
如何使用 Deepfakes 换脸
如何使用 Deepfakes 换脸
1. 获取deepfakes工具包
git clone https://github.com/deepfakes/faceswap.git
2. 补齐依赖包:
pip install tqdm
pip install cv2
pip install opencv-contrib-python
pip install dlib
pip install keras
pip install tensorflow
pip install tensorflow-gpu(如机器带有gpu)
pip install face_recognition
3.收集样本:
这里我选用的是新垣结衣的样本,费了好半天,下了100张图片:

另外一个人的样本是凯瑞穆里根,由于实在是找图片麻烦,所以直接截取了《The Great Gatsby》里的视频,然后用ffmpeg转化为图片,大概有70张的样子。
3. 面部抓取
在收集完样本后,使用 ./faceswap.py extract –i input_folder/ –o output_folder/ 命令对样本图片进行面部抓取。
做这个的原因是因为我们主要关注的是换脸,所以只需要获取脸部的特征,其他环境因素对换脸的影响并不大。

在面部抓取的过程完成后,我们可以得到所有脸部图片。在此,我们可以人工筛选一下不合适的样本(如下图中的49_1.jpg),将之去除。

4. 面部检测算法HOG:
这里简单提一下脸部特征提取算法HOG(Histogram of Oriented Gradient)。
严格来说,其实HOG是一个特征,是一种在计算机视觉和图像处理中用来进行物体检测的特征描述因子。
HOG特征结合SVM分类器已经被广泛应用于图像识别中。
此处脸部检测的一个简单过程如下:
a. 首先使用黑白来表示一个图片,以此简化这个过程(因为我们并不需要颜色数据来检测一个脸部)。


b. 然后依次扫描图片上的每一个像素点 。对每个像素点,找到与它直接相邻的像素点。然后找出这个点周围暗度变化的方向。
例如下图所示,这个点周围由明到暗的方向为从左下角到右上角,所以它的梯度方向为如下箭头所示

c. 在上一个步骤完成后,一个图片里所有的像素点均可由一个对应的梯度表示。这些箭头表示了整个图片里由明到暗的一个趋势。
如果我们直接分析这些像素点(也就是按色彩的方式分析),那么那些非常亮的点和非常暗的点,它们的值(RGB值)肯定有非常大的差别。
但是因为我们在这只关注明亮度改变的方向,所以有有色图和黑白图最终得到的结果都是一样的,这样可以极大简化问题解决的过程。

d. 但是保存所有这些梯度会是一个较为消耗存储的过程,所以我们将整个图片分成多个小方块,并且计算里面有多少不同的梯度。
然后我们使用相同梯度最多的方向来表示这个小方块的梯度方向。这样可以将原图片转化为一个非常简单的表现方式,并以一种较简单的方法抓取到面部的基本结构。

e. 当计算到一个图片的HOG特征后,可以使用这个特征来对通过训练大量图片得出的HOG特征进行比对。如果相似度超过某个阈值,则认为面部被检测到。

4. 开始训练
在提取两个人脸的面部信息后,直接使用下面命令开始进行模型的训练:
./faceswap.py train -A faceA_folder/ -B faceB_folder -m models/
其中 -m 指定被保存的models所在的文件夹。也可以在命令里加上-p 参数开启preview模式。
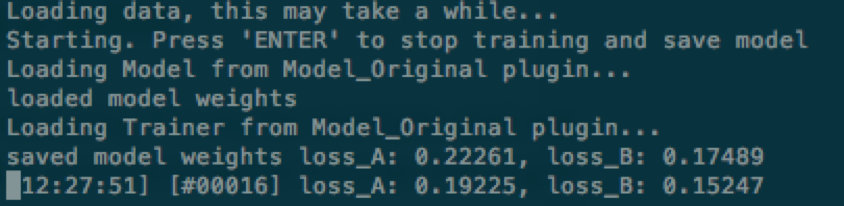
在训练过程中,可以随时键入Enter停止训练,模型会保存在目标文件夹。
训练使用的深度学习框架是tensorflow,它提供了保存checkpoint 的机制(当然代码里必须用上)。
在停止训练后,以后也可以随时使用上面的命令读取之前训练得出的权重参数,并继续训练。
5. 转换人脸
在训练完模型后(损失值较低),可以使用以下命令对目标图进行换脸:
./faceswap.py –i input_images_folder/ -o output_images_folder/ -m models/
此处的例子是找的一个视频,所以我们可以先用下面的命令将一个视频以一个固定频率转化为图片:
ffmpeg –i video.mp4 output/video-frame-%d.png
然后执行转换人脸操作。最后将转换后的人脸图片集合,合成一个视频:
ffmpeg –i video-frame-%0d.png -c:v libx264 -vf “fps=25, format=yuv420p” out.mp4
下面是两个换脸图(样本A 110张图片,样本B 70张图片,训练时间6小时):


嗯…效果不咋样… 建议大家可以增大样本量,并延长训练时间。
6. 转换人脸的过程
下面简单的聊一下转换人脸的过程。
这里用到了AutoEncoder(一种卷积神经网络),它会根据输入图片,重构这个图片(也就是根据这个图片再生成这个图片):

这里 AutoEncoder模型做的是:首先使用encoder将一个图片进行处理(卷积神经网络抽取特征),以一种压缩的方式来表示这个图片。然后decoder将这个图片还原。
具体在deepfakes中,它用了一个encoder和两个decoder。在训练的部分,其实它训练了两个神经网络,两个神经网络都共用一个encoder,但是均有不同的decoder。
首先encoder将一个图片转化为面部特征(通过卷积神经网络抽取面部的细节特征)。然后decoder 通过这个面部特征数据,将图片还原。
这里有一个error function(loss function)来判断这个转换的好坏程度,模型训练的过程就是最小化这个loss function(value)的过程。
第一个网络只训练图片A,第二个网络只训练图片B。encoder学习如何将一个图片转化为面部特征值。
decoder A用于学习如何通过面部特征值重构图片A,decoder B用于学习如何通过面部特征值重构图片B。


所以在训练时,我们会将两个图片均送入同一个encoder,但是用两个不同的decoder还原图片。
这样最后我们用图片B获取到的脸,使用encoder抽取特征,再使用A的decoder还原,便会得到A的脸,B的表情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号