
Flink 应用的一致性保障
应用一致性保障
在Flink中,会自动做检查点,用于故障时恢复一个应用。在恢复时,application的state信息可以根据最近完成的检查点进行重建,并继续运行。不过,仅将一个application的state进行重置并不足以满足exactly-once的保证。
为了给一个应用提供exactly-once保证,在应用根据检查点重置state时,它的每个source connector都应该有能力将它的read position重置到做检查点时的read position。在做一个检查点时,source operator将它的read position也持久化,并在恢复时根据此位置进行重置。对于这类可以重置read position的source connector,比较有代表性的有:
- 基于文件的源:可以存储读文件字节流时的偏移量
- Kakfa:可以存储读入topic partition的偏移量
如果一个application从一个无法重置read position的source connector读数据,则在故障发生并恢复时,只能提供at-most-once 的保证。
Flink的检查点与恢复机制、结合可重置reading position的source connector,可以确保一个应用不会丢失任何数据。但是,此应用仍可能输出同一数据两次。因为若是应用故障发生在两次检查点之间,则必定会导致已经成功输出的数据再次输出一次。所以仅通过Flink与source connector的行为,并不足以提供端到端的exactly-once保证,即使application的state具有exactly-once的保证。
一个application若是需要提供端到端exactly-once 的保证,则需要特殊的sink connectors。对于sink connectors来说,有两种技术可以应用于不同的场景,用于达到exactly-once的保证,分别为:idempotent writes、以transactional writes。
Idempotent Writes
一个idempotent 操作可被执行多次,但是仅会产生一个变化。例如向一个hashmap中插入同样的key-value pair,这即为一个idempotent操作。因为仅有第一次操作会在hashmap中增加此条目,而之后的插入不会改变hashmap中的内容。一个非 idempotent 操作的例子如追加操作,即使是同样的数据,每次追加都会增加一条数据。在流应用中,idempotent write是一个很有特点的操作,它们可以多次执行,但并不改变最终的结果。所以在Flink根据检查点机制进行恢复时,可以在一定程度上缓解replay对结果造成的影响(或是没有影响)。
需要注意的是,若是一个应用依赖于idempotent sinks,以达到exactly-once 的结果,则必须保证的是:在replay时覆盖之前写的结果。一般来说,只要流应用在replay时正常执行并输出,在新的输出覆盖掉之前写的结果后,即可以正常到达一致状态。
Transactional Writes
第二种实现端到端exactly-once 一致性的方法是基于transactional writes。这个方法基于的想法是:仅在最近一个检查点成功完成后,才将所有结果写入到一个外部的sink系统。这个行为可以实现端到端exactly-once的原因是因为:在故障发生时,应用会被重置到最近的检查点,并且在此检查点之后,没有任何结果被写入到外部sink系统。但是此方法会增加延时,因为结果仅能在一个检查点完成后才能看到。
Flink提供了两种方式分别实现transactional sink connectors – 一个通用的 write-ahead-log(WAL
)以及一个two-phase-commit(2PC)sink。WAL
sink将所有result
records写入应用的state,并在它收到了一个“检查点完成”的通知后,将结果输出到sink
系统。因为WAL
sink会将result
records缓存到state
backend,所以它可以用于任何sink
系统中。然而,使用此方法实现的exactly-once仍会有些代价:增加了应用的state大小,并且sink
系统需要处理突增写入的模式。
与WAL不同的是,2PC sink需要sink system提供事务支持,或者提供模拟事务的支持。对于每个检查点,sink首先启动一个事务,将所有接收到的记录添加到事务中,并将它们写入sink系统,但是不提交(commit)。当它收到一个“检查点完成”的通知后,它提交事务,并将结果落盘。
2PC协议集成在Flink的检查点机制中。Checkpoint barriers便是启动一个新事务的通知,所有operators中对于它“自身检查点完成”的通知,即是它们的commit 投票。JobManager的对于“整个检查点完成”的消息,即为提交事务的指示。
相对于WAL sinks,2PC sinks是基于sink 系统以及sink的实现方式,达到exactly-once的输出保障。而 相对于WAL sink的突增写入模式,2PC sink为持续向sink 系统写入记录。
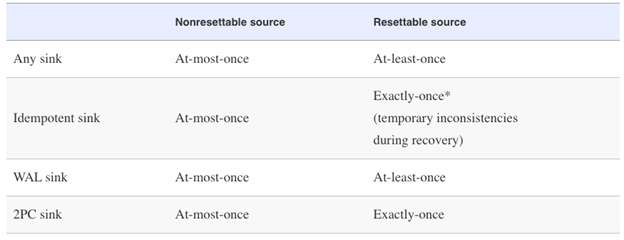
下表展示的是对于不同类型的source与sink connectors,在最优的情况下是否可以达到端到端exactly-once保障的对比(根据sink的实现不同,真正的一致性可能会更差):
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号