
使用Python访问微信
itchat是一个开源的微信个人号接口,使用它我们可以很方便的访问我们个人微信号里的信息。itchat的github地址如下:
https://github.com/littlecodersh/itchat
在通过 pip install itchat安装此模块后,我们即可以通过使用python访问自己微信号下的信息。
1. 登陆
首先我们需要登陆我们的微信号:
import itchat
itchat.auto_login(hotReload=True)
此处的auto_login()执行后,会下载一张二维码图片,然后通过手机扫描二维码图片后即可登录个人微信。在指定hotReload=True后,此方法会生成一个本地的itchat.pkl文件,用于保存登录信息。之后在一定时间内再次登录时,就不需要再次扫描二维码。
另外一种登录方式为:
>>>itchat.login()
2. 访问微信好友信息
在成功登陆后,我们可以直接获取所有微信好友的信息:
friends = itchat.get_friends(update=True)
print(friends)
通过观察打印出的信息,我们可以发现每个好友的信息均存在一个字典里,这个字典里的key主要有:
'UserName', 'City', 'DisplayName', 'Province', 'Signature', 'NickName', 'Sex'…… 等等。
接下来,我们可以将一些主要的信息存放在几个列表里:
# information
NickName = []
Sex = []
Province = []
City = []
Signature = []
for friend in friends:
NickName.append(friend['NickName'])
Sex.append(friend['Sex'])
Province.append(friend['Province'])
City.append(friend['City'])
Signature.append(friend['Signature'])
dic = {'NickName':NickName, 'Sex':Sex, 'Province':Province, 'City':City, 'Signature':Signature}
然后将它存为DataFrame:
from pandas import DataFrame
data = DataFrame(dic)
如果你更擅长用excel分析的话,可以将它保存为一个excel文档保存到本地:
data.to_csv('data.csv', index=True, encoding='utf_8_sig')
之后可以直接在excel里查看这些信息,如(隐私被处理):
|
City |
NickName |
Province |
Sex |
Signature |
|||
|
0 |
N1 |
X |
|||||
|
1 |
XXX |
N2 |
XXXX |
X |
XXXXX |
||
|
2 |
N3 |
X |
|||||
|
3 |
XXX |
N4 |
XXX |
X |
XXXXX |
||
|
4 |
N5 |
X |
XXXXX |
||||
…
3. 分析信息
在获取了这些信息后,我们可以简单的查看一下,如:
1. 好友里男女比例:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
sexcounts = data['Sex'].value_counts()
sexcounts.plot(kind='pie', autopct='%1.0f%%', pctdistance=0.5, labeldistance=1.2).get_figure()
plt.show()
其中0表示性别未填写,1表示男性,2表示女性
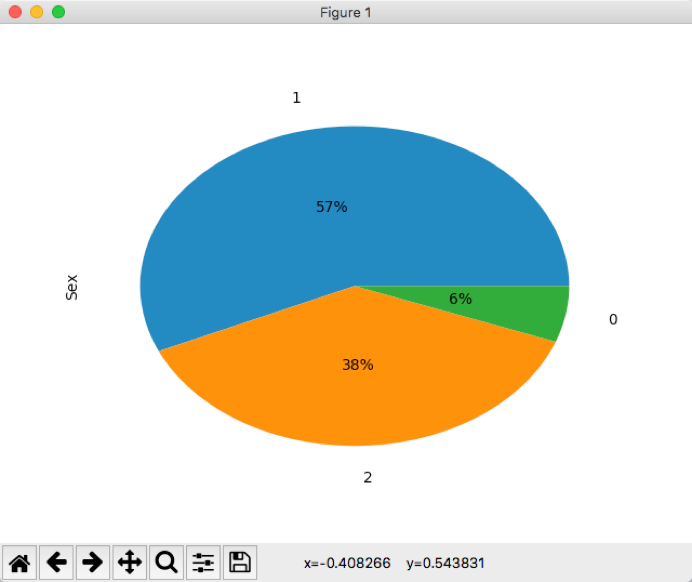
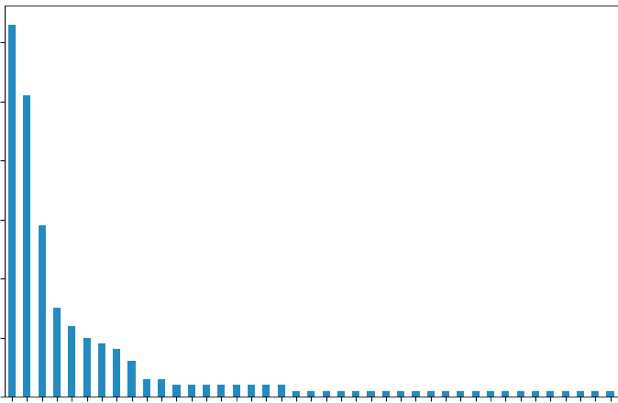
2. 好友里地域分布(其中地域部分未截图):
procounts = data['Province'].value_counts()
procounts.plot(kind='bar').get_figure()
3. 好友签名里的常用词:
首先我们可以将所有签名合并:
text = ''.join(Signature)
由于会有好友在签名里使用表情,所以在文本里会有如下标签
<span class="emoji emoji1f4aa"></span><span class="emoji emoji1f4aa">
这里我们用正则将这些标签去掉:
import re
reg = re.compile('<span .*?>(.*?)</span>')
text = reg.sub('', text)
然后使用jieba这个模块对得到的文本进行分词:
import jieba
wordlist = jieba.cut(text, cut_all=True)
words = ' '.join(wordlist)
最后我们画出词云图:
coloring = np.array(Image.open('w.jpg'))
my_wordcloud = WordCloud(background_color='white', max_words=2000, mask=coloring, max_font_size=60, random_state=42, scale=2, font_path='/Library/Fonts/Microsoft/SimHei.ttf').generate(words)
image_colors = ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
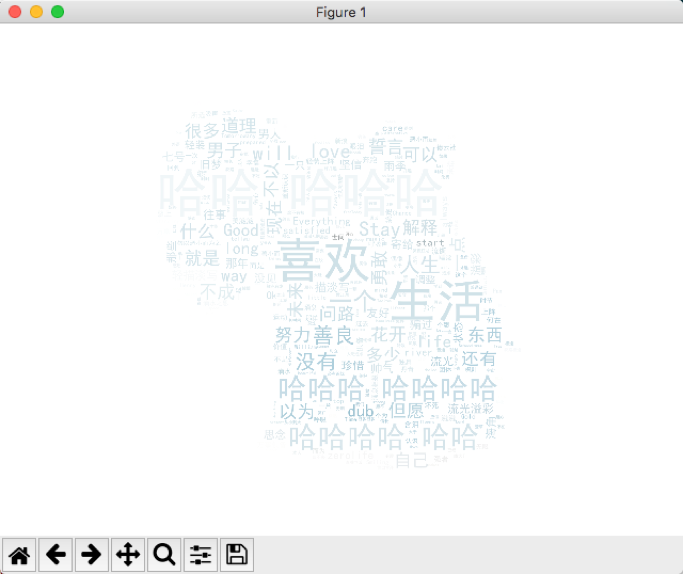
看来大家都是很热爱生活的哇!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号