
HBase架构
HBase Architectural Components
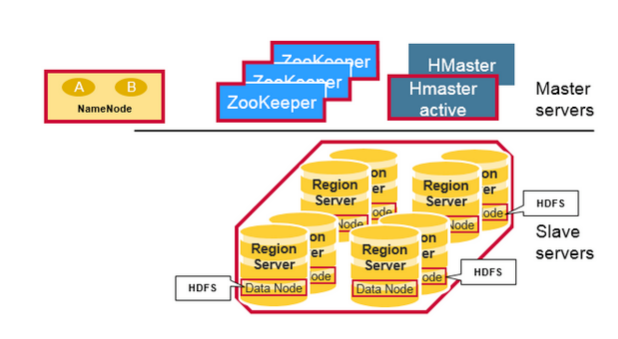
HBase 的主从结构主要由三部分组成。Region Server 用于服务数据的读写,当访问数据时,客户端直接与 HBase RegionServer 交互。Region 的分配(region assignment),DDL(create,delete tables)的操作由 HBase Master 处理。Zookeepr,作为HDFS的一部分,用于维持一个活跃的集群状态。
Hadoop DataNode 存储了Region Server 管理的数据。所有的HBase 数据存储在 HDFS文件里。Region Servers 与 HDFS DataNodes 搭配组合,可以让 RegionServers 的数据实现 data locality(将数据靠近最被需要的地方)。HBase 数据在被写入时是本地化的,但是当 region 被移动后,直到它被 compaction 之前,仍然不是本地化(local)的。
NameNode 维护所有由文件组成的物理数据块的metadata 信息
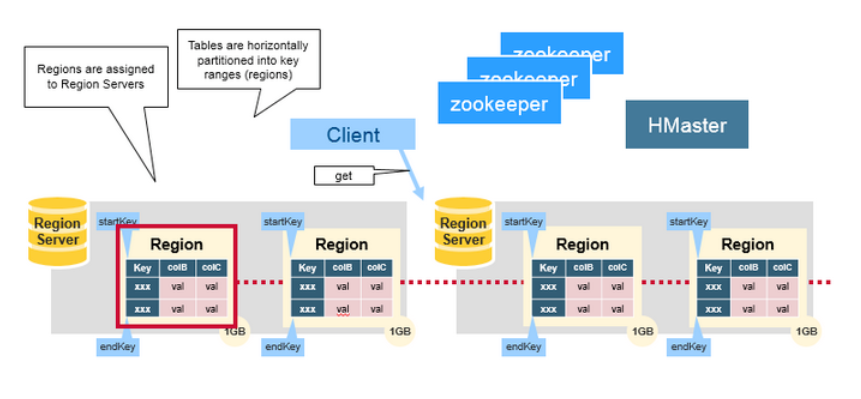
Regions
HBase 表被水平的分发到各个 Regions 中,分发的规则由行键的范围定义。每个Region 里存储的表中的内容为:region’s start key 到 region’s end key 范围内,表中所有的行。Region 被分配到集群里的节点上,这些节点被称为 Region Servers,它们用于服务数据的读写。一个 Region Server 可以服务大约 1000 个region
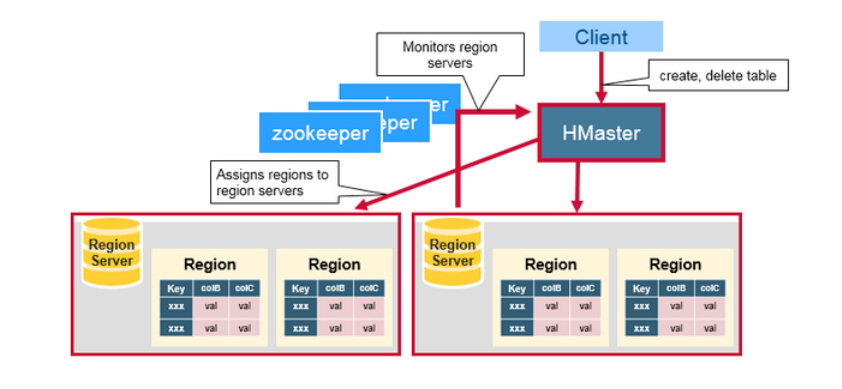
HBase HMaster
Region的分配,DDL(create,delete tables)操作由 HBase Master 完成。
一个 Master 用于:
- 协调 region servers
- 在启动时(startup)分配regions,为了恢复(recovery)或负载均衡的目的做region的重分配
- 监控集群里所有regionserver 实例(监听来自zookeeper的通知)
- 提供管理的接口
- 提供 creating,deleting,updating表的接口
ZooKeeper:协调者
HBase 使用 Zookeeper 作为分布式的协调服务,用于维护集群里服务器的状态。Zookeeper 维护了哪个server 是活跃的、可用的,这部分信息。并提供了 server failure 的通知。Zookeeper 使用 consensus(共识、一致同意)来保证公共共享状态。不过值得注意的是,需要有3或5台机器(单数)用于 consensus

组件之间如何协调工作
Zookeeper 用于给分布式集群里的成员协调共享的状态信息(coordinate shared state information)。Region servers 以及当前活跃的 HMaster 与Zookeeper之间通过session 连接。Zookeeper 维护瞬态节点,并通过心跳检测获取当前活跃的sessions
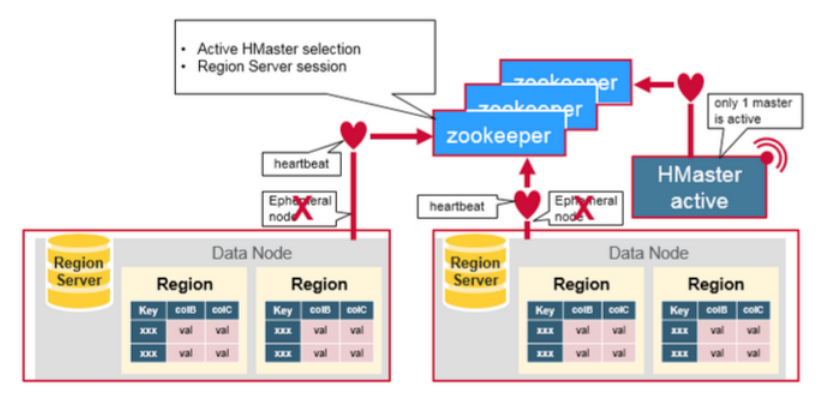
每个 Region Server 创建一个瞬态节点(ephemeral node),HMaster监控这些节点,以发现可用的regions server。同时,它可以会监控这些节点的服务器 failure。
多个HMasters 会竞争创建一个瞬态节点。Zookeeper 会认定并确认第一个节点为唯一的活跃 master。活跃的 HMaster 向Zoodeeper发送心跳,同时inactive HMaster会监听 active HMaster 的错误。
如果一个region server或是active HMaster 发送心跳失败,则它当前的 session会过期,并且对应的ephemeral node 会被删除。此时监听者会收到这些被删除的节点的通知,具体的说:由于active HMaster 监听regions servers,所以在regions servers 挂掉后,会做 recover region servers的操作。而 Inactive HMaster 监听 active HMaster 的错误,所以如果一个 active HMaster 失败,则inactive HMaster 会成为 active。
HBase First Read or Write
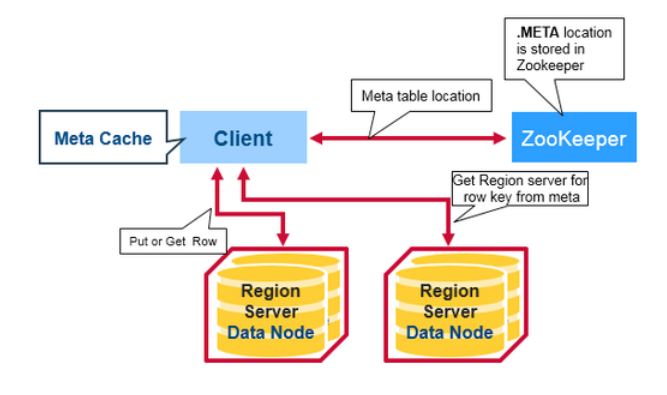
HBase 中有个特殊的目录(Catalog) 表,称为META table,它保存集群里所有regions 的位置信息。Zookeeper保存META table的位置信息。
当一个客户端对 HBase 进行第一次读或写实,会发生以下过程:
- 客户端从Zookeeper 获取存放了META table 的Region server 信息
- 客户端query .META. server,根据需要访问的行键范围,从 .META. server获取存储对应行键范围的region server。客户端将这个信息以及META table的位置信息加入缓存
- 从对应的 Region Server 获取对应行信息
对于之后的读操作,客户端使用缓存获取 META的位置,以及之前访问过的行键。随着时间的推移,客户端可以不需要query META 表,除非在访问时返回 miss(由于region被移动),然后客户端会 re-query 并更新缓存
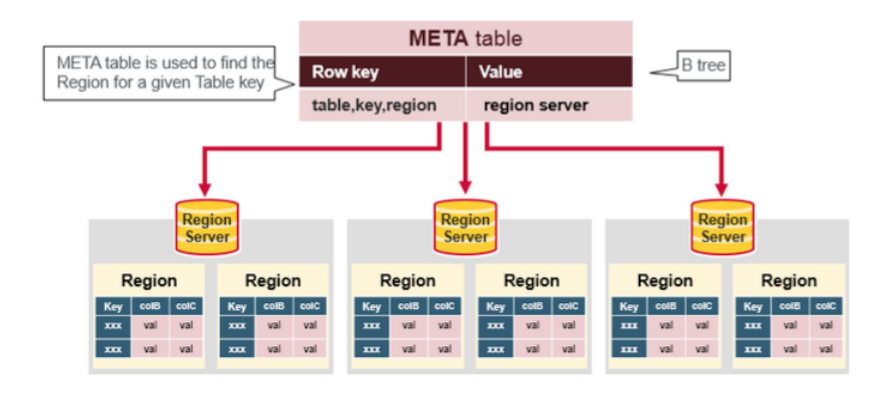
HBase Meta Table
- META table 是一个 HBase 表,保存系统里所有regions的信息
- .META. table 像一个 B-树
- .META. table 结构如下:
- Key:region 的start key,region id
- Values:RegionServer
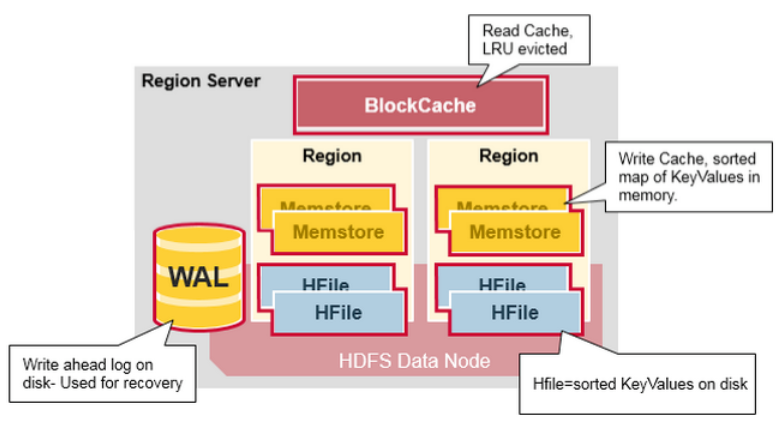
Region Server 组件:
一个 Region Server 运行在一个 HDFS data node,并拥有以下组件:
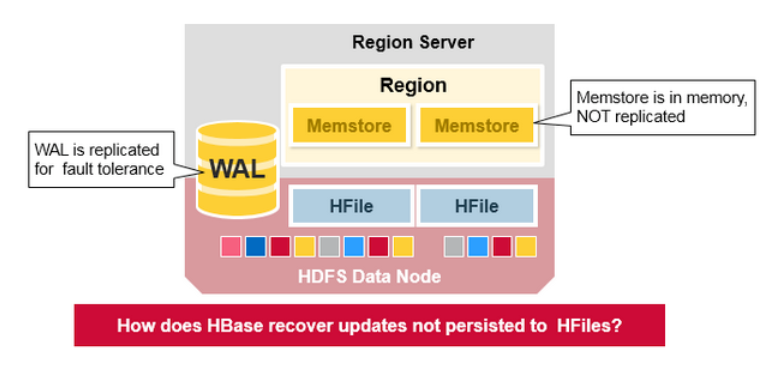
- WAL:预写日志(Write Ahead Log)是存在分布式文件系统里的一个文件。WAL 用于存储还没有被持久化到永久性存储的新数据。也被用于在发生failure时做recovery
- BlockCache:读缓存。它存储最频繁被读取的数据在内存中。在缓存满后,最长时间未被访问的数据(Least Recently Used)会被替换掉
- MemStore:写缓存,它保存所有尚未写入到disk 的新数据。新数据在被写入到disk 之前会先存储到MemStore。每个region下的每个列族(column family)会有一个 MemStore
- HFile:保存行(rows),以排序好的 KeyValues 形式,保存在disk
HBase 写步骤(1)
当客户端发起一个Put请求时,第一步是将数据写入到 write-ahead 日志(WAL):
- 编辑(edit)操作会被添加到(存储在磁盘上的)WAL 文件的末尾
- WAL用于:在服务器挂掉时,恢复尚未持久化的数据
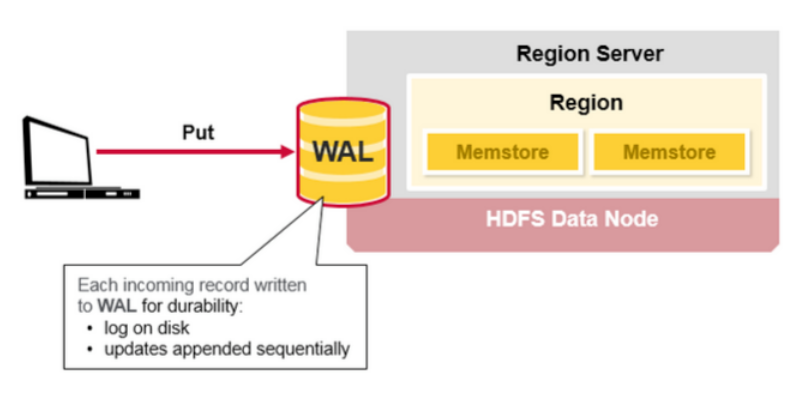
HBase 写步骤(2)
当数据被写入 WAL后,它会被放入MemStore。然后,put 请求会被ack,并返回给客户端。
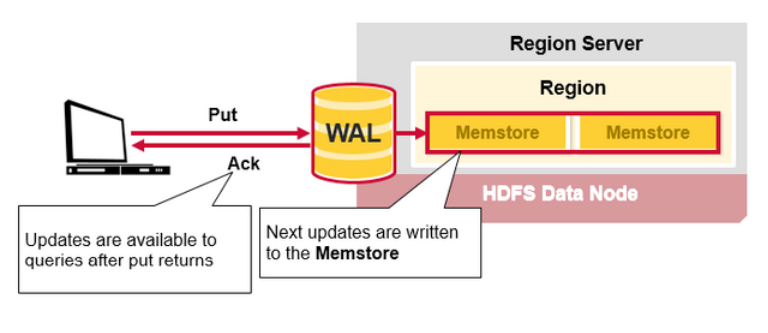
HBase MemStore
MemStore 在内存里存储更新(updates)操作,以排序的 KeyValues 形式(与HFile 存储里形式一样)。每个列族都会有一个 MemStore,更新操作被存储于各个列族中。
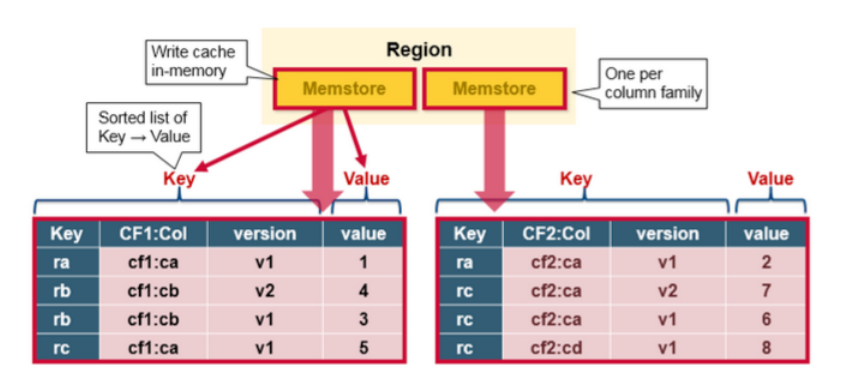
HBase Region Flush
当 MemStore 聚集了足够的数据时,整个排序好的数据会被写入到HDFS 里的一个新HFile中。HBase对每个列族使用多个HFile,它们包含真正的数据单元(或 KeyValue 实例)。这些文件随着MemStores 里不断增加的 KeyValue 编辑操作后,作为文件被flushed 到磁盘
值得注意的是,这是为什么HBase 里对列族数量有限制的一个原因。每个列族都会有一个MemStore,当一个已经满时,它们所有的都会被flush。它也会保存最后一次写的序列号,以此让系统得知当前持久化的进度。
最高的序列号(sequence number)被作为一个meta field 保存在每个 HFile 中,以此反应持久化终止在哪,并应从哪里继续。当一个region 启动后,序列号会被读取,然后最高的会被用于最新编辑操作的序列号。

Hbase HFile
数据被存在HFile,格式为排好序的 Key/Values。当MemSotre聚集了足够的数据,整个sorted KeyValue set 会被写入到HDFS上的一个新的HFile。这个是一个顺序写的过程,非常快,因为它避免了移动 disk drive head

HBase HFile 结构
一个 HFile 包含多层的索引,允许HBase 在不读取整个文件的情况下找到数据。这个多层索引有类似B-数的结构:
- Key-Value pair 以增序存储
- 索引指向的行键,行键以及行键指向的键值数据存储在 64KB 的块中
- 每个块有它自己的leaf-index
- 每个块的最后一个key被放在intermediate index
- Root index指向intermediate index
Trailer 指向 meta blocks,并被写在持久化数据的末尾。Trailer 也有如bloom filters 信息以及 time range 信息。Bloom filters 帮助跳过那些不包含特定行键的文件。如果某些文件不在读请求的 time range 中,Time range 信息对跳过这些文件非常有用。

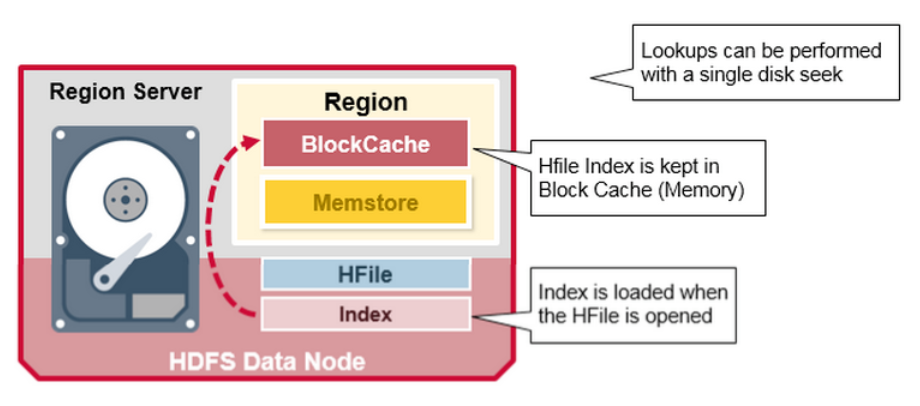
HFile 索引
在HFile 被打开时,索引会被载入并保存在内存。它允许查询在一个磁盘搜索操作内完成
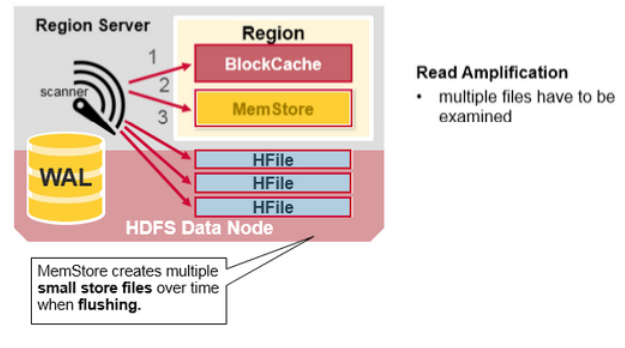
HBase 读聚合(Read Merge)
我们已经知道一个行的KeyValue cells 会被存储在多个地方,row cells 已经被持久化到 HFile,最近被更新的 cells在MemSotre,并且最近被读过的 cells 会在 Block Cache。所以当读某一个行时,系统如何得到对应的 cells 返回?一个读操作会从 block cache,MemStore以及HFile聚合 Key Values,步骤如下:
- 首先,Scanner会在Block Cache 搜索 Row cells。最近被读过的 Key Values 被缓存到这,并且,如内存需要,最常时间未使用的会被替换掉
- 然后 scanner会在 MemStore 里搜索,write cache里保有最近的写操作
- 如果scanner没有在MemStore以及Block Cache里找到所有的row cells,则HBase会使用Block Cache 索引以及bloom filter 加载HFiles 到内存,这些Hfiles可能包含目标的row cells
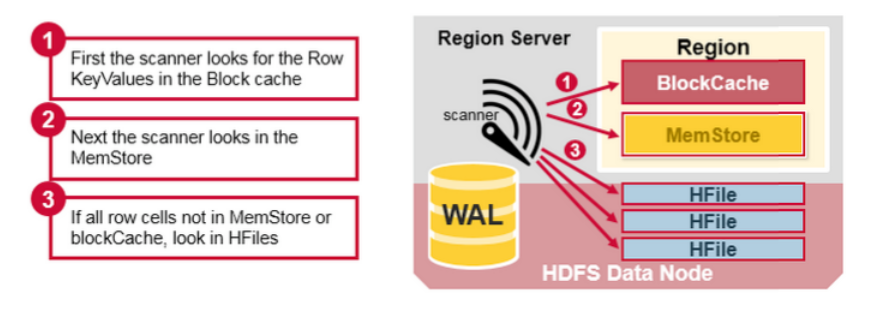
正如之前提到过的,每个MemStore可能会有多个HFiles,即是说:对于一个读操作,可能需要检查多个文件,并继而影响performance。这个被称为读放大(read amplification)
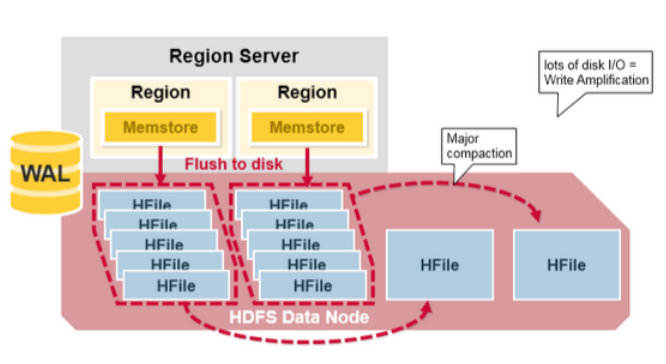
HBase Major Compaction(Major 压缩合并)
Major 压缩合并将一个 region 中一个列族的若干个HFile 重写为一个新 HFile。在这个过程中,major 合并能扫描所有的键/值对,顺序重写全部的数据,重写数据的过程中会略过做了删除标记的数据。对于那些超过版本号限制的数据以及生存时间到期的数据,在重写数据时也不再写入磁盘。这个可以提高读的performance,但是,因为major compaction 会重写所有的文件,在这个过程中会产生大量的disk I/O 以及网络流量。这个被称为写放大(write amplification)。
Major compaction可以被设置为定时自动运行。由于写放大的原因,major compaction经常被计划到晚上或压力小时运行。一个 major compaction也会让那些存储在远程的文件(由于server failure或 load balancing的原因)被本地化到当前region server
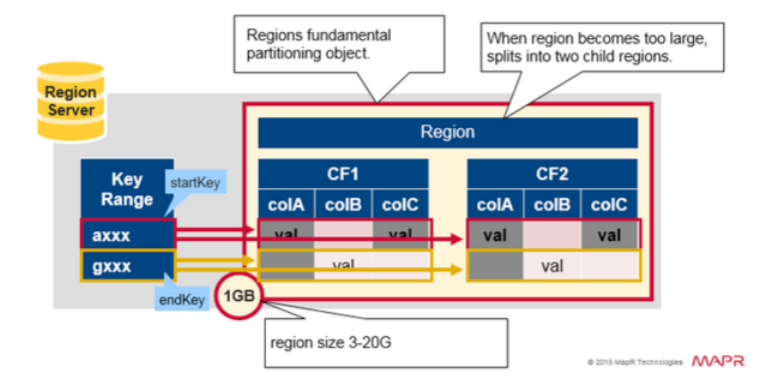
Region = Contiguous Keys
对 regions 做一个快速总结:
- 一个表可以被水平的分配到一个或多个region中。一个region包含相邻的、排序的一组行。范围从start key 到 end key。
- 每个region默认大小是1GB
- 每个表的每个region,由一个region server 提供服务
- 一个region server 可以服务大约 1000 个regions(可能属于同一个表或是不同的表)
Region 分裂(Split)
最开始,每个表都有一个region。当region增大到足够大时,它会分裂成两个子region。两个子region中的每一个,都代表了原region 的一半,并在同一个region server中被并行打开。然后,分裂会被报告给 HMaster。出于负载均衡的原因,HMaster 可能会调度新regions到其他servers。
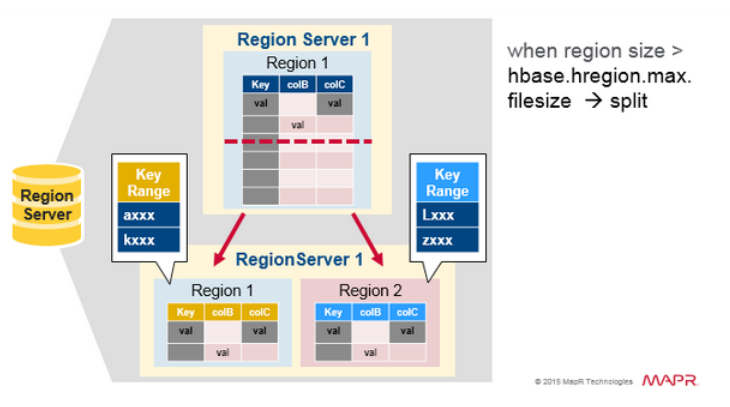
读负载均衡(Read Load Balancing)
刚开始,分裂操作发生在同一个region server,但是出于 load balancing 的原因,HMaster 可能会调度新regions 到其他servers。这会导致:在major compaction 移动数据文件到region server 本地之前,新region server 会从remote HDFS 节点提供数据访问服务。HBase 的数据在被写入后会是在本地,但是当一个region被移动到其他节点后,在major compaction之前,这部分数据不再是本地。

HDFS 数据复制
所有的写操作以及读操作会访问主节点。HDFS 会复制WAL 和 HFile 数据块。HFile 块的复制会自动运行。由于HBase 依赖HDFS 存储,所以HDFS提供了数据的安全性。当数据被写入HDFS 后,一个副本会被写入本地,然后它会被复制到第二个节点、第三个节点。
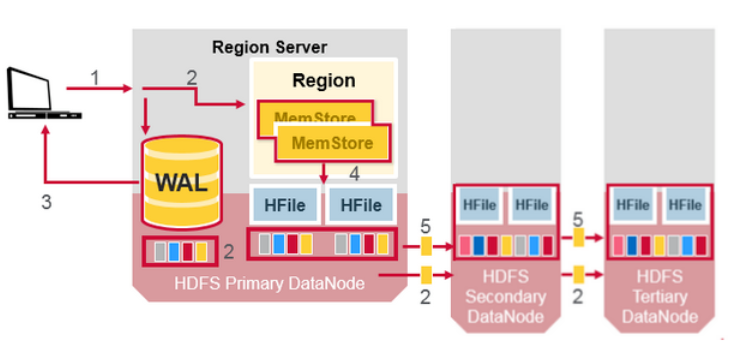
WAL 文件以及HFile 文件被持久化到磁盘并被复制,那么HBase如何恢复那些持久化到HFile 里的 MemStore updates呢?
HBase 故障恢复(Crash Recovery)
当一个 RegionServer 挂掉后,崩掉的Regions 会不可用,直到检测(detection)以及恢复(recovery)步骤发生。Zookeeper在失去 region server 的心跳后,会判定节点失败。然后HMaster会被通知 Region Server 已经失败。
当HMaster 检测到一个region server 已经崩掉,HMaster会从挂掉的server分配regions 到新的、活跃的region servers。为了恢复那些挂掉的region server 中,还没有flushed 到disk 的MemStore edits。HMaster 会将属于此挂掉的region server 上的WAL 分割成分离的文件,并存储到新 region server的数据节点。每个region server 在接下来会重新运行这些 WAL 文件,以重建那个region 的MemStore
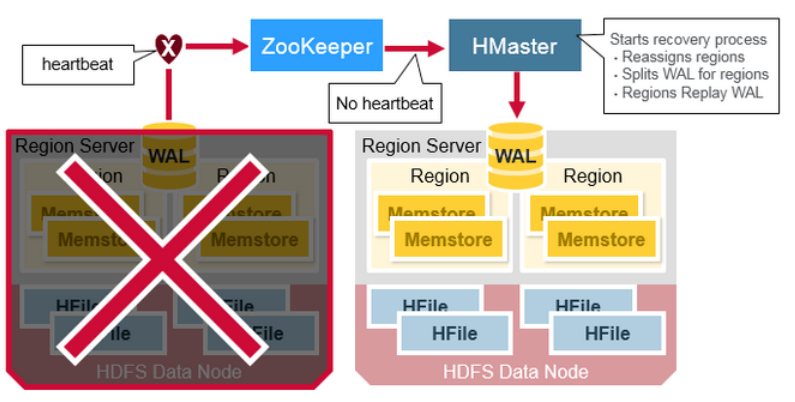
数据恢复
WAL 文件包含了edits 操作的列表,每个 edit操作代表一个put 或 delete操作。Edits 操作按时间顺序写入,所以,对于持久化,新增加的会被添加到WAL 文件的末尾。
当数据仍在memory而没有持久化到HFile之前,若此时报错的话,会发生什么呢?此时WAL 会被重新处理,通过读取WAL文件,添加并整理(sorting)包含的edits到当前的MemStore中。最后,MemStore 会将write changes 内容flush到一个HFile

Apache HBase 架构的优点
HBase 提供了以下优点:
- 强一致性模型:当一个write 请求返回时,所有的reader会获取同一个值
- 自动扩展:
- Region split,当数据增长到足够大时
- 使用HDFS 分布并复制数据
- 内置恢复:使用WAL
- 集成Hadoop
HBase 的问题:
业务持久性可靠性:
- WAL replay 较慢
- Crash 恢复复杂且慢
- Major Compaction I/O 风暴
References:
https://mapr.com/blog/in-depth-look-hbase-architecture/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号