
Flink流处理(一)- 状态流处理简介
1. Flink 简介
Flink 是一个分布式流处理器,提供直观且易于使用的API,以供实现有状态的流处理应用。它能够以fault-tolerant的方式高效地运行在大规模系统中。
流处理技术在当今地位愈发重要,因为它为很多业务场景提供了非常优秀的解决方案,例如数据分析,ETL,事务应用等。
2. 有状态的流处理
在很多场景下,数据都是以持续不断的流事件创建。例如网站的交互、或手机传输的信息、服务器日志、传感器信息等。有状态的流处理(stateful stream processing)是一种应用设计模式,用于处理无边界的流事件。下面我们简单介绍一下有状态流处理的机制。
对于任何处理流事件的应用来说,并不会仅仅简单的一次处理一个记录就完事了。在对数据进行处理或转换时,操作应该是有状态的。也就是说,需要有能力做到对处理记录过程中生成的中间数据进行存储及访问。当一个application 收到一个 event,在对其做处理时,它可以从状态信息(state)中读取数据进行协助处理。或是将数据写入state。在这种准则下,状态信息(state)可以被存储(及访问)在很多不同的地方,例如程序变量,本地文件,或是内置的(或外部的)数据库中。
Apache Flink 存储应用状态信息在本地内存或是一个外部数据库中。因为Flink 是一个分布式系统,本地状态信息需要被有效的保护,以防止在应用或是硬件挂掉之后,造成数据丢失。Flink对此采取的机制是:定期为应用状态(application state)生成一个一致(consistent)的checkpoint,并写入到一个远端持久性的存储中。下面是一个有状态的流处理Flink application的示例图:
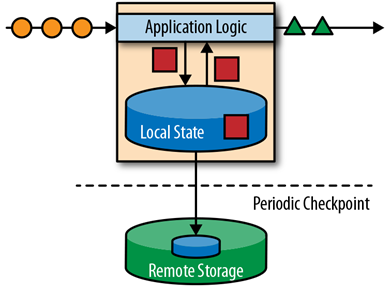
Stateful stream processing 应用的输入一般为:事件日志(event log)的持续事件。Event log 存储并且分发事件流。事件被写入一个持久性的,仅可追加的(append-only)日志中。也就是说,被写入的事件的顺序始终是不变的。所以事件在Publish 给多个不同用户时,均是以完全一样的顺序发布的。在开源的event log 系统中,最著名的当属 Kafka。
使用flink流处理程序连接event log的理由有多种。在这个架构下,event log 持久化输入的 events,并且可以以既定的顺序replay这些事件。万一应用发生了某个错误,Flink会通过前一个checkpoint 恢复应用的状态,并重置在event log 中的 read position,并据此对events做replay(and fast forward),直到它抵达stream 的末端。这个技术不仅被用于错误恢复,并且也可以用于更新application,修复bugs,以及修复之前遗漏结果等场景中。
状态流处理主要有三种常见的实现方式:(1) Event-driven applications;(2)Data pipeline applications;(3)Data Analytics applications
在实际场景中,大部分应用会使用以上多种结合的方式。
3. Event-Driven Applications
事件驱动应用(event-driven application)消费事件流,并以业务逻辑处理events。根据业务逻辑,event-driven application 可以触发某些action(例如发送警报或是email),亦或是向另一事件流写入events,并被其他event-driven application 处理。
常见event-driven applications 使用场景包括:
- 实时推荐(例如客户在浏览卖家网站时,为客户推荐产品)
- 模式识别或是复杂事件处理(例如信用卡诈骗识别)
- 异常检测(例如网络入侵检测)
Event-driven application是微服务的演变。微服务使用 REST 调用以及外部数据存储(例如 Key-Value store)。而事件驱动应用使用的是 event log,并使用本地状态(local state)记录应用数据。下面是事件驱动应用的一个示例图:
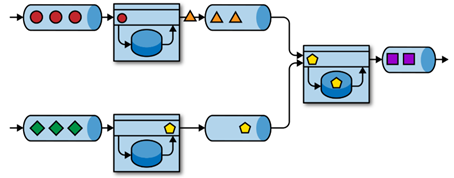
从上图我们可以看出,多个应用经由event log 连接。一个application 将输出写入 event log,并继而被另一application 消费。Event log 将发送端与接收端解耦,并提供了异步非阻塞的事件传输。每个application 都可以是有状态的,并可以在本地管理它自己的状态,而不需要外部数据存储。Applications 可以独立地运行并扩展。
相对于微服务来说,事件驱动应用有多个优点。相较于读写外部数据库,本地状态访问(local state access)提供了非常好的性能。扩展以及容错,由流处理器解决。利用event log 作为输入源,application的输入被稳定存储,并能够以既定的顺序replay。再者,Flink 可以重置application的状态到前一个检查点,这样可以实现在不丢失application 状态的情况下,对应用进修改或是rescale。
Event-driven 应用对流处理器的要求较高。并不是所有流处理器均适用于跑event-driven applications。对此应用的要求包括:处理state的有效方式,事件时间支持等。同时,exactly-once 状态的一致性,以及伸缩能力也同样重要。Apache Flink 的实现符合所有这些需求,对于这类应用来说,是一个很好的选择。
4. Data Pipelines
当今的IT 架构中,涵盖了多种不同的数据存储,例如关系型数据库、nosql 数据库、event logs、分布式文件系统、in-memory cache 以及 search indexes 等。所有这些系统以不同的格式和结构存储数据,以为它们特定的访问模式提供最高效的性能。在实际场景中,可以经常看到同样的数据被存储在多个不同的系统中,以提高数据访问的性能。例如,一个产品的信息可以被存储在关系型数据库、nosql 数据库,以及cache 和search index中。由于数据有多个备份,所以各个位置存储的数据必须保持同步(in-sync)。
一个传统的实现方案是:使用定期的 ETL jobs对存储在不同系统中的数据做同步。但是,此方法导致的高延迟,在当今系统中很多场景都无法接受。另一个方法是使用event log用于发布数据的更新。更新操作被写入到event log,然后被 event log 发布出去。根据使用的场景,被传输的数据可能需要被标准化,亦或是与外部数据进行整合后,再写入到目标存储。
以低延迟的方式消费、转换,然后插入数据,是另一个stateful stream processing application 的应用场景。这种应用被称为data pipeline。Data pipeline 必须能在短时间内处理大量的数据。作为 data pipeline 的流处理器应有能力连接不同的数据源,并进行写入。Flink 对此有较好的支持。
5. Streaming Analytics
ETL 任务会定期导入数据到存储, 然后数据会被一次(或是定期的query)处理。这种批处理与架构是否基于数据仓库,或是Hadoop 生态应用无关。定期载入数据到数据分析系统,在很多年都是业界标准用法。但是它对analytics pipeline 来说,增加了相当的延迟。
取决于每两次操作的间隔,每次操作可能需要消耗几个小时或是几天,直到生成一个结果。在一定程度内,可以通过使用data pipeline application 将数据导入到datastore,以减少延迟。然而,即使是持续的 ETL,直到event被query处理之前,也会存在delay。这个delay在过去是可以被接受的,但是在当今场景中,数据更需要被实时收集并处理(例如,即时推荐)。
相对于等待一个定期触发的job处理数据,streaming analytics application 可以持续消费事件流,并以低延迟整合最新的事件,并更新输出的结果。一般来说,streaming applications 会将它们的结果存储在一个外部datastore,此datastore支持高效的update,例如数据库,或是key-value 存储。流处理程序输出的实时更新的结果,可以被用于Dashboard applications。如下图:
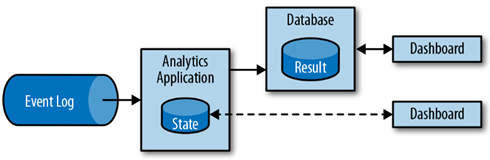
除了能以更短的时间将一个event整合到最终的分析结果中,streaming analytics applications 还有另一个优点。传统analytics pipeline由多个独立的部分组成,如一个ETL 系统,一个存储系统,大数据分析系统等。然而,stateful stream application 可以顾及到所有这些步骤,包括事件消费,持续计算(并维护状态信息),以及更新数据。进一步的,流处理器可以从错误恢复(通过保证exactly-once state consistency),并调整应用的计算资源。Flink 这类流处理器也支持event-time处理,以产生正确、确定的结果,并有能力在短时间内处理大量的数据。
Streaming analytics applications 常用场景有:
- 监控手机网络的质量
- 分析手机应用用户的行为
- 实时数据的Ad-hoc 分析
Flink 同时也提供在流上的 SQL query。
6. Flink 的特点
Apache Flink可以在大规模集群中提供了高吞吐与低延时,相对于其他流处理器,有以下有点:
- Event-time 与 processing-time 语义。事件-时间语义可以,在有无序事件的情况下,提供一致与准确的结果。处理-时间语义可以被用于需要低延迟的application
- Exactly-once 状态一致性的保障
- 以毫秒级的延迟处理每秒百万级的事件。Flink应用可以被扩展运行到上千个核
- 易于使用的API
- 多种connectors用于连接不同数据源,如Kafka,Cassandra,Elasticsearch,JDBC,Kinesis,HDFS以及S3
- 没有单点故障,支持HA设置,极少有downtime。与YARN,Kuberntes等集成较好。快速从错误恢复,以及动态扩展的能力
- 更新application 代码,然后迁移到另一Flink 集群时,可以不丢失application的state 信息
- 详细、可自定义的系统及应用指标收集
- 也可以用作为batch processor
除了这些特点,Flink的API的使用较为简单。内置的execution mode 可以启动一个application,并让整个Flink 系统运行在一个JVM 进程中,方便开发者做开发、测试与debug。
7. 第一个flink程序
在启动一个 flink 集群后,使用命令执行示例程序:
> flink run -m yarn-cluster -yn 2 /usr/lib/flink/examples/streaming/WordCount.jar --input hdfs:///user/hadoop/input --output hdfs:///user/hadoop/output
> cat output
(3123,1)
(asdf21,1)
…
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号