pdf教程爬取
起由
觉得c语言中文网的教程总体水平很棒,又怕哪天站长突然删了这些教程(以前遇到过),所以充了个vip会员,并写了个爬虫将教程全部保存到本地的pdf,留给以后自己慢慢看,不做扩散,只做合理合法的使用,如果要使用该爬虫,需要自己去充值c语言中文网的vip会员,以及注册超级鹰账号
分析
- 如下图所示,由于vip的文章是通过ajax动态加载出来的,并且不能提前解析,故requests无法直接获取到网页,只能通过selenium加载浏览器获取

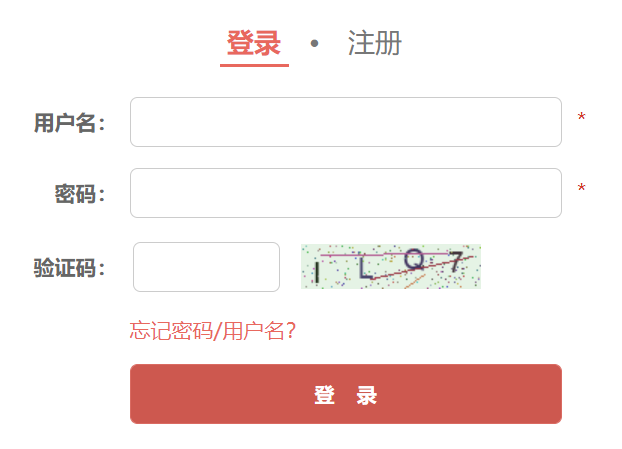
- 登录认证时,需要输入图片识别码,一种方法是用pytesseract ocr识别(对这种中英文混杂且有杂点的非常不准),另一种方法是提交到超级鹰(需要注册账号,但不贵),经测试采用后者效果很好
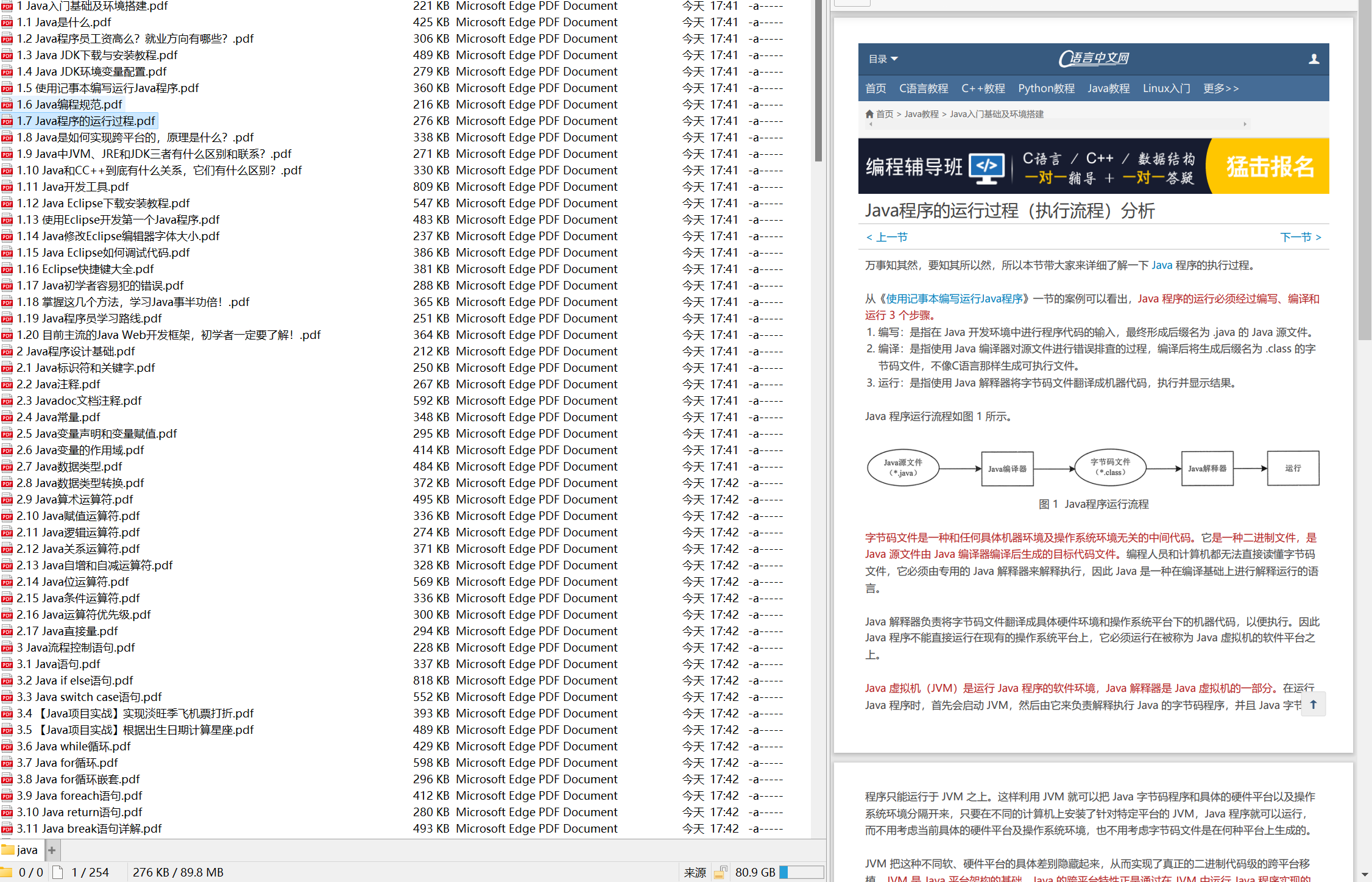
- 教程按照网页结构可以分为三种,不带一级标题、只带一级标题和带二级标题的,需要用不同的方法解析 (下图只写了一部分教程)

- 对于如何将网页保存为pdf,尝试了很多方法
- 先保存为html,然后用pdfkit转,但是存在不包含css\js等资源的问题
- 保存为mhtml,包含css/js资源,可以显示图片等,但是接口过老
- 用selenium调用chrome的打印功能,直接保存为pdf,测试可行
结果
用的手机流量下的,不敢全部下,只下了11个教程,400M,10分钟,考虑到selenium驱动和图片识别等问题,没有开多线程,所以下的很慢
- 日志

- 下载结果
代码
import json
import os.path
import shutil
from time import sleep
import pytesseract
from PIL import Image
from chaojiying import Chaojiying_Client
from pyquery import PyQuery as pq
from selenium import webdriver
login_page = "http://vip.biancheng.net/login.php"
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"}
login_name = "" #教程网账号
login_pwd = "" #教程网密码
chaoji_name = "" #超级鹰账号
chaoji_pwd = "" #超级鹰密码
chaoji_code = "" #超级鹰软件识别号
try_time = 5 #尝试登录次数
main_url = "http://c.biancheng.net"
download_list_0 = ["django", "c/practice", "stl"] #零级标题
download_list_1 = ["redis", "csharp", "js", "python_spider", "qt"] #一级标题
download_list_2 = ["java", "golang", "mysql"] #二级标题
def init_browser():
# 设置打印机的纸张大小、打印类型、保存路径等
chrome_options = webdriver.ChromeOptions()
settings = {
"recentDestinations": [{
"id": "Save as PDF",
"origin": "local",
"account": ""
}],
"selectedDestinationId": "Save as PDF",
"version": 2,
"isHeaderFooterEnabled": False,
# "customMargins": {},
# "marginsType": 2,#边距(2是最小值、0是默认)
# "scaling": 100,
# "scalingType": 3,
# "scalingTypePdf": 3,
# "isLandscapeEnabled": True, # 若不设置该参数,默认值为纵向
"isCssBackgroundEnabled": True,
"mediaSize": {
"height_microns": 297000,
"name": "ISO_A4",
"width_microns": 210000,
"custom_display_name": "A4"
},
}
chrome_options.add_argument('--enable-print-browser')
# chrome_options.add_argument('--headless') #headless模式下,浏览器窗口不可见,可提高效率
file_directory = os.path.join(os.getcwd(), "result/")
prefs = {
'printing.print_preview_sticky_settings.appState': json.dumps(settings),
'savefile.default_directory': file_directory # 此处填写你希望文件保存的路径,可填写your file path默认下载地址
}
chrome_options.add_argument('--kiosk-printing') # 静默打印,无需用户点击打印页面的确定按钮
chrome_options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(options=chrome_options)
browser.maximize_window() # 浏览器最大化
return browser
#注意截图时需要将屏幕缩放调到100%
def save_img():
browser.save_screenshot('page.png') # save_screenshot:将当前页面进行截图并保存下来
code_img_ele = browser.find_element("id", "captcha-img")
location = code_img_ele.location # 验证码左上角的坐标x,y
size = code_img_ele.size # 验证码图片对应的长和宽
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
image1 = Image.open('./page.png')
frame = image1.crop((left, top, right, bottom)) #裁剪时需要将电脑缩放调至100%
frame.save('./code.png')
return code_img_ele
#缩小图片
def narrow_img():
code = Image.open('./code.png')
small_img = code.resize((150, 70))
small_img.save('./small_img.png')
#方式一:用ocr tessert进行识别,不好用
def ocr_captchr():
img = Image.open(r'1.png')
# 将彩色图像转换为灰度图像并保存
gray_img = img.convert('L')
gray_img.show()
gray_img.save("2.jpg")
# 设置阈值将图像二值化,一般为白色(0)或者黑色(1),更好处理
value = 200
two_table = [] # 像素的映射表,比如1-200之间的像素映射为255其他映射为0变为黑白图像
for i in range(256):
if i < value:
two_table.append(255)
else:
two_table.append(0)
# 将映射表和之前的二值图像关联起来,即使用映射的像素,进行一一转换
out_img = gray_img.point(two_table, "1")
out_img=out_img.resize((550,260))
out_img.save("5.jpg")
out_img.show()
th = Image.open("5.jpg")
str = pytesseract.image_to_string(th)
print(str)
#方式二:用超级鹰进行图片识别,好用,收费便宜
def get_captcha():
save_img()
narrow_img()
chaojiying = Chaojiying_Client(chaoji_name, chaoji_pwd, chaoji_code)
im = open('small_img.png', 'rb').read()
ret = chaojiying.PostPic(im, 1902)
code = ret["pic_str"]
pic_id = ret["pic_id"]
print ("[*] 识别码为:" + code)
return code, pic_id
def report_error(pic_id):
chaojiying = Chaojiying_Client(chaoji_name, chaoji_pwd, chaoji_code)
chaojiying.ReportError(pic_id)
def login(try_time):
browser.get(login_page)
username = browser.find_element("id", "username")
pwd = browser.find_element("id", "password")
captcha = browser.find_element("id", "captcha")
code, pic_id = get_captcha()
username.send_keys(login_name)
pwd.send_keys(login_pwd)
captcha.send_keys(code)
browser.find_element("id", "submit").click()
print("[*] 正在登录...")
sleep(5)
page_source = browser.page_source
if "验证码错误" in page_source:
report_error(pic_id)
try_time = try_time - 1;
if try_time > 0:
login(try_time)
else:
print("[-] 尝试登录失败,退出程序")
exit()
return
def filter_key(key):
sets = ['/', '\\', ':', '*', '?', '"', '<', '>', '|']
for char in key:
if char in sets:
key = key.replace(char, '')
return key
def download_one_page(main_name, url, name):
print ("[*] =====>正在下载文件: " + name + ", 链接: " + url)
name = filter_key(name)
file_name = main_name+'XXXXX'+name
prefix = "document.title=\"" + file_name + "\";window.print();"
browser.get(url)
browser.execute_script(prefix) # 利用js修改网页的title,该title最终就是PDF文件名,利用js的window.print可以快速调出浏览器打印窗口,避免使用热键ctrl+P
def download_page():
if not os.path.exists("result"):
os.mkdir("result")
#对零级标题的处理
for page_name in download_list_0:
print("[*] 准备下载教程:" + page_name)
url = main_url + '/' + page_name
browser.get(url)
html = pq(browser.page_source)
try:
items = html('#arc-list')
except:
print("[-] 下载教程失败,结构不符,跳过")
continue
for item in items.children().items():
try:
prefix = item("a").attr("href")
next_url = main_url + prefix
next_name = item.text()
download_one_page(page_name, next_url, next_name)
except:
pass
#对一级标题的处理
for page_name in download_list_1:
print("[*] 准备下载教程:" + page_name)
url = main_url + '/' + page_name
browser.get(url)
html = pq(browser.page_source)
try:
items = html('#sidebar #contents')
except:
print("[-] 下载教程失败,结构不符,跳过")
continue
for item in items.children().items():
try:
prefix = item("a").attr("href")
next_url = main_url + prefix
next_name = item.text()
download_one_page(page_name, next_url, next_name)
except:
pass
#对二级标题的处理
for page_name in download_list_2:
print("[*] 准备下载教程:" + page_name)
url = main_url + '/' + page_name
browser.get(url)
html = pq(browser.page_source)
try:
items = html('#sidebar #contents')
except:
print("[-] 下载教程失败,结构不符,跳过")
continue
for item in items.children().items():
prefix = item("a").attr("href")
next_url = main_url + prefix
next_name = item.text()
download_one_page(page_name, next_url, next_name)
html = pq(browser.page_source)
sub_channels = html(".dl-sub").children()
for sub_channel in sub_channels.items():
next_url = main_url + sub_channel("a").attr("href")
next_name = sub_channel.text()
download_one_page(page_name, next_url, next_name)
def arrange_files():
result_path = os.path.join(os.getcwd(), "result")
for file in os.listdir(result_path):
old_file = os.path.join(result_path, file)
if not os.path.isfile(old_file):
continue
split_str = file.split("XXXXX")
dir_name, file_name = split_str
new_dir = os.path.join(result_path, dir_name)
if not os.path.exists(new_dir):
os.mkdir(new_dir)
new_file = os.path.join(new_dir, file_name)
shutil.move(old_file, new_file)
browser = init_browser()
login(try_time)
download_page()
arrange_files()
