python django基础五 ORM多表操作
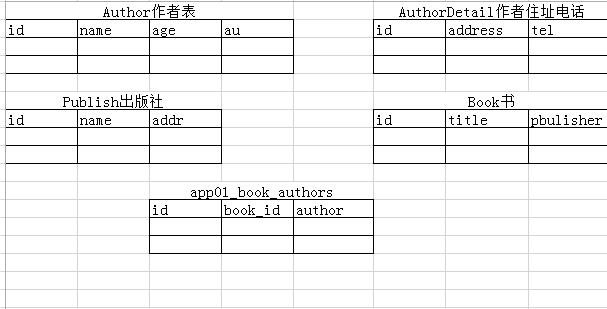
首先在创建表的时候看下分析一下
1.作者表和作者详细地址表 一对一关系 理论上谁都能当主表 把Author设置成主表 au=models.OneToOneField(to='AuthorDetail',to_field='id')
主表会多个au列 用于关联
2.书和出版社 一个出版社可以出好多书 一对多关系,哪个表数据多就把关键设置哪个表中 所以publisher=models.ForeignKey(to='Publish',to_field='id',on_delete=models.CASCADE)关联后publisher字段会变成publisher_id,有级联删除deltete
3.书和作者表 多对多关系 理论上谁都能当主表 把book设为主表 authors=models.ManyToManyField(to='Author')这时候会产生第3个表app01_book_authors用于保存书id和作者id的对应的关系
创建表
from django.db import models #作者表 class Author(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=30) age=models.IntegerField() #AuthorDetail 一对一表 关联 au=models.OneToOneField(to='AuthorDetail',to_field='id') #详细地址 class AuthorDetail(models.Model): id=models.AutoField(primary_key=True) address=models.CharField(max_length=40) tel=models.CharField(max_length=20) #出版社 class Publish(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=20) addr=models.CharField(max_length=40) #书 class Book(models.Model): id=models.AutoField(primary_key=True) title=models.CharField(max_length=20) #书和出版社 出版社一对多 publisher=models.ForeignKey(to='Publish',to_field='id',on_delete=models.CASCADE) #多对多 书跟作者 authors=models.ManyToManyField(to='Author')
python manage.py makemigrations
python manage.py migrate
添加数据
一对一
先添加地址表 models.AuthorDetail.objects.create( id=2,address='杭州',tel=777 ) #如果写对应另一个表id 需要写au_id字段
models.Author.objects.create( name='张无忌',age=18,au_id=1 )
一对多
方法一 查询出版社id=1 pub_obj=models.Publish.objects.filter(id=1)[0] models.Book.objects.create(title='西游记',publisher=pub_obj) #publisher是设计字段
publisher_id是生产的 方法二 models.Book.objects.create( title='三国演义', publisher_id=1 )
book_obj.authors.add(*[1,2])#添加多参数
多对多
# 多对多插入 book_obj = models.Book.objects.get(id=2) lzs = models.Author.objects.get(id=2) ##第二种方式 # book_obj.authors.add(*[1,2]) book_obj.authors.add(2, 2)
删除:
models.Author.objects.filter(id=1).delete() #删除作者的不会删除详细信息 models.Book.objects.filter(id=1).delete() #删除某一本书的时候会删除书相关的第三张表 book_obj.authors.clear()#全部清空 book_obj.authors.remove('2')
应用地址
models.Book.objects.get(id=n).delete()
更新
models.Author.objects.filter(id=1).update(au_id=5) au=authordetail对象 book_obj = models.Book.objects.filter(id=1)[0] models.Book.objects.filter(id=1).update(title='xxxxx',publisher_id=4) book_obj.authors.set(['3','4']) #应用地址 models.Book.objects.filter(id=n).update(**data) one_book.authors.set(authors_lsit)
查询数据
一对一查询
##正向一对一查询 zuozhe=models.Author.objects.get(name='张无忌') print(zuozhe.au.address)#通过 au映射 作者信息 找到地址 ##反向一对一查询 fanzuozhe=models.AuthorDetail.objects.get(address='台湾') print(fanzuozhe.author.name)#author是作者名称
一对多查询
# 一对多查询 shu=models.Book.objects.get(title='三国演义') print(shu.publisher.name)#通过书名 publisher正向查询出版社name #反向查询 fanshu=models.Publish.objects.get(name='18期出版') print(fanshu.book_set.all().values())
多对多查询
##多对多查询 shu=models.Book.objects.get(title='三国演义') print(shu.authors.all().values('name')) fanshu=models.Author.objects.get(name='张无忌') print(fanshu.book_set.all().values())
双__线查法
正向----->字段名__属性
反向----->表名__属性
#查询18期出版 出版了哪些书 ret=models.Book.objects.filter(publisher__name='18期出版').values('title') #先找book表到出版社属性中的name values值等于title ret=models.Publish.objects.filter(name='18期出版').values('book__title') #先找到出版社18期values等于book表的title #天龙八部这本书是哪些作者写的 ret=models.Book.objects.filter(title='天龙八部').values('authors__name') # print(ret)#<QuerySet [{'authors__name': '张无忌'}, {'authors__name': '赵敏'}]> ret=models.Author.objects.filter(book__title='天龙八部').values('name') # print(ret)#<QuerySet [{'name': '张无忌'}, {'name': '赵敏'}]>
#查询18期出版 出版过的所有书籍的名字以及作者的姓名 找到作者 因为作者和出版社没关系 所以要通过authors ret=models.Publish.objects.filter(name='18期出版').values('book__title','book__authors__name') # print(ret) #通过publisher 找到18期出版 values等于title 然后通过authors查作者名称 ret=models.Book.objects.filter(publisher__name='18期出版').values('title','authors__name') # print(ret)
#手机号以2开头的作者出版过的所有书籍名称以及出版社名称 #书表通过authors作者,au找到tel 6开头的 书名 通过publisher查出版社name ret=models.Book.objects.filter(authors__au__tel__startswith='6').values('title','publisher__name') print(ret)
聚合查询
聚合是同aggreate(*args,**kwarges),通过querySet进行计算 主要有Sum,Avg,Max,Min
from django.db.models import Sum,Avg,Max,Min,Count
Sum 总和
ret=models.Author.objects.all().aggregate(Sum("age")) print(ret) 85
Avg 平均值
ret=models.Author.objects.all().aggregate(Avg("age")) print(ret)#{'age__avg': 28.3333}
还可以对结果进行别名
ret=models.Author.objects.all().aggregate(age=Avg("age"))
print(ret)#{'age': 28.3333}
Max和Min
ret=models.Author.objects.all().aggregate(Max('age'),Min('age'),age=Avg("age")) print(ret)#{'age': 28.3333, 'age__max': 55.0, 'age__min': 10.0}
Count(计数)
ret=models.Author.objects.all().aggregate(Count('name')) print(ret)#{'name__count': 3}
分组查询
将查询结果按照某个字段或字段分组进行分组,字段中相等的为一组
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值
单表分组查询
#统计每个部门的人数 ret=models.Author.objects.values('dep').annotate(c=Count('id')) print(ret)#<QuerySet [{'dep': '人力', 'c': 2}, {'dep': '人事', 'c': 1}, {'dep': '财务', 'c': 1}]> #统计每个部门的平局工资 ret=models.Author.objects.values('dep').annotate(avg=Avg('salary')) print(ret)
values('dep')表示以dep字段进行分组
annotate(按每个组的id字段进行统计)
多表分组查询
#每个出版社出了多少书 ret=models.Book.objects.values('publisher__id','publisher__name').annotate(c=Count('id')) print(ret)#<QuerySet [{'publisher__id': 1, 'publisher__name': '太阳出版社', 'c': 2}, {'publisher__id': 2, 'publisher__name': '月亮出版社', 'c': 1}]> #每个作者出了多少书 ret=models.Book.objects.values('authors__name').annotate(c=Count('title')) print(ret)#<QuerySet [{'authors__name': '张无忌33', 'c': 1}, {'authors__name': '周芷若', 'c': 1}, {'authors__name': '赵敏', 'c': 2}]> #查询每一本书的名称及作者个数 对id进行分组,按authors__name ret=models.Book.objects.annotate(count=Count("authors__name")).values('title','count') print(ret)#<QuerySet [{'title': '倚天屠龙记', 'count': 1}, {'title': '天龙八部', 'count': 2}, {'title': '月亮代表我的心', 'count': 1}]> #查询大于一个作者的书籍名称 ret=models.Book.objects.filter(count__gt=1).values('title','count') print(ret)#<QuerySet [{'title': '天龙八部', 'count': 2}]> # 查询每个出版色最便宜的书籍名称 ret = models.Publish.objects.annotate(MinPrice=Min("book__price")).values_list("name", "MinPrice") print(ret)#<QuerySet [('太阳出版社', Decimal('100.00')), ('月亮出版社', Decimal('300.00'))]> #统计每一本以py开头的书籍的作者个数 ret=models.Book.objects.filter(title__startswith="天").annotate(num_authors=Count('authors')).values_list("title","num_authors") print(ret)#<QuerySet [('天龙八部', 2), ('天天开心', 1)]> #查询每个作者的姓名以及出版的书的最高价格 ret=models.Author.objects.values('name').annotate(Max('book__price')) ret=models.Author.objects.annotate(jiage=Max('book__price')).values('name','jiage') #2 查询作者id大于2作者的姓名以及出版的书的最高价格 ret = models.Author.objects.values('name').filter(id__gt=2).annotate(Max('book__price')) #3 查询作者id大于2或者作者年龄大于等于20岁的女作者的姓名以及出版的书的最高价格 ret = models.Author.objects.filter(Q(id__gt=2)|Q(age__gte=20),sex='female').values('name').annotate(Max('book__price')) #4 查询每个作者出版的书的最高价格 的平均值 ret = models.Author.objects.values('name').annotate(aa=Max('book__price')).aggregate(Avg('aa'))
多表分组查询
F对象之间的加减乘除
from django.db.models import F
#把Book的价格字段 批量+30 models.Book.objects.all().update(price=F("price")+ 30) #查询年纪小于 工资的name __gt 表示大于 models.Author.objects.filter(age__lt=F('salary')).values("name")
Q对象的复杂查询
对象可以使用&(与) 、|(或)、~(非)
from django.db.models import Q
#分别查询作者周芷若、赵敏出版过的书籍名称 ret=models.Book.objects.filter(Q(authors__name="周芷若")|Q(authors__name="赵敏")).values("title")#如果2个人合出的书,会出现2个title
等同于下面的SQL WHERE 子句: WHERE name ="周芷若" OR name ="赵敏"
ret=models.Book.objects.filter(~Q(authors__name="赵敏")).values("title") print(ret)#查询非赵敏
ret=models.Book.objects.filter(Q(authors__name="周芷若") & ~Q(authors__salary=6000)).values_list("title")
print(ret)
#分别查询作者周芷若、赵敏出版过的书籍名称 ret=models.Book.objects.filter(authors__name="周芷若").filter(authors__name="赵敏").values_list("title") print(ret)#<QuerySet [('天龙八部',)]>
事物
#正常只有第一条被成功插入 from app01 import models from django.db import transaction models.Publish.objects.create(name='青蛙出版社1', addr='井里1') with transaction.atomic(): # ret = models.Publish.objects.all().values('name') models.Publish.objects.create(name='青蛙出版社2',addr='井里2') models.Publish.objects.create(id='青蛙出版社3',addr='井里3')
