


正则表达式/re模块
一.正则表达式
1.1正则表达式和re模块的关系
正则表达式不是python独有的,它是一门独立的技术,在所有的编程语言中都可以使用,但是在python中使用正则表达式需要借助re模块
1.2正则表达式的作用以及使用领域
正则表达式是用来筛选字符串中特定的内容的,如果像匹配具体的内容,可以直接写完整的内容,不需要写正则
正则表达式现一般用在爬虫领域和数据分析
1.3字符组


字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
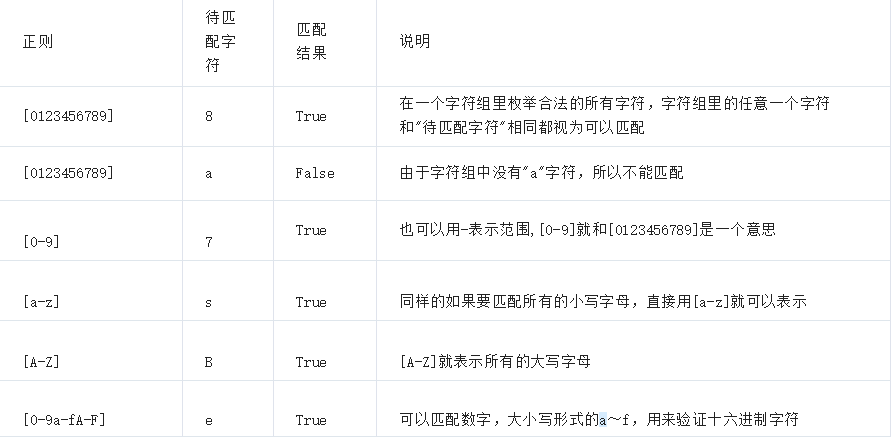
ps:在字符组中表达式之间是或的关系如[0-9a-z]表示该位是数字或者小写字母
1.4字符
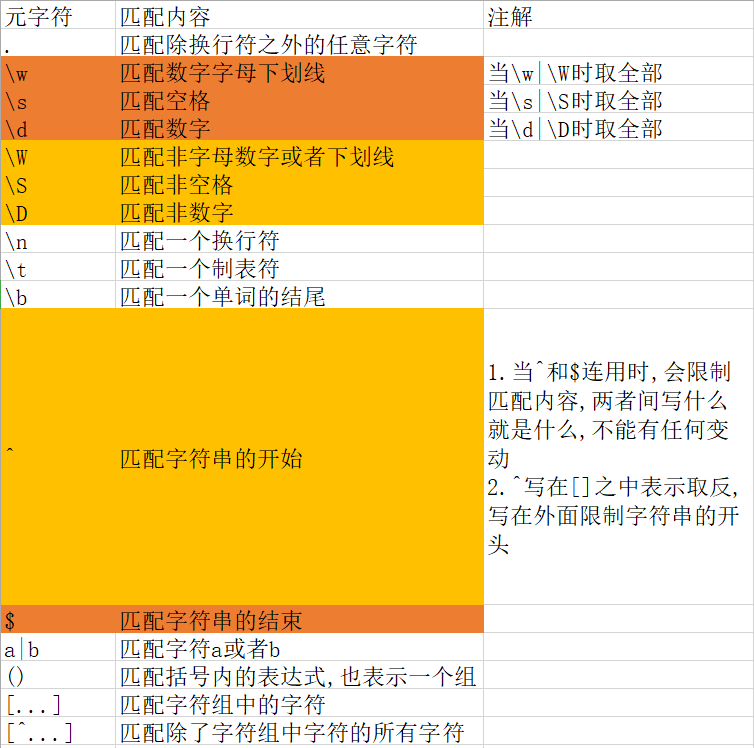
1.5量词

ps:量词必须更在正则符号的后面如.*其表示为取除了换行符外的任意字符且数目尽量取至最大.原因是正则在匹配的时候默认的是贪婪匹配(尽量匹配多的),若想解决这种问日可以在量词后面加?,如+?,这样就将贪婪匹配转化成惰性匹配.
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x res = ('^[1-9]\d{16}[0-9x]|^[1-9]\d{14}')
二.re模块
re模块:在使用re模块中主要使用三种功能:findall,search,match
2.1:findall
基本句式: findall('正则表达式','带匹配的字符串')
res1 = re.findall('[a-z]+','zhang LOVE who is a probleam') res2 = re.findall('[a-z]+','zhAng LOVE who is a proBleam') print(res1) # ['zhang', 'who', 'is', 'a', 'probleam'] print(res2) # ['zh', 'ng', 'who', 'is', 'a', 'pro', 'leam'] # 找出字符串中符合正则表达式全部内容 并且返回的是一个列表,列表中的元素就是正则匹配到的结果
ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # 忽略分组优先的机制 print(ret1) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 print(ret2) # ['www.oldboy.com'] 可以用?:来取消权限
2.2search
search基本句式:search('正则表达式','带匹配的字符串')
res1 = re.search('a','zhang LOVE who is a probleam') print(res1) # search不会给你直接返回匹配到的结果 而是给你返回一个对象 <_sre.SRE_Match object; span=(2, 3), match='a'>
if res1:
print(res1.group()) # a
res1 = re.search('k','zhang LOVE who is a probleam') print(res1) # None if res1: print(res1.group())
ps:1.search只会依据正则表达式查一次,只要找到一个结果就不会往后找了
2.当查找的结果存在返回的是一个对象,需要调用group才能才看
3.当检查的结果不存在返回的值是None,当调用group时会报错,所以在使用时采用if判断,若果返回值为真则调用group取解析
2.3match
res = re.match('z','zhang LOVE who is a probleam') print(res) # search不会给你直接返回匹配到的结果 而是给你返回一个对象 <_sre.SRE_Match object; span=(0, 1), match='z'>
if res:
print(res.group()) # z
ps:match只会匹配字符串开始的部分,若没有符合的返回的值也是None,调用group会报错
2.4其余功能指令
split:
ret = re.split('[ad]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'd'分割 print(ret) # ['', 'bc', ''] 返回的还是列表
ret=re.split("\d+","zhang9929zhang66wang") print(ret) # 结果 :['zhang', 'zhang', 'wang'] ret1=re.split("(\d+)","zhang9929zhang66wang") print(ret1) # 结果 : ['zhang', '9929', 'zhang', '66', 'wang']
sub命令:sub('正则表达式','新的内容','待替换的字符串',n)
ret = re.sub('\d', ' love ', 'zhang9zhang2zhang9',1) # 将数字替换成'H',参数1表示只替换1个 print(ret) # zhang love zhang2zhang9
ps:subn命令的应用
ret = re.subn('\d', ' love ', 'zhang9zhang2zhang9') # 将数字替换成' love ',返回元组(替换的结果,替换了多少次) ret1 = re.subn('\d', ' love ', 'zhang9zhang2zhang9',1) # 将数字替换成' love ',返回元组(替换的结果,替换了多少次) print(ret) # ('zhang love zhang love zhang love ', 3)返回的是一个元组 元组的第二个元素代表的是替换的个数 print(ret1) # ('zhang love zhang2zhang9', 1)
compile命令:将正则表达式编译成一个正则表达式对象
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 res1 = obj.findall('347982734729349827384') print(ret.group()) #结果 : 123 print(res1) #结果 : ['347', '982', '734', '729', '349', '827', '384']
finditer:返回一个存放匹配结果的迭代器
ret = re.finditer('\d', '43asds54') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x000001A35617B2B0> print(next(ret).group()) # 等价于ret.__next__() # 4 print(next(ret).group()) # 等价于ret.__next__() # 3 print(next(ret).group()) # 等价于ret.__next__() # 5 print(next(ret).group()) # 等价于ret.__next__() # 4 print(next(ret).group()) # 等价于ret.__next__() 超出迭代取值的范围 直接报错
?P:为正则表达式取别名
res = re.search('^[1-9](?P<password>\d{14})(?P<username>\d{2}[0-9x])?$','110105199812067023') print(res.group()) # 110105199812067023 print(res.group('password')) # 10105199812067 print(res.group(1)) # 10105199812067 print(res.group('username')) # 023 print(res.group(2)) # 023
ps:在取完别名后,由于采用的是searc方法,调用group,可以指定名字的顺序来读取内容(从开始)

