
集成学习与随机森林(二)Bagging与Pasting
Bagging 与Pasting
我们之前提到过,其中一个获取一组不同分类器的方法是使用完全不同的训练算法。另一个方法是为每个预测器使用同样的训练算法,但是在训练集的不同的随机子集上进行训练。在数据抽样时,如果是从数据中重复抽样(有放回),这种方法就叫bagging(bootstrap aggregating 的简称,引导聚合)。当抽样是数据不放回采样时,这个称为pasting。
换句话说,bagging与pasting都允许训练数据条目被多个预测器多次采样,但是仅有bagging允许训练数据条目被同一个预测器多次采样。在pasting中,每个预测器仅能对同一条训练数据条目采样一次。Bagging的采样与训练的过程如下图所示:
在所有预测器都训练好后,集成器可以对一条新数据做预测,它会简单地聚集所有预测器的预测值。这个聚集方法通常在分类问题中是一个统计模型(也就是说,使用出现最频繁的预测,与投票分类器中的硬投票类似),而在回归问题中是一个平均值。每个单独预测器的bias(偏差值)相对于他们在原始训练集上训练的bias会更高,不过集成会同时减少bias与variance(方差)。一般来说,集成的结果与单个模型,两者的bias值较为接近,但是集成的variance会更低。
在上图中我们也可以看到,模型可以并行进行训练,使用不同的CPU核或是不同的服务器。类似的,预测也可以并行完成。这也是为什么当今bagging与pasting如此令人受欢迎的原因之一:它们的扩展性非常好。
Sk-learn中的Bagging与Pasting
Sk-learn提供了一个简单的API用于bagging与pasting,BaggingClassifier类(或BaggingRegressor类做回归任务)。下面的代码训练一个由500棵决策树组成的集成:每个均在100条随机采样的训练数据条目上进行训练,且数据采样有放回(也就是bagging的例子,如果要用pasting,指定bootstrap=False即可)。n_jobs 参数指定sk-learn在训练与预测时使用的CPU核数(-1表示使用所有可用资源):
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, n_jobs=-1) bag_clf.fit(X_train, y_train) y_pred = bag_clf.predict(X_test)
在BaggingClassifier中,如果基于的基本分类器是可以估计类别概率的话(例如它包含predict_proba() 方法),则BaggingClassifier 会自动执行软投票(soft voting),而不是硬投票。在上面的例子中,基本分类器是决策树,所以它执行的是软投票。
下图对比了单个决策树的决策边界与bagging集成500棵树(上面的代码)的决策边界,两者均在moon数据集上进行训练。我们可以看到,集成预测的泛化性能会更好:集成与单个决策树的bias差不多,但是集成的variance更小。
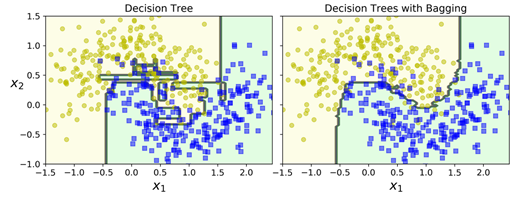
Bootstraping在每个模型使用的训练子集中引入了更多的多样性,所以bagging最终的bias会稍高于pasting一些;但是额外的多样性也意味着最终模型之间的相关性会更小,所以集成的variance会减少。总之,bagging一般相对于pasting会产生更好的模型,这也是为什么我们一般倾向于使用bagging。不够如果有足够的时间和CPU的话,我们可以使用交叉验证来评估bagging与pasting的性能,并选择其中表现最好的那个。
Out-of-Bag评估
使用bagging时,有些数据条目可能会被任一模型采样多次,而其他数据条目可能从来都不会被采样。默认情况下,BaggingClassifier会以有放回(bootstrap=True)的方式采样m条训练数据,这里m为训练集的大小。也就是说,对每个模型来说,平均大约仅有63%的训练数据条目会被采样到。剩下大约37% 的(没有被采样的)训练数据条目称为out-of-bag(oob)实例。
由于模型在训练中并不会看到oob实例,所以可以使用这些实例对模型进行评估,而不需要使用额外的验证集。我们可以通过取每个模型的oob评估的平均,作为集成的评估。
在sk-learn 中,我们在创建BagginClassifier时可以设置 oob_score=True,这样可以在训练结束后
启用一个自动的oob评估。下面的代码是展示的这个例子,评估结果分数可以通过oob_score_变量获取:
bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, bootstrap=True, n_jobs=-1, oob_score=True ) bag_clf.fit(X_train, y_train) bag_clf.oob_score_ >0.8986666666666666
根据oob的评估结果,这个BaggingClassfier可能会在测试集上达到89.8%的准确率,下面我们验证一下:
from sklearn.metrics import accuracy_score y_pred = bag_clf.predict(X_test) accuracy_score(y_test, y_pred) >0.904
在测试集上的准确度为90.4%,结果比较接近。
对每条训练集的oob决策函数也可以通过oob_decision_funcsion_ 变量获取。在上面的这个例子中(由于base estimator 有 predict_proba() 方法),决策函数会对每条训练数据返回它属于某个类别的概率。例如,oob 评估第一条训练数据有58.6%的概率属于正类,41.4%的概率属于负类。
bag_clf.oob_decision_function_ >array([[0.41361257, 0.58638743], [0.37016575, 0.62983425], [1. , 0. ], [0. , 1. ], …

 浙公网安备 33010602011771号
浙公网安备 33010602011771号