
NLP与深度学习(五)BERT预训练模型
1. BERT简介
Transformer架构的出现,是NLP界的一个重要的里程碑。它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT。
BERT的全称是Bidirectional Encoder Representation from Transformer,如名称所示,BERT仅使用了Transformer架构的Encoder部分。BERT自2018年由谷歌发布后,在多种NLP任务中(例如QA、文本生成、情感分析等等)都实现了更好的结果。
BERT的效果如此优异,其中一个主要原因是:它是一个基于上下文的词嵌入(context-based embedding)模型。我们在之前的文章中(“NLP与深度学习(一)NLP任务流程”)
提到过:
“Word2vec与GloVe都有一个特点,就是它们是上下文无关(context-free)的词嵌入。所以它们没有解决:一个单词在不同上下文中代表不同的含义的问题。例如,对于单词bank,它在不同的上下文中,有银行、河畔这种差别非常大的含义。“
BERT的出现,解决了这个问题。下面我们便从context-based与context-free开始,逐步介绍BERT模型。
2. Context-Based与Context-Free
首先我们介绍一下context-based与context-free这两种词嵌入(Embedding)的区别。
2.1. Context-Free Embedding
看看下面2条句子:
1. He got bit by Python
2. Python is my favorite programming language
作为人类,我们可以很容易分辨这2个句子中单词Python的不同含义。在第1个句子中表示的是蟒蛇,第2个句子中表示的一种编程语言。而如果我们用context-free的词嵌入(例如word2vec)来表示单词Python,则单词Python在上面2个句子中的表示方法都是同一个词向量。也即是说,这样会导致单词Python在2个句子中的含义是一样的。显然,这个在我们实际场景中是不合适的。
这便是context-free embedding的缺点:无论某个单词的上下文语境如何,它都仅有同一种对单词的表示方法。
2.2. Context-Based Embedding
另外一种更好的方式便是Context-Based Embedding,也就是BERT使用的方式。它可以基于单词的上下文,生成不同的词嵌入表示。例如在上面的2个句子中,它就可以根据单词Python所处的上下文,生成对它不同的词向量表示。
以BERT为例,再次回顾上面提到的第1个句子:He got bit by Python。
BERT会将每个单词与句子中所有其他单词计算相关性,据此来理解每个单词的上下文。也就是说,为了理解单词“Python“的上下文含义,BERT会将单词”Python“与其句子中所有其他单词进行关联,了解它们之间的相关性(也就是前文介绍过的multi-head self-attention机制)。所以在第1个句子中,BERT可以通过单词”bit“来理解单词”Python“的含义为”蟒蛇“。如下图所示:

再看第2个句子“Python is my favorite programming language“。同样,BERT会将每个单词与句子中所有单词进行相关性计算,并据此得到每个单词的上下文信息。所以对于单词”Python“,BERT同样会计算单词”Python“与句子中每个单词的相关性,并据此理解单词“Python”的含义。例如,在这个句子中即根据单词“programming“,BERT可以理解到单词“Python”的含义为“编程语言”,如下图所示:

像word2voc、GloVe这种context-free的词嵌入,总是会对单词输出固定的词向量,而忽略了上下文的信息。而BERT这种context-based的方式,可以根据不同上下文,动态生成不同词向量的方法,更符合我们人类对语言的理解(当然,这种动态的表示也是经过了大量样本训练后得出)。最后,BERT在各个NLP任务中的表现,也证实了这种方式是更优秀的。
3. BERT的基本原理
前面提到BERT基于的是Transformer模型,并且仅使用Transformer模型的Encoder部分。在Transformer模型中,Encoder的输入是一串序列,输出的是对序列中每个字符的表示。同样,在BERT中,输入的是一串序列,输出的是也是对应序列中每个单词的编码。
仍以前面提到的“He got bit by Python”为例,BERT的输入输出如下图所示:
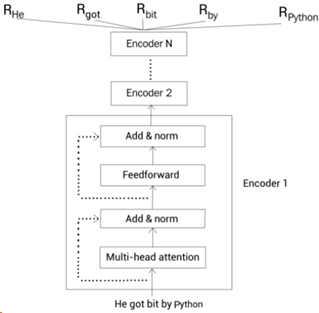
Fig. 1 Sudharsan Ravichandiran. Understanding the BERT Model[1]
其中输入为序列“He got bit by Python”,输出的是对每个单词的编码Rword。这样在经过了BERT处理后,即得到了对每个单词包含的上下文表示Rword。
这便是BERT的基本原理,下面我们介绍BERT的不同配置。
4. BERT的配置
BERT的研究人员提出了2个标准配置的BERT模型:
l BERT-base
l BERT-large
BERT-base用于与其他架构进行对比,并以此衡量其他架构的性能。BERT-large则是用在了论文中对各个NLP任务的结果展示。
下面分别介绍这2个配置的BERT模型。
4.1. BERT-base
BERT-base包含:
- 12个堆叠的encoder层,上一层的Encoder的输出是下一层Encoder的输入
- 每个Encoder使用12-head attention
- Encoder中的前馈网络包含768个隐藏单元(也就是说输出的Rword维度为768维)
使用以下符号表示这几个概念:
- Encoder堆叠的层数表示为L
- Attention的头(multi-head)数表示为A
- 前馈网络的隐藏单元数表示为H
则在BERT-base模型中,L=12,A=12,H=768。模型的总参数个数为1亿1千万(100 million)。BERT-base模型如下图所示:

4.2. BERT-large
BERT-large包含:
- 24个堆叠的Encoder层
- 每个Encoder使用16-head attention
- Encoder中的前馈网络包含1024个隐藏单元(也就是说输出的Rword维度为1024维)
也就是说,在BERT-large模型中,L=24,A=16,H=1024。模型的总参数个数为3亿4千万(340 million)。
4.3. 其他BERT配置
除了上面2种标准配置外,我们也可以使用其他的配置来构建BERT模型。部分较小配置的BERT模型如:
- Bert-tiny:L=2,H=128
- Bert-mini:L=4,H=256
- Bert-small:L=4,H=512
- Bert-medium:L=8,H=512
这些小配置的BERT模型如下图所示:
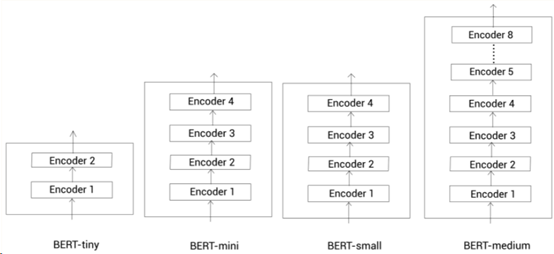
在计算资源有限的场景下,我们可以使用更小配置的BERT模型。不过,最常用的还是BERT-base和BERT-large,它们的准确率也相对小配置BERT模型更高。
在了解了BERT的配置后,下面介绍BERT模型的训练。
5. BERT输入数据的表示
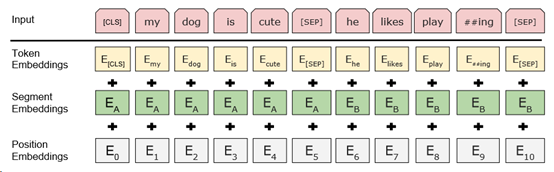
首先需要明确的一个点是:BERT是一个预训练模型。也就是说,它是在大量数据集上进行了预训练后,才被应用到各类NLP任务中。在对BERT模型进行预训练时,与前面介绍过的所有模型一样,输入的文本需要先进行处理后,才能送入到模型中。而在将文本数据输入到BERT前,会使用到以下3个Embedding层:
- Token embedding
- Segment embedding
- Position embedding
下面逐个介绍这3个Embedding 层。
5.1. Token Embedding
Token Embedding就是将一个序列做分词,把序列转为一串单词以及它们对应的词向量。举个例子,假设有2个句子,分别为:
- Beijing is a beautiful city.
- I love Beijing
首先,对2个句子进行分词得到token,结果如下所示:
Tokens = [Beijing, is, a, beautiful, city, I, love, Beijing]
(需要特别注意的是:这里为了方便解释,我们使用了最普遍的分词法为例,而BERT中使用的是WordPiece分词。这种分词方法可以显著减少词库的大小,WordPiece基于的是BPE(Byte Pair Encoding),BPE属于subword分词法中的一种。
有关WordPiece的介绍我们前面已在“NLP与深度学习(一)NLP任务流程”中有过介绍,在此不再赘述。)
然后,我们在最前面加上1个[CLS] 的token,例如:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, I, love, Beijing]
最后,在每个句子的后面分别加上[SEP] 的token,例如:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP]]
这2个特殊的token我们之前(见“NLP与深度学习(一)NLP任务流程” )介绍过:“ [CLS] 、[SEP] 与[PAD] 是BERT Tokenizer中的保留词,分别代表“分类任务”、“Sequences之间的间隔”,以及序列补全(序列补全与截断是NLP任务中常用的方法,用于将不同长度的文本统一长度)。 ”
在做完以上步骤后,在输入到BERT中之前,还需要将每个单词转换为与之对应的词向量。如:
Input:[ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP] ]
Embedding: [ E[CLS], EBeijing, Eis, Ea, Ebeautiful, Ecity, E[SEP], EI, Elove, EBeijing, E[SEP] ]
这样即完成了Token Embedding。
5.2. Segment Embedding
接下来是一层Segment Embedding,用于区分2个给定的句子。仍以上面的2个句子为例。在对这2个句子做了分词处理后,结果为:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP]]
但是,除了[SEP] 外,我们还需要一种方式来告知模型哪个单词属于哪个句子。这也就是Segment Embedding做的事情。在将例子中的Tokens输入到segment embedding后,它仅会输出2种embedding,分别为EA或EB。也就是说,如果单词属于句子1,则输出EA;如果属于句子2,则输出EB。如下所示:
Input: [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP] ]
Segment Embedding:[ EA, EA, EA, EA, EA, EA, EA, EB, EB, EB, EB, ]
如果只有1个句子,则仅输出EA。
5.3. Position Embedding
BERT基于的是Transformer的Encoder,而由于Transformer中Encoder本身不包含Positional Encoding,所以BERT中还需要一层Position Embedding来指示单词在句子中的位置。经过Position Embedding处理后,输出如下所示:
Input: [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP] ]
Position Embedding: [ E0, E1, E2,E3,E4, E5, E6, E7,E8, E9, E10 ]
我们在上一章(见“NLP与深度学习(四)Transformer模型”)介绍Transformer时,提到在Transformer中也有一个Positional Embedding,使用的是正弦曲线的方法:
“在原论文中,作者还提到了另一种位置编码的方法:直接通过训练学习得到位置编码。并且从测试结果来看,两者几乎没什么差别。”
但是在BERT中,作者使用的是“直接通过训练学习”得到的位置编码,但并没有给出具体理由。但是实验上(从Transformer论文中的试验来看)效果应该差不多。
5.4. 输入的最终表示
在将输入序列经过上述3层embedding处理后,将每层embedding的结果进行相加,即得到了输入数据的最终表示,也就是BERT模型的输入。
如下所示:

BERT 论文[5]中的一个例子为:
6. BERT预训练的方法
BERT模型在进行预训练时,基于的是2种类型的任务:
- Masked language modeling(带掩码的语言模型)
- Next sentence prediction(预测下一条句子)
下面会分别介绍这2个任务。不过,在介绍Masked Language Modeling (带掩码的语言模型)任务前,有必要先介绍一下什么是Language Modeling任务。
6.1. Language Modeling
在Language Modeling任务中,我们会给模型输入一个单词序列(句子),并令模型预测这个序列(句子)的下一个单词。这种Language Modeling可以划分为2类:
- Auto-regressive language modeling(自动回归的语言建模)
- Auto-encoding language modeling(自动编码的语言建模)
Auto-regressive language modeling
自动回归的语言建模又可以分为以下2类:
- 前向预测(Forward prediction,从左到右)
- 后向预测(Backward prediction,从右到左)
以“Beijing is a beautiful city. I love Beijing”为例。我们将city单词移除,替换为空,如下所示:
Beijing is a beautiful _. I love Beijing
接下来,我们让模型预测空白位置的单词:
- 如果使用Forward prediction,则模型从左到右读入输入,并做预测,例如:“Beijing is a beautiful _”。
- 而若是使用Backward prediction,则模型从右到左读入输入,并左预测,例如“_ I love Beijing”。
所以Auto-regressive models是单向的,仅从1个方向读入句子。
Auto-encoding language modeling
与Auto-regressive models 不同的是,Auto-regressive models是双向的。也就是说,它会从两个方向均读入句子,并对空白词做预测。例如:
Beijing is a beautiful _. I love Beijing
双向的模型的效果会更好,因为从2个方向读入句子会更有助于理解上下文(例如我们之前介绍过的双向RNN)。
以上便是language modeling的介绍,下面我们继续来讨论BERT中使用的预训练方式——Masked Language Modeling。
6.2. Masked Language Modeling
BERT是一种Auto-encoding 语言模型,也就是说,它是从2个方向读入句子并做预测。在masked language modeling 任务中(也称为填空任务cloze task),对任何一个句子,随机遮挡(mask)其中15%的单词,并训练网络预测这些单词。在进行预测时,模型会从双向读入句子,并进行预测。
仍以“Beijing is a beautiful city. I love Beijing”为例。首先对句子做分词,得到单个单词:
Tokens = [Beijing, is, a, beautiful, city, I, love, Beijing]
然后在最前面加上[CLS],并在每个句子后加上[SEP] 的特殊标记:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP]]
下面对15%的单词做遮挡(mask),假设遮挡的是单词“city”,则使用特殊标记[MASK]替换单词“city”:
Tokens = [ [CLS], Beijing, is, a, beautiful, [MASK], [SEP], I, love, Beijing, [SEP]]
这样即可提供给BERT去做训练了。但是,这种方法会有一个小问题:导致pre-train与fine-tuning之间存在差异。假设我们使用了上述方式去对BERT进行训练,而后再应用到迁移学习fine-tuning中。在预训练的时候,语料库里是有[MASK] 这个标志的,但是在实际的迁移学习中,输入的文本是不包含[MASK]标志的。所以这里会导致pre-train与fine-tuning在使用时有一个gap。
为了解决这个问题,研究人员制定了80%,10%,10%的规则。具体地说,在随机选择了15%的单词被遮挡后,对于这15%的单词,做如下处理:
- 80%的概率将被遮挡的单词替换为[MASK]。
- 10%的概率将被遮挡的单词替换为1个随机单词,例如将上例中的“city”替换为“dog”
- 10%的概率不做任何改变,例如上例中“city”仍然是“city”
这样做的好处是:
- 解决了与fine-tuning的gap问题。80%的遮挡率既应用了[MASK],也有20%的概率不使用[MASK]
- 存在10%的概率不做任何改变,保留了原有语义,让模型可以有机会了解原始数据样貌
- 存在10%的概率替换随机单词,可以使得模型不仅仅依赖于看到过的原始数据,而是还让数据依赖于句子的上下文来预测目标词,达到“纠错”的目的
在对单词序列进行了遮挡处理后,即可送入到BERT模型中进行训练。此时,单词序列会依次进入Token Embedding,Segment Embedding以及Position Embedding,并得到它们的最终表示。整个过程如下图所示:
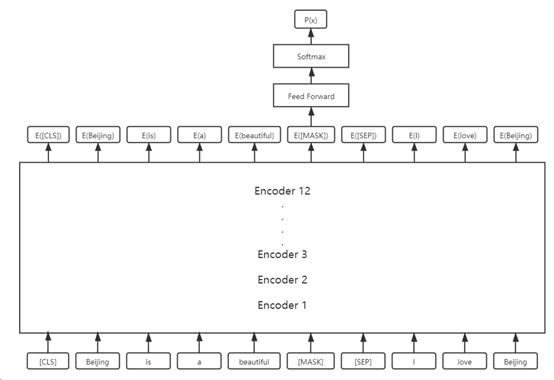
需要注意的是,这里仅需要将E([MASK]) 输入到前馈网络与softmax中即可。因为BERT基于的是multi-head self-attention,所以E([MASK]) 中已经包含了整个句子的信息。
除了以上介绍的这种遮挡单词的方法外,还有另一种稍微不同的方法,称为whole word masking(WWM,全词掩码)。
Whole Word Masking
在介绍WWM之前,首先需要回顾的一个知识点是:BERT中使用的是WordPiece分词法。以句子“let us start pretraining the model”为例,在对一个句子进行分词后,生成的单词为:
Tokens = [let, us, start, pre, ##train, ##ing, the, model]
加上 [CLS] 与 [SEP]:
Tokens = [ [CLS], let, us, start, pre, ##train, ##ing, the, model, [SEP] ]
随机遮挡15%的单词,假设遮挡的单词为 let 与 ##train,则:
Tokens = [ [CLS], [MASK], us, start, pre, [MASK], ##ing, the, model, [SEP] ]
但是这里尤为需要注意的一点是:单词 ##train 实际上仅是单词pretraining 的一部分。在 WWM 方法中,如果遮挡的单词为一个subword,则会遮挡这个subword对应的所有单词,例如:
Tokens = [ [CLS], [MASK], us, start, [MASK], [MASK], [MASK], the, model, [SEP] ]
但是,WWM仍需要遵守“1个句子中仅有15%单词被遮挡”这一规则。所以若是在遮挡 所有subword后,已经达到了这一15%的阈值,则可以忽略其他词(这个例子中就是单词let)的遮挡,例如:
Tokens = [ [CLS], let, us, start, [MASK], [MASK], [MASK], the, model, [SEP] ]
在进行了WWM后,句子即可输入到BERT中进行训练,并让模型预测被遮挡的单词。
6.3. Next Sentence Prediction
Next Sentence Prediction(NSP)是另一个训练BERT的方法,它是一个2分类任务。在此任务中,为BERT模型输入2个句子,需要让模型判断第2个句子是否是第1个句子的下一个句子。例如,准备2个句子Sentence-A和Sentence-B(2个句子合起来为1条训练数据),若Sentence-B是Sentence-A的下一个句子,则这条训练数据的label为isNext。反之为notNext。
在BERT训练中,他需要完成的便是判断Sentence-B是否为Sentence-A的下一条句子。若是,则输出isNext,反之输出notNext。所以这是一个二分类任务。
NSP任务的用途在于:通过NSP任务,可以让模型理解2条句子之间的关系。很多重要的下游任务(例如QA系统、自然语言推理等)都是基于句子之间的关系理解。而这种句子间的关系是无法通过language modeling 学习到的。
在准备训练数据时,可以选取任何单一语言的语料库。假设我们从语料库获取了大量文档。对于isNext类别,仅需要从同一个文档中选取2条连续的句子即可。而对于notNext类别,首先从一个文档选取一条句子,然后从另一个随机文档中选取一条句子即可。一个重要的注意点是:需要确保isNext与notNext的数据条目分别占50%。
在NSP任务中,输入数据的处理方法与前面介绍的一致,在此不再赘述。不过需要提及的一点是:NSP使用的是[CLS] 作为输入的2个句子的代表,输入到前馈网络与softmax中,对结果进行预测。如下图所示:
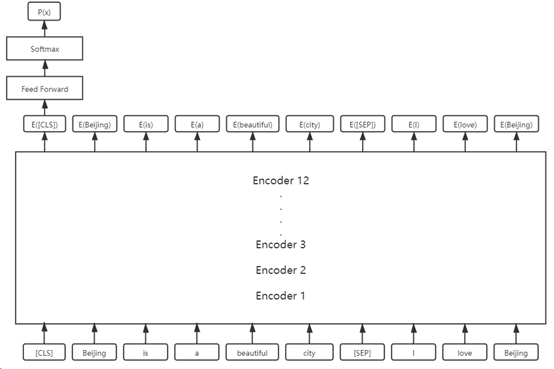
7. BERT预训练的过程
BERT的预训练语料库使用的是Toronto BookCorpus和Wikipedia数据集。在准备训练数据时,首先从语料库中采样2条句子,例如Sentence-A与Sentence-B。这里需要注意的是:2条句子的单词之和不能超过512个。对于采集的这些句子,50%为两个句子是相邻句子,另50%为两个句子毫无关系。
假设采集了以下2条句子:
- Beijing is a beautiful city
- I love Beijing
对这2条句子先做分词:
Tokens = [ [CLS], Beijing, is, a, beautiful, city, [SEP], I, love, Beijing, [SEP] ]
然后,以15%的概率遮挡单词,并遵循80%-10%-10%的规则。假设遮挡的单词为city,则:
Tokens = [ [CLS], Beijing, is, a, beautiful, [MASK], [SEP], I, love, Beijing, [SEP] ]
接下来将Tokens送入到BERT中,并训练BERT预测被遮挡的单词,同时也要预测这2条句子是否为相邻(句子2是句子1的下一条句子)。也就是说,BERT是同时训练Masked Language Modeling和NSP任务。
BERT的训练参数是:1000000个step,每个batch包含256条序列(256 * 512个单词 = 128000单词/batch)。使用的是Adam,learning rate为1e-4、β1 = 0.9、β2 = 0.999。L2正则权重的衰减参数为0.01。对于learning rete,前10000个steps使用了rate warmup,之后开始线性衰减learning rate(简单地说,就是前期训练使用一个较大的learning rate,后期开始线性减少)。对所有layer使用0.1概率的dropout。使用的激活函数为gelu,而非relu。
8. 总结
BERT的一个成功的关键在于:它提供了一个更深层的模型来学习到了一个更好的文本特征,使得它在各类NLP任务上的表现也更精准。当前BERT+迁移学习已经应用在各个实际应用中,例如情感分析、QA系统等。另一方面,研究人员基于BERT也衍生出了很多变种,例如ALBERT、RoBERTa、ELECTRA等等。后续我们会继续介绍BERT的应用以及它的变种。
References
[2] https://www.geeksforgeeks.org/explanation-of-bert-model-nlp/
[3] https://zhuanlan.zhihu.com/p/95594311
[4] https://zhuanlan.zhihu.com/p/366396747
[5] https://arxiv.org/pdf/1810.04805.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号