vue--过滤器(filter)的使用详解

前言
Vue 允许我们在项目中定义过滤器对我们页面的文本展示进行格式的控制,本文就来总结一下过滤器在项目中的常见使用方法。
正文
1.局部过滤器的注册
(1)无参局部过滤器
<div id="app"> <!-- 组件内部的过滤器 --> <filter-item :msg="toMsg"></filter-item> </div> <script> // 组件内部注册过滤器 Vue.component("filter-item", { data() { return { } }, props: ['msg'], filters: { toFixed(value) { if (!value) { return } return value.toFixed(2) }, }, template: "<div>{{msg|toFixed}}</div>" }) new Vue({ el: "#app", data() { return { toMsg: 123, } }, }) </script>
运行结果如下:
上面的代码中在子组件内部定义一个过滤器,在其模板中的插值表达式中使用,完成了对字符串的格式化。
(2)带参局部过滤器
<div id="app"> <!-- 组件内部的过滤器 --> <filter-item :msg="toMsg"></filter-item> </div> <script> // 组件内部注册过滤器 Vue.component("filter-item", { data() { return { } }, props: ['msg'], filters: { toString(value,arg){ if (!value) { return } console.log("value",value); return value.toString(arg) } }, template: "<div>{{msg|toString(2)}}</div>" }) // 全局注册过滤器 new Vue({ el: "#app", data() { return { toMsg: 123, } }, }) </script>
运行结果如下:
上面的代码中在组件内部定义一个过滤器,接受两个参数,第一个参数是需要格式化的文本,第二个是需要进行的进制转化。
2.全局过滤器的注册
(1)无参全局过滤器
<div id="app"> <!-- 全局的过滤器 --> {{myMsg|toUpper}} </div> <script> // 全局注册过滤器 new Vue({ el: "#app", data() { return { myMsg: "abcdef" } }, filters: { toUpper(value) { if (!value) { return } return value.toUpperCase() }, }, methods: { } }) </script>
运行结果如下: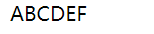
上面的代码中在vue根组件中定义一个过滤器,该过滤器为全局过滤器,同样通过插值表达式完成格式转化。
(2)带参全局过滤器
<div id="app"> <!-- 传递参数的过滤器 --> {{myMsg|toSlice(3)}} </div> <script> // 全局注册过滤器 new Vue({ el: "#app", data() { return { toMsg: 123, myMsg: "abcdef" } }, filters: { // 传参的过滤器 toSlice(value,arg){ if (!value) { return } return value.slice(arg) } }, }) </script>
运行结果如下:
上面的代码中在vue根组件中定义一个全局过滤器,该过滤器接收两个参数,第一个参数为需要格式化的文本,第二个为真正的参数。
注意:当局不和全局有两个名称相同的过滤器的时候,会首先使用局部过滤器,这里采用就近原则,局部过滤器会优先于全局过滤器的调用。
3.过滤器的使用
在插值表达式中使用带个过滤器如上文,如果需要组合使用多个过滤器的时候,需要用 "|"分隔符隔开。使用如下:
<div id="app"> <!-- 串联的过滤器 --> {{myMsg|toUpper|toReverse}} </div> <script> // 全局注册过滤器 new Vue({ el: "#app", data() { return { toMsg: 123, myMsg: "abcdef" } }, filters: { toUpper(value) { if (!value) { return } return value.toUpperCase() }, toReverse(value) { if (!value) { return } return value.split("").reverse().join("") }, } }) </script>
运行结果如下:
上面的代码使用了串联的过滤器,首先通过toUpper过滤器对文本进行大写转化,然后toReverse过滤器对文本进行反转转化,最终得到结果。
4、原理分析
使用过滤器
{{ message | capitalize }}
在模板编译阶段过滤器表达式将会被编译为过滤器函数,主要是用过parseFilters,我们放到最后讲
_s(_f('filterFormat')(message))
首先分析一下_f:
_f 函数全名是:resolveFilter,这个函数的作用是从this.$options.filters中找出注册的过滤器并返回
// 变为
this.$options.filters['filterFormat'](message) // message为参数
关于resolveFilter
import { indentity,resolveAsset } from 'core/util/index'
export function resolveFilter(id){
return resolveAsset(this.$options,'filters',id,true) || identity
}
内部直接调用resolveAsset,将option对象,类型,过滤器id,以及一个触发警告的标志作为参数传递,如果找到,则返回过滤器;
resolveAsset的代码如下:
export function resolveAsset(options,type,id,warnMissing){ // 因为我们找的是过滤器,所以在 resolveFilter函数中调用时 type 的值直接给的 'filters',实际这个函数还可以拿到其他很多东西 if(typeof id !== 'string'){ // 判断传递的过滤器id 是不是字符串,不是则直接返回 return } const assets = options[type] // 将我们注册的所有过滤器保存在变量中 // 接下来的逻辑便是判断id是否在assets中存在,即进行匹配 if(hasOwn(assets,id)) return assets[id] // 如找到,直接返回过滤器 // 没有找到,代码继续执行 const camelizedId = camelize(id) // 万一你是驼峰的呢 if(hasOwn(assets,camelizedId)) return assets[camelizedId] // 没找到,继续执行 const PascalCaseId = capitalize(camelizedId) // 万一你是首字母大写的驼峰呢 if(hasOwn(assets,PascalCaseId)) return assets[PascalCaseId] // 如果还是没找到,则检查原型链(即访问属性) const result = assets[id] || assets[camelizedId] || assets[PascalCaseId] // 如果依然没找到,则在非生产环境的控制台打印警告 if(process.env.NODE_ENV !== 'production' && warnMissing && !result){ warn('Failed to resolve ' + type.slice(0,-1) + ': ' + id, options) } // 无论是否找到,都返回查找结果 return result }
下面再来分析一下_s:
_s 函数的全称是 toString,过滤器处理后的结果会当作参数传递给 toString函数,最终 toString函数执行后的结果会保存到Vnode中的text属性中,渲染到视图中
function toString(value){ return value == null ? '' : typeof value === 'object' ? JSON.stringify(value,null,2)// JSON.stringify()第三个参数可用来控制字符串里面的间距 : String(value) }
最后,在分析下parseFilters,在模板编译阶段使用该函数阶段将模板过滤器解析为过滤器函数调用表达式
function parseFilters (filter) { let filters = filter.split('|') let expression = filters.shift().trim() // shift()删除数组第一个元素并将其返回,该方法会更改原数组 let i if (filters) { for(i = 0;i < filters.length;i++){ experssion = warpFilter(expression,filters[i].trim()) // 这里传进去的expression实际上是管道符号前面的字符串,即过滤器的第一个参数 } } return expression } // warpFilter函数实现 function warpFilter(exp,filter){ // 首先判断过滤器是否有其他参数 const i = filter.indexof('(') if(i<0){ // 不含其他参数,直接进行过滤器表达式字符串的拼接 return `_f("${filter}")(${exp})` }else{ const name = filter.slice(0,i) // 过滤器名称 const args = filter.slice(i+1) // 参数,但还多了 ‘)’ return `_f('${name}')(${exp},${args}` // 注意这一步少给了一个 ')' } }
小结:
- 在编译阶段通过
parseFilters将过滤器编译成函数调用(串联过滤器则是一个嵌套的函数调用,前一个过滤器执行的结果是后一个过滤器函数的参数) - 编译后通过调用
resolveFilter函数找到对应过滤器并返回结果 - 执行结果作为参数传递给
toString函数,而toString执行后,其结果会保存在Vnode的text属性中,渲染到视图
写在最后
以上就是本文的全部内容,希望给读者带来些许的帮助和进步,方便的话点个关注,小白的成长之路会持续更新一些工作中常见的问题和技术点。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号