前端性能优化原理与实践二
webpack 性能调优与 Gzip 原理
大家可以从第一节的示意图中看出,我们从输入 URL 到显示页面这个过程中,涉及到网络层面的,有三个主要过程:
- DNS 解析
- TCP 连接
- HTTP 请求/响应
HTTP 连接这一层面的优化是我们网络优化的核心。因此我们开门见山,抓主要矛盾,直接从 HTTP 开始讲起。
HTTP 优化有两个大的方向:
- 减少请求次数
- 减少单次请求所花费的时间
这两个优化点直直地指向了我们日常开发中非常常见的操作——资源的压缩与合并。没错,这就是我们每天用构建工具在做的事情。而时下最主流的构建工具无疑是 webpack,所以我们这节的主要任务就是围绕业界霸主 webpack 来做文章。
webpack 优化方案
构建过程提速策略
babel-loader 无疑是强大的,但它也是慢的。
最常见的优化方式是,用 include 或 exclude 来帮我们避免不必要的转译,比如 webpack 官方在介绍 babel-loader 时给出的示例:
module: {
rules: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
}
]
}
除此之外,如果我们选择开启缓存将转译结果缓存至文件系统,则至少可以将 babel-loader 的工作效率提升两倍。要做到这点,我们只需要为 loader 增加相应的参数设定:
loader: 'babel-loader?cacheDirectory=true'
不要放过第三方库
出于对效率的考虑,我们这里为大家推荐 DllPlugin。DllPlugin 是基于 Windows 动态链接库(dll)的思想被创作出来的。这个插件会把第三方库单独打包到一个文件中,这个文件就是一个单纯的依赖库。这个依赖库不会跟着你的业务代码一起被重新打包,只有当依赖自身发生版本变化时才会重新打包。
用 DllPlugin 处理文件,要分两步走:
- 基于 dll 专属的配置文件,打包 dll 库
- 基于 webpack.config.js 文件,打包业务代码
以一个基于 React 的简单项目为例,我们的 dll 的配置文件可以编写如下:
const path = require('path')
const webpack = require('webpack')
module.exports = {
entry: {
// 依赖的库数组
vendor: [
'prop-types',
'babel-polyfill',
'react',
'react-dom',
'react-router-dom',
]
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].js',
library: '[name]_[hash]',
},
plugins: [
new webpack.DllPlugin({
// DllPlugin的name属性需要和libary保持一致
name: '[name]_[hash]',
path: path.join(__dirname, 'dist', '[name]-manifest.json'),
// context需要和webpack.config.js保持一致
context: __dirname,
}),
],
}
编写完成之后,运行这个配置文件,我们的 dist 文件夹里会出现这样两个文件:
vendor-manifest.json
vendor.js
vendor.js 不必解释,是我们第三方库打包的结果。这个多出来的 vendor-manifest.json,则用于描述每个第三方库对应的具体路径,我这里截取一部分给大家看下:
{
"name": "vendor_397f9e25e49947b8675d",
"content": {
"./node_modules/core-js/modules/_export.js": {
"id": 0,
"buildMeta": {
"providedExports": true
}
},
"./node_modules/prop-types/index.js": {
"id": 1,
"buildMeta": {
"providedExports": true
}
},
...
}
}
随后,我们只需在 webpack.config.js 里针对 dll 稍作配置:
const path = require('path');
const webpack = require('webpack')
module.exports = {
mode: 'production',
// 编译入口
entry: {
main: './src/index.js'
},
// 目标文件
output: {
path: path.join(__dirname, 'dist/'),
filename: '[name].js'
},
// dll相关配置
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
// manifest就是我们第一步中打包出来的json文件
manifest: require('./dist/vendor-manifest.json'),
})
]
}
Happypack——将 loader 由单进程转为多进程
大家知道,webpack 是单线程的,就算此刻存在多个任务,你也只能排队一个接一个地等待处理。这是 webpack 的缺点,好在我们的 CPU 是多核的,Happypack 会充分释放 CPU 在多核并发方面的优势,帮我们把任务分解给多个子进程去并发执行,大大提升打包效率。
HappyPack 的使用方法也非常简单,只需要我们把对 loader 的配置转移到 HappyPack 中去就好,我们可以手动告诉 HappyPack 我们需要多少个并发的进程:
const HappyPack = require('happypack')
// 手动创建进程池
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length })
module.exports = {
module: {
rules: [
...
{
test: /\.js$/,
// 问号后面的查询参数指定了处理这类文件的HappyPack实例的名字
loader: 'happypack/loader?id=happyBabel',
...
},
],
},
plugins: [
...
new HappyPack({
// 这个HappyPack的“名字”就叫做happyBabel,和楼上的查询参数遥相呼应
id: 'happyBabel',
// 指定进程池
threadPool: happyThreadPool,
loaders: ['babel-loader?cacheDirectory']
})
],
}
构建结果体积压缩
这里为大家介绍一个非常好用的包组成可视化工具——webpack-bundle-analyzer,配置方法和普通的 plugin 无异,它会以矩形树图的形式将包内各个模块的大小和依赖关系呈现出来,格局如官方所提供这张图所示:
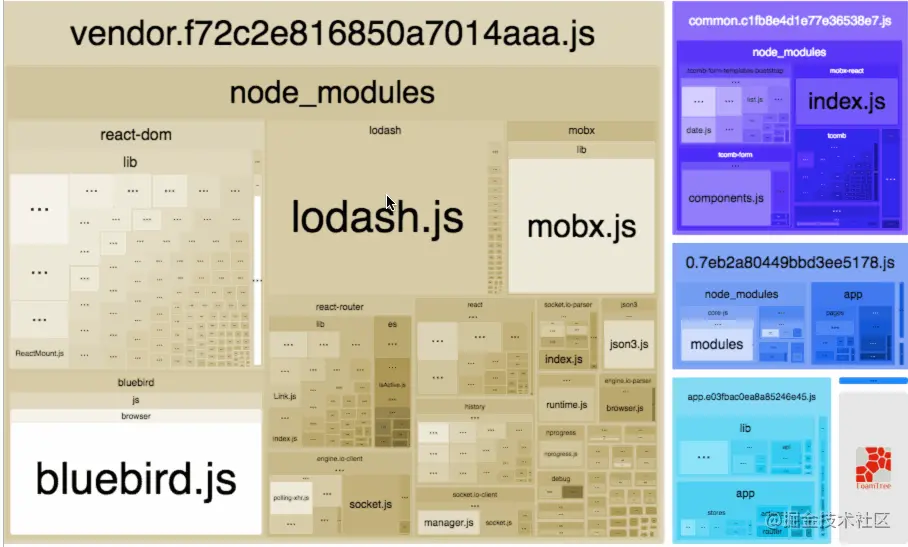
在使用时,我们只需要将其以插件的形式引入:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}
按需加载
按需加载的思想:
- 一次不加载完所有的文件内容,只加载此刻需要用到的那部分(会提前做拆分)
- 当需要更多内容时,再对用到的内容进行即时加载
当我们不需要按需加载的时候,我们的代码是这样的:
import BugComponent from '../pages/BugComponent'
...
<Route path="/bug" component={BugComponent}>
为了开启按需加载,我们要稍作改动。
首先 webpack 的配置文件要走起来:
output: {
path: path.join(__dirname, '/../dist'),
filename: 'app.js',
publicPath: defaultSettings.publicPath,
// 指定 chunkFilename
chunkFilename: '[name].[chunkhash:5].chunk.js',
},
路由处的代码也要做一下配合:
const getComponent => (location, cb) {
require.ensure([], (require) => {
cb(null, require('../pages/BugComponent').default)
}, 'bug')
},
...
<Route path="/bug" getComponent={getComponent}>
小结
说了这么多,我们都在讨论文件——准确地说,是文本文件及其构建过程的优化。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了