01玩转数据结构_06_二分搜索树
为什么要研究树结构:
因为生活中本身就有这很多的树结构实例。
例如:电脑中的文件系统,图书馆中的图书分类等等。。。
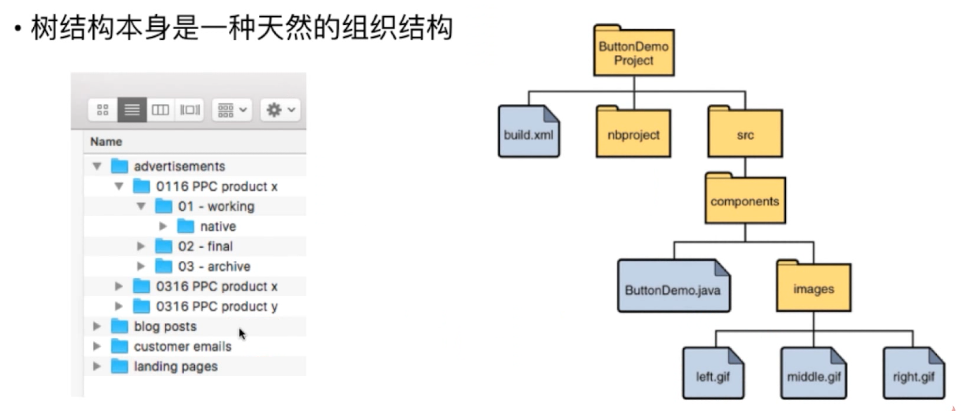
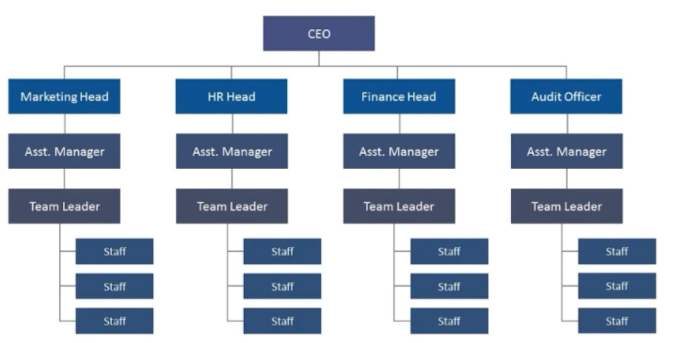
一个公司中也可以体现树这种结构。
为什么要有树结构:
无论是在生活中,还是在计算机中,大量充斥着树结构,那么为什么呢?
因为高效,快速。
![]()

二分搜索树基础:
二叉树:

当然,如果一个节点有多个分叉,那么就形成了多叉树。后面的字典树其实就是个多叉树。
不过,二叉树是使用最多的。这里的例子绝大部分都是二叉树。
二叉树的特点:

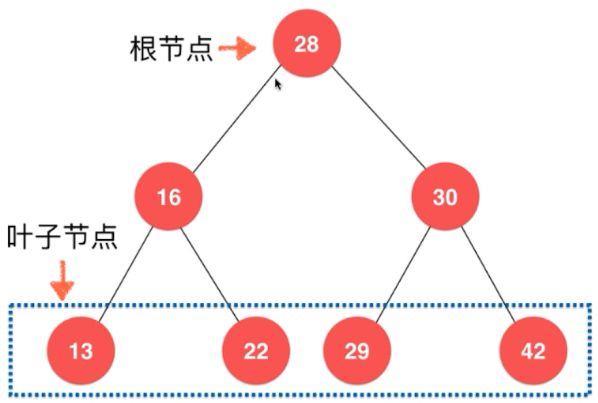
没有孩子的节点称之为 叶子节点。
整个二叉树中只有一个节点没有父亲节点,就是根节点。
二叉树的结构:
二叉树具有天然的递归结构。
它的左子树也是个二叉树,它的右子树也是个二叉树。
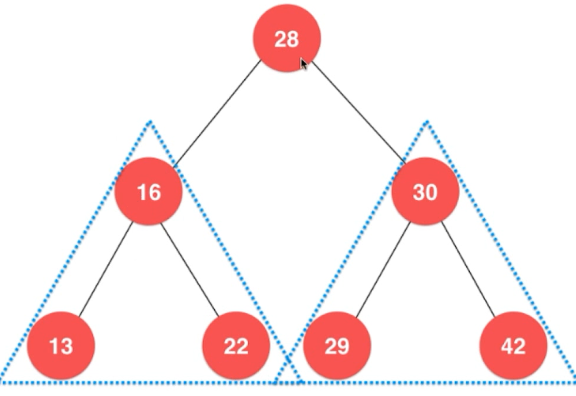

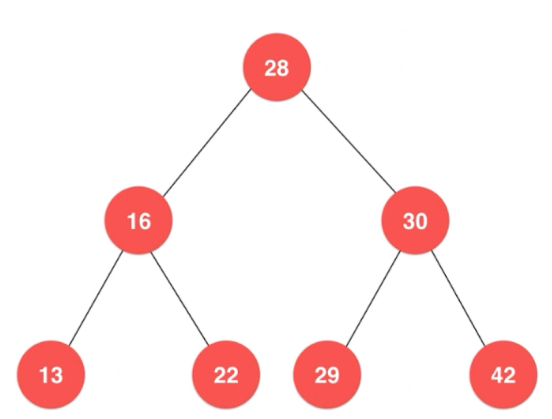
上面图片中的二叉树 是 “满” 的。 不过二叉树不一定是满的,如下面的图片:


二分搜索树 Binary Search Tree:
二分搜索树也是二叉树。
二分搜索树除了是二叉树以外还具有自己独特的性质:
它的每个节点的值都要大于其左子树的所有的节点的值,
它的每个节点的值都要小于其右子树的所有的节点的值。
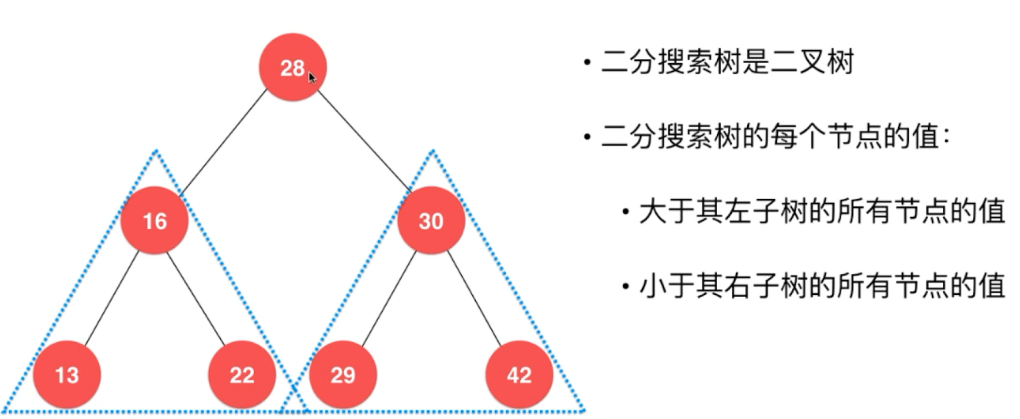
也就是说,二分搜索树的每个子树也都是二分搜索树。
下面的图是个更大的二分搜索树:


二分搜索树为什么这么定义呢?
因为这样定义的话, 对于一个节点,它的左子树的每个节点的值都小于该节点的值,它的有子树的每个节点的值都大于该节点的值。
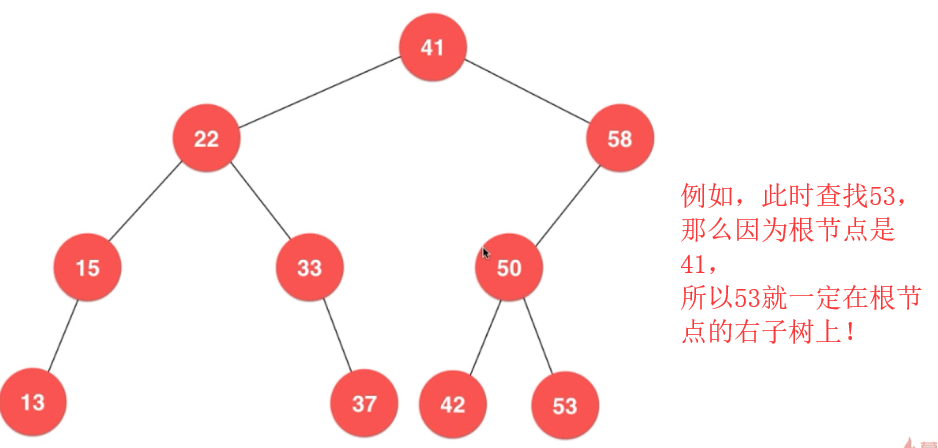
41的左子树根本不需要遍历,这就大大的加块的遍历查找的速度了。我们在生活中使用树这种结构也是这个原因。
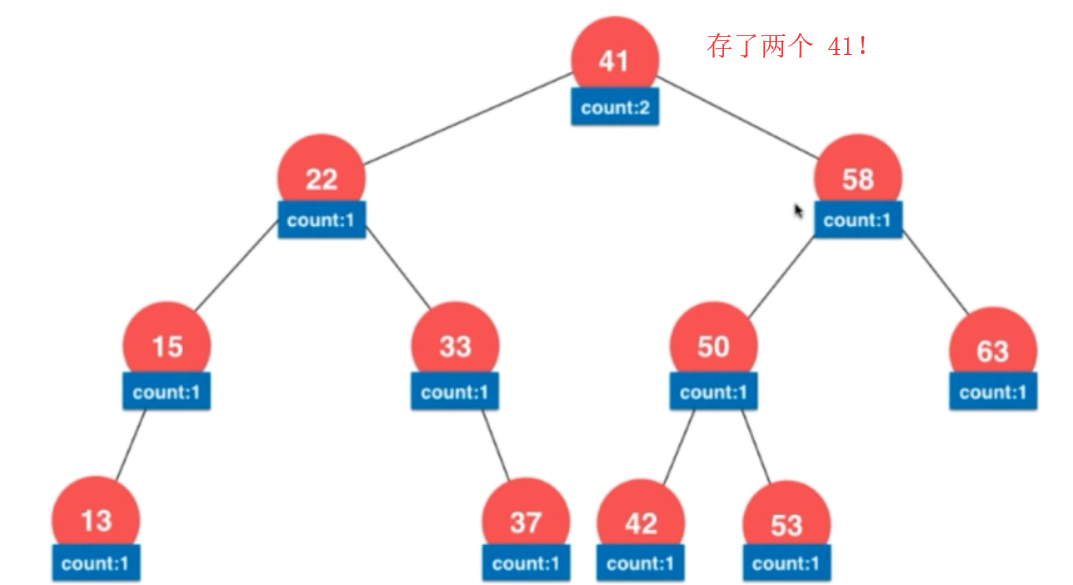
这里需要注意的是:树中存储的元素要有可比较性。如果要存储自己自定义的数据类型,通常我们要给出 两个自定义类型之间是如何进行比较的。


1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 36 37 }
向二分搜索树中添加元素--分析:
刚一开始树中一个元素都没有:如下图:

添加一个元素41,那么41就成为了根。

现在又来了个22,因为它是小于41,所以它要变为41的左孩子。
假设树已经为如下情况:
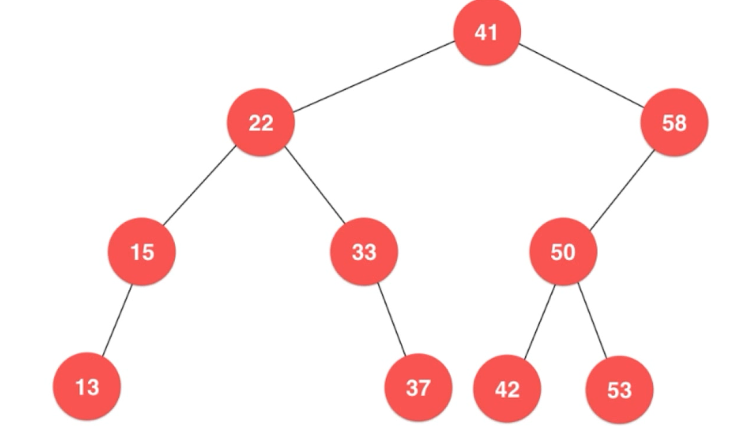
此时又来了个60.
60先和41比较,因为它是大于41的,所以它一定要插在41的右子树,
此时,58和60比较,因为60大于58,故它应该插在58的右子树!
然后58的右子树为空,所以就插入到58的右子树。
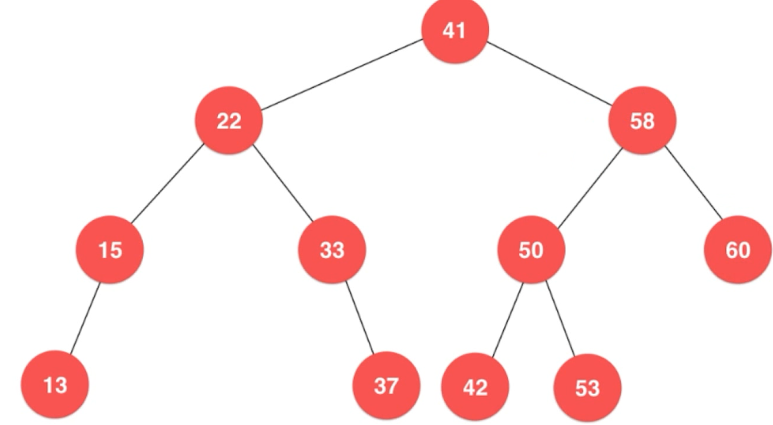
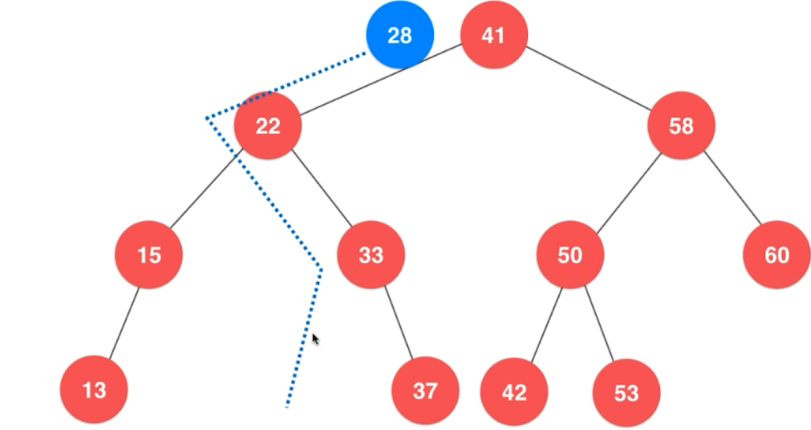
再如:如果此时要插入28的话,
因为28小于41,所以应该插在41的左子树。
因为28大于22,所以应该插在22的右子树。
因为28小于33,所以应该插入33的左子树。
因为33左子树为空,所以就应该插在33的左孩子!
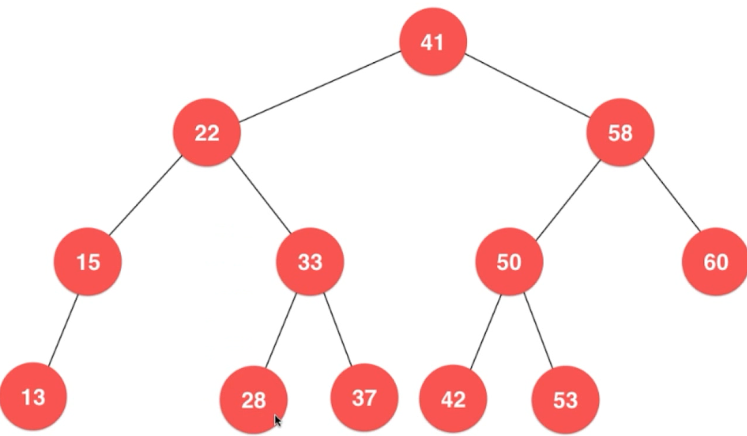
再如:如果此时要插入50的话,
因为50大于41,所以要插在41的右子树,
因为50小于58,所以要插在58的左子树,
因为50=50,所以就不作任何操作了。(我们这里是这样操作的。)


如果感兴趣,也可以自己实现一个包含重复元素的二分搜索树。
注:前面说的 数组 和 链表是可以有重复元素的。
其实,看到底有没有重复元素,要依具体的应用来看。
向二分搜索树中添加元素--代码实现:
其实,对于这个需求,非递归实现也很简单,
![]() ,如下图:
,如下图:
不过,我们这里采用递归算法,采用递归不是说,非递归不重要。只是加深递归的理解。
递归算法的开销还是很大的。
这里的代码都是递归的。对于非递归的代码,有时间可以尝试。

1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 //向二分搜索树 中添加新的元素e 36 public void add(T t){ 37 if(this.root == null){ //如果根节点为空, 38 this.root = new Node(t); 39 this.size ++; 40 }else{ 41 //调用递归函数 42 add(this.root,t); 43 } 44 45 } 46 //此时 node 为根节点。 47 private void add(Node node,T t){ 48 if(t.equals(node.t) ) 49 return; //此时相等,不作任何事情 50 else if(t.compareTo(node.t) < 0 && node.left == null ){ 51 var newNode = new Node(t); 52 node.left = newNode; 53 this.size ++; 54 return; 55 }else if(t.compareTo(node.t) >0 && node.right == null){ 56 var newNode = new Node(t); 57 node.right = newNode; 58 this.size ++; 59 return; 60 } //上面都是终止条件 。。。。。。 下面是递归链条! 61 62 if(t.compareTo(node.t) < 0) //此时的node.left 和node.right一定不等于null了 63 add(node.left,t); 64 else 65 add(node.right,t); 66 } 67 }
上面代码针对 根节点和其他的节点插入时候,逻辑没有统一,下面是改进版:
1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 //向二分搜索树 中添加新的元素e 36 public void add(T t){ 37 this.root = add(this.root,t); 38 } 39 //向 以node 为根节点 的 二分查找树中插入 元素 40 //返回 插入新节点后 二分搜索树的根 41 private Node add(Node node,T t) { 42 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 43 this.size ++; 44 return new Node(t); 45 } 46 if (t.compareTo(node.t) < 0){ 47 node.left = add(node.left, t); 48 } 49 else if(t.compareTo(node.t) >0 ){ 50 node.right = add(node.right, t); 51 } 52 return node; 53 } 54 55 }
如果有时间,我们也应该尝试一下使用链表来实现!!!
区别:树来存的要判断插入左子树 还是右子树,
而用链表的话,直接插入到next中就行了。(next有两个,左,右两个next )
如何在二分搜索树中查询元素:
看当前的树中是否包含 元素。
1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 //向二分搜索树 中添加新的元素e 36 public void add(T t){ 37 this.root = add(this.root,t); 38 } 39 //向 以node 为根节点 的 二分查找树中插入 元素 40 //返回 插入新节点后 二分搜索树的根 41 private Node add(Node node,T t) { 42 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 43 this.size ++; 44 return new Node(t); 45 } 46 if (t.compareTo(node.t) < 0){ 47 node.left = add(node.left, t); 48 } 49 else if(t.compareTo(node.t) >0 ){ 50 node.right = add(node.right, t); 51 } 52 return node; 53 } 54 55 56 //看 二分搜索树 中是否存在某个元素 t 57 public boolean contains(T t){ 58 59 return contains(this.root,t); 60 } 61 62 63 //看 以node 为根的二分搜索树 中是否存在某个元素 t 64 private boolean contains(Node node,T t){ 65 if(node == null){ 66 return false; 67 } 68 if(t.compareTo(node.t) == 0) 69 return true; 70 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 71 return contains(node.left,t); 72 else //此时只可能出现在右子树。 73 return contains(node.right,t); 74 } 75 76 77 78 79 80 81 }
二分搜索树中遍历操作--前序遍历:
![]()
![]()

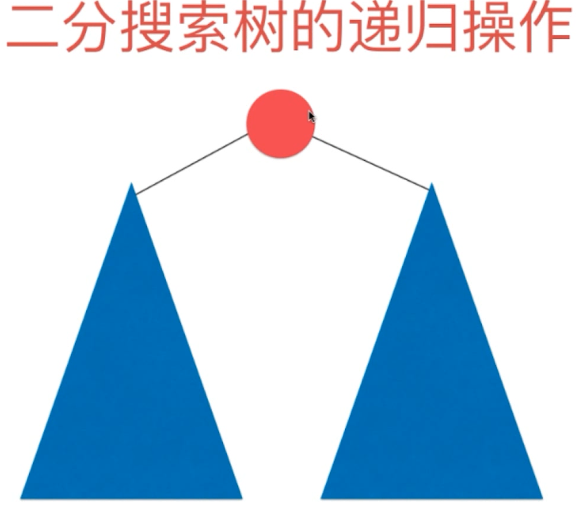
在插入和查找的代码中,我们每次值选择一个子树进入,但是对于遍历就不是这样了。
由于我们要访问二叉树中所有的节点,所以对于一个节点,它的左右子树都要有所顾及。


通常这种遍历,我们也称之为前序遍历(先访问该节点,然后再访问左右子树!)
1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 //向二分搜索树 中添加新的元素e 36 public void add(T t){ 37 this.root = add(this.root,t); 38 } 39 //向 以node 为根节点 的 二分查找树中插入 元素 40 //返回 插入新节点后 二分搜索树的根 41 private Node add(Node node,T t) { 42 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 43 this.size ++; 44 return new Node(t); 45 } 46 if (t.compareTo(node.t) < 0){ 47 node.left = add(node.left, t); 48 } 49 else if(t.compareTo(node.t) >0 ){ 50 node.right = add(node.right, t); 51 } 52 return node; 53 } 54 55 56 //看 二分搜索树 中是否存在某个元素 t 57 public boolean contains(T t){ 58 59 return contains(this.root,t); 60 } 61 62 //看 以node 为根的二分搜索树 中是否存在某个元素 t 63 private boolean contains(Node node,T t){ 64 if(node == null){ 65 return false; 66 } 67 if(t.compareTo(node.t) == 0) 68 return true; 69 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 70 return contains(node.left,t); 71 else //此时只可能出现在右子树。 72 return contains(node.right,t); 73 } 74 75 // 二分搜索树的前序遍历 76 public void preOrder(){ 77 preOrder(this.root); 78 79 } 80 //遍历 以 node 为根节点的二分搜索树 81 private void preOrder(Node node){ 82 if(node == null) 83 return; 84 else 85 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 86 87 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 88 preOrder(node.right); 89 } 90 91 92 @Override 93 public String toString(){ 94 StringBuilder builder = new StringBuilder(); 95 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 96 return builder.toString(); 97 } 98 99 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 100 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 101 if(node == null){ 102 builder.append(generateDepthInfo(depth)+"|null \n"); 103 return; 104 } 105 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 106 107 generateBinarySearchTreeString(node.left,depth+1,builder); 108 generateBinarySearchTreeString(node.right,depth+1,builder); 109 } 110 //生成 关于深度的字符串。 111 private String generateDepthInfo(int depth){ 112 StringBuilder res = new StringBuilder(); 113 for (int i =0;i<depth;i++ ){ 114 res.append("="); //一个= 对应一个深度。 115 } 116 return res.toString(); 117 } 118 119 }
1 package cn.zcb.demo02; 2 3 public class Test{ 4 public static void main(String[] args) { 5 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 6 int [] nums = {5,3,6,8,4,2}; 7 for (int num :nums) 8 bst.add(num); 9 10 bst.preOrder();//前序遍历 11 12 //直接打印 二叉树 13 System.out.println(bst); //每个等号 代表一个深度! 14 15 16 17 } 18 } 19 /* 输出 20 5 21 3 22 2 23 4 24 6 25 8 26 5 27 =3 28 ==2 29 ===|null 30 ===|null 31 ==4 32 ===|null 33 ===|null 34 =6 35 ==|null 36 ==8 37 ===|null 38 ===|null 39 * 40 * */
上面的代码输出的可读性仍然不是特别的易读。
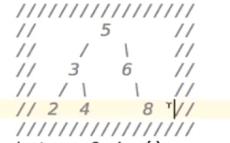
思考题:如何能像下图一样打印输出呢?
这个需要用到后面说的二叉树的程序遍历!而且也要计算每个数字之前有多少个空格,这算是个比较难的挑战!
二分搜索树中遍历操作的另外两种--中序和后序 遍历:
对于树的遍历,前序遍历是最自然的遍历方式,是最常用的遍历方式!
下面看:中序遍历 和 后序遍历:


1 package cn.zcb.demo02; 2 3 public class BinarySearchTree<T extends Comparable<T>> { 4 //这里对树中存储的类型做了限制,它必须具有可比较性。 5 private class Node{ 6 public T t; 7 public Node left,right; 8 9 //Node 构造函数 10 public Node(T t){ 11 this.t = t; 12 this.left = null; 13 this.right = null; 14 } 15 16 } 17 18 //二分搜索树 的成员变量:1,根节点,2,size 19 private Node root; 20 private int size; 21 //二分搜索树的构造函数 22 public BinarySearchTree(){ 23 //此时一个元素都没有存 24 this.root = null ; 25 this.size = 0; 26 } 27 28 public int getSize(){ 29 return this.size; 30 } 31 public boolean isEmpty(){ 32 return this.size == 0; 33 } 34 35 //向二分搜索树 中添加新的元素e 36 public void add(T t){ 37 this.root = add(this.root,t); 38 } 39 //向 以node 为根节点 的 二分查找树中插入 元素 40 //返回 插入新节点后 二分搜索树的根 41 private Node add(Node node,T t) { 42 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 43 this.size ++; 44 return new Node(t); 45 } 46 if (t.compareTo(node.t) < 0){ 47 node.left = add(node.left, t); 48 } 49 else if(t.compareTo(node.t) >0 ){ 50 node.right = add(node.right, t); 51 } 52 return node; 53 } 54 55 56 //看 二分搜索树 中是否存在某个元素 t 57 public boolean contains(T t){ 58 59 return contains(this.root,t); 60 } 61 62 //看 以node 为根的二分搜索树 中是否存在某个元素 t 63 private boolean contains(Node node,T t){ 64 if(node == null){ 65 return false; 66 } 67 if(t.compareTo(node.t) == 0) 68 return true; 69 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 70 return contains(node.left,t); 71 else //此时只可能出现在右子树。 72 return contains(node.right,t); 73 } 74 75 // 二分搜索树的前序遍历 76 public void preOrder(){ 77 preOrder(this.root); 78 79 } 80 //遍历 以 node 为根节点的二分搜索树 81 private void preOrder(Node node){ 82 if(node == null) 83 return; 84 else 85 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 86 87 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 88 preOrder(node.right); 89 } 90 91 92 //二分搜索树的中序遍历 先左 中 然后再右 93 public void midOrder(){ 94 midOrder(this.root); 95 } 96 //中序遍历 遍历以node 为根节点的树 97 private void midOrder(Node node){ 98 if(node == null) 99 return; 100 101 //先遍历该节点的左子树 102 midOrder(node.left); 103 System.out.println(node.t); 104 midOrder(node.right); 105 } 106 107 //二分搜索树后序遍历 先左 右 然后 当前节点 108 public void lastOrder(){ 109 lastOrder(this.root); 110 } 111 //后序遍历 遍历 以node 为根节点的二叉搜索树 112 private void lastOrder(Node node){ 113 if(node == null) 114 return; 115 116 //先遍历 左子树 117 lastOrder(node.left); 118 lastOrder(node.right); 119 System.out.println(node.t); 120 } 121 122 123 @Override 124 public String toString(){ 125 StringBuilder builder = new StringBuilder(); 126 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 127 return builder.toString(); 128 } 129 130 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 131 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 132 if(node == null){ 133 builder.append(generateDepthInfo(depth)+"|null \n"); 134 return; 135 } 136 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 137 138 generateBinarySearchTreeString(node.left,depth+1,builder); 139 generateBinarySearchTreeString(node.right,depth+1,builder); 140 } 141 //生成 关于深度的字符串。 142 private String generateDepthInfo(int depth){ 143 StringBuilder res = new StringBuilder(); 144 for (int i =0;i<depth;i++ ){ 145 res.append("="); //一个= 对应一个深度。 146 } 147 return res.toString(); 148 } 149 150 }
1 package cn.zcb.demo02; 2 3 public class Test{ 4 public static void main(String[] args) { 5 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 6 int [] nums = {5,3,6,8,4,2}; 7 for (int num :nums) 8 bst.add(num); 9 10 bst.preOrder();//前序遍历 11 System.out.println("============"); 12 bst.midOrder();//中序遍历 根据结果可以发现中序的结果就是当前二分搜索树存储元素的排序输出。 13 14 System.out.println("============"); 15 bst.lastOrder();//后序遍历 16 17 System.out.println("============"); 18 //直接打印 二叉树 19 System.out.println(bst); //每个等号 代表一个深度! 20 21 22 23 } 24 } 25 /* 输出 26 * */
由上面代码的输出容易发现中序的输出是有顺序的。
中序的性质:输出是 整个树中元素的 顺序输出 。
后序遍历的应用:如果需要释放内存。我们需要将一个 节点的孩子先释放完毕,才能释放自己。所以这时可以采用后序遍历 释放!(Java用不到,C/C++可以用到)
二分搜索树的前序遍历 的非递归实现:
模拟系统栈:
栈的作用是用来帮我们记录下次要访问的元素 !

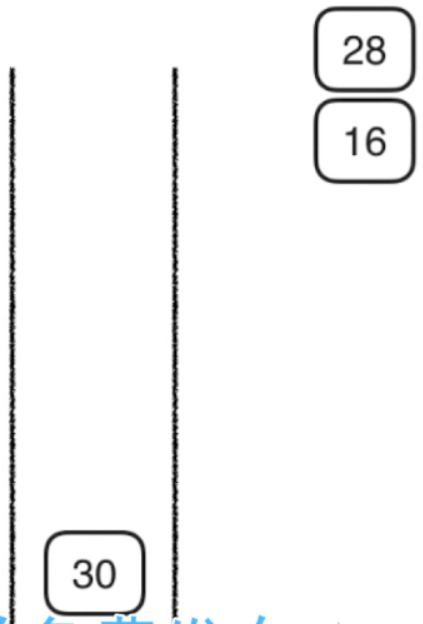
1,首先将28压入栈

然后访问28,

2,将28的两个孩子压入栈(先压 30,后压16)

这时访问16,
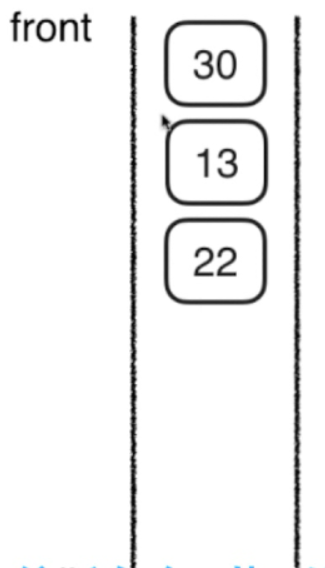
3,将16的两个孩子压入栈(先压 22,后压13)
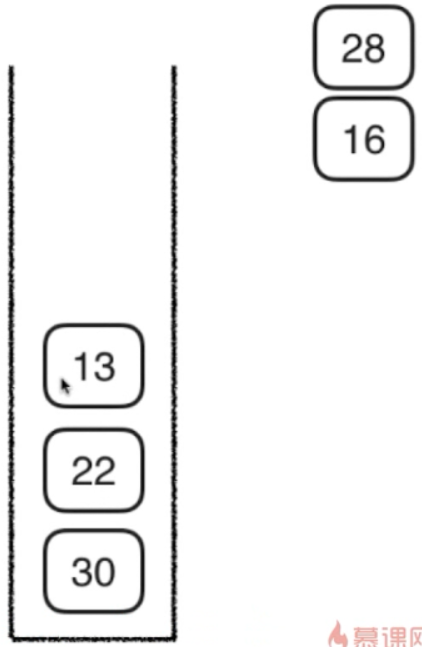
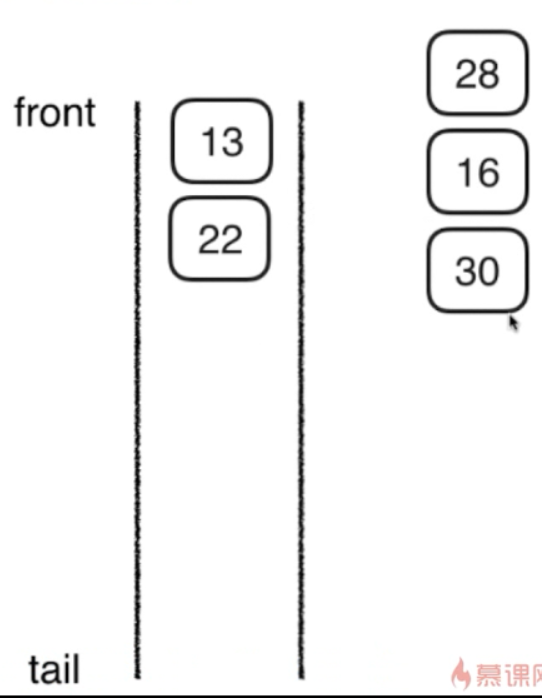
然后,访问13 ,因为13没有孩子了,所以访问22,因为22也没孩子,所以访问30.

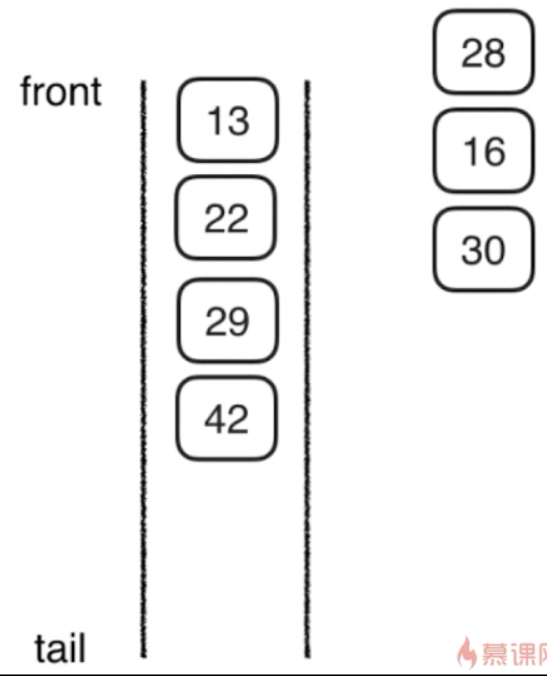
4,将30的两个孩子压入栈(先压 42,后压29)
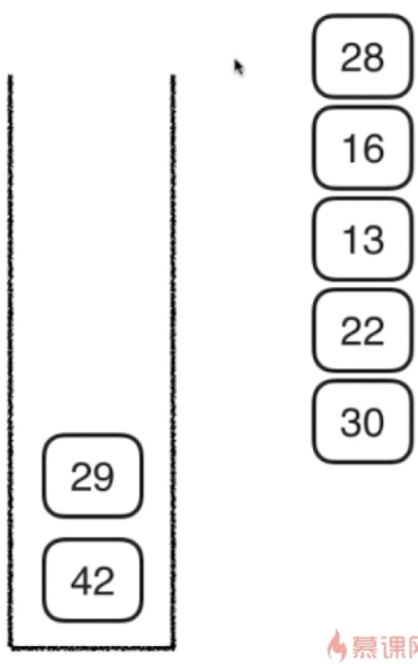
然后访问29,29没孩子,访问42,42没孩子了,而且此时栈为空。所以访问结束。
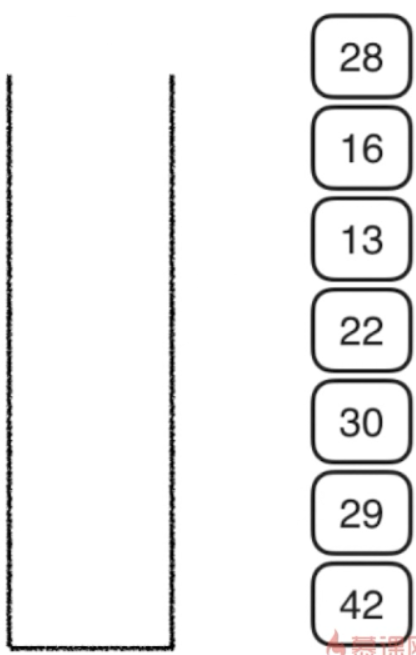
下面看代码:
1 package cn.zcb.demo02; 2 3 import java.util.Stack; 4 5 public class BinarySearchTree<T extends Comparable<T>> { 6 //这里对树中存储的类型做了限制,它必须具有可比较性。 7 private class Node{ 8 public T t; 9 public Node left,right; 10 11 //Node 构造函数 12 public Node(T t){ 13 this.t = t; 14 this.left = null; 15 this.right = null; 16 } 17 18 } 19 20 //二分搜索树 的成员变量:1,根节点,2,size 21 private Node root; 22 private int size; 23 //二分搜索树的构造函数 24 public BinarySearchTree(){ 25 //此时一个元素都没有存 26 this.root = null ; 27 this.size = 0; 28 } 29 30 public int getSize(){ 31 return this.size; 32 } 33 public boolean isEmpty(){ 34 return this.size == 0; 35 } 36 37 //向二分搜索树 中添加新的元素e 38 public void add(T t){ 39 this.root = add(this.root,t); 40 } 41 //向 以node 为根节点 的 二分查找树中插入 元素 42 //返回 插入新节点后 二分搜索树的根 43 private Node add(Node node,T t) { 44 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 45 this.size ++; 46 return new Node(t); 47 } 48 if (t.compareTo(node.t) < 0){ 49 node.left = add(node.left, t); 50 } 51 else if(t.compareTo(node.t) >0 ){ 52 node.right = add(node.right, t); 53 } 54 return node; 55 } 56 57 58 //看 二分搜索树 中是否存在某个元素 t 59 public boolean contains(T t){ 60 61 return contains(this.root,t); 62 } 63 64 //看 以node 为根的二分搜索树 中是否存在某个元素 t 65 private boolean contains(Node node,T t){ 66 if(node == null){ 67 return false; 68 } 69 if(t.compareTo(node.t) == 0) 70 return true; 71 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 72 return contains(node.left,t); 73 else //此时只可能出现在右子树。 74 return contains(node.right,t); 75 } 76 77 // 二分搜索树的前序遍历 78 public void preOrder(){ 79 preOrder(this.root); 80 81 } 82 //遍历 以 node 为根节点的二分搜索树 83 private void preOrder(Node node){ 84 if(node == null) 85 return; 86 else 87 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 88 89 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 90 preOrder(node.right); 91 } 92 93 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 94 public void preOrderNR(){ 95 Stack<Node> stk = new Stack<>(); 96 stk.push(this.root); //将根节点的值压入栈中。 97 98 while (!stk.isEmpty()){ 99 Node temp = stk.pop(); 100 System.out.println(temp.t); //访问 101 102 if(temp.right != null) 103 stk.push(temp.right); 104 if(temp.left != null) 105 stk.push(temp.left); 106 } 107 } 108 109 110 //二分搜索树的中序遍历 先左 中 然后再右 111 public void midOrder(){ 112 midOrder(this.root); 113 } 114 //中序遍历 遍历以node 为根节点的树 115 private void midOrder(Node node){ 116 if(node == null) 117 return; 118 119 //先遍历该节点的左子树 120 midOrder(node.left); 121 System.out.println(node.t); 122 midOrder(node.right); 123 } 124 125 //二分搜索树后序遍历 先左 右 然后 当前节点 126 public void lastOrder(){ 127 lastOrder(this.root); 128 } 129 //后序遍历 遍历 以node 为根节点的二叉搜索树 130 private void lastOrder(Node node){ 131 if(node == null) 132 return; 133 134 //先遍历 左子树 135 lastOrder(node.left); 136 lastOrder(node.right); 137 System.out.println(node.t); 138 } 139 140 141 @Override 142 public String toString(){ 143 StringBuilder builder = new StringBuilder(); 144 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 145 return builder.toString(); 146 } 147 148 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 149 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 150 if(node == null){ 151 builder.append(generateDepthInfo(depth)+"|null \n"); 152 return; 153 } 154 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 155 156 generateBinarySearchTreeString(node.left,depth+1,builder); 157 generateBinarySearchTreeString(node.right,depth+1,builder); 158 } 159 //生成 关于深度的字符串。 160 private String generateDepthInfo(int depth){ 161 StringBuilder res = new StringBuilder(); 162 for (int i =0;i<depth;i++ ){ 163 res.append("="); //一个= 对应一个深度。 164 } 165 return res.toString(); 166 } 167 168 }
1 package cn.zcb.demo02; 2 3 public class Test{ 4 public static void main(String[] args) { 5 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 6 int [] nums = {5,3,6,8,4,2}; 7 for (int num :nums) 8 bst.add(num); 9 10 bst.preOrderNR();// 非递归的方法 进行前序遍历! 11 } 12 } 13 /* 输出 14 5 15 3 16 2 17 4 18 6 19 8 20 * */
这里我们发现,二分搜索树的非递归实现,比递归实现复杂很多,我们必须要使用一个数据结构来辅助完成!(这里使用的是栈!)

![]()
不过,无论是递归还是非递归实现,我们会发现,对于树的遍历,我们都是“一扎到底”!这种的模式叫做深度优先遍历。
和深度优先遍历对应的就是广度优先遍历。
广度优先遍历的结果其实是二分搜索树的层序遍历结果!
二分搜索树的层序遍历:

这里我们使用的方法是非递归的方式,
而且这里要借助 队列这种数据结构的帮助!

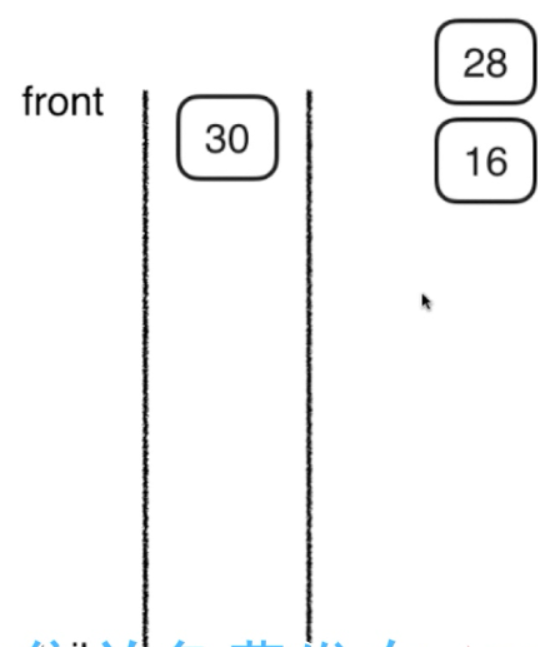
1,初始化时将28入队,

此时访问28,
2,将28的左右两个孩子16,30分别入队
此时访问16,如下:
3,将16的左右两个孩子分别入队
此时访问30.
4,将30的左右两个孩子29,42分别入队
此时访问13,
13 没有孩子了,故不入队。
此时访问22,
22没有孩子了,故不入队。
此时访问29,
29 没有孩子了,故不入队。
此时访问42,
42没有孩子了,故不入队。
最后队列为空,遍历结束!
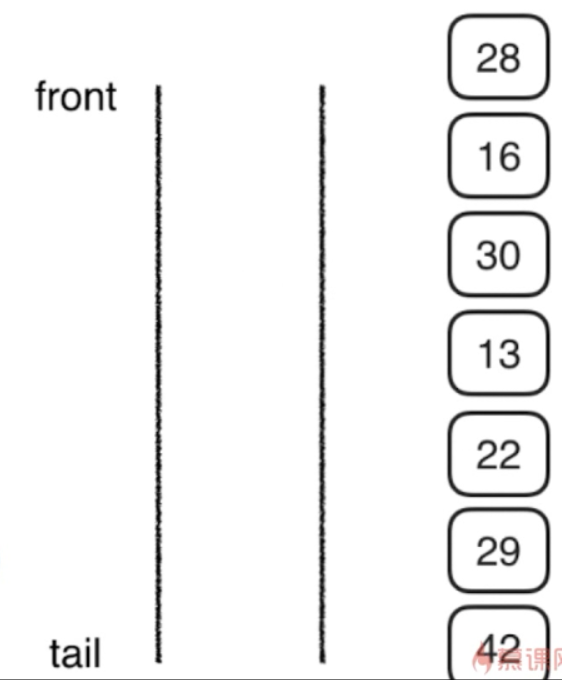
规律:访问一个元素,就将它的孩子压入队列。
层序遍历代码:
1 package cn.zcb.demo02; 2 3 import java.util.LinkedList; 4 import java.util.Queue; 5 import java.util.Stack; 6 7 public class BinarySearchTree<T extends Comparable<T>> { 8 //这里对树中存储的类型做了限制,它必须具有可比较性。 9 private class Node{ 10 public T t; 11 public Node left,right; 12 13 //Node 构造函数 14 public Node(T t){ 15 this.t = t; 16 this.left = null; 17 this.right = null; 18 } 19 20 } 21 22 //二分搜索树 的成员变量:1,根节点,2,size 23 private Node root; 24 private int size; 25 //二分搜索树的构造函数 26 public BinarySearchTree(){ 27 //此时一个元素都没有存 28 this.root = null ; 29 this.size = 0; 30 } 31 32 public int getSize(){ 33 return this.size; 34 } 35 public boolean isEmpty(){ 36 return this.size == 0; 37 } 38 39 //向二分搜索树 中添加新的元素e 40 public void add(T t){ 41 this.root = add(this.root,t); 42 } 43 //向 以node 为根节点 的 二分查找树中插入 元素 44 //返回 插入新节点后 二分搜索树的根 45 private Node add(Node node,T t) { 46 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 47 this.size ++; 48 return new Node(t); 49 } 50 if (t.compareTo(node.t) < 0){ 51 node.left = add(node.left, t); 52 } 53 else if(t.compareTo(node.t) >0 ){ 54 node.right = add(node.right, t); 55 } 56 return node; 57 } 58 59 60 //看 二分搜索树 中是否存在某个元素 t 61 public boolean contains(T t){ 62 63 return contains(this.root,t); 64 } 65 66 //看 以node 为根的二分搜索树 中是否存在某个元素 t 67 private boolean contains(Node node,T t){ 68 if(node == null){ 69 return false; 70 } 71 if(t.compareTo(node.t) == 0) 72 return true; 73 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 74 return contains(node.left,t); 75 else //此时只可能出现在右子树。 76 return contains(node.right,t); 77 } 78 79 // 二分搜索树的前序遍历 80 public void preOrder(){ 81 preOrder(this.root); 82 83 } 84 //遍历 以 node 为根节点的二分搜索树 85 private void preOrder(Node node){ 86 if(node == null) 87 return; 88 else 89 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 90 91 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 92 preOrder(node.right); 93 } 94 95 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 96 public void preOrderNR(){ 97 Stack<Node> stk = new Stack<>(); 98 stk.push(this.root); //将根节点的值压入栈中。 99 100 while (!stk.isEmpty()){ 101 Node temp = stk.pop(); 102 System.out.println(temp.t); //访问 103 104 if(temp.right != null) 105 stk.push(temp.right); 106 if(temp.left != null) 107 stk.push(temp.left); 108 } 109 } 110 111 112 //二分搜索树的中序遍历 先左 中 然后再右 113 public void midOrder(){ 114 midOrder(this.root); 115 } 116 //中序遍历 遍历以node 为根节点的树 117 private void midOrder(Node node){ 118 if(node == null) 119 return; 120 121 //先遍历该节点的左子树 122 midOrder(node.left); 123 System.out.println(node.t); 124 midOrder(node.right); 125 } 126 127 //二分搜索树后序遍历 先左 右 然后 当前节点 128 public void lastOrder(){ 129 lastOrder(this.root); 130 } 131 //后序遍历 遍历 以node 为根节点的二叉搜索树 132 private void lastOrder(Node node){ 133 if(node == null) 134 return; 135 136 //先遍历 左子树 137 lastOrder(node.left); 138 lastOrder(node.right); 139 System.out.println(node.t); 140 } 141 142 //二分搜索树的 层序遍历 143 public void levelOrder(){ 144 Queue<Node> queue = new LinkedList<>(); //因为 Queue本质是个接口,我们要选择它的一个实现类 145 146 queue.add(this.root); 147 148 while (!queue.isEmpty()){ 149 Node temp = queue.remove(); 150 System.out.println(temp.t); //访问 151 152 if(temp.left != null) 153 queue.add(temp.left); 154 if(temp.right != null) 155 queue.add(temp.right); 156 } 157 } 158 159 160 161 162 @Override 163 public String toString(){ 164 StringBuilder builder = new StringBuilder(); 165 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 166 return builder.toString(); 167 } 168 169 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 170 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 171 if(node == null){ 172 builder.append(generateDepthInfo(depth)+"|null \n"); 173 return; 174 } 175 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 176 177 generateBinarySearchTreeString(node.left,depth+1,builder); 178 generateBinarySearchTreeString(node.right,depth+1,builder); 179 } 180 //生成 关于深度的字符串。 181 private String generateDepthInfo(int depth){ 182 StringBuilder res = new StringBuilder(); 183 for (int i =0;i<depth;i++ ){ 184 res.append("="); //一个= 对应一个深度。 185 } 186 return res.toString(); 187 } 188 189 }
1 package cn.zcb.demo02; 2 3 public class Test{ 4 public static void main(String[] args) { 5 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 6 int [] nums = {5,3,6,8,4,2}; 7 for (int num :nums) 8 bst.add(num); 9 10 bst.levelOrder();// 树结构的层序遍历! 11 } 12 } 13 /* 输出 14 5 15 3 16 6 17 2 18 4 19 8 20 * */

对于遍历来说,深度优先遍历和 广度优先遍历差不多,它们都要将每个元素都走一遍,
但是对于查找来说,就不一样了。
如果我们要查找的元素在深度很小的地方,这时如果用深度优先,程序会一股脑的“一扎到底”!
此时使用广度优先就有好处了。所以对于查找来说,广度优先 比较好!
广度优先 的意义:
更快的找到问题的解,
常用于算法设计中---求最短路径,
图中也有深度优先和广度优先的应用!
二分搜索树 之 删除节点:
在树中删除节点是比较复杂的,这里先从简单的开始---删除二分搜索树中的最小值和最大值!
删除二分搜索树的最小值 和 最大值 :
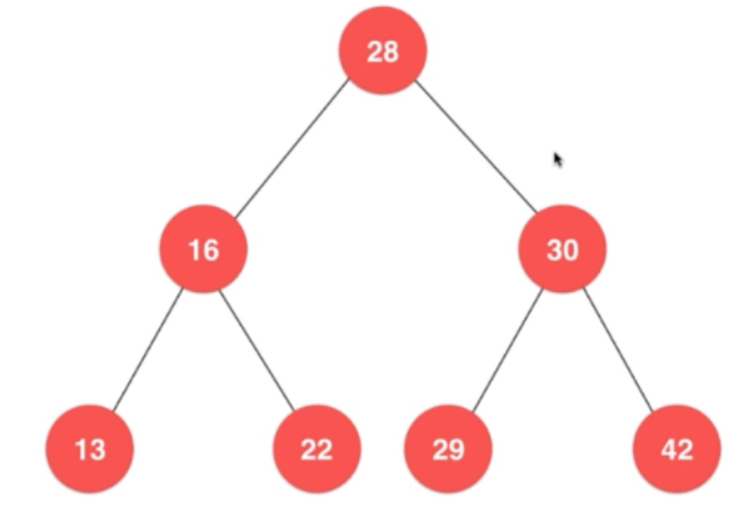
我们根据二分搜索树的特点,很容易知道
树中的最小值是 从根节点向左子树找,直到最后一个没有左子树的节点的值。
树中的最大值是 从根节点向右子树找,直到最后一个没有右子树的节点的值。
对于上图就是
最小值:13,最大值:42
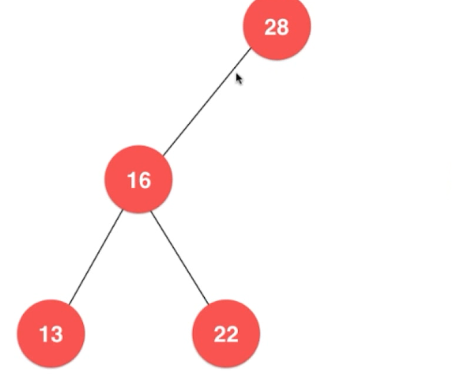
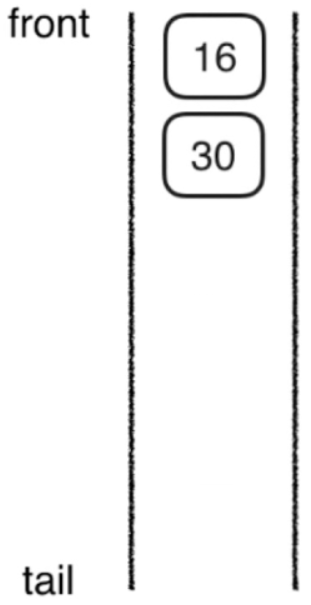
下图是
最小值:16,最大值:30

1 package cn.zcb.demo02; 2 3 import java.util.LinkedList; 4 import java.util.Queue; 5 import java.util.Stack; 6 7 public class BinarySearchTree<T extends Comparable<T>> { 8 //这里对树中存储的类型做了限制,它必须具有可比较性。 9 private class Node{ 10 public T t; 11 public Node left,right; 12 13 //Node 构造函数 14 public Node(T t){ 15 this.t = t; 16 this.left = null; 17 this.right = null; 18 } 19 20 } 21 22 //二分搜索树 的成员变量:1,根节点,2,size 23 private Node root; 24 private int size; 25 //二分搜索树的构造函数 26 public BinarySearchTree(){ 27 //此时一个元素都没有存 28 this.root = null ; 29 this.size = 0; 30 } 31 32 public int getSize(){ 33 return this.size; 34 } 35 public boolean isEmpty(){ 36 return this.size == 0; 37 } 38 39 //向二分搜索树 中添加新的元素e 40 public void add(T t){ 41 this.root = add(this.root,t); 42 } 43 //向 以node 为根节点 的 二分查找树中插入 元素 44 //返回 插入新节点后 二分搜索树的根 45 private Node add(Node node,T t) { 46 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 47 this.size ++; 48 return new Node(t); 49 } 50 if (t.compareTo(node.t) < 0){ 51 node.left = add(node.left, t); 52 } 53 else if(t.compareTo(node.t) >0 ){ 54 node.right = add(node.right, t); 55 } 56 return node; 57 } 58 59 60 //看 二分搜索树 中是否存在某个元素 t 61 public boolean contains(T t){ 62 63 return contains(this.root,t); 64 } 65 66 //看 以node 为根的二分搜索树 中是否存在某个元素 t 67 private boolean contains(Node node,T t){ 68 if(node == null){ 69 return false; 70 } 71 if(t.compareTo(node.t) == 0) 72 return true; 73 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 74 return contains(node.left,t); 75 else //此时只可能出现在右子树。 76 return contains(node.right,t); 77 } 78 79 // 二分搜索树的前序遍历 80 public void preOrder(){ 81 preOrder(this.root); 82 83 } 84 //遍历 以 node 为根节点的二分搜索树 85 private void preOrder(Node node){ 86 if(node == null) 87 return; 88 else 89 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 90 91 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 92 preOrder(node.right); 93 } 94 95 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 96 public void preOrderNR(){ 97 Stack<Node> stk = new Stack<>(); 98 stk.push(this.root); //将根节点的值压入栈中。 99 100 while (!stk.isEmpty()){ 101 Node temp = stk.pop(); 102 System.out.println(temp.t); //访问 103 104 if(temp.right != null) 105 stk.push(temp.right); 106 if(temp.left != null) 107 stk.push(temp.left); 108 } 109 } 110 111 112 //二分搜索树的中序遍历 先左 中 然后再右 113 public void midOrder(){ 114 midOrder(this.root); 115 } 116 //中序遍历 遍历以node 为根节点的树 117 private void midOrder(Node node){ 118 if(node == null) 119 return; 120 121 //先遍历该节点的左子树 122 midOrder(node.left); 123 System.out.println(node.t); 124 midOrder(node.right); 125 } 126 127 //二分搜索树后序遍历 先左 右 然后 当前节点 128 public void lastOrder(){ 129 lastOrder(this.root); 130 } 131 //后序遍历 遍历 以node 为根节点的二叉搜索树 132 private void lastOrder(Node node){ 133 if(node == null) 134 return; 135 136 //先遍历 左子树 137 lastOrder(node.left); 138 lastOrder(node.right); 139 System.out.println(node.t); 140 } 141 142 //二分搜索树的 层序遍历 143 public void levelOrder(){ 144 Queue<Node> queue = new LinkedList<>(); //因为 Queue本质是个接口,我们要选择它的一个实现类 145 146 queue.add(this.root); 147 148 while (!queue.isEmpty()){ 149 Node temp = queue.remove(); 150 System.out.println(temp.t); //访问 151 152 if(temp.left != null) 153 queue.add(temp.left); 154 if(temp.right != null) 155 queue.add(temp.right); 156 } 157 } 158 159 //寻找二分搜索树中的最小值 160 public T getMinimum(){ 161 if(this.size == 0) 162 throw new IllegalArgumentException("此时,树中为空!"); 163 164 return getMinimum(this.root); 165 } 166 //返回以 node为根节点中的 最小值 。 167 private T getMinimum(Node node){ 168 if(node.left == null) 169 return node.t; 170 return getMinimum(node.left); 171 } 172 173 174 //寻找二分搜索树中的最大值 175 public T getMaximum(){ 176 if(this.size == 0) 177 throw new IllegalArgumentException("此时,树中为空!"); 178 return getMaximum(this.root); 179 } 180 //返回以 node为根节点中的 最大值 。 181 private T getMaximum(Node node){ 182 if(node.right == null) 183 return node.t; 184 return getMaximum(node.right); 185 } 186 187 188 189 190 191 192 @Override 193 public String toString(){ 194 StringBuilder builder = new StringBuilder(); 195 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 196 return builder.toString(); 197 } 198 199 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 200 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 201 if(node == null){ 202 builder.append(generateDepthInfo(depth)+"|null \n"); 203 return; 204 } 205 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 206 207 generateBinarySearchTreeString(node.left,depth+1,builder); 208 generateBinarySearchTreeString(node.right,depth+1,builder); 209 } 210 //生成 关于深度的字符串。 211 private String generateDepthInfo(int depth){ 212 StringBuilder res = new StringBuilder(); 213 for (int i =0;i<depth;i++ ){ 214 res.append("="); //一个= 对应一个深度。 215 } 216 return res.toString(); 217 } 218 219 }
1 package cn.zcb.demo02; 2 3 public class Test{ 4 public static void main(String[] args) { 5 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 6 int [] nums = {5,3,6,8,4,2}; 7 for (int num :nums) 8 bst.add(num); 9 10 int ret = bst.getMinimum(); 11 int ret2 = bst.getMaximum(); 12 System.out.println("最小值 "+ret);//最小值 13 System.out.println("最大值 "+ret2);//最大值 14 15 } 16 } 17 /* 输出 18 最小值 2 19 最大值 8 20 * */
上面代码,我们可以寻找到 树中的最小值和最大值。
下面看如何删除最小值和最大值
删除时,
1,如果该节点是叶子节点,那么直接将其删除就可以了。
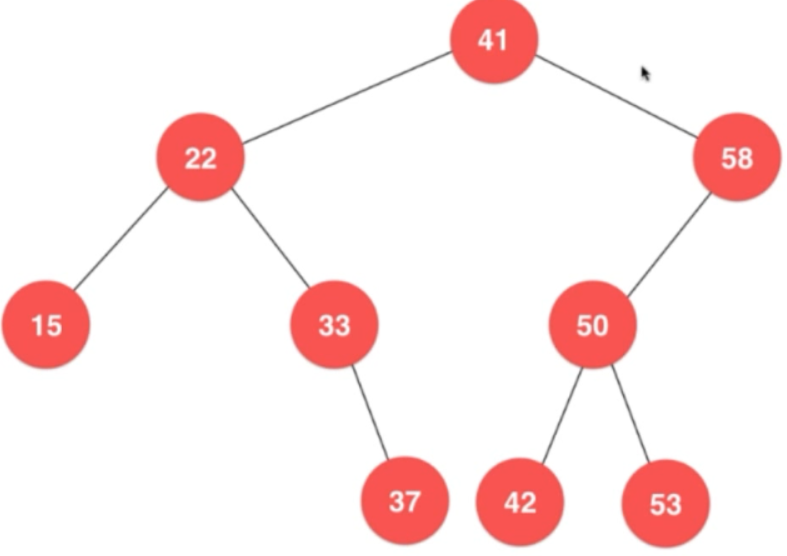
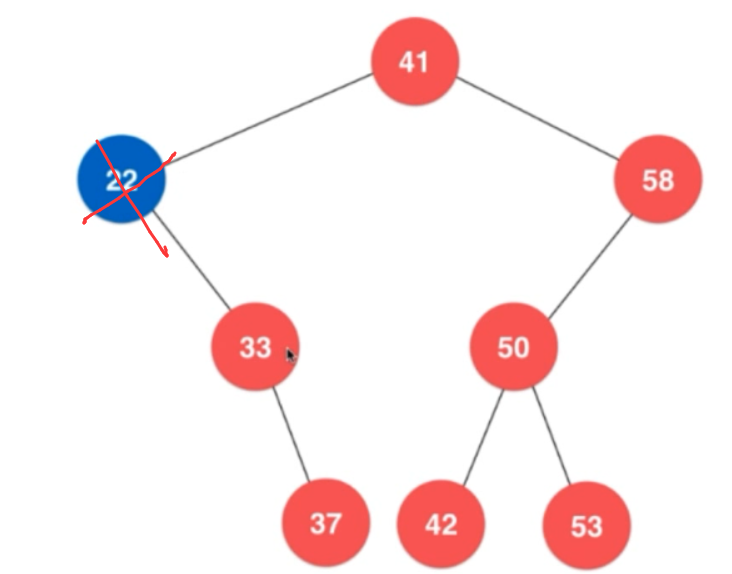
上图中直接将15删除就可以了!
2,如果该节点是不是叶子节点,此时要将该节点删除,之后将其右子树 放到自己父节点的左子树(即将自己带有的右子树放到自己原来的位置)。

删除最大值 的时候和最小值 思想一致
下面代码实现:
1 package cn.zcb.demo02; 2 3 import java.util.LinkedList; 4 import java.util.Queue; 5 import java.util.Stack; 6 7 public class BinarySearchTree<T extends Comparable<T>> { 8 //这里对树中存储的类型做了限制,它必须具有可比较性。 9 private class Node{ 10 public T t; 11 public Node left,right; 12 13 //Node 构造函数 14 public Node(T t){ 15 this.t = t; 16 this.left = null; 17 this.right = null; 18 } 19 20 } 21 22 //二分搜索树 的成员变量:1,根节点,2,size 23 private Node root; 24 private int size; 25 //二分搜索树的构造函数 26 public BinarySearchTree(){ 27 //此时一个元素都没有存 28 this.root = null ; 29 this.size = 0; 30 } 31 32 public int getSize(){ 33 return this.size; 34 } 35 public boolean isEmpty(){ 36 return this.size == 0; 37 } 38 39 //向二分搜索树 中添加新的元素e 40 public void add(T t){ 41 this.root = add(this.root,t); 42 } 43 //向 以node 为根节点 的 二分查找树中插入 元素 44 //返回 插入新节点后 二分搜索树的根 45 private Node add(Node node,T t) { 46 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 47 this.size ++; 48 return new Node(t); 49 } 50 if (t.compareTo(node.t) < 0){ 51 node.left = add(node.left, t); 52 } 53 else if(t.compareTo(node.t) >0 ){ 54 node.right = add(node.right, t); 55 } 56 return node; 57 } 58 59 60 //看 二分搜索树 中是否存在某个元素 t 61 public boolean contains(T t){ 62 63 return contains(this.root,t); 64 } 65 66 //看 以node 为根的二分搜索树 中是否存在某个元素 t 67 private boolean contains(Node node,T t){ 68 if(node == null){ 69 return false; 70 } 71 if(t.compareTo(node.t) == 0) 72 return true; 73 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 74 return contains(node.left,t); 75 else //此时只可能出现在右子树。 76 return contains(node.right,t); 77 } 78 79 // 二分搜索树的前序遍历 80 public void preOrder(){ 81 preOrder(this.root); 82 83 } 84 //遍历 以 node 为根节点的二分搜索树 85 private void preOrder(Node node){ 86 if(node == null) 87 return; 88 else 89 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 90 91 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 92 preOrder(node.right); 93 } 94 95 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 96 public void preOrderNR(){ 97 Stack<Node> stk = new Stack<>(); 98 stk.push(this.root); //将根节点的值压入栈中。 99 100 while (!stk.isEmpty()){ 101 Node temp = stk.pop(); 102 System.out.println(temp.t); //访问 103 104 if(temp.right != null) 105 stk.push(temp.right); 106 if(temp.left != null) 107 stk.push(temp.left); 108 } 109 } 110 111 112 //二分搜索树的中序遍历 先左 中 然后再右 113 public void midOrder(){ 114 midOrder(this.root); 115 } 116 //中序遍历 遍历以node 为根节点的树 117 private void midOrder(Node node){ 118 if(node == null) 119 return; 120 121 //先遍历该节点的左子树 122 midOrder(node.left); 123 System.out.println(node.t); 124 midOrder(node.right); 125 } 126 127 //二分搜索树后序遍历 先左 右 然后 当前节点 128 public void lastOrder(){ 129 lastOrder(this.root); 130 } 131 //后序遍历 遍历 以node 为根节点的二叉搜索树 132 private void lastOrder(Node node){ 133 if(node == null) 134 return; 135 136 //先遍历 左子树 137 lastOrder(node.left); 138 lastOrder(node.right); 139 System.out.println(node.t); 140 } 141 142 //二分搜索树的 层序遍历 143 public void levelOrder(){ 144 Queue<Node> queue = new LinkedList<>(); //因为 Queue本质是个接口,我们要选择它的一个实现类 145 146 queue.add(this.root); 147 148 while (!queue.isEmpty()){ 149 Node temp = queue.remove(); 150 System.out.println(temp.t); //访问 151 152 if(temp.left != null) 153 queue.add(temp.left); 154 if(temp.right != null) 155 queue.add(temp.right); 156 } 157 } 158 159 //寻找二分搜索树中的最小值 160 public T getMinimum(){ 161 if(this.size == 0) 162 throw new IllegalArgumentException("此时,树中为空!"); 163 164 return getMinimum(this.root); 165 } 166 //返回以 node为根节点中的 最小值 。 167 private T getMinimum(Node node){ 168 if(node.left == null) 169 return node.t; 170 return getMinimum(node.left); 171 } 172 173 174 //寻找二分搜索树中的最大值 175 public T getMaximum(){ 176 if(this.size == 0) 177 throw new IllegalArgumentException("此时,树中为空!"); 178 return getMaximum(this.root); 179 } 180 //返回以 node为根节点中的 最大值 。 181 private T getMaximum(Node node){ 182 if(node.right == null) 183 return node.t; 184 return getMaximum(node.right); 185 } 186 187 //从二分搜索树中 删除最小值所在的节点。返回最小值 188 public T removeMin(){ 189 T ret = getMinimum(); //获取最小值 190 191 //删除最小值所在的节点。 192 this.root = removeMin(this.root); 193 return ret; 194 } 195 //删除掉 以 node为根节点的树中的最小节点, 196 //并将删除节点后的 新的二分搜索树的根节点 返回出来 197 private Node removeMin(Node node){ 198 if(node.left == null) { 199 Node temp = node.right; //此时node.right 可能为null ,也可能不为空, 200 node.right = null; 201 this.size --; 202 return temp; 203 } 204 205 node.left = removeMin(node.left); 206 return node; 207 } 208 209 //从二分搜索树中 删除最大值所在的节点。返回最大值 210 public T removeMax(){ 211 T ret = getMaximum(); 212 213 this.root = removeMax(this.root); 214 return ret; 215 } 216 217 //删除 以 node 为根节点 的二叉树, 218 //返回 删除最小值节点 之后的新的 二叉树的 根节点 219 private Node removeMax(Node node){ 220 if(node.right == null){ 221 Node temp = node.left; //此时node.left 可能为null ,也可能不为空, 222 node.left = null; 223 this.size --; 224 return temp; 225 } 226 node.right = removeMax(node.right); 227 return node; 228 } 229 230 231 232 233 234 235 236 237 @Override 238 public String toString(){ 239 StringBuilder builder = new StringBuilder(); 240 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 241 return builder.toString(); 242 } 243 244 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 245 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 246 if(node == null){ 247 builder.append(generateDepthInfo(depth)+"|null \n"); 248 return; 249 } 250 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 251 252 generateBinarySearchTreeString(node.left,depth+1,builder); 253 generateBinarySearchTreeString(node.right,depth+1,builder); 254 } 255 //生成 关于深度的字符串。 256 private String generateDepthInfo(int depth){ 257 StringBuilder res = new StringBuilder(); 258 for (int i =0;i<depth;i++ ){ 259 res.append("="); //一个= 对应一个深度。 260 } 261 return res.toString(); 262 } 263 264 }
1 package cn.zcb.demo02; 2 3 import java.util.ArrayList; 4 import java.util.Random; 5 6 public class Test{ 7 public static void main(String[] args) { 8 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 9 10 Random random = new Random(); 11 int n = 1000; //1000个【0-9999】的随机数 加入到二叉树中! 最终二叉树中的个数不一定是1000个,因为这里的二叉树中不能有重复的值! 12 for (int i =0;i<n;i++){ 13 bst.add(random.nextInt(10000)); 14 } 15 16 ArrayList <Integer> arrayList = new ArrayList<>(); 17 while (!bst.isEmpty()){ //当二叉树不为空时,就移除它的最小值。并将最小值加入到 我们的arrayList 中! 18 arrayList.add(bst.removeMin()); 19 } 20 System.out.println(arrayList); //此时的arrayList 中的顺序应当是 从小到大 ! 21 System.out.println("二叉树的节点数量是 "+arrayList.size()); 22 23 //代码验证 arrayList是否为 从小到大 24 for (int i=0;i<arrayList.size() -1 ;i++){ 25 if(arrayList.get(i) > arrayList.get(i+1)) 26 throw new IllegalArgumentException("Error"); 27 } 28 //如果经过这个循环,没有抛出异常,就说明arrayList 是从小到大! 29 //对于 removeMax() 的测试和removeMin()一致! 30 } 31 } 32 /* 输出 33 [26, 45, 46, 57, 60, 67, 83, 87, 88, 89, 97, 103, 130, 135, 140, 142, 149, 158, 185, 226, 250,.....] 34 二叉树的节点数量是 962 35 * */
删除二分搜索树的任意值:
对于删除一个节点:
要分下面几个情况:
1,删除只有左孩子的节点
2,删除只有右孩子的节点
上面两种情况,也包含了删除叶子节点的情况。 (它们的代码类似于删除最大值和删除最小值)
最麻烦的是下面这种:
3,删除既有左孩子又有右孩子的节点。 (方法是:1962年,Hibbard 提出的--Hibbard Deletion)
第三种情况:如何删除58呢?
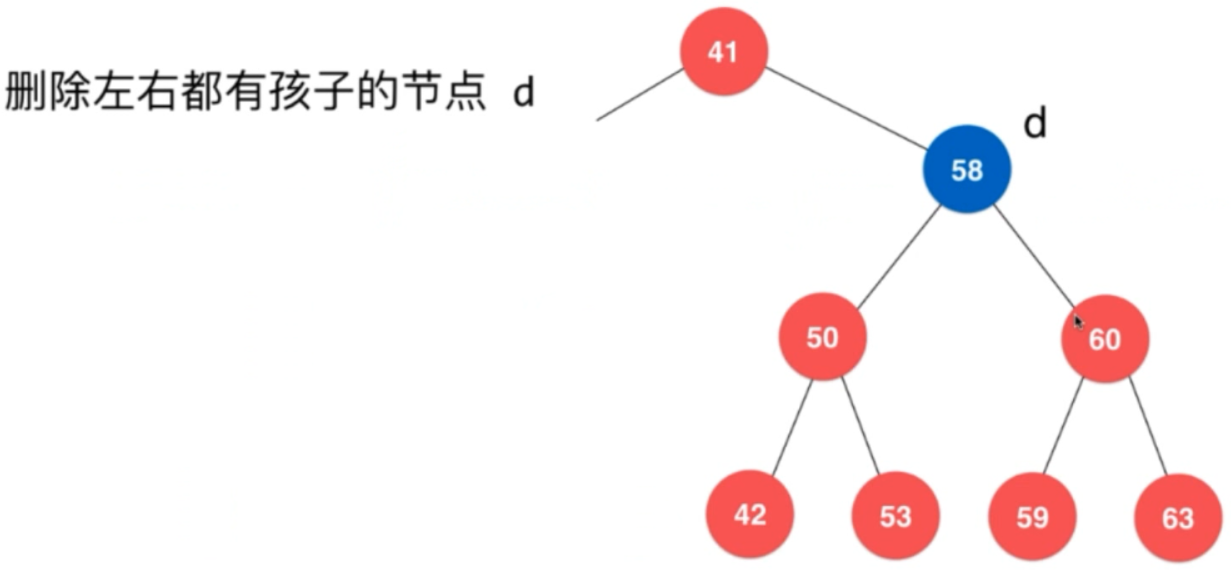
把58删除之后,要把剩下的两个子树融合在一起,
如何解决呢?
需要找一个节点,把58给替代了。寻找方法是找一个58 的后继节点(比58大,而且离58 最近!!!)
这里找的就是59!
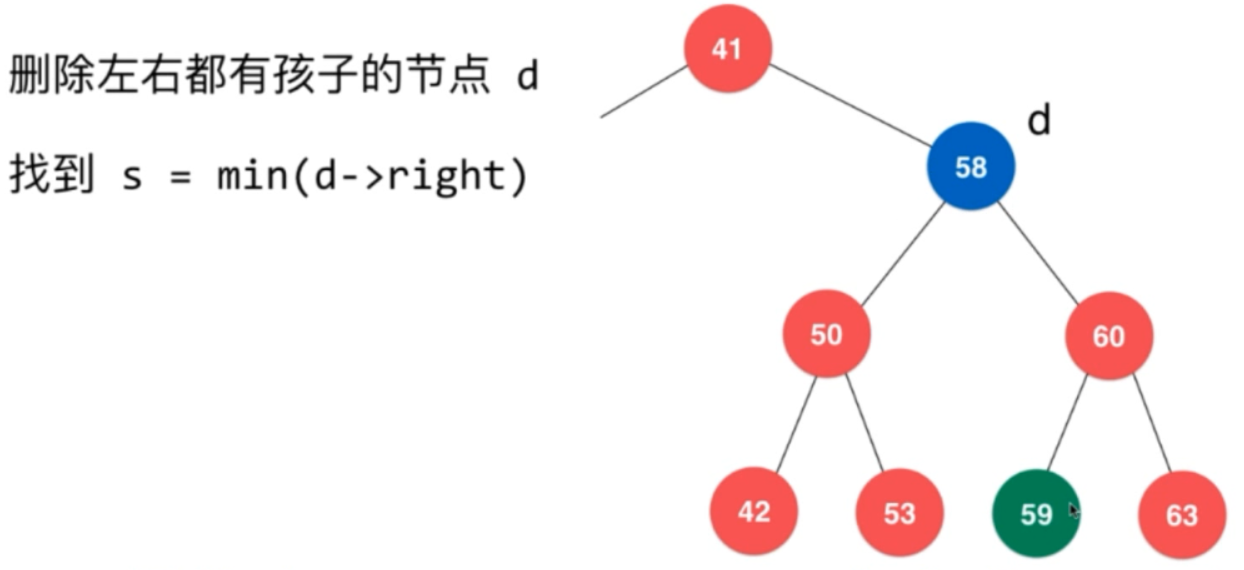
如何找到的呢?
其实就是58 的右子树中的最小值的那个节点。即 min(d->right);
找到59 之后,将它从它删除并让它替换掉58!如图:


此时就可以放心的把d给删除了 :
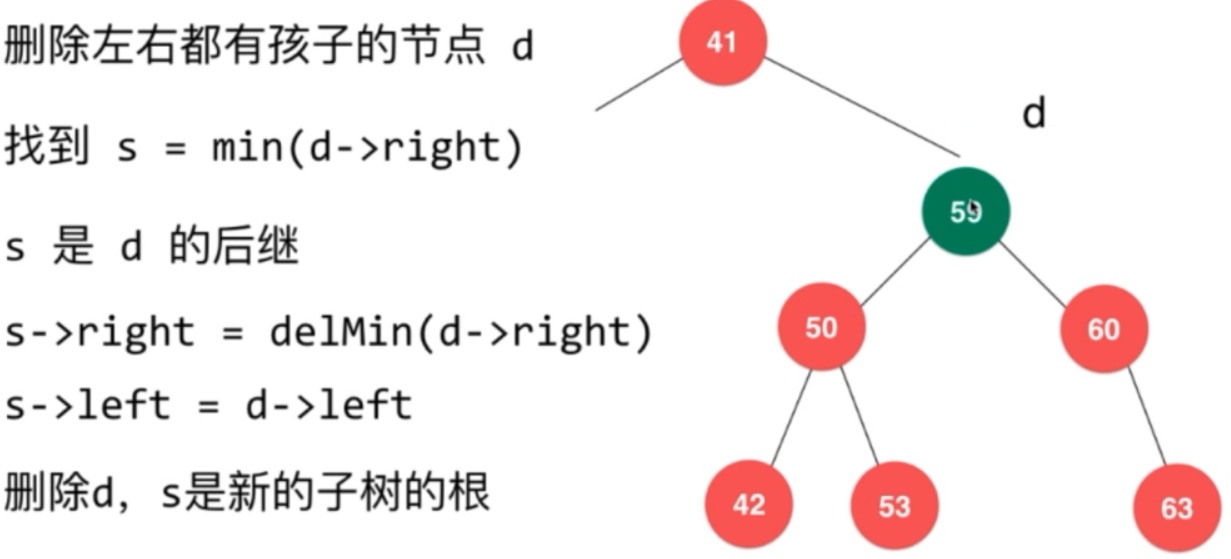
1 package cn.zcb.demo02; 2 3 import java.util.LinkedList; 4 import java.util.Queue; 5 import java.util.Stack; 6 7 public class BinarySearchTree<T extends Comparable<T>> { 8 //这里对树中存储的类型做了限制,它必须具有可比较性。 9 private class Node{ 10 public T t; 11 public Node left,right; 12 13 //Node 构造函数 14 public Node(T t){ 15 this.t = t; 16 this.left = null; 17 this.right = null; 18 } 19 20 } 21 22 //二分搜索树 的成员变量:1,根节点,2,size 23 private Node root; 24 private int size; 25 //二分搜索树的构造函数 26 public BinarySearchTree(){ 27 //此时一个元素都没有存 28 this.root = null ; 29 this.size = 0; 30 } 31 32 public int getSize(){ 33 return this.size; 34 } 35 public boolean isEmpty(){ 36 return this.size == 0; 37 } 38 39 //向二分搜索树 中添加新的元素e 40 public void add(T t){ 41 this.root = add(this.root,t); 42 } 43 //向 以node 为根节点 的 二分查找树中插入 元素 44 //返回 插入新节点后 二分搜索树的根 45 private Node add(Node node,T t) { 46 if (node == null) { //上次的终止条件 太过于庞杂,其实这样就可以了。 47 this.size ++; 48 return new Node(t); 49 } 50 if (t.compareTo(node.t) < 0){ 51 node.left = add(node.left, t); 52 } 53 else if(t.compareTo(node.t) >0 ){ 54 node.right = add(node.right, t); 55 } 56 return node; 57 } 58 59 60 //看 二分搜索树 中是否存在某个元素 t 61 public boolean contains(T t){ 62 63 return contains(this.root,t); 64 } 65 66 //看 以node 为根的二分搜索树 中是否存在某个元素 t 67 private boolean contains(Node node,T t){ 68 if(node == null){ 69 return false; 70 } 71 if(t.compareTo(node.t) == 0) 72 return true; 73 else if(t.compareTo(node.t) < 0) //此时只可能出现在左子树。 74 return contains(node.left,t); 75 else //此时只可能出现在右子树。 76 return contains(node.right,t); 77 } 78 79 // 二分搜索树的前序遍历 80 public void preOrder(){ 81 preOrder(this.root); 82 83 } 84 //遍历 以 node 为根节点的二分搜索树 85 private void preOrder(Node node){ 86 if(node == null) 87 return; 88 else 89 System.out.println(node.t); //t一定是可以比较的。上面接口已经限制了。 90 91 preOrder(node.left); //先递归完 左子树之后,再递归右子树。 92 preOrder(node.right); 93 } 94 95 // 二分搜索树的前序遍历 (使用非递归 NR 实现,利用 栈 来实现!!!) 96 public void preOrderNR(){ 97 Stack<Node> stk = new Stack<>(); 98 stk.push(this.root); //将根节点的值压入栈中。 99 100 while (!stk.isEmpty()){ 101 Node temp = stk.pop(); 102 System.out.println(temp.t); //访问 103 104 if(temp.right != null) 105 stk.push(temp.right); 106 if(temp.left != null) 107 stk.push(temp.left); 108 } 109 } 110 111 112 //二分搜索树的中序遍历 先左 中 然后再右 113 public void midOrder(){ 114 midOrder(this.root); 115 } 116 //中序遍历 遍历以node 为根节点的树 117 private void midOrder(Node node){ 118 if(node == null) 119 return; 120 121 //先遍历该节点的左子树 122 midOrder(node.left); 123 System.out.println(node.t); 124 midOrder(node.right); 125 } 126 127 //二分搜索树后序遍历 先左 右 然后 当前节点 128 public void lastOrder(){ 129 lastOrder(this.root); 130 } 131 //后序遍历 遍历 以node 为根节点的二叉搜索树 132 private void lastOrder(Node node){ 133 if(node == null) 134 return; 135 136 //先遍历 左子树 137 lastOrder(node.left); 138 lastOrder(node.right); 139 System.out.println(node.t); 140 } 141 142 //二分搜索树的 层序遍历 143 public void levelOrder(){ 144 Queue<Node> queue = new LinkedList<>(); //因为 Queue本质是个接口,我们要选择它的一个实现类 145 146 queue.add(this.root); 147 148 while (!queue.isEmpty()){ 149 Node temp = queue.remove(); 150 System.out.println(temp.t); //访问 151 152 if(temp.left != null) 153 queue.add(temp.left); 154 if(temp.right != null) 155 queue.add(temp.right); 156 } 157 } 158 159 //寻找二分搜索树中的最小值 160 public T getMinimum(){ 161 if(this.size == 0) 162 throw new IllegalArgumentException("此时,树中为空!"); 163 164 return getMinimum(this.root).t; 165 } 166 //返回以 node为根节点中的 最小值 。 167 private Node getMinimum(Node node){ 168 if(node.left == null) 169 return node; 170 return getMinimum(node.left); 171 } 172 173 174 //寻找二分搜索树中的最大值 175 public T getMaximum(){ 176 if(this.size == 0) 177 throw new IllegalArgumentException("此时,树中为空!"); 178 return getMaximum(this.root).t; 179 } 180 //返回以 node为根节点中的 最大值 。 181 private Node getMaximum(Node node){ 182 if(node.right == null) 183 return node; 184 return getMaximum(node.right); 185 } 186 187 //从二分搜索树中 删除最小值所在的节点。返回最小值 188 public T removeMin(){ 189 T ret = getMinimum(); //获取最小值 190 191 //删除最小值所在的节点。 192 this.root = removeMin(this.root); 193 return ret; 194 } 195 //删除掉 以 node为根节点的树中的最小节点, 196 //并将删除节点后的 新的二分搜索树的根节点 返回出来 197 private Node removeMin(Node node){ 198 if(node.left == null) { 199 Node temp = node.right; //此时node.right 可能为null ,也可能不为空, 200 node.right = null; 201 this.size --; 202 return temp; 203 } 204 205 node.left = removeMin(node.left); 206 return node; 207 } 208 209 //从二分搜索树中 删除最大值所在的节点。返回最大值 210 public T removeMax(){ 211 T ret = getMaximum(); 212 213 this.root = removeMax(this.root); 214 return ret; 215 } 216 217 //删除 以 node 为根节点 的二叉树, 218 //返回 删除最小值节点 之后的新的 二叉树的 根节点 219 private Node removeMax(Node node){ 220 if(node.right == null){ 221 Node temp = node.left; //此时node.left 可能为null ,也可能不为空, 222 node.left = null; 223 this.size --; 224 return temp; 225 } 226 node.right = removeMax(node.right); 227 return node; 228 } 229 230 //从二分搜索树上 删除任意元素 t 231 public void remove(T t){ 232 this.root = remove(this.root,t); 233 } 234 // 删除 以 Node 为根节点的二分搜索树中的任意值 235 // 返回删除之后 新的二分搜索树的 根节点 236 private Node remove(Node node,T t){ 237 if(node == null) 238 return null; //没找到要删除的t ,此时什么都不干! 239 if(t.compareTo(node.t) < 0) { 240 node.left = remove(node.left, t); 241 return node; 242 } 243 else if(t.compareTo(node.t) >0) { 244 node.right = remove(node.right, t); 245 return node; 246 }else{ 247 //此时就找到了要删除的元素! 248 if(node.left == null){ //此时,是只有右子树的情况 右子树也可能为null 249 Node temp = node.right; 250 node.right = null; 251 this.size --; 252 return temp; 253 } 254 if(node.right == null){ //此时,是只有左子树的情况 左子树也可能为null 255 Node temp = node.left; 256 node.left = null; 257 this.size --; 258 return temp; 259 } 260 //此时 是该节点既有左子树,又有右子树,而且左右子树都不为null 261 Node temp = getMinimum(node.right); // 找到当前节点 的右子树中的 最小节点。 262 temp.right = removeMin(node.right); //删除 右子树的最小节点,并将右子树的根节点 连在temp。right上。 263 temp.left = node.left; 264 //此时的node 就可以被删除了。 265 node.left = node.right = null; //或者用 node =null; 直接删除 266 // this.size --; 它是不需要的,因为我们在 removeMin 中已经进行了 this.size-- ; 267 return temp; 268 } 269 } 270 271 272 @Override 273 public String toString(){ 274 StringBuilder builder = new StringBuilder(); 275 generateBinarySearchTreeString(this.root,0,builder); //builder是传出参数 276 return builder.toString(); 277 } 278 279 //生成以 node 为根节点,深度为depth 的 描述二叉树的 字符串 280 private void generateBinarySearchTreeString(Node node,int depth,StringBuilder builder){ 281 if(node == null){ 282 builder.append(generateDepthInfo(depth)+"|null \n"); 283 return; 284 } 285 builder.append(generateDepthInfo(depth)+node.t+"\n"); //不要忘了!!! 286 287 generateBinarySearchTreeString(node.left,depth+1,builder); 288 generateBinarySearchTreeString(node.right,depth+1,builder); 289 } 290 //生成 关于深度的字符串。 291 private String generateDepthInfo(int depth){ 292 StringBuilder res = new StringBuilder(); 293 for (int i =0;i<depth;i++ ){ 294 res.append("="); //一个= 对应一个深度。 295 } 296 return res.toString(); 297 } 298 299 }
1 package cn.zcb.demo02; 2 3 4 public class Test{ 5 public static void main(String[] args) { 6 BinarySearchTree<Integer> bst = new BinarySearchTree<>(); 7 int [] arr = {1,23,4,34,43,87,45,554,43,56}; 8 for (int i = 0;i<arr.length;i++){ 9 bst.add(arr[i]); 10 } 11 System.out.println(bst); //打印二叉树! 12 13 //删除 45 的节点 14 bst.remove(45); 15 System.out.println("======分界线====="); 16 System.out.println(bst); 17 18 } 19 } 20 /* 输出 21 1 22 =|null 23 =23 24 ==4 25 ===|null 26 ===|null 27 ==34 28 ===|null 29 ===43 30 ====|null 31 ====87 32 =====45 33 ======|null 34 ======56 35 =======|null 36 =======|null 37 =====554 38 ======|null 39 ======|null 40 41 ======分界线===== 42 1 43 =|null 44 =23 45 ==4 46 ===|null 47 ===|null 48 ==34 49 ===|null 50 ===43 51 ====|null 52 ====87 53 =====56 54 ======|null 55 ======|null 56 =====554 57 ======|null 58 ======|null 59 * */
最后,补充:
在找节点替代的时候,其实不一定要找右子树中的最小的。
也可以找左子树中的最大的。如下图:
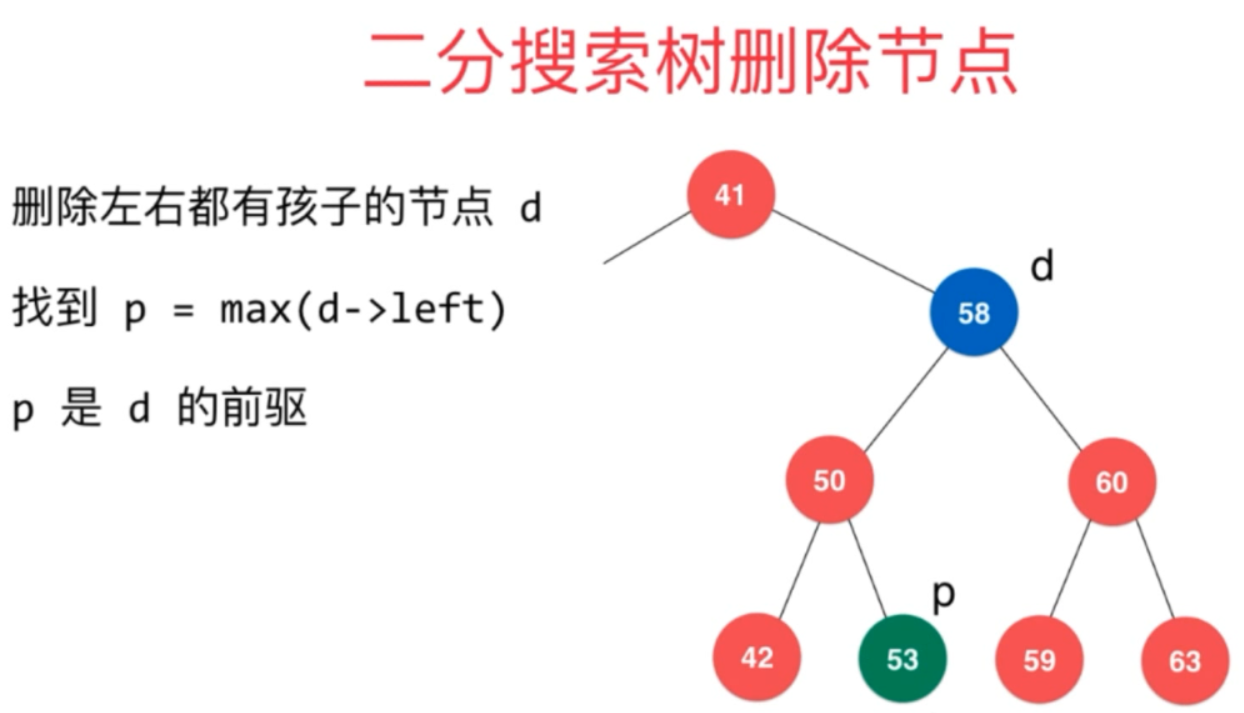
更多二分搜索树相关话题:
二分搜索树具有顺序性:
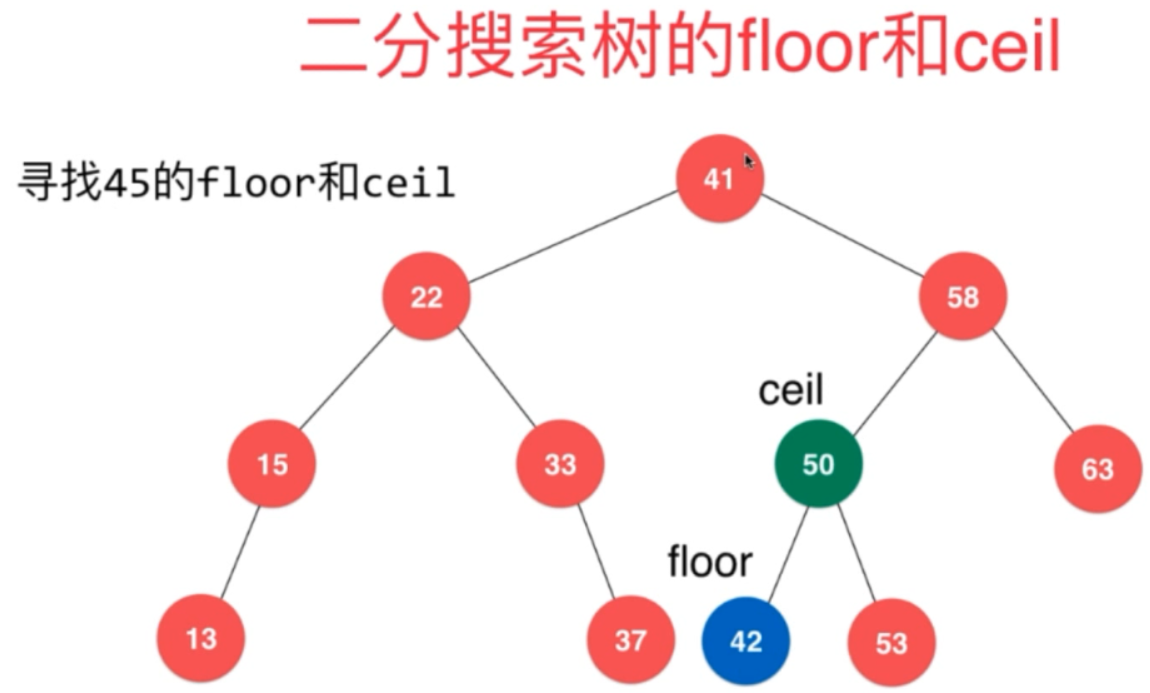
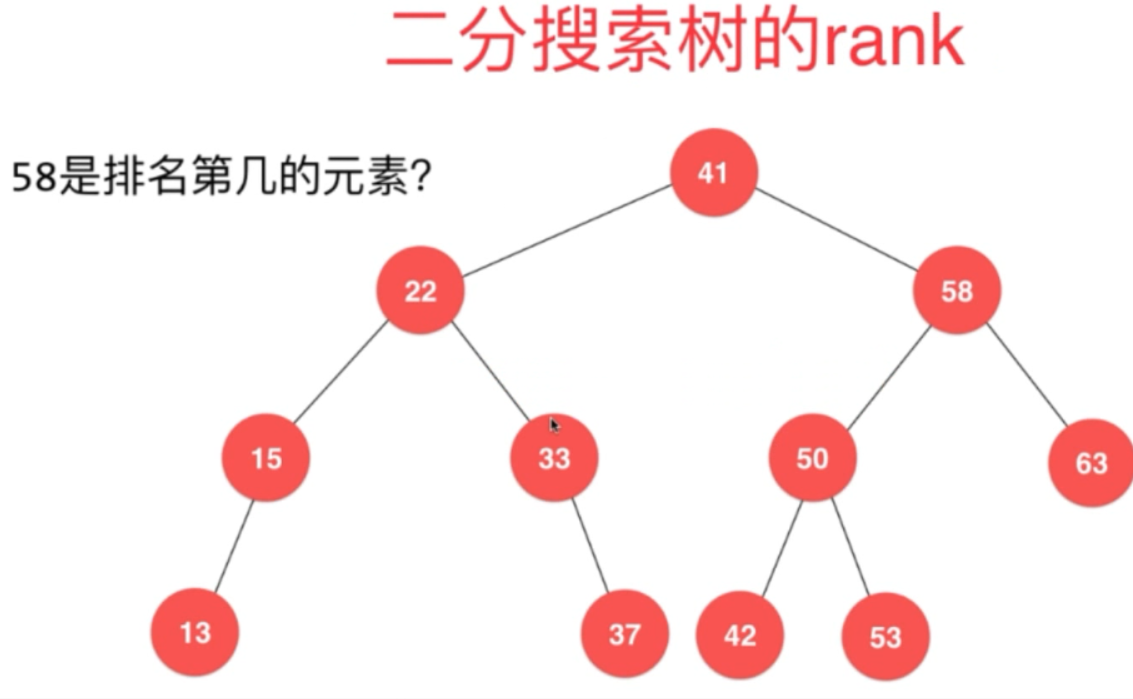

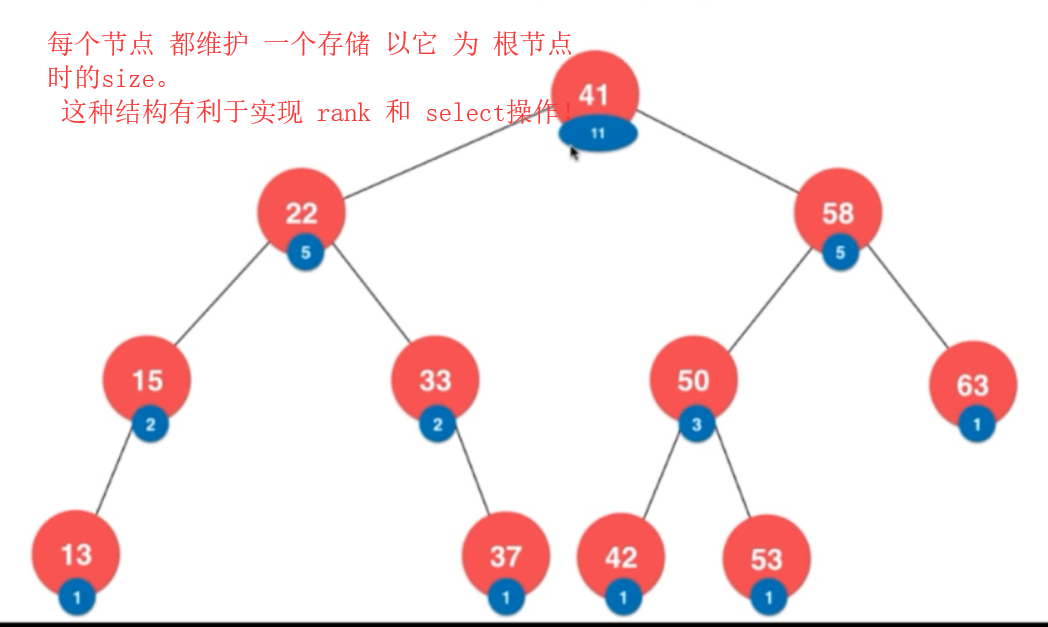
而且此时就不需要整个二分搜索树的size 了。如果想看的话,直接this.root.size 即可了!
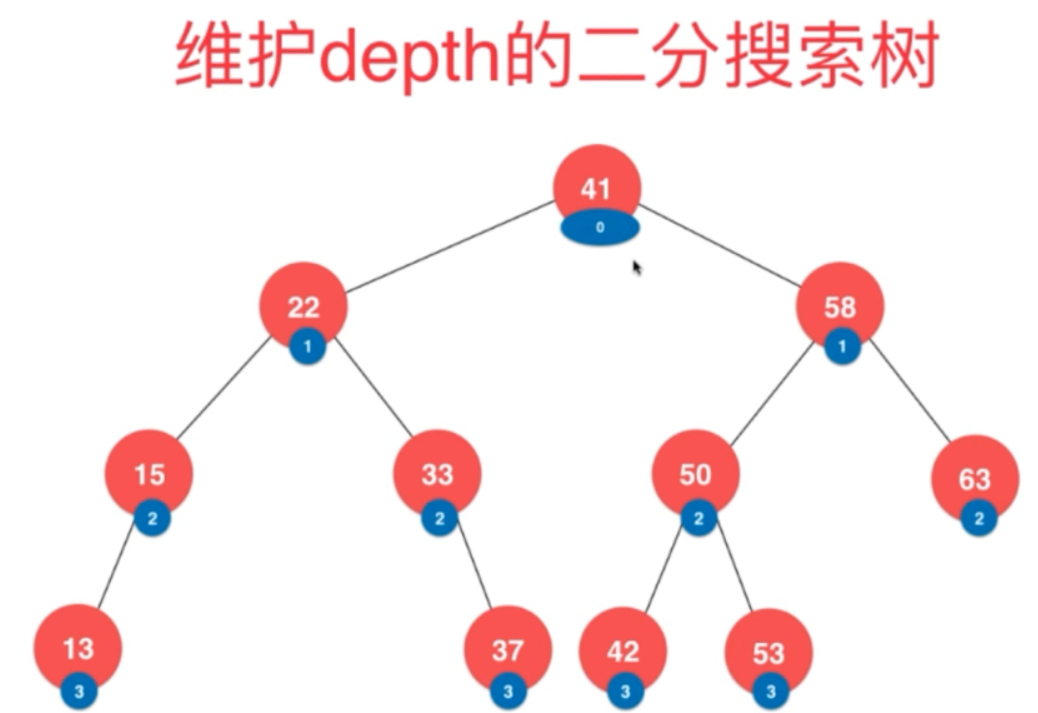
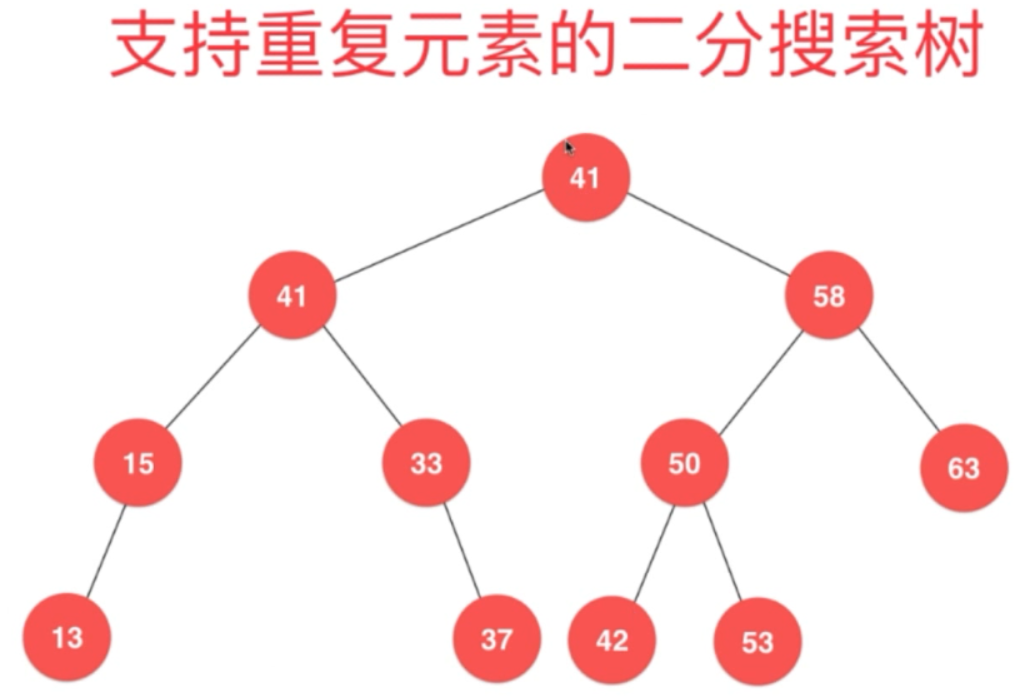
二分搜索树的时间复杂度分析暂时不说,后面说。
下一章也将会看到二分搜索树的应用---集合和映射,
与此同时,下一章不仅使用二分搜索树实现集合和映射,也会用数组和链表来实现!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号