
Flink架构(三)- 事件-时间(Event-Time)处理
3. 事件-时间(Event-Time)处理
在“时间语义”中,我们强调了在流处理应用中时间语义的重要性,并解释了处理时间与事件时间的不同点。处理时间较好理解,因为它基于本地机器的时间,它产生的是有点任意的、不一致的、以及无法复现的结果。而事件时间的语义产生的是可复现的、一致性的结果,它对于很多流处理场景是一个硬性的要求。然而,相对于处理时间语义,事件时间语义应用需要额外的配置,并且引入了更多的系统内部构件。
Flink为常见的event-time处理操作提供了直观、并易于使用的原型。同时也提供了清晰的APIs,用于为用户自定义的operators实现更高级的event-time 应用。有一个对Flink内部时间处理的理解,对与这类高级应用的开发与理解是很有帮助的,有时候也是必须的。前一章介绍过Flink依赖的两个用于提供事件时间语义的概念:record时间戳和水印。下面我们会介绍Flink内部是如何实现并处理时间戳与水印,从而为流应用提供事件-时间语义。
时间戳
所有由Flink 事件-时间流应用生成的条目都必须伴随着一个时间戳。时间戳将一个条目与一个特定的时间点关联起来,一般这个时间点表示的是这条record发生的时间。不过application可以随意选择时间戳的含义,只要流中条目的时间戳是随着流的前进而递增即可。
当Flink以事件-时间的模式处理流数据时,它基于条目的时间戳来评估(evaluate)基于时间(time-based)的operators。例如,一个time-window operator 根据条目的时间戳,将它们分派给不同的windows。Flink将时间戳编码为 16-byte,Long类型的值,并将它们以元数据(metadata)的方式附加到流记录(records)中。它内置的operators将这个Long型的值解释为Unix 时间戳,精确到毫秒,也就是自1970-01-01-00:00:00.000 开始,所经过的毫秒数。不过,用户自定义的operators可以有它们自己的解释方法(interpretation),例如,将精确度指定为微秒级别。
水印
除了条目时间戳,Flink 事件-时间应用必须也提供水印。在一个事件-时间应用中,水印用于从每个task中获取当前的事件时间。Time-based operators 使用这个时间触发计算,并取得进展。例如,一个time-window 任务在到达window的结束边界后,会触发计算并产生输出。
在Flink中,水印是以特殊的records实现的,这些records会持有一个Long类型的值,作为时间戳。如下图所示,水印流记录穿插在正常流记录(包含时间戳)之中:
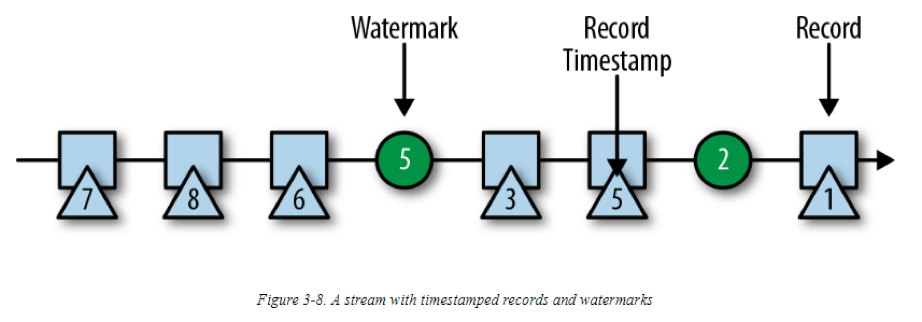
水印有两个基本属性:
1. 它们必须单调递增,以确保任务的event-time时钟向前推进,而不是向后
2. 它们与记录的时间戳是相关的。一个时间戳为T的水印表示的是:在它之后接下来的所有记录的时间戳,都必须大于T
第二个属性用于,处理有乱序时间戳的条目(例如上图中的时间戳3和5)流。在基于时间的operator 中,它的tasks会收集并处理可能乱序的时间戳,在任务的event-time 时钟(这里的event-time时钟就是指收到的水印时间戳)表示没有更多相关的记录需要被考虑时,会触发一个计算。当一个task收到一条与水印属性有冲突的记录,且此记录的时间戳比收到的前一个水印要小时,说明此记录可能本应属于之前已经完成的计算批次。这种记录称为迟到记录(late records)。Flink提供多不同的方法用于处理迟到的记录,我们会在“处理延迟数据”部分介绍。
水印中一个比较有意思的属性是,它们允许一个应用控制结果的完整度与延时。若是水印间隔十分紧凑,例如非常接近记录的时间戳,则可达到较低的处理延时,因为一个任务在执行一个计算前,仅需要等待一小段时间,以获取这段时间内的records。同时,结果的准确度可能会受到影响,因为相关的记录(延迟或是迟到的记录)可能未包括在结果中。反之,非常保守的水印则会增加处理延时,但是会提高结果的准确度。
水印传播与事件时间
在这节,我们会讨论operator 如何处理水印。Flink实现水印时,是将水印作为特殊的记录处理,这些记录可以由operator的任务接收或是释放。Task有一个内部的时间服务(time service),此服务用于维护计时器,并在收到一个水印的时候被激活。Task可以在time service注册计时器,以在未来某个时间点执行一个计算。例如,一个window operator 为每个活跃的窗口注册一个计时器,在event time 超过窗口的终止时间后,会对窗口的状态做清理。
当一个task收到一个水印,会发生以下行动:
1. 此任务根据水印的时间戳更新它内部的事件-时间(event-time)时钟。
2. 任务的time service 标识出所有时间小于更新后的事件-时间的计时器。对于每个过期的计时器,task调用一个回调函数,用于执行计算并释放结果
3. Task使用更新后的事件时间,赋值并释放一个水印
这里需要注意的是,Flink限制了通过DataStream API 访问时间戳或是水印的权限。DataStream中的Functions无法读取或修改记录的时间戳和水印,除了process functions。它们可以读当前处理的record的时间戳,请求operator当前的event time,并注册计时器。没有方法提供设置emitted records的时间戳的API、也没有提供操作一个task的event-time 时钟的API、更没有释放水印的API。
我们现在详细的解释一下,一个task如何释放一个水印,并在收到一个新的水印时如何更新它自身的event-time时钟(clock)。如之前介绍过的数据并行(data parallelism),Flink会将数据流分成不同的分区(partition),对于每个分区,都会有不同的operator task 处理,这些task并行工作处理整个数据流。每个分区都是记录(包含时间戳)与水印的数据流。对于一个operator,基于它与上游/下游 operators 连接的方式,它的tasks可以从一个或多个输入分区接受records和水印,并释放records和水印到一个或多个输出分区。下面我们会详细的介绍一个task如何释放水印到多个output tasks,以及它如何根据(从输入tasks)收到的水印,推进它自身的event-time时钟。
一个task对每个输入分区,都维护了一个分区水印。当task从一个分区收到一个水印,它会将对应分区的水印,更新为收到的水印最大值,并设置为当前值。然后,task更新它的event-time 时钟为所有分区水印中的最小值。如果event-time 时钟相较之前有增加,则task处理所有被触发的计时器,并最终广播它的新事件-时间到所有下游task,此操作通过释放一个对应的水印到所有连接的输出分区完成。
下图是一个有4个输入分区与3个输出分区的task,在收到水印后如何更新它的分区水印以及事件-时间时钟,并释放水印:
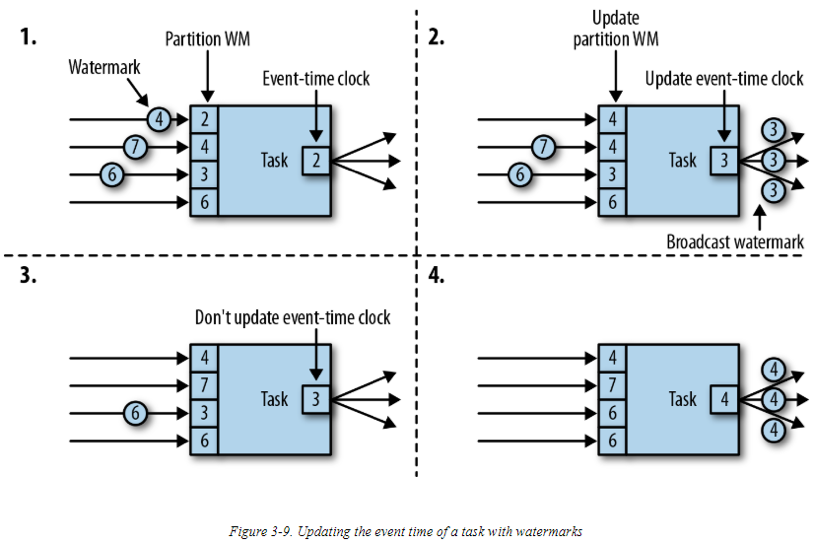
对于有多个输入流的(例如Union或CoFlatMap操作)operators,它们的tasks也会计算它们自身的event-time时钟,并作为所有分区水印的最小值– 他们并不(从不同的输入流中)区分partition watermarks。这样做的结果是,两个不同的输入流中的数据会根据同一event-time时钟进行处理。但是,如果一个application的各个输入流的事件时间并不是一致的,则这个行为会导致问题。
Flink 的水印处理以及传播算法,确保了operator task恰当地释放一致时间戳的记录和水印。然而它依赖的基础是:所有分区持续提供递增的水印。一旦一个分区的水印不再递增,或者完全空闲(不再发送任何记录与水印),则task的事件-时间时钟不会再向前推进,并且task的计时器也不会被触发。在基于时间的、依赖于向前(advancing)时钟执行计算(并做清理)的operators中,便会造成问题。最终会导致处理延时、state大小剧增(如果没有定期从所有的输入任务中接收到新的水印)。
若是两个输入流的水印差异太大,也会造成类似的影响。在有两个输入流的task中,它的事件-时钟会对应于较慢的流,并且较快的流的records或是中间结果一般会缓存到state中,直到event-time 时钟允许处理它们。
时间戳分配与水印生成
到目前为止,我们已经解释了什么是时间戳与水印,并且Flink 内部是如何处理它们的。然而,我们还没有讨论它们的是源头是哪。一般来说,时间戳和水印是在一个stream被stream application 消费时产生的。因为时间戳的选择是取决于application的,而水印是基于时间戳与stream的特点选择,application必须明确的指定时间戳并生成水印。一个Flink DataStream 应用能以三种方式执行时间戳并生成水印:
1. At the source:当一个流被一个application消费时,通过一个SourceFunction,可以完成时间戳的分配与水印的生成。一个source 函数释放一个记录流。Records可以与一个关联的时间戳一起被释放,水印作为特殊的records,可以在任何时间点被释放。如果一个source函数(暂时)不再释放任何水印,它可以声明它自己是空闲的。Flink 会将由空闲source 函数生成的流分区,从后继的operators的水印计算中排除。Sources的空闲机制可以用于定位前面提到的“不递增水印”的问题。
2. 定期分配者(Periodic assigner):DataStream API 提供了一个用户定义的方法,名为AssignerWithPeriodicWatermarks。它从每个记录中抽取一个时间戳,并定期查询当前的水印。提取出的时间戳被分配给对应的记录,查询到的水印被送往流去消费。
3. Punctuated assigner:AssignerWithPunctuatedWatermarks是另一个用户定义的方法,它从每个record抽取时间戳。它可以用于生成(被编码到特殊的记录中的)水印,相对于AssignerWithPeriodicWatermarks,这个方法可以(但是也不是必须的)从每个record抽取水印。
用户定义的时间戳分配函数一般尽可能近的应用到离source operator,因为若是在records已经被一个operator处理后,将会很难推出原本的records顺序。这也是为什么尽量不要在流处理程序的middle部分对时间戳与水印做覆盖的原因,尽管这个是可以通过用户定义函数实现的。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号