
Stable Diffusion(二)WebUI使用指南
1. 前言
基于 https://stable-diffusion-art.com/ 内的教程进行翻译与整理,帮助快速上手 stable-diffusion 的使用。
2. 环境
AWS DeepLearning AMI
3. 部署Stable Diffusion web UI
Web UI github:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
SD web UI提供了一站式的SD工具,功能非常全面。
部署:
|
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh) |
|
Model loaded in 14.5s (calculate hash: 11.3s, load weights from disk: 0.2s, create model: 0.8s, apply weights to model: 0.3s, apply half(): 0.2s, load VAE: 1.1s, move model to device: 0.6s). Running on local URL: http://127.0.0.1:7860 |
之后遍自动部署了监听本地7860端口的webui。其中所有相关文件均在stable-diffusion-webui下。
由于需要外网访问,所以需要使用--listen的启动参数:
|
./webui.sh --listen 启动命令参考: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings |
启动后的界面,可以看到默认是v1-5-pruned-emaonly的模型:
3.1. stable diffusion v1-5-pruned-emaonly
根据huggingface的介绍,v1-5-pruned 版本是基于 v1-2 版本fine tune得到,提升了CFG采样:
https://huggingface.co/runwayml/stable-diffusion-v1-5
在介绍文档里,可以看到,权重分为2种:
- v1-5-pruned-emaonly.ckpt - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- v1-5-pruned.ckpt - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
可以看到emaonly的区别在于:它的规模更小,使用更少的显存,适合做推理。而ema+non-ema的规模更大,使用更多显存,适合做调优。
Checkpoint文件就是Stable Diffusion的权重。
4. 添加inpainting模型
可以将下载的Stable Diffusion模型放在目录stable-diffusion-webui/models/Stable-diffusion/ 下。
例如,假设我们要做inpaint的调整。先在huggingface下载stable-diffusion-inpainting的checkpoint:
https://huggingface.co/runwayml/stable-diffusion-inpainting
并存放在stable-diffusion-webui/models/Stable-diffusion/ 下。
而后我们在web UI 刷新checkpoint目录即可:
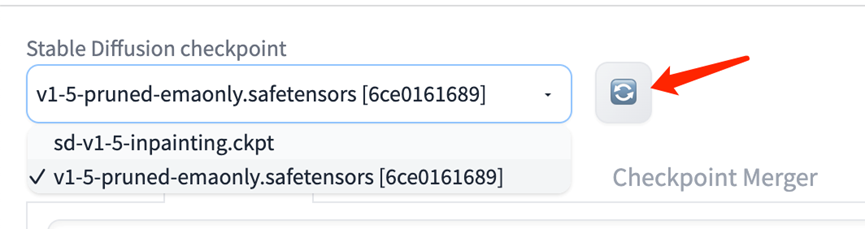
使用时,在 img2img 的 Inpaint 部分上传图片,并使用鼠标进行遮盖。然后输入prompt 词,即可替换遮盖内容。
4.1. inpainting参数解释
在做inpainting时,相关参数解释为:
- Denoising strength:控制最终图片与初始图片的变化程度。设置为0则表示不修改任何东西,设置为1表示大幅修改

- CFG scale:与文生图中的CFG类似,表示生成的图片要follow prompt的程度
- 1:基本忽略prompt
- 3:带些创造性
- 7:创造性与prompt之间的一个较好的平衡
- 15:紧跟prompt提示走
- 30:完全follow prompt
- Masked content:控制覆盖的区域如何初始化
- Fill:使用原图的高模糊图作为初始化
- Original:无修改
- Latent noise:先使用fill的模式对masked区域做初始化,然后再加入随机噪点到latent 空间
- Latent nothing:与latent noise类似,但是不加入随机噪点
下图是sampling之前的Masked content,便于大家理解:

4.2. inpainting技巧
Inpainting是个精细化,需要不断地调整,下面是一些常规的建议:
- 一次做一个较小的区域
- 设置masked content为Original,并调整denoising strength,基本满足90%的场景
- 调整masked content,看看哪个最终效果最好
- 如果webui的所有配置最终都不太好,则先在ps里把目标位置的形状与颜色调好,然后再做inpainting
5. 使用ESRGAN放大结果图片
使用SD模型最终生成的图片大小为512 x 512。一般来说,这种程度是不够清晰的。我们可以使用AI upscaler来放大图片,例如ESRGAN。它是一个独立的工具,用于放大SD模型生成的图片。
例如,对于生成后的图片,可以点击“Send to extras”,然后进入到Extras界面。
而后,即可在界面选择R-ESRGAN 4x+的Upscaler,并进行放大。Resize可选为倍数,例如2倍就是1024 x 1024(原始图为512 x 512)。
5.1. Upscaler常规选项
- l LDSR:Latent Diffusion Super Resolution。是与stable diffusion 1.4共同发布的,专门做SD图片放大的模型。虽然可以生成高质量的放大图,但是速度非常慢,不推荐
- ESRGAN 4x:Enhanced Super-Resolution Generative Adversarial Network。在2018年的Perceptual Image Restoration and Manipulation challenge上获奖的网络。是对前任SRGAN模型的增强。擅长保留很好的细节,并生成清晰的图像
- R-ESRGAN 4x:Real-ESRGAN,是对ESRGAN的增强,可以恢复各种各样的真实世界图片。它对相机镜头和数字压缩产生的不同程度的失真进行建模。相对于ESRGAN,擅长产生更平滑的图片。对于真实照片非常擅长
R-ESRGAN对于真实照片与图片的效果非常好。动画图片的放大需要特定的预训练的模型,才可以工作地更好。可以访问Upscaler model database 下载其他upscaler。
5.2. 安装新的upscaler
安装新的upscaler时,只需要从Upscaler model database下载新的模型并放在文件夹stable-diffusion-webui/models/ESRGAN即可。
6. 安装Stable Diffusion 2.0
SD 2.0 使用了更大的text encoder(可以提升图片质量),并调整默认图片大小为768 x 768像素。
首先在huggingface下载stable-diffusion-2版本:
https://huggingface.co/stabilityai/stable-diffusion-2
并放入目录stable-diffusion-webui/models/Stable-diffusion/ 下:
wget https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt
然后即可在web UI里进行使用。
6.1. 使用SD 2.0
由于SD 2.0 是在 768 x 768 的图片上生成的,所以确保设置的width与height同样为768。一般使用DPM++2M Karras 采样器 + 30个采样步,可以满足大部分场景。
6.2. SD v1与v2版本的区别
在转换SD v1 到v2时,需要注意的点:
- v1生成的图片大小为512 x 512,v2生成的图片大小为768 x 768。虽然v2设计为可以生成512 x 512 以及 768 x 768 的图片,但是早期测试看起来512 x 512的图片不够好
- 不要在v2里复用v1的prompt。在v1里表现很好的prompt可能在v2里不太适用。这个结果也是合理的,因为v2使用了更大的OpenClip H/14的分词器(差不多是v1模型的6倍)。并且是从头开始训练的。
- v2的图片一般更真实。例如“Ink drips portrait”,在v2里更真实,而在v1里更有艺术感
- 如果一定要用v1的prompt,可以使用prompt converter来做转换。它的工作原理是:先用v1的prompt生成图,然后使用CLIP interrogator 2从图中提取prompt词。它可以高效地给出模型如何描述图片的词汇
- 使用更长的prompt(更多的prompt词),以及更明确的描述,在v2里更为适用
总的来说:SD 2.0可以生成更高质量的图片,并更符合prompt词的结果。
7. Fine Tune
Fine tune可以让模型更定制化。对SD模型来说,较为常见的fine tune方式为Dreambooth。Dreambooth最初由谷歌开发,它的原理是将自定义的subject插入到“文生图”的模型中。只需要3-5张的自定义图片即可正常运行。我们可以拍几张自画像,并使用Dreambooth把自己放入模型。使用Dreambooth训练好的的模型需要特定的keyword来告知模型。
另一个并不太热门的调优方法叫textual inversion(有时候也叫embedding)。它的目标与Dreambooth类似:插入一个用户自定义的subject到模型中,同样也只需要少量样本即可。对于新的对象,会创建一个新的keyword。在训练时,仅有text embedding层的网络做fine tune,其他部分保持原样。用外行的话来说,这就像用现有的单词来描述一个新的概念。
使用 Dreambooth 进行 fine-tune,以及使用 LoRA 模型的方式,请参考文档:
Stable Diffusion(三)Dreambooth finetune模型 - ZacksTang - 博客园 (cnblogs.com)
7.1. 调优过的SD模型
有很多模型已经是经过SD fine tune得来,包括SD v1.5。
以下模型均由SD v1调优得来:
l F222:本来是用来训练生成裸体,但是后来发现在生成漂亮女性画像时很有帮助,并且身体部位的关系也非常正确。比较适合生成很美的服装。F222适合肖像画,但是它有较高的倾向生成裸体。可以在提示中包括“连衣裙”和“牛仔裤”等衣服的关键词来避免此情况
下载地址:https://huggingface.co/acheong08/f222/blob/main/f222.ckpt

l Anything V3:专门训练用于生成高质量的动漫风格的图片。可以在prompt里使用danbooru tags(例如lgirl,white hair)。可以用于将名人转为动漫的风格,然后可以无缝地与虚拟元素进行融合。一个缺点是可能会生成不相称的身体结构,一般可以用F222来进行调整
下载地址:https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/anything-v3-fp16-pruned.safetensors

还有些比较有趣的模型:
l DreamShaper:用于人像插画风格,介于照片与计算机图片之间。
模型地址:https://civitai.com/models/4384/dreamshaper

l ChiloutMix:专门用于生成照片级质量的亚洲女性,可以理解为亚洲版的F222。使用韩国embedding ulzzang-6500-v1生成女性(例如k-pop)。与F222一样,容易生成裸体,需要把衣服例如dress,jeans放在prompt里,nude放negative prompt里
模型地址:https://civitai.com/models/6424/chilloutmix

l Waifu-diffusion:日本动漫风格
模型地址:https://huggingface.co/hakurei/waifu-diffusion
有2个地方可以找到更多模型:hugging face与civitai(https://civitai.com)
7.2. SD 2.0问题
在SD v2版本后,社区里发现2.0生成的图片效果不太好。同时也发现名人以及艺术家的名字作为prompt,效果也不太明显。后续在2.1版本里部分解决了这些问题,图片生成的更好了,且更容易生成艺术家的风格。
到目前为止,大部分人还没有完全转移到2.1版本模型,而是仍投入在v1模型的调优中。如果我们希望尝试v2模型,建议先检查这些tips避免遇到一些常规的问题。
8. 模型融合
可以在WebUI的Checkpoint Merger里对两个模型进行融合,例如:
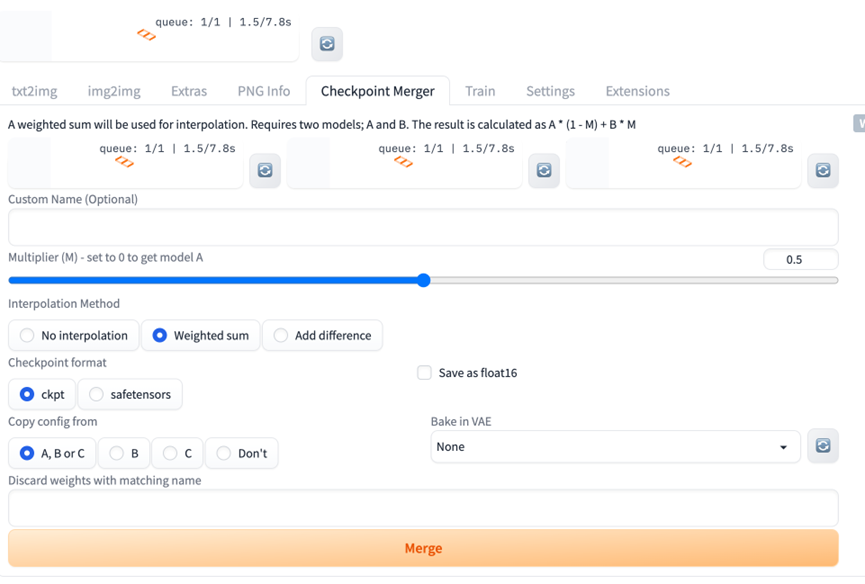
下图是使用F222与Anything V3融合后(权重各位0.5)生成的效果图:

9. 将人转卡通风格
使用2个模型,F222以及Anything V3。
先使用F222模型生成一张人像图,图片大小为512×704,使用prompt:
|
a young female, highlights in hair, sitting outside restaurant, brown eyes, wearing a dress, side light |
Negative prompt:
|
disfigured, ugly, bad, immature |
生成的例如:

然后送往img2img,使用模型anything V,以及prompt词:
|
nvinkpunk A woman sitting outside
|


nvinkpunk(denoising 0.4) Anything V3(denoising 0.5)
这里主要是denoising strength要调整,越高与原图越不符合。
10. 使用VAE提升眼睛与脸的表现
VAE是对Stable Diffusion 1.4 或 1.5的一个部分更新(可以理解为插件),让模型生成人脸中的眼睛效果更好。
10.1. 什么是VAE
VAE = variational autoencoder(变化的自动编码器)。它是神经网络的一部分,用于将图片编码到latent space,以及从latent space中恢复成图片。这么做的目的,是因为latent space空间更小,计算速度更快。
10.2. 我是否需要VAE
我们不需要为SD再安装VAE文件,它们都自带了默认的VAE。
在提到使用VAE时,表示是使用了一个“更优的版本”。一般是模型调优的人使用额外的数据fine-tune了VAE部分,然后替换这部分。
10.2. VAE有什么作用
一般来说,它的作用比较小。一个优化过的VAE可以在将图片从“潜空间”解码时效果更好,可以恢复更多的细节。例如可以有助于渲染眼睛,以及文本(图片里生成的文本)的细节。
Stability AI发布了2个fine-tuned VAE解码器的变种:EMA(Exponential Moving Average)与MSE(Mean Square Error)。这两个本质的含义是用来评估autoencoders好坏的指标。
下面对比了使用不同VAE 产生的结果:
https://huggingface.co/stabilityai/sd-vae-ft-ema#visual

那我们应该使用哪个?根据Stability在256 x 256 图片上做的测试,EMA生成的图片更sharper,而MSE的图片更smoother:
https://huggingface.co/stabilityai/sd-vae-ft-ema#decoder-finetuning
总的来说,EMA与MSE对生成图片的细节(例如眼睛)有帮助,但是对于生成图片上文字的细节帮助有限。
11. Negative Prompt
11.1. Negative Prompt的使用
先看一个negative prompt的例子,使用SD v1.5模型。
首先不用negative prompt 生成图片:
Portrait photo of a man

可以看到都是带胡子的男性。然后我们在prompt里试试把胡子去掉:
Portrait photo of a man without mustache
可以看到,并没有什么用:

这里便是positive prompt里明显的问题,无法排除掉一个特征。其罪魁祸首看起来像是cross attention未将without和mustache两个单词关联起来。而SD模型清楚的明白“man”与“mustache”所代表的含义,因此结果图片包含了这2种特征。
因此,如果要生成没有胡子的男性,则需要把mustache放在negative prompt中。最终生成的图片为:

11.2. Negative Prompt的工作原理
在SD执行流程中,prompt会转为embedding向量,并送入到U-Net noise predictor中。不过,实际上这里会有2组embedding vectors,一个是positive prompt,一个是negative prompt。两者的地位是平等的,都是最高77个token,使用时也可以仅使用其中1个。
Negative prompt是在samplers(采样器,也就是实现反向扩散的算法部分)里实现的。为了理解negative prompts是如何工作的,我们首先看看没有negative prompts时,sampling是如何工作的。
11.3. 没有Negative Prompt时的采样
在SD的采样步骤中,算法首先使用conditional sampling(由text prompt指导)移除图片的一些噪点。然后采样器对同样的图片使用unconditional sampling(也就是不用text prompt指导)移除一些噪点。需要注意的是,扩散过程仍会朝着“好”的图片进展,例如下面的篮球与玻璃的例子,但是可以是任何东西。扩散步骤实际做的是: 在conditional与unconditional采样之间的差别。然后这个过程重复指定的“采样步数”。
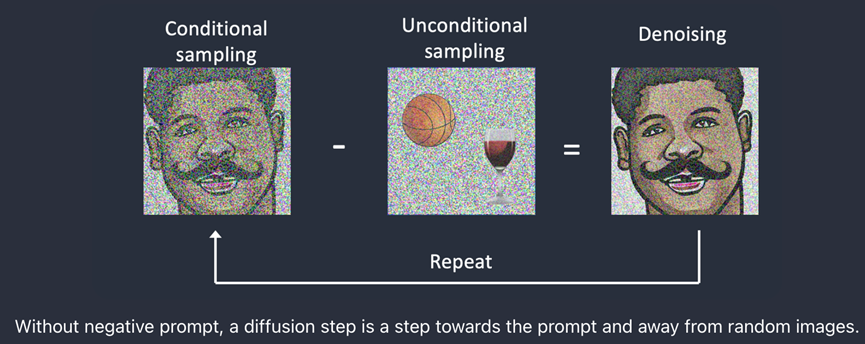
11.4. 使用Negative Prompt时的采样
Negative Prompt实现的方式就是:指定unconditional 采样。使用后,便不再是unconditional 采样,而是使用negative prompt进行采样。
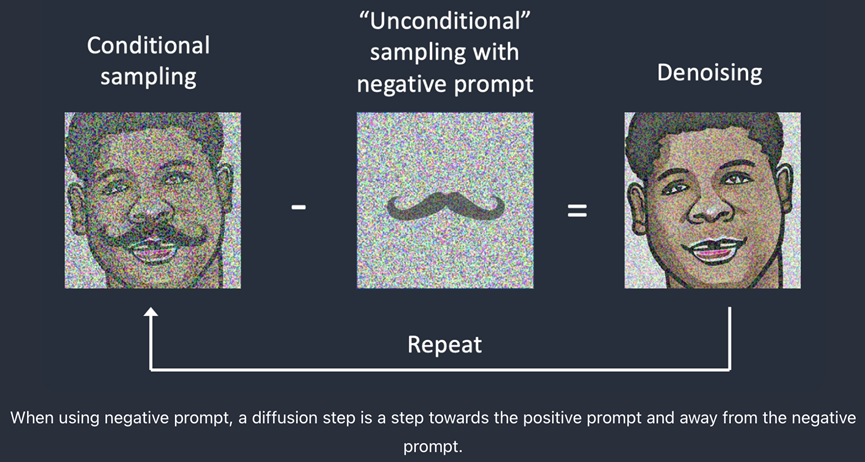
从技术角度看,positive prompts会让扩展过程朝着目标提示词发展,而negative prompts让扩散过程朝着目标提示词原理。需要注意的是,扩散过程发生在latent space,而不是图片本身。上面的图片例子仅为了演示方便。
12. ControlNet
ControlNet也是一个Stable Diffusion模型,可以复制人类的姿势。在ControlNet出现之前,控制模型生成的人类姿势是非常困难的一件事,因为基本上姿势都是随机的。ControlNet解决了此问题。
12.1. 什么是ControlNet
ControlNet是一个修改过的SD模型,它在模型中加入了除text prompt外的另一个condition来实现控制生成的姿势。
下面介绍2个ControlNet例子:1. edge detection;2. Human pose detection
Edge Detection
如下图所示,ControlNet会额外输入一张图片,并使用Canny edge detector检测里面人类的轮廓。检测到的轮廓保存为一个control map,并送入ControlNet模型作为额外的(除text prompt外的)条件:
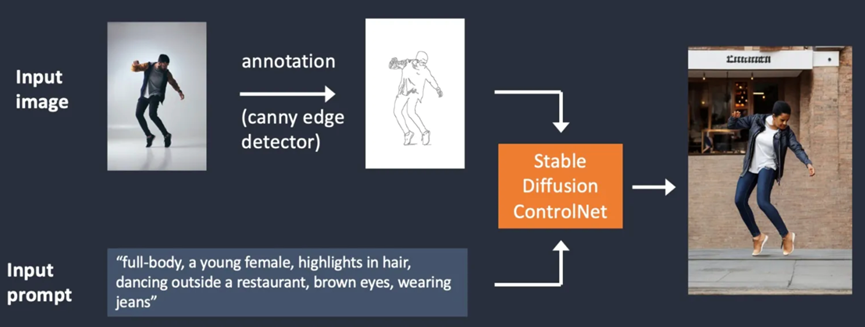
从输入图片中提取特定信息(这个例子里,特定信息便是人类轮廓)的过程称为annotation(注释,原论文里称呼)或preprocessing(预处理,ControlNet插件里称呼)。
Human Pose Detection
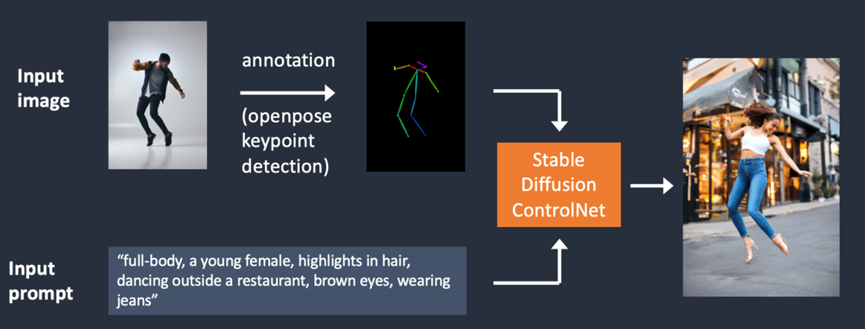
当然,edge detection并非是唯一的图片预处理方法。Openpose是另一种快速的关键点检测(keypoints detection)模型,可以提取人类的具体动作,例如手、腿以及头的位置。如下图所示:

下图是使用OpenPose的ControlNet工作流示意图。使用OpenPose从输入图片中提取关键点,并保存为control map,其中包含了关键点的位置。然后将这部分信息作为额外的conditioning,与文本提示词一起输入ControlNet。模型便会基于这2个条件生成图片:
使用Canny edge detection与Openpose的区别是什么呢?
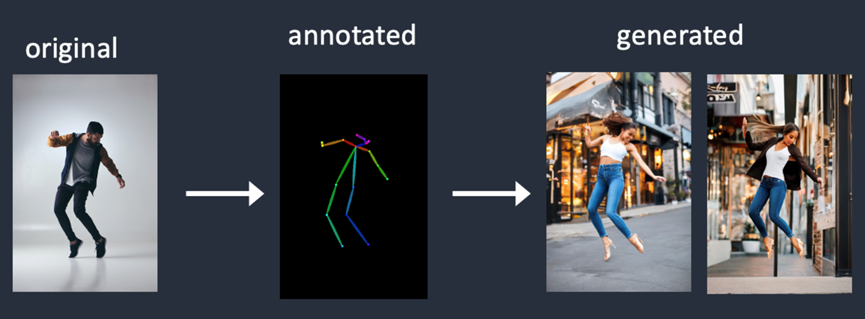
Canny edge detector提取了主体与背景的边缘,倾向于更加真实地呈现场景。在之前的例子中,可以看到跳舞的男人变为了女人,但是轮廓和发型是类似的。
Openpose仅检测关键点,所以图像的生成更自由,但是会遵循原始姿势。在上面的例子中,生成了一位跳跃的女人,但是脚的方向与原图是有区别的。
12.2. ControlNet能做什么
下面介绍当前ControlNet能够完成的任务包括哪些。
OpenPose Detector
OpenPose检测人类的关键点,例如头、肩、手等的位置。用于复制人类的动作,但其他例如衣服、背景、发型的细节无法复制。
Canny Edge Detector
Canny edge detector是一个常规用途,老派的边缘检测器。可以从图片中提取轮廓信息。适用于保留原始图片的组成成分。
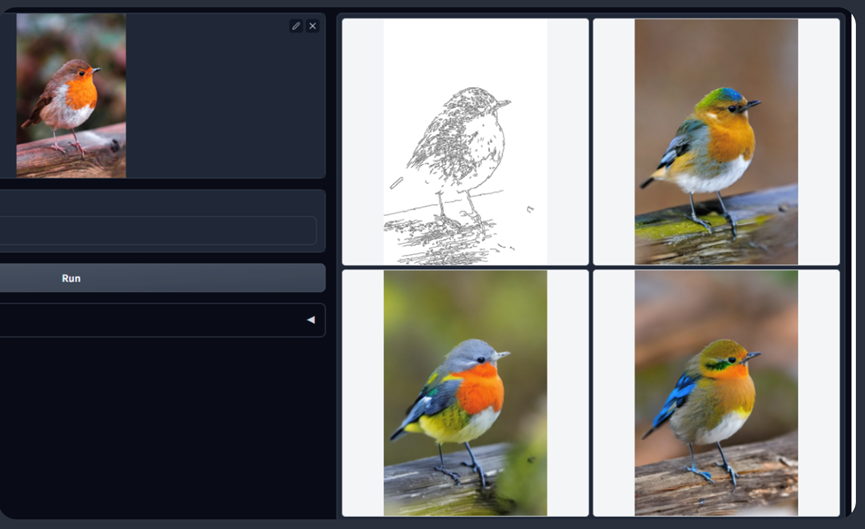
Straight Line Detector
ControlNet也可以与M-LSD(Mobile Line Segment Detection)一起使用,它是一个快速的直线检测器。适用于提取物体的直线轮廓,例如室内设计、建筑、街景、相框和纸张边缘等。
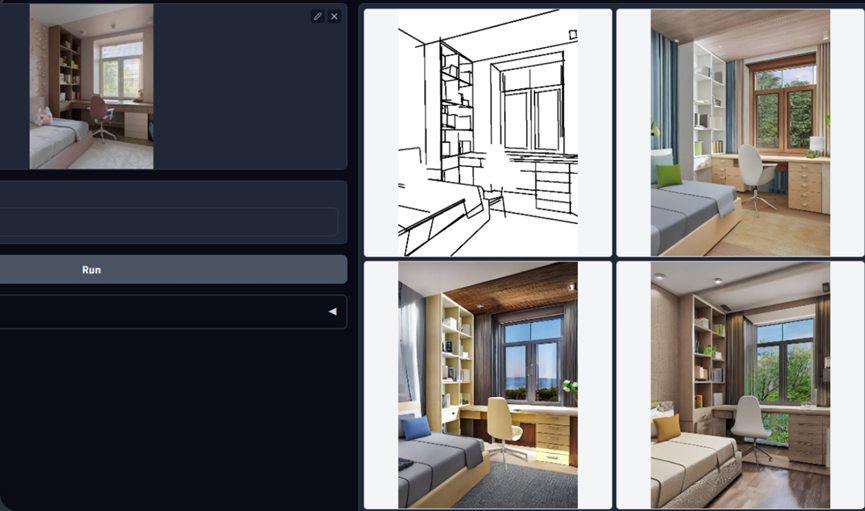
HED Edge Detector
HED (Holistically-Nested Edge Detection) 是一个边缘检测器,擅长于生成实际人类的轮廓。根据ControlNet的作者描述,HED适用于重新上色和重新风格话图像。
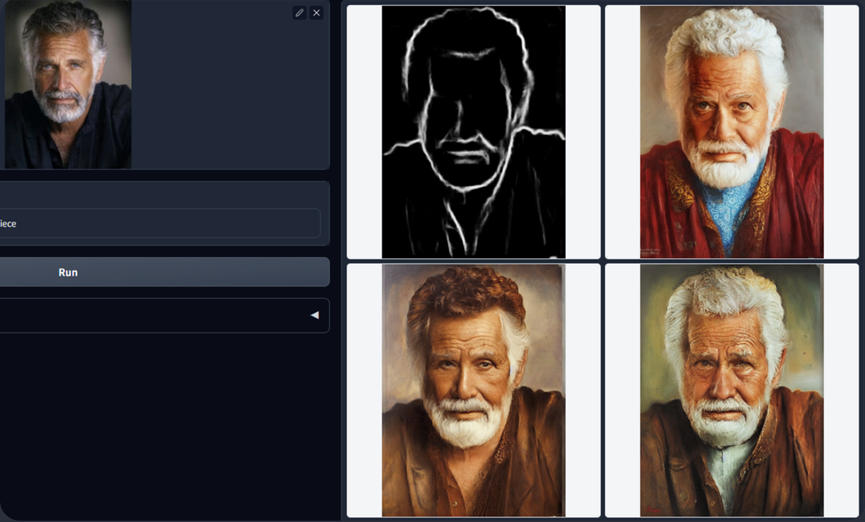
Scribbles
ControlNet也可以将草稿画转为图片:
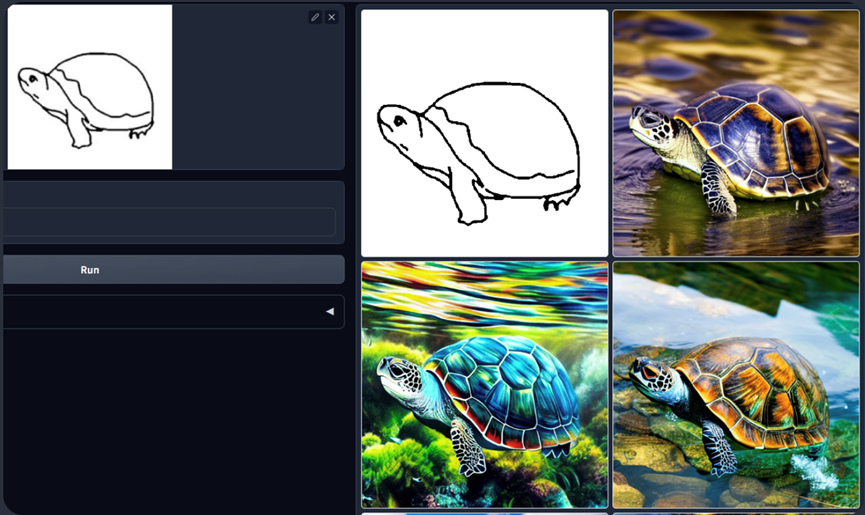
其他模型
更多更新的ControlNet模型用法,可以参考官方github:
https://github.com/lllyasviel/ControlNet#controlnet-with-human-pose
12.3. 安装ControlNet
与安装Dreambooth插件一样,可以在Extensions界面的Available里安装controlnet插件:

安装完毕后重启web UI,即可在txt2img看到ControlNet的tab。
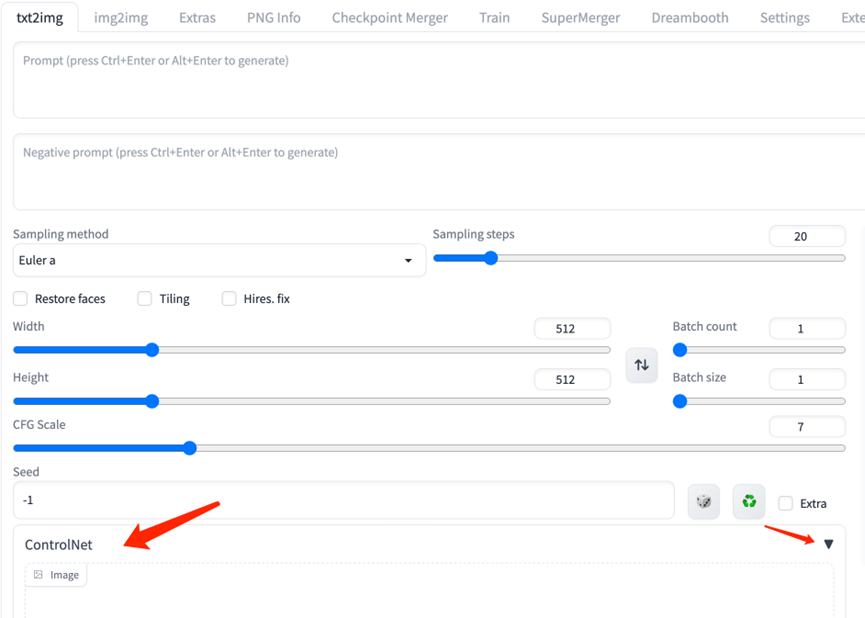
12.4. 使用ControlNet模型
下面我们使用openpose模型进行测试,首先下载模型并放入对应目录:
https://huggingface.co/lllyasviel/ControlNet/blob/main/models/control_sd15_openpose.pth
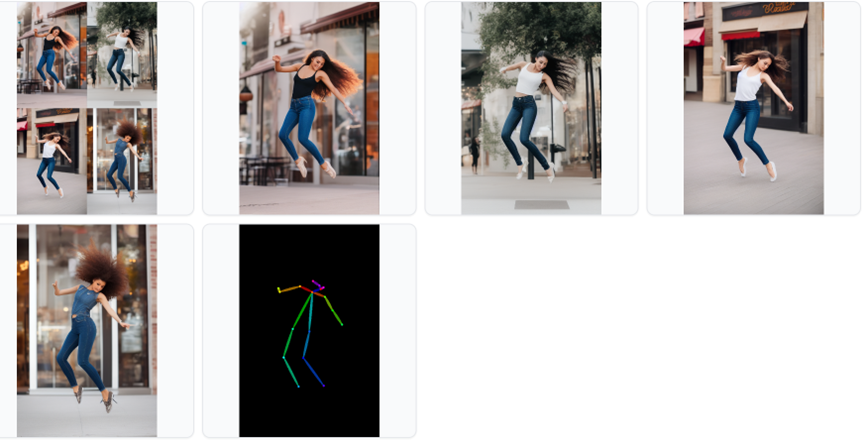
使用的测试图片为:

ControlNet也需要与SD模型一起使用,这里仍然使用的是sd v1-5版本。
在positive prompts输入:
full-body, a young female, highlights in hair, dancing outside a restaurant, brown eyes, wearing jeans
Negative prompts输入:
disfigured, ugly, bad, immature
设置生成图片size为512 x 776。
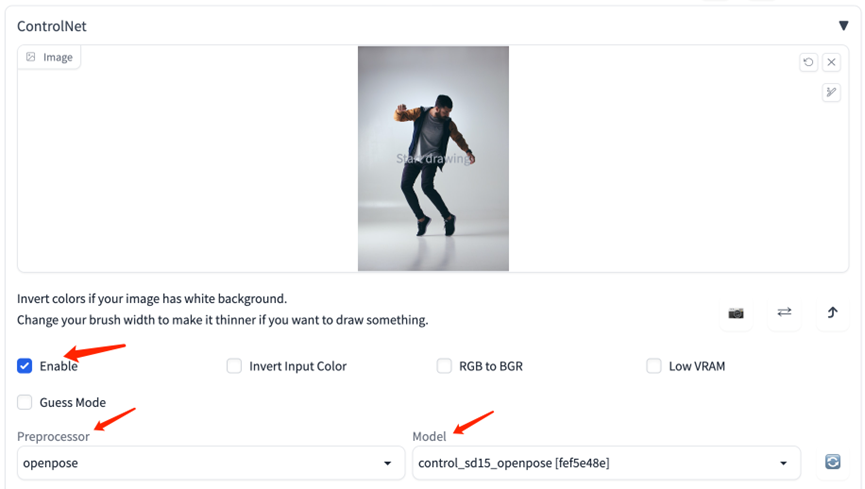
12.5. ControlNet设置
首先上传准备好的图片到ControlNet,选择下面的“Enable”。然后需要选择preprocessor以及model。这里选择openpose以及之前下载的controlnet模型。
然后点击generate即可生成图片,例如:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号