学习了条件请求以及强弱Etag,大家要着重了解下。然后呢,本篇没有问题,但是有个遗留的小例子我没写,就是条件请求的例子。大家可以参照我上面的小例子,试着在这里玩一下条件请求。
好啦~下一篇,我们来学下代理~
本文来自博客园,作者:Zaking,转载请注明原文链接:https://www.cnblogs.com/zaking/p/17057833.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号