论文阅读笔记——基于SRP-Phat与3D卷积神经网络的声源追踪
1.Introdcution
大多数传统声源追踪技术可以分为以下几类
- 基于到达时延(TDOA)的技术,即首先使用互相关(GCC)函数来估计到达时延,紧接着测算出最有可能的DOA
- 基于波束成形技术,例如SRP-PHAT。通过搜寻波束成形器最大功率的方向来找寻最可能的DOA
- 子空间技术,例如多信号分类(MUSIC),基于窄带互相关矩阵特征结构
上面提到的三类传统方法在噪声以及混响等复杂场景下表现较差,使用它们去处理复杂信号还需要利用源位置之间的相关性,借助跟踪算法来进一步提升识别结果。
近些年来,基于深度学习的声源识别得到推广,但是由于深度学习技术在使用的过程中,会加上一些原因不明的层导致它们在实际使用中存在不小的困难,且不能证明它们是最具鲁棒性且最可靠的方式。
作者团队在SRP-PHAT功率图的基础上使用3DCNN来执行高混响条件下的声源估计,且取得了不错的结果。并且通过多次实验验证了该方法的鲁棒性。作者在实验该方法的过程中,主要关注始终存在的单一声学信号,不关注声音信号的产生和消失。但是该种方法在多声源的情况下也许使用困难。
2.SRP-PHAT算法
在第n个麦克风处接受到的信号可以表示为:
- \(x_n(t) = a_s(t) * h_n(\theta_s, t)+v_n(t)\)
- 参数含义:
- \(a_s(t)\):信号源产生的信号
- \(\theta_s\):声源位置,可以表示一个角度,两个球面坐标,或者是3D笛卡尔坐标中的一个点,具体取决于数组的几何形状
- \(h_n(\theta_s, t)\):从声源位置到第n个传感器的脉冲响应
- \(v_n(t)\):传感器噪声,通常被认为是白色,高斯,并且与声源信号和其他传感器的噪声无关
- 常用方法:寻找最大响应脉冲功率,获得最可靠的声源位置。使用滤波波束和波束成形器获得功率。
- \(\hat{\theta}_s = argmax_\theta P(\theta)\)
- \(P(\theta) = \int_{-\infty}^{+\infty} \lvert \sum^\limits{N-1}_\limits{n=0}G_n(\omega)X_n(\omega)e^{jw\tau_n(\theta)}\rvert^2d\omega\)
- 参数含义
- \(X_n(\omega)\):\(x_n(t)\)的傅里叶变换
- \(G_n(\omega)\):滤波器对通道n的频率响应
- \(\tau_n(\theta)\):从位置或者\(\theta\)角方向到第n个传感器的时延
上面的过程可以用广义互相关实现:
- \(P(\theta) = 2\pi \sum^\limits{N-1}_\limits{n=0}\sum^\limits{N-1}_\limits{m=0} R_{mn} (\Delta\tau_{nm}(\theta))\)
- \(\Delta\tau_{nm}(\theta) = \tau_n(\theta) - \tau_m(\theta)\)和Rmn代表了第n个和第m个传感器之间的广义互相关。
- \(R_{nm}(\tau) = \frac{1}{2\pi}\int^{+\infty}_{-\infty}\psi_{nm}(\omega)X^*_m(\omega)e^{j\omega t}d\omega\)
- *代表复共轭算子,\(\psi_{nm}(\omega) = G_n(\omega)X^ *_m(\omega)\)是权重函数
上面的计算\(P(\theta)\)式子与PHAT加权函数:\(G_n(\omega) = 1/\lvert X_n(\omega) \rvert\),这就是SRP-PHAT算法。
下图是作者团队在信噪比=30,混响时间=0.3s的情况下,获得的SRP-PHAT功率图,其中红点代表真实的声源DOA,黑点代表的是功率图的最大值:
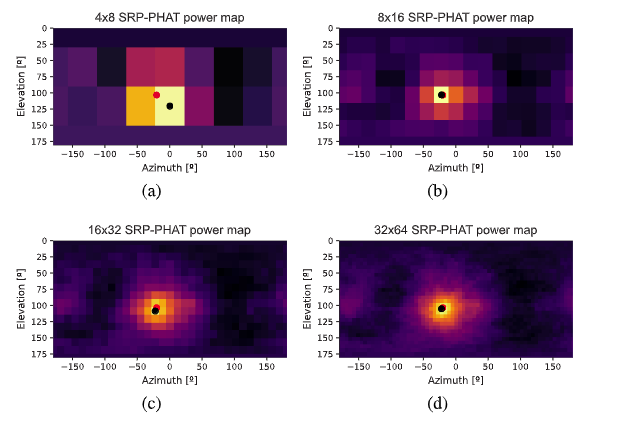
在高信噪比,低混响的情况下,SRP-PHAT功率图反应的对声源的DOA估计存在明显的最大值,可以获得对声源的良好估计。但是如果信噪比降低,混响增加,会出现数个局部最大值,这些最大值kennel会错误地被解释为声音的DOA。
下图很好的反映了上述改变带来的误差:

常见的处理方案是在使用上述算法进行声源估计之后加入跟踪阶段,通过源位置与时间的相关性,避免在信号功率较低或者是某帧中最大值不精确的情况下带来不准确的估计。
使用深度学习网络进行DOA估计
最早使用DOA估计的最早使用是具有隐藏层的全连接感知器从广义互相关中获得DOA,来作为分类问题。
A.输出格式
作者团队为了获得DOA估计,首先定义了一个具有方向的网格,在网格之中可以建立声源,所以神经网络可以在每个网格点处产生输出。在论文中,作者还特别提到了将DOA估计问题作为回归问题,将DOA问题当作回归问题来解决回事的多声源估计问题更复杂更困难。
B.输入特征和网络构建
最初最常见的特征是每个传感器信号之间的GCC,但是我们也可以找到别的方法,例如使用空间协方差矩阵的特征向量。作者团队提出使用低分辨率的SRP-PHAT图谱,与全联接的感知器结合。近年来还有在麦克风频谱图上使用二维卷积。
主要使用的特征包括相位信息,幅度信息(或两者兼有),还包括强度矢量,原本音频样本以及其他提到的向量。
CNN具有平移不变性,在一定限度内对数据进行评议处理,得到的结果仍然具有相同的特征以及规律性。这一性质在计算机视觉领域应用广泛,即相同的部分在图片的任意位置都具有相同的含义。
本文在SRP-PHAT的基础上使用cnn在图的维度和时间维度上进行卷积,是否能使用此方法取决于阵列的几何形状。作者关注的是紧凑阵列,并且由于他们关注时间维度,所以需要使用3DCNN,并且作者是用了2D球面功率图。
CNN的主要作用是对SRP-PHAT处理之后的数据进行跟踪,并且进一步处理。使用任何跟踪方法都可以有效的达成这一目的,作者为了使得系统可以用于实时应用,选择了仅使用因果卷积。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号