python 内置函数,匿名函数,sorted,filter,map,递归,二分法,冒泡算法 eval
############################总结#################################
1. lambda 匿名函数
语法——lambda 参数:返回值
__name__:查看函数的名字(查看到底是谁)
fn=lamdba a,b:a+b ret=fn(1,2) print(ret) #结果 3
2. sorted() 排序函数
语法:sorted(iterable, key = 函数名, reverse = False)
内置函数提供的一个通用的排序方案,sortend()
key: 排序方案,sorted函数会把可迭代对象中的每一个元素拿出来交给后面的key
后面的key计算出一个数字(权重),作为当前这个元素的权重,整个函数根据权重排序
reverse=True: 默认表示为正序, reverse=False表示反转
#按照排序出
lst=['刘亦菲','张倩','张三'] print(sorted(lst)) print(sorted(lst,key=lambda a:len(a))) ======结果==== ['张倩', '张三', '刘亦菲']
3. filter() 过滤函数
语法: filter(function, iterable)
li = ['sv','sdf','fdf','fdsg','ghfd'] f=filter(lambda a:a[0] != 's',li) a=[i for i in f] print(a) #######筛选第一个字符 是不是s打头赛选出来 ['fdf', 'fdsg', 'ghfd']
#年纪大于12的
dic=[{'name':'zhang1','shenggao':12},
{'name': 'zhang2', 'shenggao': 14},
{'name': 'zhang3', 'shenggao': 15}]
f=filter(lambda d:d['shenggao']>12,dic)
i=[i for i in f]
print(i)
############
[{'name': 'zhang2', 'shenggao': 14}, {'name': 'zhang3', 'shenggao': 15}]
4. map() 映射函数(水桶效应)
语法: map(function, iterable)
把后面的可迭代对象中的每一个元素传递给function,结果就是function的处理结果
dic=[{'name':'zhang1','shenggao':12},
{'name': 'zhang2', 'shenggao': 14},
{'name': 'zhang3', 'shenggao': 15}]
f=map(lambda d:d['shenggao']+10,dic)
i=[i for i in f]
print(i)
##########把年纪 加上10岁
[22, 24, 25]
lst=['篮球','足球','排球'] s=map(lambda a:a+'aaa',lst) for i in s: print(i) ########### 篮球aaa 足球aaa 排球aaa
5. 递归
函数自己调用自己
官方最大深度:1000
6. 二分法
核心:掐头去尾取中间,一次砍一半
前提条件:有序序列
可以提高效率
两种算法:常规循环,递归循环
##################################作业##########################################
# lst = ['今天星期三', "明天星期四", "马上星期 五"] # it = lst.__iter__() # print(it.__next__()) # print(it.__next__()) # print(it.__next__()) # it = iter(lst) # it = lst.__iter__() # print(next(it)) # it.__next__() # zip 拉链函数 lst1 = ["赵四", "刘能", "香秀"] lst2 = ["刘晓光", "王小利"] # 水桶效应 lst3 = ["街舞", "磕巴", "哭"] z = zip(lst1, lst2, lst3) print("__iter__" in dir(z)) # 判断是否是可迭代对象 for el in z: print(el)
lst = [11,5,36,1,27,58] s = sorted(lst) # 默认从小到大排序. print(s) lst = ["胡一菲", "张伟", "关谷神奇", "曾小贤吕小布", "诺澜"] # 按照字符串长度排序 def func(s): return len(s) # 返回长度 # 执行流程: # 把可迭代对象中的每一项拿出来, 作为参数传递给后面key函数. # 函数返回数字. 根据数字进行排序 s = sorted(lst, key=func) print(s) print(sorted(lst, key=lambda s:len(s) ))
lst = [
{"name":"alex", "shengao":150, "tizhong":250},
{"name":"wusir", "shengao":158, "tizhong":150},
{"name":"taibai", "shengao":177, "tizhong":130},
{"name":"ritian", "shengao":165, "tizhong":130},
{"name":"nvshen", "shengao":160, "tizhong":120},
{"name":"baolang", "shengao":183, "tizhong":190}
]
# 按照体重进行排序
print(sorted(lst, key=lambda dic:dic['tizhong'], reverse=True))
# # filter 过滤 # lst = ["张无忌", "张翠山", "范冰冰", "金毛狮王", "李冰冰"] # # # 过滤掉姓张的人 # # 把可迭代对象打开. 把内部元素一个一个的传递给前面的函数. 由这个函数决定此项是否保留 # f = filter(lambda name : not name.startswith("张"), lst) # # print("__iter__" in dir(f)) # 可迭代对象 # for el in f: # print(el)
lst = [
{"name":"alex", "shengao":150, "tizhong":250},
{"name":"wusir", "shengao":158, "tizhong":150},
{"name":"taibai", "shengao":177, "tizhong":130},
{"name":"ritian", "shengao":165, "tizhong":130},
{"name":"nvshen", "shengao":160, "tizhong":120},
{"name":"baolang", "shengao":183, "tizhong":190}
]
# 过滤掉体重大于180的人 想要的是 小于180
f = filter(lambda d : d['tizhong'] <= 180, lst)
print(list(f))
# map() 映射函数 lst = ["篮球球", "打打台球", "唱歌", "爬慌山", "步"] m = map(lambda s: "爱好:"+s , lst) print(list(m)) lst = [1,5,78,12,16] # 计算每个数字的平方 print([i **2 for i in lst]) m = map(lambda i: i ** 2, lst) print(list(m))
# l=[{'name':'alex'},{'name':'y'}]
# m=map(lambda d : d['name']+'_sb',l)
# print(list(m))
# 4,用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb # name=['oldboy','alex','wusir'] # m=map(lambda s:s+'_sb', name) # print(list(m)) # 5,用map来处理下述l,然后用list得到一个新的列表,列表中每个人的名字都是sb结尾 # l=[{'name':'alex'},{'name':'y'}] # m=map(lambda d : d['name']+'_sb',l) # print(list(m)) # 6,用filter来处理,得到股票价格大于20的股票名字 # shares={ # 'IBM':36.6, # 'Lenovo':23.2, # 'oldboy':21.2, # 'ocean':10.2, # } # ret=filter(lambda d:shares[d]>20, shares) # print(ret) # for i in ret: # print(i) # 7,有下面字典,得到购买每只股票的总价格,并放在一个迭代器中。 # 结果:list一下[9110.0, 27161.0,......] portfolio = [ {'name': 'IBM', 'shares': 100, 'price': 91.1}, {'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'FB', 'shares': 200, 'price': 21.09}, {'name': 'HPQ', 'shares': 35, 'price': 31.75}, {'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'ACME', 'shares': 75, 'price': 115.65}] # # m=map(lambda x:x['shares'] * x['price'],portfolio) # print(list(m)) # 8,还是上面的字典,用filter过滤出单价大于100的股票。 # f = filter(lambda d : d['price'] > 100,portfolio) # print(list(f)) # 9,有下列三种数据类型, l1 = [1,2,3,4,5,6] l2 = ['oldboy','alex','wusir','太白','日天'] tu = ('**','***','****','*******') # 写代码,最终得到的是(每个元祖第一个元素>2,第三个*至少是4个) # [(3, 'wusir', '****'), (4, '太白', '*******')]这样的数据。 ret=list(filter(lambda x:x[0] >2 and len(x[2])> 3,zip(l1,l2,tu))) print(list(ret)) # 10,有如下数据类型: l1 = [ {'sales_volumn': 0}, {'sales_volumn': 108}, {'sales_volumn': 337}, {'sales_volumn': 475}, {'sales_volumn': 396}, {'sales_volumn': 172}, {'sales_volumn': 9}, {'sales_volumn': 58}, {'sales_volumn': 272}, {'sales_volumn': 456}, {'sales_volumn': 440}, {'sales_volumn': 239}] # 将l1按照列表中的每个字典的values大小进行排序,形成一个新的列表。 ret = list(sorted(l1, key = lambda x:x['sales_volumn'])) print(ret)
################################递归####################################
import os def func(lujing,n): lst=os.listdir(lujing)#打开文件夹,列出所有名字 b c for el in lst: #循环当前文件夹名字 b c path=os.path.join(lujing,el)#拼接出路径+文件夹 D:/app/zip\7-Zip if os.path.isdir(path):#判断是不是文件夹 print('...'* n,el) #如果是文件就打印 func(path,n+1) #再来一次 else: print("\t" * n,el) func("D:/app/zip",0)
============================================
import os
for path,dirs,files in os.walk("D:\\python_work_s18\\djangozong\\ajax"):
for file in files:
print(os.path.join(path,file))
############################二分法#################################
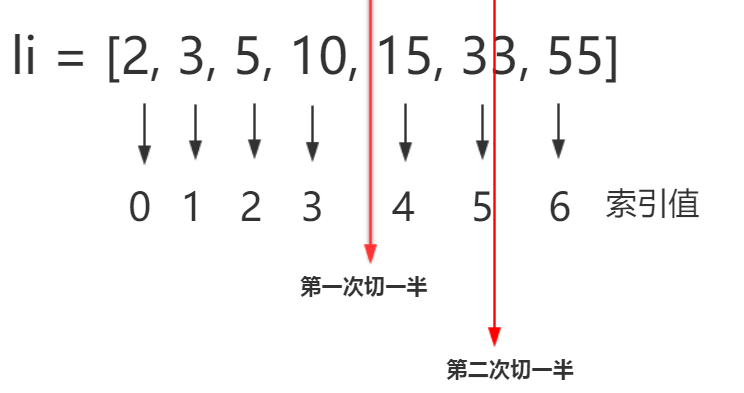
lst = [1,3,5,7,12,36,68,79] n = int(input("请输入一个数")) left = 0 #左边界等于0 right = len(lst) - 1 #右边界 while left <= right:#小于等于right的时候才成立 不然就为假 mid = (left + right)//2 if n > lst[mid]:#如果输入的内容n比右边的大 就把左边境加mid+1 掐头结尾 left = mid + 1 elif n < lst[mid]:#如果输入的内容n比左边的小 就把右边边境mid减1 掐头结尾 right = mid - 1 else: print("存在") break else: print("不存在")
########################冒泡算法################################
# 冒泡排序, 最low的冒泡. 可以进行优化, ACM, 领扣 lst = [1 , 2, 3, 43, 2, 2, 21, 1, 12, 3] # sort() for j in range(len(lst)): # ??? 有多少个数. 就循环多少次 for i in range(len(lst)-1): #要与i+1比较 所以要减一位 if lst[i] > lst[i+1]: #for循环 i和i+1做比较 如果前面的比后面的大就换 lst[i], lst[i+1] = lst[i+1], lst[i] # 核心思想 交换 #结果值把最大的换到了最后 所以要加个外层for 继续执行换 print(lst)
eval() 函数用来执行一个字符串表达式,并返回表达式的值。 f = open("shoppingcart.txt", mode="r", encoding="utf-8") for line in f: # {'id': 1, 'name': '大白菜', 'price': 8.8} d = eval(line.strip()) # {'id': 1, 'name': '大白菜', 'price': 8.8} print("商品名称:", d['name'], "商品价格", d['price'])#商品名称: 大白菜 商品价格 8.8
callable 查看是否可被调用
def func(): pass print(callable(func)) # 可以被调用 print(callable("刘伟")) a = 123 print(callable(a)) # 可以帮我们区分 函数和普通变量 ######结果 True False False
不怕大牛比自己牛,就怕大牛比自己更努力

