数据分析
1.数据分析介绍
2.Anaconda的安装
3.jupyternotebook的用法
4.numpy初识
一.数据分析介绍
1.数据分析是什么:
在我们如今这个时代,相信大多数人都能明白数据的重要性,数据就是信息,而数据分析就是可以让我们发挥这些信息功能的重要手段。
2.数据分析能干什么:
对于数据分析能干什么其实我们可以简单的举几个例子: 1、淘宝可以观察用户的购买记录、搜索记录以及人们在社交媒体上发布的内容选择商品推荐 2、股票可以根据相应的数据选择买进卖出 3、今日头条可以将数据分析应用到新闻推送排行算法当中 4、爱奇艺可以为用户提供个性化电影推荐服务 其实数据分析不仅可以完成像以上这样的推荐系统,在制药行业也可运用数据分析来预测什么样的化合物更有可能制成高效药物等 所以说数据分析绝对是未来所有公司不可或缺的岗位,目前社会上获取数据方式太多了,这么多的数据,只要我们拥有数据分析的技能,绝对可以应付任何岗位上的工作。
3.为什么用python进行数据分析:
1、Python的代码语法简单易学 2、Python可以很容易的整合C、C++等语言的代码 3、Python有大量用于科学计算的库 4、Python不仅可以用于研究和原型构建,同时也适用于构建生产系统
4.数据分析过程概述:
1.提出问题:
在真正的工作场景下,往往我们需要的处理的是多个庞大的数据集还有可能是类型完全不同的数据,
那这个时候一个准确的问题就可以让我们聚集与问题相关的那部分数据,为后续的分析操作提供一个明确的方向,
帮助我们得到一个有意义的结论。
2.整理问题:
整理数据主要分为三步: (1)、收集数据 通过多种途径拿到数据,导入到Jupyter Notebook中 (2)、评估数据 这一步主要是需要找出数据是否存在质量或者结构等方面的问题 (3)、清理数据 通过修改、替换、删除等方式保证数据质量高、结构好
3.搜索性数据分析:
在这一步骤主要可以探索并且扩充数据
4.得出结论:
在进行完探索性数据分析之后肯定会得出一个结果或者说是结论,这样我们就可以根据这样一个结论进行相应的操作,
就比如说分析股票数据得到那个大盘趋势好可以选择买进,又或者说类似于万达这样的大型商场可以分析那种类型的
商品会比较受用户的欢迎,以便针对性的存货。但是具体的操作可能就需要用到机器学习或者推断统计学来实现,
这个就与数据分析不一样了
5.传达结果:
分析的能力有多强,分析的价值就有多大。
这一步主要是向其他人证明你发现的见解以及传达意义
常用库简介:
Numpy Numpy是Numerical Python的简写,主要可以用来做Python数值计算。它提供了多种数据结构、算法以及大部分涉及Python数值计算所需的接口。 快速、高效的多维数组对象ndarray 基于元素的数组计算以及直接对数组执行数学运算的函数 用于读写硬盘上基于数组的数据集的工具 线性代数运算、傅里叶变换,以及随机数生成 用于将C、C++、Fortran代码集成到python的工具 Pandas Pandas使我们进行数据分析的一个主要工具。它所包含的数据结构和数据处理工具的设计使得Python中进行数据清洗和分析非常快捷。pandas一般也是和其他数值计算工具一起使用的,支持大部分Numpy语言风格的数组计算。pandas和numpy最大的区别就是pandas是用来处理表格型或者异质性数据的,而Numpy则刚好相反,它更适合处理同质型的数值类数组数据 matplotlib matplotlib是最流行的用于绘制数据图表的python库。 Scipy Scipy是科学计算领域针对不同标准问题域的包集合。提供了强大的科学计算方法(矩阵分析、信号分析、数理分析等) IPython和Juypyter notebook IPython是一个加强版的Python解释器,Juypyter notebook是一种基于Web的代码笔记本,最初也是源于IPython项目
二.Anaconda的安装
1.Ipython的用法 安装: pip3 install ipython 2.jupyter notebook 俩种安装和启动方式 1.命令行安装: pip3 install jupyter 启动 jupyter notebook 缺点: 必须手动去安装数据分析包 2.anaconda: 就是一个软件 推荐使用第二种方式 优点:包含了数据分析的基础包 大概 200 个左右的科学运算包
搜索Anaconda Prompt 进入终端 执行 conda list 在搜索 Anaconda
三.jupyternotebook的用法
快捷键: 1.运行当前代码并选中下一个单元格 shift+enter 2.运行当前的单元格 ctrl+enter 绿色:编辑模式 蓝色:命令行模式 3.在单元格的上方添加一个单元格,按esc进入命令行模式,接下来按a(above)添加 4.在单元格的下方添加一个单元格,按esc进入命令行模式,接下来按b(below)添加 5.删除一个单元格,按esc进入命令行模式,接下来按dd(delete)删除 6.代码和markdown的切换,按esc进入命令行模式,接下来按m切换
四.numpy初识
numpy简介:
Numpy是高性能科学计算和数据分析的基础包。它也是pandas等其他数据分析的工具的基础,基本所有数据分析的包都用过它。
NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组。它将常用的数学函数都支持向量化运算,
使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循环,放到C语言的运算中,明显地提高了程序的运算速度。
首先需要导入:import numpy as np
1.numpy的优势
#### 有一个购物车, 购物车中有商品的数量和对应的价格, 求总的价格 shop_car = [2,4,6,1] shop_price = [10,20,1,30] shop_car_np = np.array(shop_car) ### ndarray shop_car_np shop_price_np = np.array(shop_price) ### ndarray shop_price_np res = shop_car_np * shop_price_np #### 向量操作 res.sum() ### 求和 l = np.array([1,2,3,4]) l * 3 结果为:array([ 3, 6, 9, 12])
创建ndarray: np.array()
ndarray是一个多维数组列表:
接下就举几个例子
res = np.array([[1,2,3,4], [5,6,7,8]]) res 结果: array([[1, 2, 3, 4], [5, 6, 7, 8]])
常用属性:
| 属性 | 描述 | |
|---|---|---|
| T | 数组的转置(对高维数组而言) | |
| dtype | 数组元素的数据类型 | |
| size | 数组元素的个数 | |
| ndim | 数组的维数 | |
| shape | 数组的维度大小(以元组形式) |
例子:
res = np.array([[1,2,3,4], [5,6,7,8]]) res 1.数组的转换 res.T 结果:array([[1, 5], [2, 6], [3, 7], [4, 8]]) 2.数组元素的数据类型 res.dtype 结果:dtype('int32') 3.数组元素的个数 res.size 结果:8 4.数组对的维度 res.ndim 结果:2 5.以元组的形式展示数组的维度 res.shape 结果:(2,4)
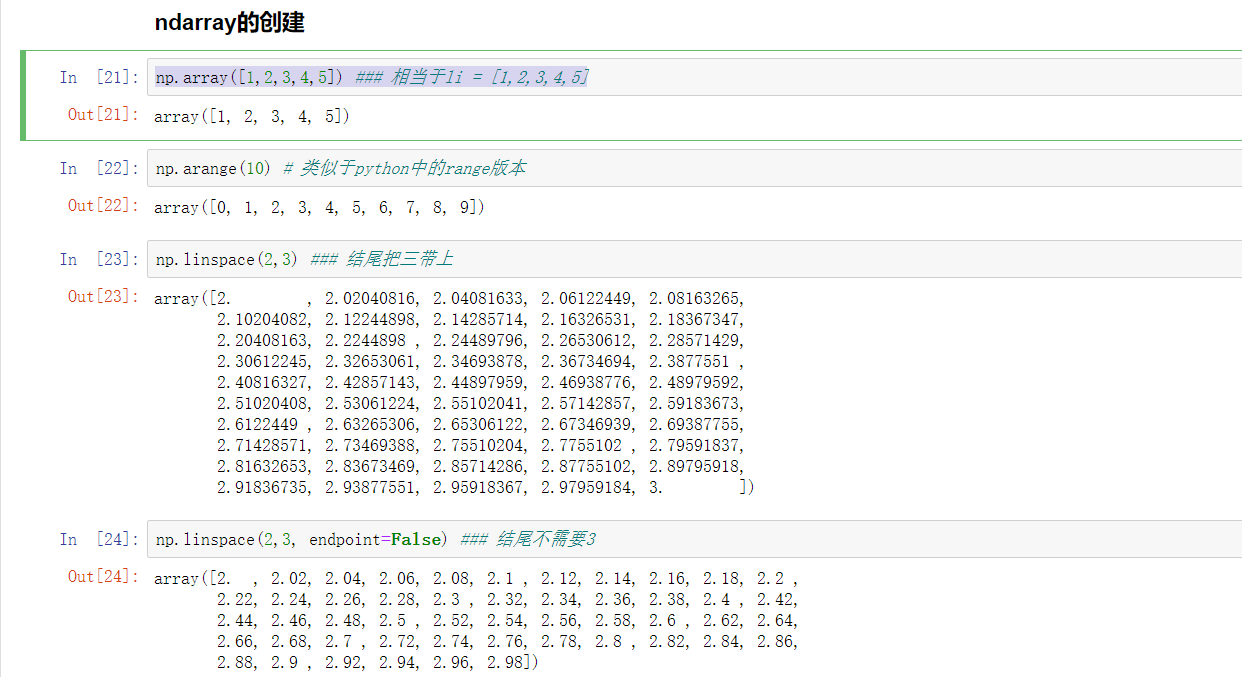
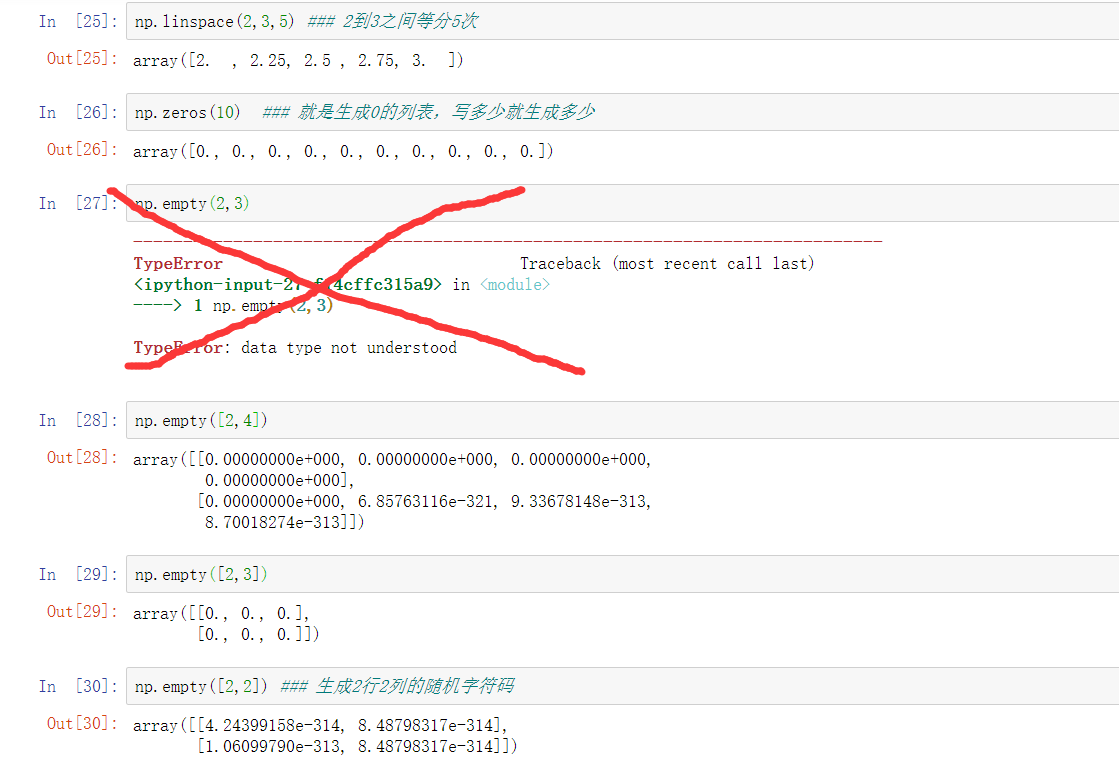
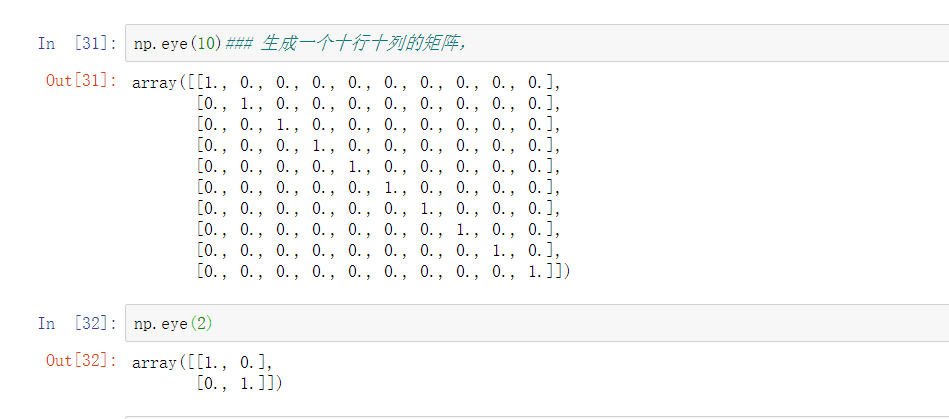
ndarray-创建
| 方法 | 描述 | |
|---|---|---|
| array() | 将列表转换为数组,可选择显式指定dtype | |
| arange() | range的numpy版,支持浮点数 | |
| linspace() | 类似arange(),第三个参数为数组长度 | |
| zeros() | 根据指定形状和dtype创建全0数组 | |
| ones() | 根据指定形状和dtype创建全1数组 | |
| empty() | 根据指定形状和dtype创建空数组(随机值) | |
| eye() | 根据指定边长和dtype创建单位矩阵 |
案例