
ClickHouse介绍(二)MergeTree引擎
MergeTree引擎
ClickHouse中有多种表引擎,包括MergeTree、外部存储、内存、文件、接口等,6大类,20多种表引擎。其中最强大的当属MergeTree(及其同一家族中)引擎。我们在前面的建表例子中也使用了MergeTree引擎。
MergeTree系列引擎,在写入一批数据时,数据是以数据片段(官网称为part)的形式一个接一个地快速写入,且此数据片段无法修改。这些数据片段会在后台按照一定的规则进行合并,避免数据片段过多。相对于在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
相信大家对将数据片段写入的方式不会太陌生,在kafka和ElasticSearch中使用的segment作为数据存储,以及HBase中以HFile作为数据存储,这些方式均采用了以下方式:
- 数据文件只能追加,不能对已有数据进行直接修改(即使是删除,也仅是添加一行记录表示删除标记)
- 为了防止文件数过多,会在后台按照一定规则进行合并
这种设计对于大量写入是非常有益的。
MergeTree的主要特点为:
- 存储的数据按主键排序:这样可以创建一个小型的稀疏索引来加快数据检索
- 支持数据分区:数据分区可以仅扫描指定分区数据,提高性能
- 支持数据副本
- 支持数据采样
1. MergeTree存储结构
MergeTree表引擎中的数据会以分区目录的形式保存在磁盘上,下面我们创建一个分区表,并以此为例,介绍MergeTree的实际数据存储的目录结构。
# 建表 CREATE TABLE partition_v1 ( `ID` String, `URL` String, `EventTime` Date ) ENGINE = MergeTree PARTITION BY toYYYYMM(EventTime) ORDER BY ID # 插入数据 insert into partition_v1 values ('A000', 'www.nauu.com', '2020-04-13'), ('A001', 'www.hello.com', '2021-05-14')
根据clickhouse服务器默认配置,数据默认落盘路径为/var/lib/clickhouse/ 。
在/var/lib/clickhouse/下的 data/ 路径下,我们定位到创建的表的路径,打印当前路径结果为:
# pwd /var/lib/clickhouse/data/default/partition_v1 # ll total 4 drwxr-x--- 2 clickhouse clickhouse 201 Apr 13 06:38 202004_1_1_0 drwxr-x--- 2 clickhouse clickhouse 201 Apr 13 06:38 202105_2_2_0 drwxr-x--- 2 clickhouse clickhouse 6 Apr 13 06:37 detached -rw-r----- 1 clickhouse clickhouse 1 Apr 13 06:37 format_version.txt
需要说明的是:partition_v1 是一个链接文件,指向的是实际存储地址(此地址与system.parts 表里的地址一致)。
可以看到在表下出现了3类文件,分别为:
- 202004_1_1_0:指定的分区路径
- detached:ClickHouse中可以从表detach一个分区,并在后续再attach回表,detach的分区会放入此路径
- format_version.txt:当前格式版本
再往下一层查看分区路径内文件:
# cd 202105_2_2_0/ # ll total 36 -rw-r----- 1 clickhouse clickhouse 256 Apr 13 06:38 checksums.txt -rw-r----- 1 clickhouse clickhouse 79 Apr 13 06:38 columns.txt -rw-r----- 1 clickhouse clickhouse 1 Apr 13 06:38 count.txt -rw-r----- 1 clickhouse clickhouse 99 Apr 13 06:38 data.bin -rw-r----- 1 clickhouse clickhouse 112 Apr 13 06:38 data.mrk3 -rw-r----- 1 clickhouse clickhouse 10 Apr 13 06:38 default_compression_codec.txt -rw-r----- 1 clickhouse clickhouse 4 Apr 13 06:38 minmax_EventTime.idx -rw-r----- 1 clickhouse clickhouse 4 Apr 13 06:38 partition.dat -rw-r----- 1 clickhouse clickhouse 10 Apr 13 06:38 primary.idx
这里面主要介绍的文件有:
- data.bin:实际存储数据的文件,使用压缩格式存储,默认压缩格式为LZ4(由default_compression_codec.txt定义)
- data.mrk3:标记文件,保存.bin 文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与.bin文件一一对应,所以MergeTree通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系。也就是说,先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin 文件中读取数据。
- count.txt:记录统计的行数
- partition.dat 与 minmax_[Column].idx:如果使用了分区键,则会额外生成这2个文件,均使用二进制存储。partition.dat保存当前分区下分区表达式最终生成的值;minmax索引用于记录当前分区下分区字段对应原始数据的最小值和最大值。例如,假设EventTime字段对应的原始数据为2019-05-01、2019-05-05,分区格式为 toYYYYMM(EventTime)。则partition.dat 中的值为2019-05,minmax索引中保存的值为2019-05-012019-05-05。
这里需要特别注意的是,由于测试表中partition_v1仅有2条数据,所以全部数据均在data.bin 文件中。但是在一般情况下,每一列均会有一个对应的[Column].bin、[Column].mrk 文件。
例如我们查看tutorial.hits_v1 表对应的数据目录可以看到:
# ll | grep UserAgentMajor -rw-r----- 1 clickhouse clickhouse 3562335 Apr 12 12:16 UserAgentMajor.bin -rw-r----- 1 clickhouse clickhouse 26280 Apr 12 12:16 UserAgentMajor.mrk2
UserAgentMajor为hits_v1 表中的一个字段(列),它会有单独的数据文件,以及对应的标记文件。
2. 分区目录命名
在上面的例子中,分区表partition_v1 对应的分区目录为:202004_1_1_0 和 202105_2_2_0
对于MergeTree来说,分区路径命名的格式为:PartitionID_MinBlockNum_MaxBlockNum_Level。
以202004_1_1_0 举例,202004表示分区目录的ID;1_1表示最小的数据块编号和最大的数据块编号;最后的_0表示当前合并的层级。
具体解释为:
- PartitionID:也就是分区具体名称(ID)
- MinBlockNum_MaxBlockNum:最小数据块的编号与最大数据块的编号。BlockNum是一个自增的编号,每当新创建一个分区目录时,计数就加1。对于新增加的分区目录,MinBlockNum与MaxBlockNum一致,例如第1个分区为 202004_1_1_0,第2个分区为202105_2_2_0,依次类推。不过当分区目录发生合并时,它们会有不同的取值规则。
- Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄,数字越大表示年龄越大。Level计数与BlockNum不同,并非全局累加。对每个新分区来说,Level初始值均为0。之后若是相同分区发生合并,则相应分区内计数加1
3. 分区目录合并
在MergeTree中,每次写入数据(例如一次INSERT写入一批新数据)时,并非是在已有分区目录里追加文件,而是都会生成一批新的分区目录。即便不同批次写入的数据都数据相同分区,也会生成不同的分区目录。所以,对于同一个分区,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize语句),ClickHouse会通过后台任务,将属于相同分区的多个目录合并为一个新的目录。已经存在的旧分区目录不会立即删除,而是在之后的某个时刻通过后台任务删除(默认8分钟)。
例如,再次向表partition_v1 插入一条数据:
insert into partition_v1 values('A002','www.a02.com','2020-04-13')
查看表下路径:
# ls 202004_1_1_0 202004_3_3_0 202105_2_2_0 detached format_version.txt
可以看到新增加了一个目录202004_3_3_0,虽然插入的是一个已有的分区。
执行OPTIMIZE TABLE partition_v1 后的表下路径:
# ls 202004_1_1_0 202004_1_3_1 202004_3_3_0 202105_2_2_0 detached format_version.txt
可以看到同一分区202004 进行了合并,生成新目录202004_1_3_1,但旧目录并未立即被删除。
通过新生成的目录名,我们可以得知:此分区为202004,MinBlockNum为1,MaxBlockNum为3,合并过一次,所以Level为1。
合并后,目录下的索引和数据文件也会相应进行合并。新目录命名遵循的规则为:
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值
- Level:取同一分区内最大Level值并加1
在目录分区合并完成后,旧的分区会置为active=0 的状态(在system.parts表中记录),在数据查询时,它们会被自动过滤。等待一段时间后,就会被自动删除。
4. 稀疏索引
primary.idx 文件内的一级索引采用稀疏索引实现。稀疏索引与稠密索引区别如下:
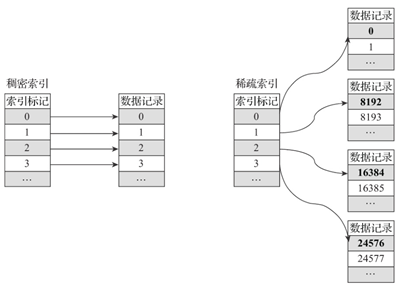
在稀疏索引中,每行索引不会对应到每行记录,而是映射到一段数据的第一行。在Clickhouse中,索引粒度由index_granularity 决定(默认为8192,不过新版ClickHouse中提供了自适应粒度大小的特性),在这个配置下,对于1亿行数据,只需要12208行索引标记即可提供索引。由于稀疏索引占用空间较小,所以primary.idx 内的索引数据常驻内存,取用速度非常快。
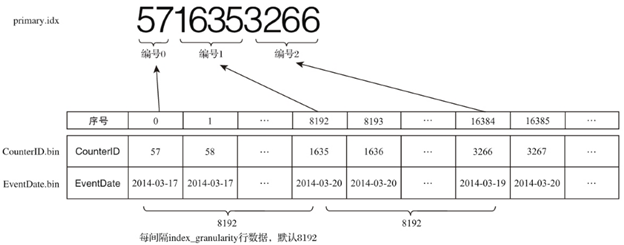
5. 索引数据生成规则
以hits_v1表的数据为例,其主键为CounterID(ORDER BY CounterID),对于2014-03分区内的数据,以index_granularity=8192为例,每隔8192行数据就会取一次CounterID的值作为索引,此索引值最终写入primary.idx文件。如下图所示:
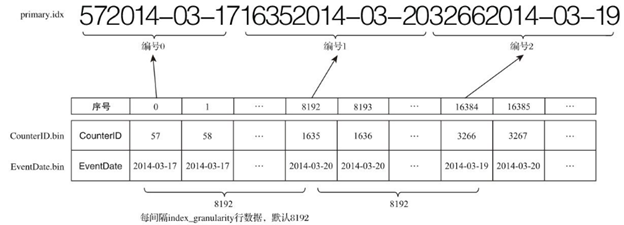
如果主键为复合主键,例如ORDER BY (CounterID, EventDate),则每隔8192行可以同时取CounterID与EventDate两列的值作为索引值。如下图所示:
6. 索引查询过程
在ClickHouse中,MarkRange用于定义标记区间的对象。MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成多个小的间隔数据段,一个具体的数据段即为一个MarkRange。
MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。结合索引编号的取值以及start和end,即可得到它所对应的数值区间,此数值区间即为此MarkRange包含的数据范围。
假设有一份示例数据,一共192条记录,主键ID为String类型,ID的取值从A000开始,后面依次为A001、A002 … 直到 A192。MergeTree的索引粒度index_granularity = 3,根据索引的生成规则,primary.idx 文件内的索引数据值如下图所示:

根据索引数据,MergeTree会将此数据片段划分为 192/3 = 64 个小的MarkRange,2个相邻的MarkRange的步长为1。其中,所有MarkRange(整个数据片段)的最大数值区间为[A000, +inf],示意图如下:

在了解以上背景后,对索引的查询过程就比较好解释了。索引查询是2个数值区间的交集判断。其中,一个区间是由基于主键的查询条件转换而来的条件区间;而另一个区间是与MarkRange对应的数值区间。
整个索引查询过程可以大致分为3个步骤:
1. 生成查询条件区间:首先将查询条件转换为条件区间。即便是单个值的查询条件,也会被转换成区间的形式。例如:
WHERE ID = 'A003' ['A003', 'A003'] WHERE ID > 'A000' ('A000', + inf) WHERE ID < 'A188' (-inf, 'A188') WHERE ID LIKE 'A006%' ['A006', 'A007')
2. 递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000, +inf) 开始:
- 如果不存在交集,则直接通过剪支算法优化此整段MarkRange
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回
3. 合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
完整过程如下图所示:
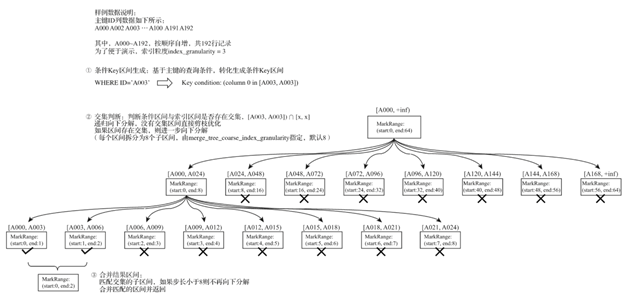
MergeTree通过递归的形式持续向下拆分区间,最终将MarkRange定位到最细的粒度,以帮助在后续读取数据的时候,能够最小化扫描数据的范围。以上图为例,当查询条件 WHERE ID=’A003’ 时,最终只需要读取[A000, A003] 和 [A003, A006] 两个区间的数据,它们对应所属MarkRange(start:0, end:2) 的范围。其他无用区间都被裁减掉了。因为MarkRange转换的数值区间是闭区间,所以会额外匹配到邻近的一个区间。
7. 数据存储
从之前的文件目录结构我们已经知道,在MergeTree中,每个分区都有一个独立的目录。每个分区目录下,对于每列,都有一个 .bin 格式存储文件,用于存储实际压缩后的数据。所以在 .bin 文件中仅保存当前分区片段内的这一部分数据。
在存储数据到 .bin 文件中时,数据首先是经过压缩的(默认为LZ4 算法);其次,数据会事先以ORDER BY 的声明进行排序;最后,数据是以压缩数据块的形式被组织并写入到 .bin 文件中的。
7.1. 压缩数据块
一个压缩数据块由头信息和压缩数据,这两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型、2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。具体如下图所示:
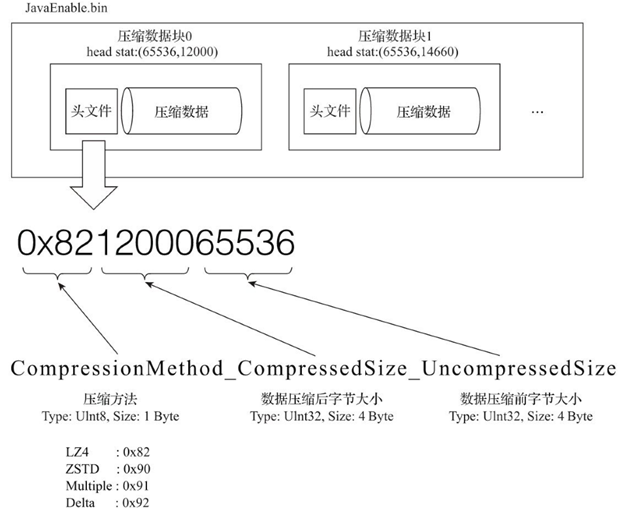
从上图可以看到,.bin压缩文件是由多个压缩数据块组成,每个压缩数据块的头信息是基于CompressionMethod_CompressedSize_UncompressedSize公式生成。
通过ClickHouse提供的clickhouse-compressor工具,可以查询到某个.bin 文件中压缩数据的统计信息:
# clickhouse-compressor --stat UserID.bin | head 65536 14009 65536 18431 65536 6434 … 65536 9267 65536 14260
其中每一行数据代表一个压缩数据块的头部信息,分别表示该压缩块中“未压缩数据大小”和“压缩后数据大小”(打印的信息与物理存储的顺序相反)。
每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB~1MB,其上下限分别由min_compress_block_size(默认65536)与max_compress_block_size(默认1048576)参数指定。而一个压缩数据块最终的大小,则和一个间隔(index_granularity)内数据的实际大小相关。
MergeTree在数据具体的写入过程中,会依照索引粒度(默认情况下,每次取8192行),按批次获取数据并进行处理。如果把一批数据的未压缩大小设置为size,则整个写入过程遵循以下规则:
- 单个批次数据size < 64KB:如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size >= 64 KB 时,生成下一个压缩数据块
- 单个批次数据64KB <= size <= 1MB:如果单个批次数据大小恰好在64KB 与 1MB之间,则直接生成下一个压缩数据块
- 单个批次数据 size > 1MB:如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续按照上述规则执行。此时会出现一个批次数据生成多个压缩数据块的情况。
整体逻辑如下图所示:
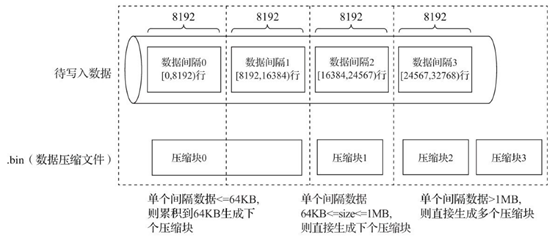
经过上述介绍后,我们知道:一个 .bin 文件是由1到多个压缩数据块组成,每个压缩块在64KB ~1MB 之间。多个压缩数据块之间,按照写入顺序首位相接,紧密地排列在一起。
在 .bin 文件中引入压缩数据块的目的至少有2点:
- 虽然数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率,但数据的压缩和解压动作,其本身也会带来额外的性能损耗。所以需要控制被压缩数据的大小,以求在性能损耗和压缩率之间寻求一种平衡;
- 在具体读取某一列数据时(.bin文件),首先需要将压缩数据加载到内存并解压,然后才能进行后续的数据处理。通过压缩数据块,可以在不读取整个 .bin 文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取的范围
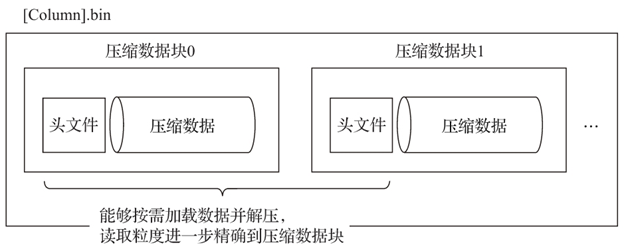
8. 数据标记
前面我们已经介绍了 .bin 与 primary.idx,.bin 存储了分区目录下某一列的压缩数据,primary.idx 中,以index_granularity为间隔,存储了对应列的稀疏索引。前面我们还看到过一个文件格式是 .mrk类型,下面介绍数据标记文件。
8.1. 数据标记生成规则
通过索引下标找对应数据标记的流程如:

首先可以看到的是,数据标记和索引区间是对其的,均按照index_granularity的粒度间隔。这样只需要通过索引区间的下标编号就可以直接找到对应的数据标记。
同时,每个列字段的 [column_name].bin 文件都有一个与之对应的 [column_name].mrk 数据标记文件,用于记录数据在 [column_name].bin 文件中的偏移量信息。
一行标记数据使用一个元组表示,元组内包含2个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的 .bin 文件中,压缩数据块的起始偏移量;以及将该数据块解压后,其未压缩数据的起始偏移量。如下图所示:
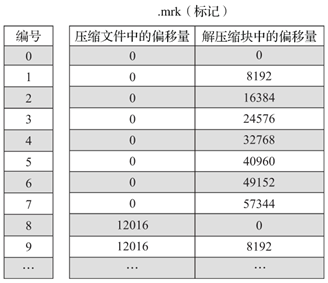
每一行标记数据都表示了一个片段的数据(默认8192行)在 .bin 压缩文件中的读取位置信息。标记数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取用数据。
8.2. 数据标记的工作方式
MergeTree在读取数据时,必须通过标记数据的位置信息才能够找到所需要的数据。整个查找过程大致分为2步:“读取压缩数据块” 和 “读取数据”。
下面以hits_v1表为例,下图为hits_v1表的JavaEnable字段及其标记数据与压缩数据的对应关系:
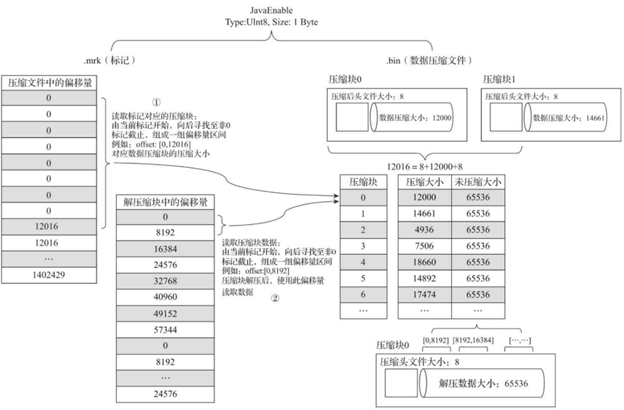
首先解释最左边的“压缩文件中的偏移量”。
- JavaEnable字段的数据类型为UInt8,所以对于此列,每个条目占用空间为1个字节,也就是1B
- hits_v1表的index_granularity粒度为8192。前面提到primary.idx 中,每隔8192行,就写一个索引条目,所以此时一个MarkRange的大小即为 8192B
- 前面提到,在实际存储数据到JavaEnable.bin中时,是以压缩数据块的形式。此时8192B作为单个批次数据的size,是小于64KB,所以会继续获取下一个批次的数据(也就是又一批size=8192B 的数据,也就是下一个MarkRange),直到数据量 >= 64 KB时,生成一个压缩数据块
- 对于JavaEnable字段,64KB = 65536B,65536B/8192 = 8。所以在 JavaEnable.mrk 数据标记文件中,前8行对应的均是JavaEnable.bin 里的第1个压缩数据块。也就是说,每8行标记数据,对应1个压缩数据块
- 从图中可以看到,.mrk前8行对应的均是 .bin 文件中的压缩块0
再解释左二的“解压缩块中的偏移量”:
- 前面提到,在 .mrk 文件中,每行标记数据为2元元组,第一个元素表示在 .bin 文件中压缩数据块的起始偏移量;第二个元素表示将数据块解压后,未压缩数据的起始偏移量
- 在对JavaEnable字段数据解压缩后,每个MarkRange的长度均为8192,所以在“解压缩块中的偏移量”以8192B为单位递增。而由于超出了64KB后,一个压缩数据块结束,到第二个压缩块时,此偏移量又以0为起始
简单来说:在 .mrk文件中,每行的第一个元素找到 .bin 中的对应压缩数据块;第二个元素找到此压缩块展开后,对应的MarkRange的其实地址在这个数据块中的位置。
下面详细解释MergeTree如何定位压缩数据块,并读取数据:
- 读取压缩数据块:在查询某一列数据时,MergeTree无须一次行加载整个.bin文件。而是根据过滤条件,仅加载所需特定压缩数据块。.mrk 文件中的元组的第一个元素即可用于判断有多少行的 .mrk 数据构成了一个压缩数据块。例如:第1个压缩数据块在 .mrk 文件中元组的第一个元素均为0。所以在这个例子中,每8个数据标记遍定位到了一个压缩数据块
- 读取数据:在压缩数据块解压后,MergeTree并不需要扫描整个解压后的数据,而是以index_granularity为粒度,加载特定一个MarkRange。此时遍可以通过 .mrk 文件中元组的第二个元素判断要读取哪个MarkRange的数据。例如在上图中,通过 .mrk的[0, 0] 可以定位到第1个MarkRange的起始位置;通过 .mrk 的第2行 [0, 8192] 可以定位到第1个MarkRange的结束位置;结合起来,便可读到对应 primar.idx 中第1条索引对应的数据内容。
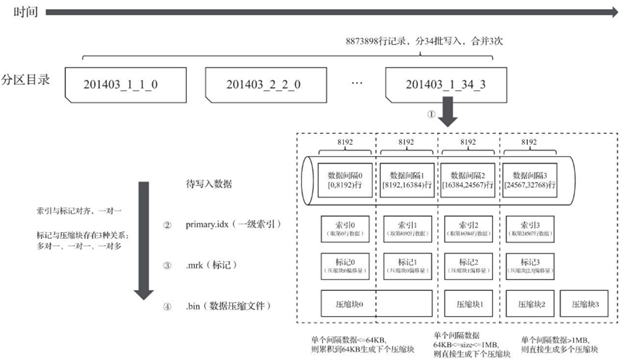
9. MergeTree写入过程总结
数据写入的第1步是生成分区目录,每个批次的写入均会写入一个新的分区。后续对于相同的分区会进行合并,生成新的分区,并且旧的分区会在后续被删除。
接下来,按照index_granularity索引粒度,生成 primary.idx 一级索引(如果声明了二级索引,还会创建二级索引文件),此时每个索引片段对应的是一个MarkRange。同时还会对每个column生成 .mrk 数据标记文件,和.bin 压缩数据文件。下图是MergeTree在写入数据时,分区目录、索引、标记和压缩数据的过程:
10. MergeTree查询过程总结
查询的过程是一个不断过滤的过程,在理想情况下,MergeTree可以依次借助分区目录,primary.idx 和二级索引,将数据扫描的范围缩至最小。然后再借助 .mrk 数据标记文件,定位到具体压缩数据块,并在解压缩后,定位到具体MarkRange内的数据。如下图所示:
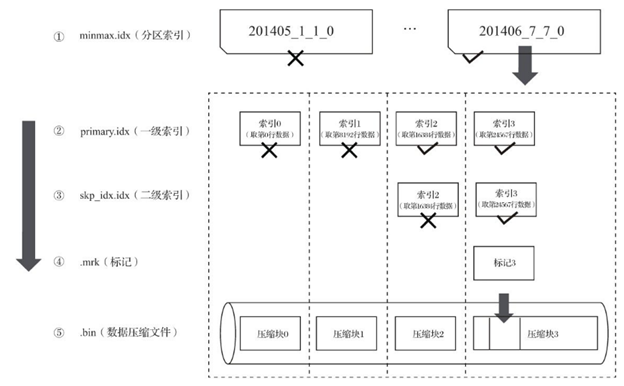
如果一条查询语句没有指定任何WHERE条件,或是指定了WHERE条件但是没有匹配到任何索引(包含分区、一级索引与二级索引),则MergeTree就无法预先减少所需扫描的数据范围。它会扫描所有分区目录,以及目录内索引段的最大区间。虽然无法减少扫描数据范围,但MergeTree仍能够借助.mrk数据标记文件,以多线程的方式同时读取多个压缩数据块,以提升性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号