


第一次个人编程作业
github作业链接
题目需求
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
计算模块接口的设计与实现过程
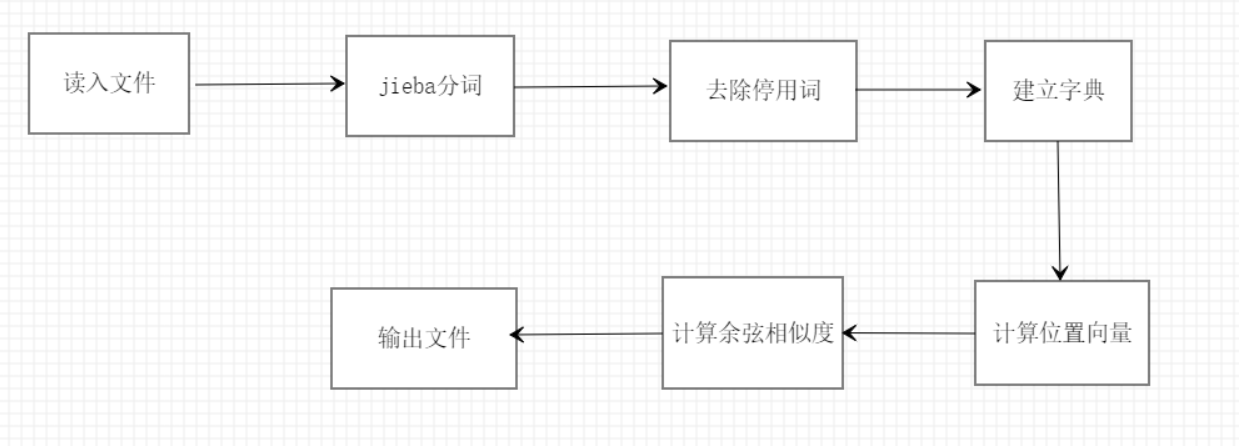
流程图
如何应用余弦相似度计算文本相似度?
1.举个栗子
句子A:明天周末没课,我们去打篮球吧
句子B:明天还要上课,好想去打篮球
2.先用jieba分词
句子A:明天/周末/没课。/我们/去/打篮球/吧。
句子B:明天/还要/上课/,/我/好想/去/打篮球。
3.列出所有词
明天,周末,没课,我们,去,打篮球,吧,还要,上课,我,好想
4.计算词频
句子A:明天1,周末1,没课1,我们1,去1,打篮球1,吧1,还要0,我0,上课0,好想0
句子B:明天1,周末0,没课0,我们0,去1,打篮球1,吧0,还要1,我1,上课1,好想1
5.列出词频向量
句子A:(1,1,1,1,1,1,1,0,0,0,0)
句子B:(1,0,0,0,1,1,0,1,1,1,1)
6.计算向量余弦值确定句子相似度
- 计算向量余弦值的公式为
\[cos(\theta)=\frac{\sum_{i=1}^n{(x_i*y_i)}}{\sqrt[]{\sum_{i=1}^n{x_i}^2}×\sqrt[]{\sum_{i=1}^n{y_i}^2}}
\]
- 将栗子向量带入公式
\[cos(\theta)=\frac{1×1+1×0+1×0+1×0+1×1+1×1+1×0+0×1+0×1+0×1+0×1}{\sqrt[]{1^2+1^2+1^2+1^2+1^2+1^2+1^2+0^2+0^2+0^2+0^2}×\sqrt[]{1^2+0^2+0^2+0^2+1^2+1^2+0^2+1^2+1^2+1^2+1^2}}=\frac{3}{7}=0.43
\]
测试单元代码
import unittest
from BeautifulReport import BeautifulReport
import main
class TestFunction(unittest.TestCase):
@classmethod
def setUp(self):
print("开始测试")
@classmethod
def tearDown(self):
print("测试结束")
def text_orig(self):
print("正在读取orig.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_add(self):
print("正在读取orig_0.8_add.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_add.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_del(self):
print("正在读取orig_0.8_del.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_del.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_dis_1(self):
print("正在读取orig_0.8_dis_1.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_dis_1.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_dis_3(self):
print("正在读取orig_0.8_dis_3.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_dis_3.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_dis_7(self):
print("正在读取orig_0.8_dis_7.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_dis_7.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_dis_10(self):
print("正在读取orig_0.8_dis_10.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_dis_10.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_dis_15(self):
print("正在读取orig_0.8_dis_15.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_dis_15.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_mix(self):
print("正在读取orig_0.8_mix.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_mix.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
def text_rep(self):
print("正在读取orig_0.8_rep.txt")
file1 = main.readfile(r'sim_0.8\orig.txt')
file2 = main.readfile(r'sim_0.8\orig_0.8_rep.txt')
list1 = main.wordcut(file1)
list2 = main.wordcut(file2)
degree = main.sim((main.dic(list1,main.unii(list1,list2))), main.dic(list2,main.unii(list1,list2)))
print('相似度为%.2f' % degree)
if __name__ == '__main__':
suite = unittest.TestSuite()
tests = [
TestFunction('text_orig'),
TestFunction('text_add'),
TestFunction('text_del'),
TestFunction('text_dis_1'),
TestFunction('text_dis_3'),
TestFunction('text_dis_7'),
TestFunction('text_dis_10'),
TestFunction('text_dis_15'),
TestFunction('text_mix'),
TestFunction('text_rep')
]
suite.addTests(tests)
BeautifulReport(suite).report(filename='测试报告.html',
description='论文查重报告',
log_path='.')
测试报告
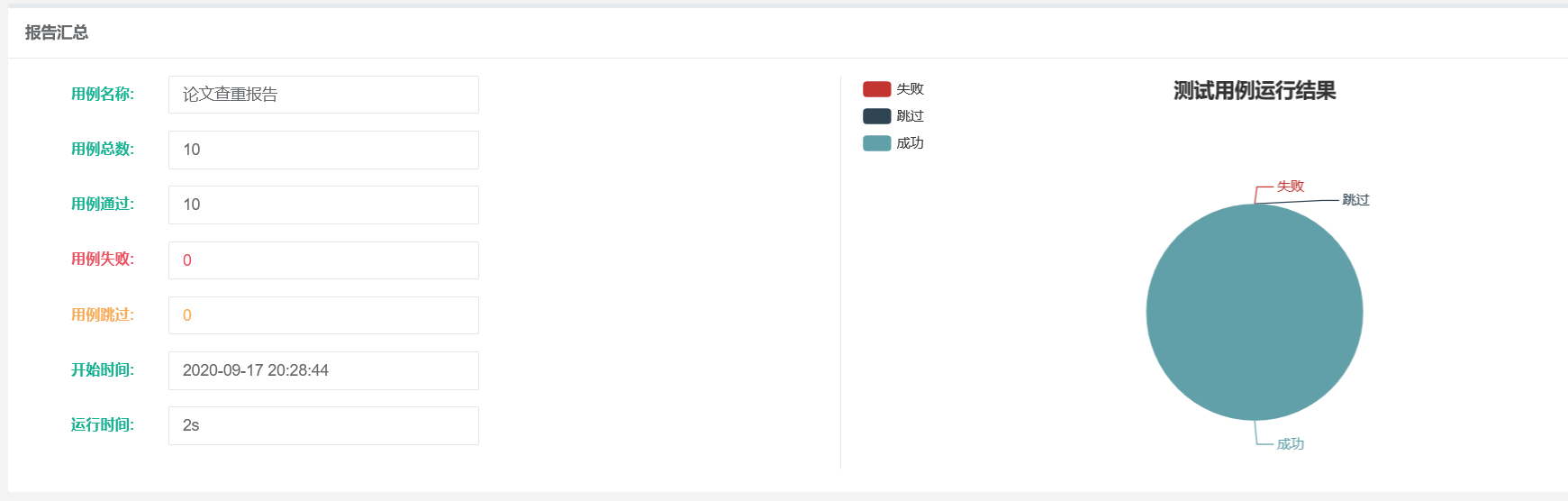
覆盖率
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| · 计划 | 30 | 30 |
| · 估计这个任务需要多少时间 | 30 | 30 |
| · 开发 | 360 | 400 |
| · 需求分析 (包括学习新技术) | 480 | 500 |
| · 生成设计文档 | 20 | 30 |
| · 设计复审 | 20 | 30 |
| · 代码规范 (为目前的开发制定合适的规范) | 60 | 40 |
| · 具体设计 | 40 | 40 |
| · 具体编码 | 360 | 430 |
| · 代码复审 | 30 | 30 |
| · 测试(自我测试,修改代码,提交修改 | 240 | 210 |
| · 报告 | 30 | 50 |
| · 测试报告 | 30 | 20 |
| · 计算工作量 | 30 | 40 |
| · 事后总结, 并提出过程改进计划 | 20 | 40 |
| · 合计 | 1780 | 1920 |
总结
1.这次作业是我从小学开始直到现在,整个学习生涯遇到的最大的坎,就是完全无法下手的那种困难,事实上我也没有战胜他,而是写出了一坨shit
2.一定要好好学,多打代码,争取下次作业做得好一点,做出一坨五彩缤纷的shit

