afl原生代码学习笔记
- 调试前准备
- afl-fuzz.cc源码
- 初始配置
- 参数解析函数
- fix_up_sync
- setup_signal_handlers
- get_core_count
- bind_to_free_cpu
- check_crash_handling
- check_cpu_governor
- setup_post
- setup_shm
- memset_sakura_array
- init_count_class16
- setup_dirs_fds
- read_testcases
- add_to_queue
- load_auto
- pivot_inputs
- load_extras
- find_timeout
- detect_file_args
- setup_stdio_file
- check_binary
- get_qemu_argv
- perform_dry_run
- calibrate_case
- init_forserver
- has_new_bits
- count_bytes
- run_target
- classify_counts
- update_bitmap_score(struct queue_entry *q)
- minimize_bits(u8 *bit_map, u8 *trace_bits)
- cull_queue
- mark_as_redundant
- show_init_stats
- find_start_position
- write_stats_file
- save_auto
- Fuzz运行
- 初始配置
- afl-gcc源码
- afl-as源码
- 插桩代码
- afl_clang_fast源码
- afl-llvm-pass.so.cc源码
- afl-llvm-rt.o.c源码
- 其他
- 问题
调试前准备
需要调试的文件
- afl-gcc.c
- afl-fuzz.c
- afl-as.c
- llvm-mode.c
命令
- 删除大于1M的文件
find . -size +1M -exec rm {}
- 查看指定段的汇编代码
objdump -d -j .bss demo
snap常见错误
问题:
snap-confine has elevated permissions and is not confined but should be. Refusing to continue to avoid permission escalation attacks: Operation not permitted
解决:
systemctl enable apparmor
systemctl start apparmor
问题:
启动snap程序卡住
解决:
service snapd start
sudo systemctl start snapd.service
afl-fuzz.cc源码
初始配置
参数解析函数
- 通过getopt解析,switch case捕获参数,并获取optarg的值
- -m,设置内存限制,如果设为none,则mem_limit值设为0
- -t,设置超时,如果带+号,timout_given值为2,否则为1
- -M或者-S,将sync_id设为optarg
- -f,将out_file设为optarg
- -x,将extras_dir设为optarg
- -b,绑定CPU
- -d,将skip_deterministic置1
- -B,指定加载bitmap,用于单独变异某一个中间用例
- -C,将crash_mode置为FAULT_CRASH
- -n,如果设了AFL_DUMB_FORKSRV环境变量,dump_mode置为2,否则为1
- -T,设置use_banner
- -Q,将qemu_mode置为1
fix_up_sync
-
如果通过-M或者-S指定了sync_id,则更新out_dir和sync_dir的值
- 设置sync_dir的值为out_dir
- 设置out_dir的值为out_dir/sync_id
setup_signal_handlers
- 绑定信号
get_core_count
- 通过sysconf函数获取系统配置信息
bind_to_free_cpu
- 将fuzz任务绑定到特定的cpu核上,避免来回切换,提高运行效率
- 实现:通过读proc目录的CPU_allowed_list,找到空闲的cpu,调用sched_setaffinity CPU亲和力函数,将当前任务绑定到空闲cpu上
check_crash_handling
-
检查core dump(核心转储文件)是否交给外部程序处理
-
/proc/sys/kernel/core_pattern文件如果第一个字符是管道符,程序崩溃后的core文件会通过标准输入交给管道符后的外部程序或者脚本,这个时候fuzzer通过waitpid捕获信号的时间延长,可能会被视作超时,遗弃crash -
运行fuzz前需要写入:
echo core >/proc/sys/kernel/core_pattern
check_cpu_governor
- 检查CPU是否运行在性能模式,设置AFL_SKIP_CPUREQ环境变量来跳过检查
setup_post
- 通过dl_open,加载post_handle
setup_shm
- 如果in_bitmap为空,将virgin_bits的MAP_SIZE个字节都设置为255
- 将virgin_tmout和virgin_crash的MAP_SIZE个字节都设置为255
- 初始化共享内存,返回id,如果dumb_mode为0,将id_str写入到SHM_ENV_VAR中
- 启用共享内存,返回trace_bits指针
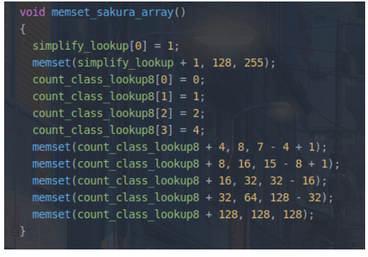
memset_sakura_array
- trace_bits用一个字节来记录边的命中次数(0-255之间),但在循环中,命中5次和6次是一样的,为了避免被当成不同路径,需要对路径命中数进行规整,比如5次和6次都认为是命中8次
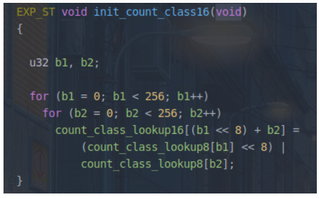
init_count_class16
- AFL后面处理trace_bits时,是一次读两个字节处理,为了提高效率,定义count_class_lookup16来保存两个字节的信息
setup_dirs_fds
- 准备输出文件夹和fd
- 创建out_dir
- 创建queue文件夹,创建queue/.state/文件夹,用来保存用于session resume和related tasks的queue metadata
- 创建deterministic_done,标记过去经历过deterministic fuzzing的queue entries
- 创建auto_extras,Directory with the auto-selected dictionary entries
- 创建redundant_edges,保存当前被认为是多余的路径集合
- 创建variable_behavior,The set of paths showing variable behavior
- 如果sync_id存在,创建.synced文件夹,同步文件夹,用于跟踪cooperating fuzzers
- 创建crashes\hangs,打开/dev/null和/dev/urandom的文件描述符
- 创建plot_data文件,打开FILE,写入
\# unix_time, cycles_done, cur_path, paths_total, pending_total, pending_favs, map_size, unique_crashes, unique_hangs, max_depth, execs_per_sec\n
read_testcases
- 从输入文件夹读测试用例,并排队准备测试
- 扫描input目录,对每个文件调用add_to_queue
add_to_queue
- 用calloc为queue_entry结构体分配内存,结构体内保存input文件名等
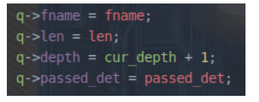
-
用链表来管理queue_entry,将新加进来的结构体插入队头,并更新queue,如果q->depth大于max_depth,则更新max_depth
-
queue计数器queued_paths和待fuzz的用例计数器pending_not_fuzzed加一
load_auto
- afl自带默认字典,也可以通过-x选项指定自定义字典,字典中的token会作为一个整体不被变异
- 该函数打开.state/auto_extras文件夹下的auto文件,调用maybe_add_auto函数,将token加入到extra_data数组中
pivot_inputs
-
将inputdir里的用例,在outputdir里创建硬连接
-
遍历queue里的每个entry,将文件名的最后一级同
id:做比较- 如果相同,则做resume操作
- 如果不同,初始化id为0,找
orig:,如果找到,将use_name设为后面的名字,没找到,use_name设为文件名
-
建立从input到output的硬链接,并将queue的fname指向这个硬链接
-
对于resume_fuzz,创建
out_dir/queue/.state/deterministic_done/use_name文件 -
如果设置了in_place_resume为1(即-i选项后接-),调用nuke_resume_dir,删除
out_dir/_resume/下的一系列文件
load_extras
- 如果指定了-x选项,则将位于extras_dir的给定字典读入到extras数组里
- extras是一组extra_data组成的数组,data指针指向字典数据
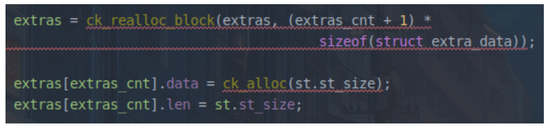
- 按照len大小对extras数组进行排序
find_timeout
- 如果没有给定timeout_given,则调用find_timeout
- 这个函数的目的是,在不指定-t的情况下resuming sessions时,不希望一遍又一遍地自动调整超时时间,以防止超时值因随机波动而增长
- 读取fuzzer_stats,找到其中的
exec_timeout:后面的时间,将值保存到exec_tmout中 - 设定timeout_given=3
detect_file_args
- 检测参数里有无
@@,如果有,将其替换为out_dir/.cur_input,并更新out_file的值
setup_stdio_file
- 如果没有设置f选项,先unlink删除.cur_input,再重新创建.cur_input,保存文件描述符在out_fd中
check_binary
- 检查目标程序是否存在,是否为脚本,是否被插装
- target_path的值设为参数中的binary路径
- 用stat检查是否可执行
- open目标程序,并通过mmap加载到内存中,返回f_data
- 检查f_data前两个字节是否
#!,判断脚本 - 检查f_data第一个字节是否
0x7f,判断ELF - 检查f_data是否包含"__AFL_SHM_ID"字符串,判断插装,非qemu模式无插装则退出
- 检查f_data是否包含"libasan.so",给uses_asan置1
- 检查f_data是否包含
#SIG_AFL_PERSISTENT##,给persistend_mode置1 - 检查f_data是否包含
__AFL_DEFER_FORKSRV,给deferred_mode置1
get_qemu_argv
- 针对无源码的情况,如果启用了qemu动态插装模式,则调用该函数获取qemu的参数,函数返回的新参数use_argv如下:
/path/to/afl-qemu-trace -- /path/to/target -目标程序的参数
- 如果未启用qemu模式,则返回的参数use_argv为:
/path/to/target -目标程序的参数
perform_dry_run
- 执行所有的用例,检查是否按预期工作
- 遍历queue
- 打开q->fname,读取到分配的内存use_mem里
- res=calibrate_case(argv, q, use_mem, 0, 1),校准测试用例
- 如果res的结果为crash_mode或者FAULT_NOBITS,打印
len = %u, map size = %u, exec speed = %llu us\ - 对res的错误类型进行判断
- FAULT_NONE
- 如果q是头结点,即第一个测试用例,则调用check_map_coverage,评估覆盖率,如果路径树小于100,直接返回,如果在trace_bits数组的后半段,直接返回,否则抛出警告
Recompile binary with newer version of afl to improve coverage! - 如果是crash_mode,则抛出异常
Test case '%s' does *NOT* crash,该文件不崩溃
- 如果q是头结点,即第一个测试用例,则调用check_map_coverage,评估覆盖率,如果路径树小于100,直接返回,如果在trace_bits数组的后半段,直接返回,否则抛出警告
- FAULT_TMOUT
- 如果给定了-t参数,则timeout_given的值为2,抛出警告
est case results in a timeout (skipping),q->cal_failed的值设为CAL_CHANCES,cal_failures计数器的值加一
- 如果给定了-t参数,则timeout_given的值为2,抛出警告
- FAULT_CRASH
- 如果crash_mode为1,break
- 如果skip_crashes为1,q->cal_failed被置为CAL_CHANCES,cal_failures的值加一,break
- FAULT_ERROR
- 抛出异常
Unable to execute target application ('%s')
- 抛出异常
- FAULT_NOINST
- 该样例没有任务路径信息,抛出异常
No instrumentation detected
- 该样例没有任务路径信息,抛出异常
- FAULT_NOBITS
- 该样例没有任何新路径,抛出警告
No new instrumentation output, test case may be useless.,并给useless_at_start加一
- 该样例没有任何新路径,抛出警告
- FAULT_NONE
- 如果这个用例的var_behavior为真,代表它多次运行,同样的输入条件下,却有不同的路径,抛出警告
Instrumentation output varies across runs.,代表该样例的路径输出可变 - 取出下一个queue,继续循环
calibrate_case
- 用来评估testcase,评估是否异常,行为是否可变(多次执行case,发现的路径是否不同)
- 如果q->exec_cksum为0,代表该case是第一次运行,即来自input文件夹,将first_run置为1
- 设置use_tmout为exec_tmou,如果不来自queue或在resuming sessions中,该值被设置的更大
- stage_name置为calibration,并根据fast_cal是否为1,来设置stage_max的值为3还是CAL_CYCLES(默认为8),含义是这个stage要执行多少次
- 如果不是dumb_mode,且没有禁用forkserver,且forksrv_pid为0,则调用init_forkserver来启动fork server
- 如果这个queue不是来自input文件夹,而是评估新的case,此时p->exec_cksum不为空,拷贝trace_bits到first_trace里,然后计算has_new_bits,并赋值给new_bits
- 开始执行calibration stage,共执行stage_max轮
- 如果这个queue不是来自input文件夹,而是评估新case,且第一轮calibration stage结束,调用一次show_stats展示界面
- 调用write_to_testcase(use_mem, q->len),将q->fname写入到.cur_input中
- 调用run_target运行程序,结果返回到fault中
- 如果fault没有crash,则goto abor_calibration
- 如果不是dumb_mode,并且是calibration stage第一次运行,并且调用count_bytes发现没有任何bytes被置位(即共享内存没有路径),设置fault为FAULT_NOINST,然后goto abort_calibration
- 调用hash32(trace_bits, MAP_SIZE, HASH_CONST),计算32位哈希值,保存到cksum中
- 如果q->exec_cksum不等于cksum,代表这是第一次运行,或者在相同的参数下,每次执行,cksum却不同,代表这是一个路径可变的queue
- 如果q->exec_cksum存在,即不是第一次运行,则循环MAP_SIZE次,遍历trace_bits和first_trace中每个字节,如果某个字节不相同,则将var_bytes[i]置为1,并将stage_max置为CAL_CYCLES_LONG,即需要执行40次,将var_detected置为1
- 如果是第一次运行,则将q->exec_cksum赋值为cksum,并将trace_bits拷贝给first_trace
- 保存所有轮次总的执行时间到total_cal_us里,保存总的执行轮次到total_cal_cycles里
- 计算一些统计信息,包括
- 每轮平均执行时间保存到q->exec_us
- 最后一次覆盖到的路径数保存到q->bitmap_size
- total_bitmap_size加上这个queue覆盖到的路径数
- 调用update_bitmap_score
- 如果falut为None,且该queue是第一次执行,且不属于dumb_mode,且new_bits为0,代表这个用例在所有轮次的执行里,没有发现任何新路径和出现异常,则设置fault为FAULT_NOBITS
- 如果new_bits为2,并且q->has_new_cov为0,则置1,并将queued_with_cov加1,代表有一个queue发现了新路径
- 如果该queue是可变路径,计算var_bytes里被置位的tuple个数,保存到var_byte_count里,代表这些tuple具有可变行为
- 将这个queue标记为一个variable
- 调用mark_as_variable,创建符号链接out_dir/queue/.state/variable_behavior/fname,设置queue的var_behavior为1
- 计数器queued_variable加一
- 恢复之前的stage值
- 如果不是第一次运行这个queue,调用show_stats
- 返回fault值
init_forserver
- 创建状态管道st_pipe和命令管道ctl_pipe
- fork子进程,返回forksrv_id
- 子进程
- 通过setrlimit设置子进程mem_limit
- 调用setsid,使子进程成为守护进程,创建新会话,并让子进程成为头进程,脱离原控制终端的控制
- 通过dup2将标准输出和标准错误重定向到/dev/null
- 如果存在out_file,即目标程序从文件读,则将标准输入重定向到/dev/null,否则而将标准输入重定向到out_file中,并关闭out_fd
- 复制命令管道的读端到FORKSRV_FD,复制状态管道的写端到FORKSRV_FD+1,并关闭ctl_pipe和st_pipe
- 如果没有设置LD_BIND_LAZY,则设置LD_BIND_NOW为1,避免链接器在fork后做多余动作,提高效率
- 设置ASAN_OPTIONS和MSAN_OPTIONS
execv(target_path, argv)带参数执行target,执行结束后子进程结束- 在这里非常特殊,第一个target会进入
__afl_maybe_log里的__afl_fork_wait_loop,并充当fork server,在整个Fuzz的过程中,它都不会结束,每次要Fuzz一次target,都会从这个fork server fork出来一个子进程去fuzz
- 在这里非常特殊,第一个target会进入
- 通过一个独特的bitmaps EXEC_FAIL_SIG(0xfee1dead)写入trace_bits,告诉父进程执行失败,并exit
- 父进程
- 关闭不需要的文件描述符,保留写命令fsrv_ctl_fd和读状态fsrv_st_fd
- 通过setitimer定时,等待fork server启动,从fsrv_st_fd管道读4个字节,如果读取成功,则代表fork server成功启动,结束函数返回,如果超时,抛出异常
- 后续是一些子进程启动失败的异常处理
- 子进程
has_new_bits
-
检查有没有新路径或者某个路径的执行次数有所不同
-
将current和virgin分别初始化为trace_bits和virgin_map的u64首元素地址
trace_bits表示被fuzz覆盖的字节,初始值为全0,每次按字节置位,指向共享内存bitmap virgin_bits表示没被fuzz覆盖的字节,初始值为全1,每次按字节置位,是位于栈上的数组 -
8个字节为一组,每次从trace_bits共享内存里取8个字节
-
如果current不为0,并且current&virgin不为0,即current发现了新路径或者路径的执行次数
-
如果当前ret小于2,取出8字节current的每个字节cur[i]和virgin的每个字节vir[i]
- i的范围为0-7,比较cur[i] && vir[i] == 0xff,如果有一个为真,则ret=2,代表发现了从未出现过的tuple(注意这里==的优先级比&&高,所以先比较vir[i]是否等于0xff)
- 否则设ret=1,代表仅仅是改变了某个tuple的hit_count
-
*virgin &=~current
-
-
取下一组8字节的current和virgin,直到MAPSIZE被遍历完
-
-
如果传入给has_new_bits的参数virgin_map是virgin_bits,且ret不为0,则设置bitmap_changed等于1
-
返回ret的值
count_bytes
- 检查bitmap中有多少个字节被置位了,即覆盖了多少条路径
- 初始化计数器ret为0,每次读取内存的4个字节到变量v中
- 如果v为0,直接跳过,如果v不为0,依次计算v&FF(0),v&FF(1),v&FF(2),v&FF(3)的结果,如果不为0,则ret加一
- #define FF(_b) (0xff << ((_b) << 3))
- 结果为
0x000000ff,0x0000ff00,0x00ff0000,0xff000000其中之一
- 结果为
- #define FF(_b) (0xff << ((_b) << 3))
run_target
- memset(trace_bits, 0, MAP_SIZE),清空共享内存
- 如果是dumb_mode并且no_forkserver不为0,直接fork子进程,在子进程中execv(target, argv),如果执行失败,向trace_bits中写入EXEC_FAIL_SIG
- 否则,向控制管道写入prev_timed_out的值,命令forkserver开始fork子进程来fuzz,然后从状态管道读子进程的IP到child_pid
- 这期间如果stop_soon值为1,则return(stop_soon的声明为int volatile stop_soon;该值在捕获ctrl+c信号后被处理函数handle_stop_sig置1)
- 不管用没用forkserver,通过setitimer设置超时,如果超时,通过handle_timeout杀死子进程,并设置child_timed_out为1
- 如果是dumb_mode并且no_forkserver不为0,waitpid将子进程结束的状态码保存到status中,否则,通过读状态管道将子进程状态结束码读入status中
- 通过getitimer将获取执行时间保存到exec_ms,并将totol_execs这个执行次数计数器加一
- 调用classify_counts((u64 *)trace_bits),对路径覆盖率进行规整,每次处理两个字节,通过count_class_lookup16获取规整值,比如5次和6次都算作命中8次,写入trace_bits,是对因为循环次数的微小区别,被误判为不同执行结果的这种情况的优化处理
- 设置prev_timed_out的值为child_timed_out
- 接着依据status的值,向调用者返回结果
- WIFSIGNALED(status),判断若为异常结束子进程返回的状态,则为真
- 通过WTERMSIG(status),取得子进程因信号中止的信号代码
- 如果child_timed_out为1,并且信号代码为SIGKILL,则返回FAULT_TMOUT
- 否则返回FAULT_CRASH
- 通过WTERMSIG(status),取得子进程因信号中止的信号代码
- 如果uses_asan为真并且退出状态码为MSAN_ERROR,则返回FAULT_CRASH
- 如果dumb_mode为真,并且trace_bits为EXEC_FAIL_SIG,则返回FAULT_ERROR
- 如果timout小于设定的exec_tmout,并且slowest_exec_ms小于exec_ms,则另slowest_exec_ms等于exec_ms
- 返回FAULT_NONE
- WIFSIGNALED(status),判断若为异常结束子进程返回的状态,则为真
classify_counts
- 8个字节一组去循环读入,直到遍历完整个mem
- 每次取两个字节
u16 *mem16 = (u16 *) mem - i从0到3,计算
mem16[i]的值,在count_class_lookup16[mem16[i]]里找到对应的取值,并赋值给mem16[i]
- 每次取两个字节
update_bitmap_score(struct queue_entry *q)
- 每发现一条新路径,都会调用该函数判断是不是更favorable,即用最小的代价来遍历到已有bitmap中的所有位
- 首先计算该用例的fav_factor=q->exec_us*q->len,即执行时间和用例大小的乘积,以此衡量代价
- 然后遍历trace_bits数组,如果该字节不为0,说明已被覆盖
- 如果该路径的top_rated存在,即存在最小代价(top_rated[i]是用最小代价遍历路径i的queue)
- 比较fav_factor是否大于top_rated[i]->exec_us*top_rated[i]->len
- 如果大于,说明该用例不能减小代价,继续遍历下一个路径
- 如果小于,将top_rated[i]->tc_ref(trace_bits的引用计数)减一,并清空top_rated[i]->trace_mini,准备更新该路径对应最小代价的bitmap
- 比较fav_factor是否大于top_rated[i]->exec_us*top_rated[i]->len
- 设置top_rated[i]为q,即当前用例,并将其tc_ref加一
- 如果q->trace_mini被清空了,则调用minimize_bits将trace_bits压缩,并将指针保存到q->trace_mini字段
- 设置score_changed为1
- 如果该路径的top_rated存在,即存在最小代价(top_rated[i]是用最小代价遍历路径i的queue)
minimize_bits(u8 *bit_map, u8 *trace_bits)
- 利用bitmap算法将占一字节的trace_bits压缩为占一位的bit_map,只记录是否覆盖到的信息,不记录覆盖多少次
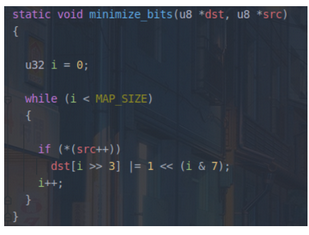
- 将src的前0-7个字节,映射到dst的第一个字节(0-7位)
- 如果第i个字节不空,则i代表src的索引,与上0x0111,可以知道对应0-7位具体哪一位,通过左移运算可以使dst相应位置1
cull_queue
- 精简队列
- 如果score_changed为0,即top_rated没有变化,或者dumb_mode,直接返回
- 设置score_changed为0
- 创建u8 temp_v数组,大小为MAP_SIZE除以8,并将其初始化为0xff,每位如果为1代表没覆盖到,为0表示被覆盖
- 设置queued_favored和pending_favored为0,遍历queue队列,设置其favored都为0
- 遍历i从0到MAP_SIZE,通过贪婪算法筛选出一组queue_entry,能够覆盖现在所有已经覆盖到的路径,并且这个用例集合里的用例要更小更快
- 如果top_rated[i]有值并且该路径对应bit被置位
- 则从temp_v中清楚掉top_rated[i]覆盖到的路径,将对应bit置0
- 设置top_rated[i]->favored为1,queued_favored计数器加一
- 如果top_rated[i]的was_fuzzed字段是0,即还没被fuzz过,则将pending_favored计数器加一
- 如果top_rated[i]有值并且该路径对应bit被置位
- 遍历queue队列,调用mark_as_redundant,对那些不是favored的case,标记为redundant_edges
mark_as_redundant
- 将不是favored的用例标记为redundant_edges
- 如果state和q->fs_redundant相等,直接返回
- 设置q->fs_redundant的值为state
- 如果state为1,尝试创建out_dir/queue/.state/redundant_edges/fname
- 如果state为0,尝试删除out_dir/queue/.state/redundant_edges/fname
show_init_stats
- 在处理输入目录的末尾显示统计信息,以及一堆警告,以及几个硬编码的常量。
-
依据之前从calibrate_case里得到的total_cal_us和total_cal_cycles,计算出单轮执行的时间avg_us,如果大于10000,就警告
"The target binary is pretty slow! See %s/perf_tips.txt."- 如果avg_us大于50000,设置havoc_div为10 /* 0-19 execs/sec */
- 大于20000,设置havoc_div为5 /* 20-49 execs/sec */
- 如果大于10000,设置havoc_div为2 /* 50-100 execs/sec */
-
如果不是resuming session,则对queue的大小和个数超限提出警告,且如果useless_at_start不为0,就警告有可以精简的样本。
-
如果timeout_given为0,则根据avg_us来计算出exec_tmout,
注意这里avg_us的单位是微秒,而exec_tmout单位是毫秒,所以需要除以1000
- avg_us > 50000
- exec_tmout = avg_us * 2 / 1000
- avg_us > 10000
- exec_tmout = avg_us * 3 / 1000
- exec_tmout = avg_us * 5 / 1000
- 然后在上面计算出来的exec_tmout和所有样例中执行时间最长的样例进行比较,取最大值赋给exec_tmout
- 如果exec_tmout大于EXEC_TIMEOUT,就设置exec_tmout = EXEC_TIMEOUT
- EXEC_TIMEOUT的值为1秒,即最大超时时间是1秒
- 打印出
"No -t option specified, so I'll use exec timeout of %u ms.", exec_tmout - 设置timeout_given为1
- avg_us > 50000
-
如果timeout_give不为0,且为3,代表这是resuming session,直接打印
"Applying timeout settings from resumed session (%u ms).", exec_tmout,此时的timeout_give是我们从历史记录里读取出的。 -
如果是dumb_mode且没有设置环境变量AFL_HANG_TMOUT
- 设置hang_tmout为EXEC_TIMEOUT和
exec_tmout * 2 + 100中的最小值
- 设置hang_tmout为EXEC_TIMEOUT和
-
All set and ready to roll!
find_start_position
-
在resume时,尝试查找队列开始的位置
-
如果不是resuming_fuzz,直接返回
-
如果in_place_resume为真,打开out_dir/fuzzer_stats文件,否则打开in_dir/../fuzzer_stats文件
-
找到文件中
cur_path后的值,并设置为ret,如果大于queued_paths就令ret为0 -
返回ret
write_stats_file
- 更新统计信息文件
- 创建文件
out_dir/fuzzer_stats - 写入统计信息
- start_time
- fuzz运行的开始时间,start_time / 1000
- last_update
- 当前时间
- fuzzer_pid
- 获取当前pid
- cycles_done
queue_cycle在queue_cur为空,即执行到当前队列尾的时候才增加1,所以这代表queue队列被完全变异一次的次数。
- execs_done
- total_execs,target的总的执行次数,每次
run_target的时候会增加1
- total_execs,target的总的执行次数,每次
- execs_per_sec
- 每秒执行的次数
- paths_total
- queued_paths在每次
add_to_queue的时候会增加1,代表queue里的样例总数
- queued_paths在每次
- paths_favored
- queued_favored,有价值的路径总数
- paths_found
- queued_discovered在每次
common_fuzz_stuff去执行一次fuzz时,发现新的interesting case的时候会增加1,代表在fuzz运行期间发现的新queue entry。
- queued_discovered在每次
- paths_imported
- queued_imported是master-slave模式下,如果sync过来的case是interesting的,就增加1
- max_depth
- 最大路径深度
- cur_path
- current_entry一般情况下代表的是正在执行的queue entry的整数ID,queue首节点的ID是0
- pending_favs
- pending_favored 等待fuzz的favored paths数
- pending_total
- pending_not_fuzzed 在queue中等待fuzz的case数
- variable_paths
- queued_variable在
calibrate_case去评估一个新的test case的时候,如果发现这个case的路径是可变的,则将这个计数器加一,代表发现了一个可变case
- queued_variable在
- stability
- bitmap_cvg
- unique_crashes
- unique_crashes这是在
save_if_interesting时,如果fault是FAULT_CRASH,就将unique_crashes计数器加一
- unique_crashes这是在
- unique_hangs
- unique_hangs这是在
save_if_interesting时,如果fault是FAULT_TMOUT,且exec_tmout小于hang_tmout,就以hang_tmout为超时时间再执行一次,如果还超时,就让hang计数器加一。
- unique_hangs这是在
- last_path
- 在
add_to_queue里将一个新case加入queue时,就设置一次last_path_time为当前时间,last_path_time / 1000
- 在
- last_crash
- 同上,在unique_crashes加一的时候,last_crash也更新时间,
last_crash_time / 1000
- 同上,在unique_crashes加一的时候,last_crash也更新时间,
- last_hang
- 同上,在unique_hangs加一的时候,last_hang也更新时间,
last_hang_time / 1000
- 同上,在unique_hangs加一的时候,last_hang也更新时间,
- execs_since_crash
- total_execs - last_crash_execs,这里last_crash_execs是在上一次crash的时候的总计执行了多少次
- exec_tmout
- 配置好的超时时间,有三种可能的配置方式,见上文
- 统计子进程的资源用量并写入。
save_auto
- 保存自动生成的extras
- 如果auto_changed为0,直接返回
- 如果不为0,设置为0,然后创建文件out_dir/queue/.state/auto_extras/autoi,并写入a_extras的数据
Fuzz运行
主循环
- 首先调用cull_queue精简队列
- 如果queue_cur为空,代表所有queue都被执行完一轮
- 设置queue_cycle执行轮次计数器加一,代表所有queue被完整执行了多少轮
- 设置current_entry为0,设置queue_cur指向queue首元素,开始新一轮fuzz
- 如果是resuming_fuzz,检查seek_to是否为空(seek_to是find_start_position的返回值),如果不空,则让queue_cur指向seek_to指定的位置
- 调用show_stats刷新界面
- 如果当前轮次执行的用例数和上一轮一样,表示当前没有发现新的用例
- 如果use_splicing为1,就设置cycles_wo_finds计数器加1
- 否则,设置use_splicing为1,表示接下来要通过splice重组queue里的case
- 如果存在sync_id并且是第一轮fuzz,并且设置了环境变量AFL_IMPORT_FIRST
- 调用sync_fuzzers,从别的fuzz里获取用例
- 执行skipped_fuzz=fuzz_one(use_argv)来对queue_cur进行一次测试
- fuzz_one并不一定真的执行当前queue_cur,它是具有策略性的,如果不执行,直接返回1,否则为0
- 如果skkiped_fuzz,且存在sync_id
- 对sync_interval_cnt加一,如果其值是sync_interval(默认是5)的整数倍,则调用sync_fuzzers
- queue_cur指向下一个queue_entrey,current_entry++,开始测试下一个queue
终止处理
-
如果是程序停止的,则kill掉forkserver和子进程,如果是手动停止的,则用信号来停止
-
如果stop_soon等于2
- 则杀死子进程和forkserver
- 等待forkserver结束后,调用write_bitmap、write_stats_file和save_auto
-
stop_fuzzing标签
- 首先打印结束来源
SAYF(CURSOR_SHOW cLRD "\n\n+++ Testing aborted %s +++\n" cRST, stop_soon == 2 ? "programmatically" : "by user");- 如果超过30分钟还在做第一轮
SAYF("\n" cYEL "[!] " cRST "Stopped during the first cycle, results may be incomplete.\n" " (For info on resuming, see %s/README.)\n", doc_path);- 关闭plot文件,释放queue和extras内存
- exit(0)退出fuzz程序
fuzz_one
- 从queue队列中取出一个用例,交给该函数执行,返回0表示执行成功,返回1表示跳过该用例
- 如果定义了IGNORE_FINDS宏,则跳过depth深度超过1的所有用例
- 如果pending_favored不为0,则对于queue_cur已经被fuzz过或者queue_cur不是favored的,有%99的概率直接返回1(通过UR获取随机数),即跳到下一个queue
- 如果pending_favored为0,并且不是dumed_mode,并且queue里用例的总数大于10
- 如果queue_cycle大于1,并且当前的queue还没被fuzz过,则由75%的概率直接返回
- 如果queue_cur被fuzz过,则有95%的概率直接返回1
- 设置len为queue_cur->len
- 用mmap将用例对应的文件映射到内存,地址赋值给orig_in和in_buf
- 分配len大小的内存,全部初始化为0,并将地址赋值给out_buf
- CALIBRATION阶段
- 假如当前有校准错误,并且校准次数小于3次,就调用calibrate_case再次校准
- TRIMMING阶段
- 如果不是dumb_mode并且queue_cur->trim_done为0(表示还没trim过)
- 调用函数trim_case进行修剪
- 设置trim_done为1
- 重新读取一次queue_cur->len到len中
- 将in_buf的len个字节拷贝到out_buf中
- PERFROMANCE SCORE阶段
- perf_score=calculate_score(queue_cur)
- 如果skip_deterministic为1,或者queue_cur被fuzz过,或者queue_cur的passed_det为1(已经经历过确定性测试),则跳转到havoc_stage阶段
- 设置doing_det为1
- SIMPLE BITFLIP阶段(包括字典构造)
- 定义了一个FLIP_BIT宏

- stage_name设为'bitflip 1/1',通过异或运算将每位翻转,然后执行一次common_fuzz_stuff,再翻转回来
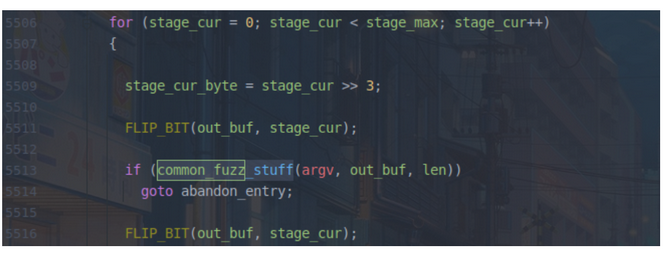
- 在进行bitflip1/1反转的同时,对于每个字节的最低位反转进行额外处理:如果连续多个字节的最低位反转后,程序的路径都没发生变化,但是都同原始执行路径不一样,则把这一段连续的bytes判断是一条token
- 通过hash32来标记trace_bits的cksum,如果ck_sum同exec_cksum不一致,则将当前字节out_buf[stage_cur>>3]收进a_colloct中,并令prev_cksum=ck_sum,收入字节直至cksum不等于prev_cksum,此时将收集到的a_colloct通过maybe_add_auto添加到a_extras数组里
- stage_finds[STAGE_FLIP1]的值加上整个FLIP_BIT中新发现的路径和crash总和
- stage_cycles[STAGE_FLIP1]的值加上整个FLIP_BIT中翻转的总次数
- 设置stage_name为bitflip 2/1,原理一样,只是这次连续翻转相邻的两位,然后保存结果到
stage_finds[STAGE_FLIP2]和stage_cycles[STAGE_FLIP2]里
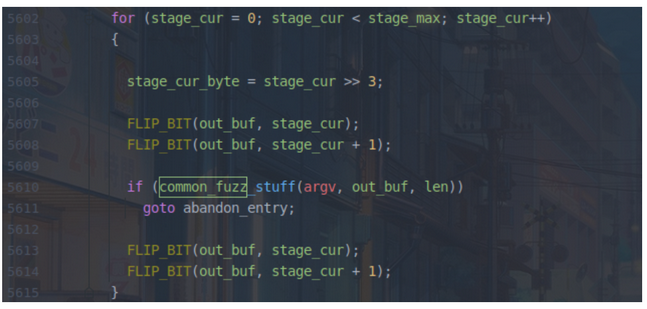
- 同理,设置stage_name为
bitflip 4/1,翻转连续的四位并记录 - 在bitflip 8/8变异时,AFL还生成了非常重要的effector map,贯穿deterministic fuzzing的始终
- 设置stage_name为
bitflip 8/8,以字节为单位,直接通过和0xff亦或运算去翻转整个字节的位,然后执行一次,并记录 - 具体地,在对每个byte进行翻转时,如果其造成执行路径与原始路径不一致,就将该byte在effector map中标记为1,即“有效”的,否则标记为0,即“无效”的
- 这样做的逻辑是:如果一个byte完全翻转,都无法带来执行路径的变化,那么这个byte很有可能是属于”data”,而非”metadata”(例如size, flag等),对整个fuzzing的意义不大。所以,在随后的一些变异中,会参考effector map,跳过那些“无效”的byte,从而节省了执行资源
- 设置stage_name为
- 设置stage_name为
bitflip 16/8,设置stage_max为len - 1,以字为单位和0xffff进行亦或运算,去翻转相邻的两个字节(即一个字的)的位。- 这里要注意在翻转之前会先检查eff_map里对应于这两个字节的标志是否为0,如果为0,则这两个字节是无效的数据,stage_max减一,然后开始变异下一个字。
- common_fuzz_stuff执行变异后的结果,然后还原。
- 同理,设置stage_name为
bitflip 32/8,然后设置stage_max为len - 3,以双字为单位,直接通过和0xffffffff亦或运算去相邻四个字节的位,然后执行一次,并记录。- 在每次翻转之前会检查eff_map里对应于这四个字节的标志是否为0,如果是0,则这两个字节是无效的数据,stage_max减一,然后开始变异下一组双字。
- ARITHMETIC INC/DEC
- 在bitflip变异全部进行完成后,便进入下一个阶段:arithmetic。与bitflip类似的是,arithmetic根据目标大小的不同,也分为了多个子阶段:
- arith 8/8,每次对8个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个byte进行整数加减变异
- arith 16/8,每次对16个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个word进行整数加减变异
- arith 32/8,每次对32个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个dword进行整数加减变异
- 加减变异的上限,在config.h中的宏ARITH_MAX定义,默认为35。所以,对目标整数会进行+1, +2, …, +35, -1, -2, …, -35的变异。特别地,由于整数存在大端序和小端序两种表示方式,AFL会贴心地对这两种整数表示方式都进行变异
- 此外,AFL还会智能地跳过某些arithmetic变异。第一种情况就是前面提到的effector map:如果一个整数的所有bytes都被判断为“无效”,那么就跳过对整数的变异。第二种情况是之前bitflip已经生成过的变异:如果加/减某个数后,其效果与之前的某种bitflip相同,那么这次变异肯定在上一个阶段已经执行过了,此次便不会再执行
- INTERSTING VALUES
- 下一个阶段是interest,具体可分为:
- interest 8/8,每次对8个bit进替换,按照每8个bit的步长从头开始,即对文件的每个byte进行替换
- interest 16/8,每次对16个bit进替换,按照每8个bit的步长从头开始,即对文件的每个word进行替换
- interest 32/8,每次对32个bit进替换,按照每8个bit的步长从头开始,即对文件的每个dword进行替换
- 而用于替换的”interesting values”,是AFL预设的一些比较特殊的数,这些数的定义在config.h文件中

- 与之前类似,effector map仍然会用于判断是否需要变异;此外,如果某个interesting value,是可以通过bitflip或者arithmetic变异达到,那么这样的重复性变异也是会跳过的
- DICTIONARY STUFF
- user extras(over),从头开始,将用户提供的tokens依次替换到原文件中,stage_max为
extras_cnt * len - user extras(insert),从头开始,将用户提供的tokens依次插入到原文件中,stage_max为
extras_cnt * len - auto extras(over),从头开始,将自动检测的tokens依次替换到原文件中,stage_max为
MIN(a_extras_cnt, USE_AUTO_EXTRAS) * len - 其中,用户提供的tokens,是在词典文件中设置并通过-x选项指定的,如果没有则跳过相应的子阶段
- 此步结束后,确定性变异结束,如果queue_cur->passed_det为0,则标记为1,表示经过确定性变异
- RANDOM HAVOC
- 对于非dumb mode的主fuzzer来说,完成了上述deterministic fuzzing后,便进入了充满随机性的这一阶段;对于dumb mode或者从fuzzer来说,则是直接从这一阶段开始。
- havoc,顾名思义,是充满了各种随机生成的变异,是对原文件的“大破坏”。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
- 随机选取某个bit进行翻转
- 随机选取某个byte,将其设置为随机的interesting value
- 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个byte,对其减去一个随机数
- 随机选取某个byte,对其加上一个随机数
- 随机选取某个word,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个word,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个byte,将其设置为随机数
- 随机删除一段bytes
- 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
- 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
- 还没完,AFL会生成一个随机数,作为变异组合的数量,并根据这个数量,每次从上面那些方式中随机选取一个(可以参考高中数学的有放回摸球),依次作用到文件上。如此这般丧心病狂的变异,原文件就大概率面目全非了,而这么多的随机性,也就成了fuzzing过程中的不可控因素,即所谓的“看天吃饭”了
- splice
- 这是一个最后的策略,它获取当前输入文件,随机选择另一个输入文件,然后以一定的偏移量将它们拼接在一起,然后跳转到havoc阶段变异新生成的文件
- adandon_entry
- 设置ret_val的值为0
- 如果queue_cur通过了评估,且was_fuzzed字段是0,就设置
queue_cur->was_fuzzed为1,然后pending_not_fuzzed计数器减一 - 如果queue_cur是favored, pending_favored计数器减一
sync_fuzzers(char **argv)
- 这个函数其实就是读取其他sync文件夹下的queue文件,然后保存到自己的queue里。
-
打开
sync_dir文件夹 -
while循环读取该文件夹下的目录和文件
while ((sd_ent = readdir(sd)))-
跳过
.开头的文件和sync_id即我们自己的输出文件夹 -
读取
out_dir/.synced/sd_ent->d_name文件即id_fd里的前4个字节到min_accept里,设置next_min_accept为min_accept,这个值代表之前从这个文件夹里读取到的最后一个queue的id。 -
设置stage_name为
sprintf(stage_tmp, "sync %u", ++sync_cnt);,设置stage_cur为0,stage_max为0 -
循环读取
sync_dir/sd_ent->d_name/queue文件夹里的目录和文件
-
同样跳过
.开头的文件和标识小于min_accept的文件,因为这些文件应该已经被sync过了。 -
如果标识
syncing_case大于等于next_min_accept,就设置next_min_accept为syncing_case + 1 -
开始同步这个case
-
如果case大小为0或者大于MAX_FILE(默认是1M),就不进行sync。
-
否则mmap这个文件到内存mem里,然后
write_to_testcase(mem, st.st_size),并run_target,然后通过save_if_interesting来决定是否要导入这个文件到自己的queue里,如果发现了新的path,就导入。
- 设置syncing_party的值为
sd_ent->d_name - 如果save_if_interesting返回1,queued_imported计数器就加1
- 设置syncing_party的值为
-
-
stage_cur计数器加一,如果stage_cur是stats_update_freq的倍数,就刷新一次展示界面。
-
-
向id_fd写入当前的
next_min_accept值
-
-
总结来说,这个函数就是先读取有哪些fuzzer文件夹,然后读取其他fuzzer文件夹下的queue文件夹里的case,并依次执行,如果发现了新path,就保存到自己的queue文件夹里,而且将最后一个sync的case id写入到
.synced/其他fuzzer文件夹名文件里,以避免重复运行
trim_case
- 如果这个case的大小len小于5字节,就直接返回
- 设置stage_name的值为tmp,在bytes_trim_in的值里加上len,bytes_trim_in代表被trim过的字节数
- 计算len_p2,其值是大于等于q->len的第一个2的幂次。(eg.如果len是5704,那么len_p2就是8192)
- 取
len_p2的1/16为remove_len,这是起始步长 - 进入while循环,终止条件是remove_len小于终止步长len_p2的1/1024, 每轮循环步长会除2
- 设置remove_pos的值为remove_len
- 读入
"trim %s/%s", DI(remove_len), DI(remove_len)到tmp中, 即stage_name = “trim 512/512” - 设置stage_cur为0,stage_max为
q->len / remove_len - 进入while循环,remove_pos < q->len , 即每次前进remove_len个步长,直到整个文件都被遍历完为止。
- 由in_buf中remove_pos处开始,向后跳过remove_len个字节,写入到
.cur_input里,然后运行一次fault = run_target,trim_execs计数器加一 - 由所得trace_bits计算出一个cksum,和 q->exec_cksum比较
- 如果相等
- 从
q->len中减去remove_len个字节,并由此重新计算出一个len_p2,这里注意一下while (remove_len >= MAX(len_p2 / TRIM_END_STEPS, TRIM_MIN_BYTES)) - 将
in_buf+remove_pos+remove_len到最后的字节,前移到in_buf+remove_pos处,等于删除了remove_pos向后的remove_len个字节。 - 如果needs_write为0,则设置其为1,并保存当前trace_bits到clean_trace中。
- 从
- 如果不相等
- remove_pos加上remove_len,即前移remove_len个字节。注意,如果相等,就无需前移
- 如果相等
- 注意trim过程可能比较慢,所以每执行stats_update_freq次,就刷新一次显示界面
show_stats - stage_cur加一
- 由in_buf中remove_pos处开始,向后跳过remove_len个字节,写入到
- 如果needs_write为1
- 删除原来的q->fname,创建一个新的q->fname,将in_buf里的内容写入,然后用clean_trace恢复trace_bits的值
- 进行一次update_bitmap_score
- 返回fault
calculate_score
- 根据queue entry的执行速度、覆盖到的path数和路径深度来评估出得分,这个得分perf_score在后面havoc的时候使用
- 解释一下
q->depth,它在每次add_to_queue的时候,会设置为cur_depth+1,而cur_depth是一个全局变量,一开始的初始值为0
- 处理input时
- 在read_testcases的时候会调用add_to_queue,此时所有的input case的queue->depth都会被设置为1
- fuzz_one时
- 会先设置cur_depth为当前queue的depth,然后这个queue经过mutate之后调用save_if_interesting,如果是interesting case,就会被add_to_queue,此时就建立起了queue之间的关联关系,所以由当前queue变异加入的新queue,深度都在当前queue的基础上再加一
common_fuzz_stuff
- 将用例写入文件并执行,然后处理结果,如果错误返回1
- 如果定义了
post_handler,就通过out_buf = post_handler(out_buf, &len)处理一下out_buf,如果out_buf或者len有一个为0,则直接返回0- 这里其实很有价值,尤其是如果需要对变异完的queue,做一层wrapper再写入的时候
- write_to_testcase(out_buf, len)
- fault = run_target(argv, exec_tmout)
- 如果fault是FAULT_TMOUT
- 如果
subseq_tmouts++ > TMOUT_LIMIT(默认250),就将cur_skipped_paths加一,直接返回1 - subseq_tmout是连续超时数
- 如果
- 否则设置subseq_tmouts为0
- 如果skip_requested为1
- 设置skip_requested为0,然后将cur_skipped_paths加一,直接返回1
- queued_discovered += save_if_interesting(argv, out_buf, len, fault),如果发现了新的路径才会加一。
- 如果stage_cur除以stats_update_freq余数是0,或者其加一等于stage_max,就调用
show_stats更新展示界面 - 返回0
write_to_testcase
- 从
mem中读取len个字节,写入到.cur_input中
save_if_interesting
- 检查这个case的执行结果是否是interesting的,决定是否保存或跳过。如果保存了这个case,则返回1,否则返回0,以下分析不包括crash_mode,暂时略过以简洁
- 设置keeping等于0
hnb = has_new_bits(virgin_bits),如果没有新的path发现或者path命中次数相同,就直接返回0- 否则,将case保存到
fn = alloc_printf("%s/queue/id:%06u,%s", out_dir, queued_paths, describe_op(hnb))文件里 add_to_queue(fn, len, 0),将其添加到队列里- 如果hnb的值是2,代表发现了新path,设置刚刚加入到队列里的queue的has_new_cov字段为1,即
queue_top->has_new_cov = 1,然后queued_with_cov计数器加一 - 保存hash到其exec_cksum
- 评估这个queue,
calibrate_case(argv, queue_top, mem, queue_cycle - 1, 0) - 设置keeping值为1
- 根据fault结果进入不同的分支
- FAULT_TMOUT
- 设置total_tmouts计数器加一
- 如果unique_hangs的个数超过能保存的最大数量
KEEP_UNIQUE_HANG,就直接返回keeping的值 - 如果不是dumb mode,就
simplify_trace((u64 *) trace_bits)进行规整。 - 如果没有发现新的超时路径,就直接返回keeping
- 否则,代表发现了新的超时路径,unique_tmouts计数器加一
- 如果hang_tmout大于exec_tmout,则以hang_tmout为timeout,重新执行一次runt_target
- 如果结果为
FAULT_CRASH,就跳转到keep_as_crash - 如果结果不是
FAULT_TMOUT,就返回keeping,否则就使unique_hangs计数器加一,然后更新last_hang_time的值,并保存到alloc_printf("%s/hangs/id:%06llu,%s", out_dir, unique_hangs, describe_op(0))文件。
- 如果结果为
- FAULT_CRASH
- total_crashes计数器加一
- 如果unique_crashes大于能保存的最大数量
KEEP_UNIQUE_CRASH即5000,就直接返回keeping的值 - 同理,如果不是dumb mode,就
simplify_trace((u64 *) trace_bits)进行规整 - 如果没有发现新的crash路径,就直接返回keeping
- 否则,代表发现了新的crash路径,unique_crashes计数器加一,并将结果保存到
alloc_printf("%s/crashes/id:%06llu,sig:%02u,%s", out_dir,unique_crashes, kill_signal, describe_op(0))文件。 - 更新last_crash_time和last_crash_execs
- FAULT_ERROR
- 抛出异常
- 对于其他情况,直接返回keeping
- FAULT_TMOUT
simplify_trace(u64 *mem)
-
按8个字节为一组循环读入,直到完全读取完mem
- 如果mem不为空
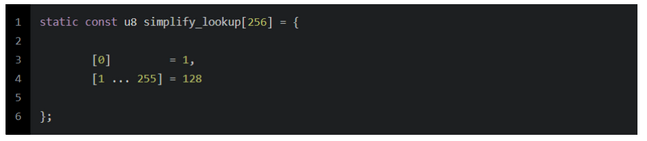
- i从0-7,
mem8[i] = simplify_lookup[mem8[i]],代表规整该路径的命中次数到指令值,这个路径如果没有命中,就设置为1,如果命中了,就设置为128,即二进制的1000 0000
- i从0-7,
- 否则设置mem为
0x0101010101010101ULL,即代表这8个字节代表的path都没有命中,每个字节的值被置为1
- 如果mem不为空
afl-gcc源码
find_as
- 该函数主要用来寻找afl-as的位置
- 首先检查AFL_PATH变量,检查afl_path/as文件是否可以访问,可以就设置afl_path为as_path
- 如果不存在,检查argv0,到当前目录下找afl-as文件
- 如果两种方式都失败,抛出异常
edit_params
- 该函数将argv拷贝到cc_params中
- 将argv[0]赋值给name,将name和afl-clang比较
- 如果相同,设置clang_mode为1,然后比较name和afl-clang++
- 如果相同,则获取环境变量AFL_CXX的值,如果存在,则将cc_params[0]设置为该值,不存在则设置为clang++
- 如果不相同,则获取环境变量AFL_CC,如果存在,则将cc_params[0]设置为该值,不存在则设置为clang
- 如果不相同,将name和afl-g++比较
- 如果相同,则获取环境变量AFL_CXX的值,如果存在,则将cc_params[0]设置为该值,不存在则设置为g++
- 如果不相同,则获取环境变量AFL_CC,如果存在,则将cc_params[0]设置为该值,不存在则设置为gcc
- 如果相同,设置clang_mode为1,然后比较name和afl-clang++
- 从arv[1]开始读取,设置其他cc_params参数,设置汇编器搜索路径
-B as_path
main函数
- afl-gcc就是找到as所在的位置,将其加入搜索路径,然后设置必要的gcc参数和一些宏,然后调用gcc进行实际的编译,仅仅只是一层wrapper
afl-as源码
edit_params
- 检查并修改参数传递给as汇编器,将传递的最后一个参数作为input_file(原文件的汇编),设置插桩处理文件modified_file为tmp_dir/afl-pid-tim.s,并加入as_params
add_instrumentation
- 处理输入文件,生成modified_file,将instrumentation插入所有适当的位置
- 将input_file读入inf指向内存,将modified_file读入outf指向内存
- 插桩的位置标记

- 插桩的核心代码
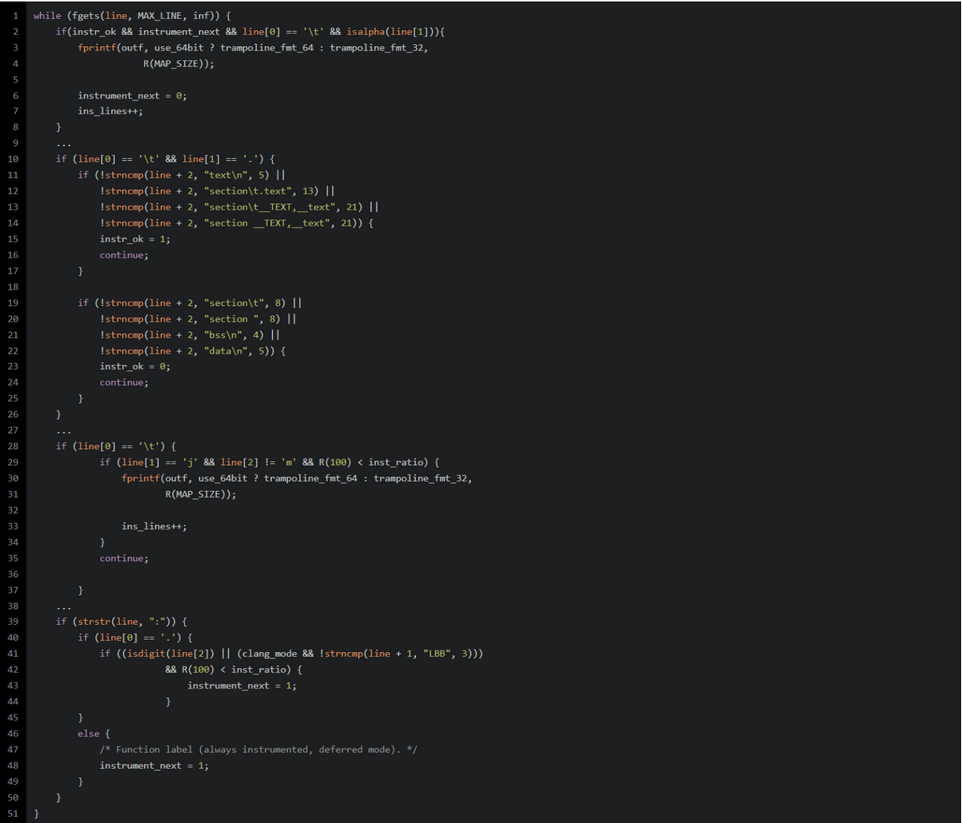
-
检查
instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])即判断instrument_next和instr_ok是否都为1,以及line是否以\t开始,且line[1]是否是字母- 如果都满足,则设置
instrument_next = 0,并向outf中写入trampoline_fmt,并将插桩计数器ins_lines加一 - 这其实是因为我们想要插入instrumentation trampoline到所有的标签,宏,注释之后。
- 如果都满足,则设置
-
首先要设置instr_ok的值,这个值其实是一个flag,只有这个值被设置为1,才代表我们在
.text部分,否则就不在。于是如果instr_ok为1,就会在分支处执行插桩逻辑,否则就不插桩- 如果line的值为
\t.[text\n|section\t.text|section\t__TEXT,__text|section __TEXT,__text]...其中之一,则设置instr_ok为1,然后跳转到while循环首部,去读取下一行的数据到line数组里 - 如果不是上面的几种情况,且line的值为
\t.[section\t|section |bss\n|data\n]...,则设置instr_ok为0,并跳转到while循环首部,去读取下一行的数据到line数组里。
- 如果line的值为
-
插桩
^\tjnz foo条件跳转指令-
如果line的值为
\tj[!m]...,且R(100) < inst_ratio,R(100)会返回一个100以内的随机数,inst_ratio是我们之前设置的插桩密度,默认为100,如果设置了asan之类的就会默认设置成30左右。 -
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));根据use_64bit来判断向outfd里写入trampoline_fmt_64还是trampoline_fmt_32
define R(x) (random() % (x)),可以看到R(x)是创建的随机数除以x取余,所以可能产生碰撞- 这里的R(x)实际上是用来区分每个桩的,也就是是一个标识,后文会再说明
-
将插桩计数器
ins_lines加一
-
-
首先检查该行中是否存在
:,然后检查是否以.开始- 如果以
.开始,则代表想要插桩^.L0:,或者^.LBB0_0:这样的branch label,即style jump destination- 然后检查
line[2]是否为数字或者如果是在clang_mode下,比较从line[1]开始的三个字节是否为LBB. 前述所得结果和R(100) < inst_ratio)相与- 如果结果为真,则设置
instrument_next = 1
- 如果结果为真,则设置
- 然后检查
- 否则代表这是一个function,插桩
^func:function entry point- 直接设置
instrument_next = 1
- 直接设置
- 如果以
-
如果插桩计数器ins_lines不为0,就在完全拷贝input_file之后,依据架构,像outf中写入main_payload_64或者main_payload_32,然后关闭这两个文件
-
至此可以看出afl的插桩相当简单粗暴,就是通过汇编的前导命令来判断这是否是一个分支或者函数,然后插入instrumentation trampoline
main函数
- 读取环境变量AFL_INST_RATIO的值,设置为inst_ratio_str
- 设置srandom的随机种子为
rand_seed = tv.tv_sec ^ tv.tv_usec ^ getpid(); - 设置环境变量AS_LOOP_ENV_VAR的值为1
- 读取环境变量AFL_USE_ASAN和AFL_USE_MSAN的值,如果其中有一个为1,则设置sanitizer为1,且将inst_ratio除3。
- 这是因为AFL无法在插桩的时候识别出ASAN specific branches,所以会插入很多无意义的桩,为了降低这种概率,粗暴的将整个插桩的概率都除以3
- edit_params(argc, argv)
- add_instrumentation()
- fork出一个子进程,让子进程来执行
execvp(as_params[0], (char **) as_params)- 这其实是因为我们的execvp执行的时候,会用
as_params[0]来完全替换掉当前进程空间中的程序,如果不通过子进程来执行实际的as,那么后续就无法在执行完实际的as之后,还能unlink掉modified_file
- 这其实是因为我们的execvp执行的时候,会用
waitpid(pid, &status, 0)等待子进程结束- 读取环境变量AFL_KEEP_ASSEMBLY的值,如果没有设置这个环境变量,就unlink掉modified_file
插桩代码
- 用于进程间通信和记录覆盖率信息,相关代码位于afl-as.h
关键变量和常量
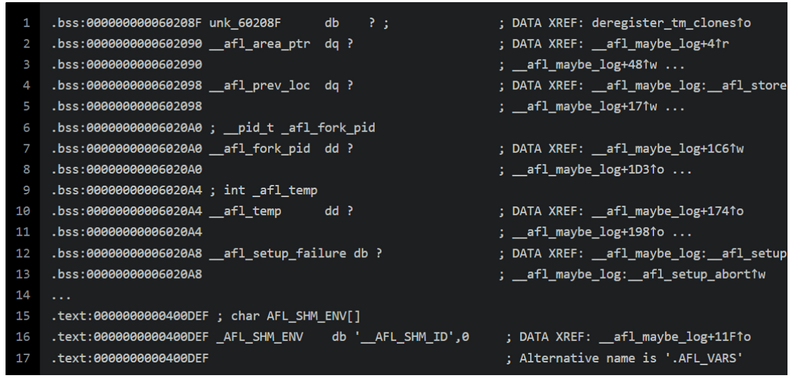
- __afl_area_ptr
- 存储共享内存的首地址
- __afl_prev_loc
- 存储上一个位置,即上一次R(MAP_SIZE)生成的随机数的值
- __afl_fork_pid
- 存储fork出来的子进程的pid
- __afl_temp
- 临时buffer
- _AFL_SHM_ENV
- 申请的共享内存的shm_id被设置为环境变量
__AFL_SHM_ID的值,所以通过这个环境变量来获取shm_id,然后进一步得到共享内存
- 申请的共享内存的shm_id被设置为环境变量
- afl_global_area_ptr
- 用于赋值给afl_area_ptr
trampoline_fmt_64
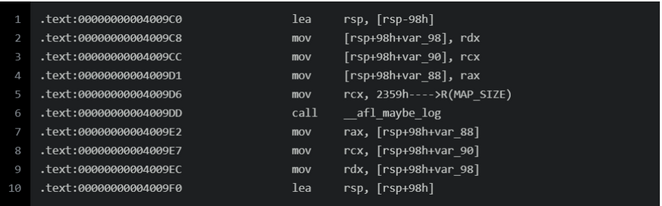
- 插入的trampoline_fmt_64只有在
mov rcx, xxx这里不同,其xxx的取值就是随机数R(MAP_SIZE)(由add_instrumention函数通过格式化字符串替换值),以此来标识与区分每个分支点,然后传入__afl_maybe_log作为第二个参数调用这个函数
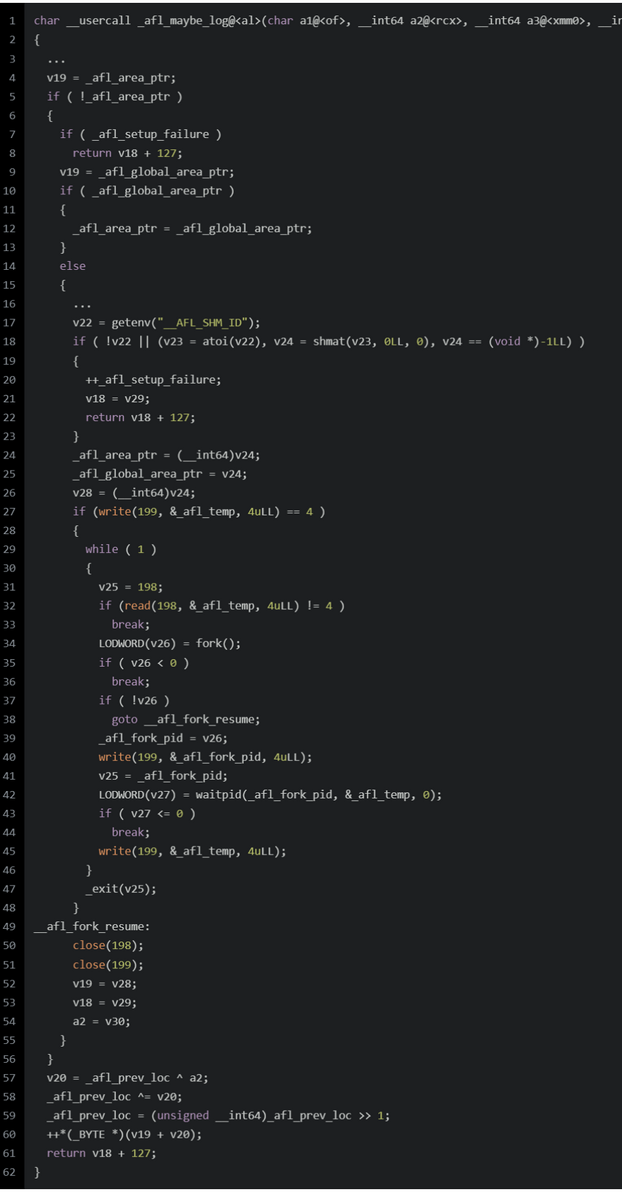
afl_maybe_log
直接看汇编,还是很好理解的
-
首先检查
_afl_area_ptr是否为0,即是否共享内存已经被设置了。
换句话说,只有第一个__afl_maybe_log会执行这个if里的代码
-
如果
_afl_area_ptr为0,即共享内存还没被设置,则判断_afl_setup_failure是否为真,如果为真,则代表setup失败,直接返回。
-
读取
_afl_global_area_ptr的值-
如果不为0,则赋值给
_afl_area_ptr -
否则
-
首先读取环境变量
__AFL_SHM_ID,默认是个字符串,atoi转一下,得到shm_id,然后通过shmat启动对该共享内存的访问,并把共享内存连接到当前进程的地址空间,将得到的地址,保存到_afl_area_ptr和_afl_global_area_ptr中。 -
然后通过
FORKSRV_FD+1即199这个文件描述符,向状态管道中写入4个字节的值,用来告知afl fuzz,fork server成功启动,等待下一步指示。 -
进入
__afl_fork_wait_loop循环,从FORKSRV即198中读取字节到
_afl_temp,直到读取到4个字节,这代表afl fuzz命令我们新建进程执行一次测试。- fork出子进程,原来的父进程充当fork server来和fuzz进行通信,而子进程则继续执行target。
- 父进程即fork server将子进程的pid写入到状态管道,告知fuzz。
- 然后父进程即fork server等待子进程结束,并保存其执行结果到
_afl_temp中,然后将子进程的执行结果,从_afl_temp写入到状态管道,告知fuzz。 - 父进程不断轮询
__afl_fork_wait_loop循环,不断从控制管道读取,直到fuzz端命令fork server进行新一轮测试。
-
-
-
-
-
如果
_afl_area_ptr不为0,即共享内存已经被设置好了。那么就跳过上面的if,只执行__afl_store逻辑,伪代码如下:- 简单的说,就是将上一个桩点的值(prev_location)和当前桩点的值(
R(MAP_SIZE))异或,取值后,使得共享内存里对应的槽的值加一,然后将prev_location设置为cur_location >> 1; - 因此,AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数。用于保存执行次数的实际上是一个哈希表,大小为MAP_SIZE=64K,当然会存在碰撞的问题;但根据AFL文档中的介绍,对于不是很复杂的目标,碰撞概率还是可以接受的。
- 另外,比较有意思的是,AFL需要将cur_location右移1位后,再保存到prev_location中。官方文档中解释了这样做的原因。假设target中存在A->A和B->B这样两个跳转,如果不右移,那么这两个分支对应的异或后的key都是0,从而无法区分;另一个例子是A->B和B->A,如果不右移,这两个分支对应的异或后的key也是相同的。
- 简单的说,就是将上一个桩点的值(prev_location)和当前桩点的值(
afl_clang_fast源码
- clang的wrapper,llvm模式的入口
- 查找运行时库和链接文件的位置
- 设置参数,如果未启用AFL_TRACE_PC,使用afl-llvm-pass.o传统模式插桩记录覆盖率代码,如果启用,使用llvm新的trace-pc-guard模式来插桩覆盖率代码
- 通过-Xclang链接afl-llvm-pass.so和运行库afl-llvm-rt.o
- 用execvp执行clang
afl-llvm-pass.so.cc源码
- 注册pass
- 在runOnModule中通过getFirstInsertionPt扫描basic block,对基本块进行随机插桩(由插桩密度控制),覆盖率记录插桩代码同afl-gcc
- 链接llvm库,编译生成afl-llvm-pass.so,由clang来加载,用于在IR层面改造目标程序代码
afl-llvm-rt.o.c源码
- llvm mode的三个功能在这里实现
初始化
- afl_auto_init是
__attribute__ constructor(被此修饰的函数将在main执行之前自动运行),该函数判断如果设置了defer模式则直接返回(由手动设置的AFL_INIT去调用afl_manual_init),否则调用afl_manual_init
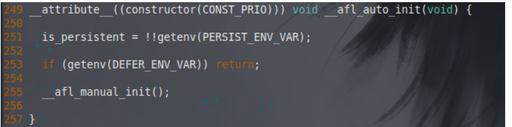
- afl_manual_init:如果没有初始化,调用afl_map_shm设置共享内存,调用afl_start_forkserver启动forkserver
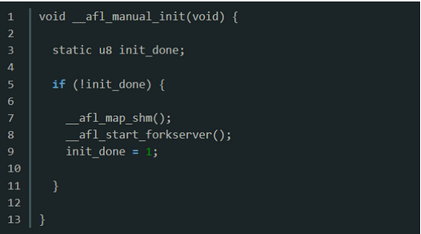
- afl_start_forkserver
- 首先,设置
child_stopped = 0,写入4字节到状态管道,通知fuzzer已准备完成; - 进入
while,开启fuzz循环:- 调用
read从控制管道读取4字节,判断子进程是否超时。如果管道内读取失败,发生阻塞,读取成功则表示AFL指示forkserver执行fuzz; - 如果
child_stopped为0,则fork出一个子进程执行fuzz,关闭和控制管道和状态管道相关的fd,跳出fuzz循环; - 如果
child_stopped为1,在persistent mode下进行的特殊处理,此时子进程还活着,只是被暂停了,可以通过kill(child_pid, SIGCONT)来简单的重启,然后设置child_stopped为0; - forkserver向状态管道
FORKSRV_FD + 1写入子进程的pid,然后等待子进程结束; WIFSTOPPED(status)宏确定返回值是否对应于一个暂停子进程,因为在persistent mode里子进程会通过SIGSTOP信号来暂停自己,并以此指示运行成功,我们需要通过SIGCONT信号来唤醒子进程继续执行,不需要再进行一次fuzz,设置child_stopped为1;- 子进程结束后,向状态管道
FORKSRV_FD + 1写入4个字节,通知AFL本次执行结束。
- 调用
- 首先,设置
deferred instrumentation
- 通过手动将如下代码插入目标源码中,自定义目标程序fork的时机,实现延迟fork

- AFL_INIT中调用了afl_manual_init
- 通过该方法消除许多OS,链接器和libc级别执行程序的成本
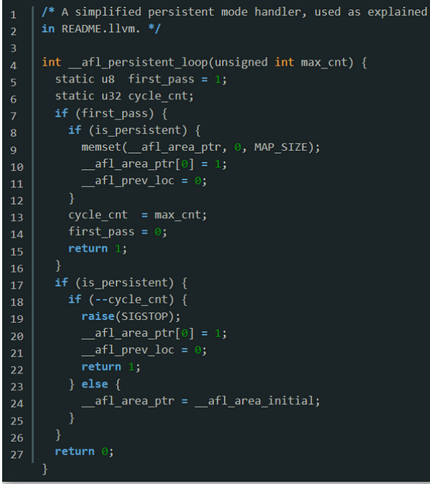
persistent mode
- 部分正在被fuzz的API是无状态的,当API重置后,长期活跃的进程就可以被重复使用,即一个进程执行多个用例,通过该方法消除重复执行fork需要的开销
- 对应宏是AFL_LOOP(1000)(内部调用afl_persistent_loop),可以设置循环的最大数量,表示该子进程重复执行的次数,太大可能会造成内存泄露
- 运行流程:第一次进入loop,初始化然后返回1,再次进入,计数减1,raise(SIGSTOP)暂停进程,forkserver此时收到暂停信号,设置child_stopped=1,并通知afl-fuzzer,当fuzzer再一次进行fuzz时,恢复之前的子进程继续执行,并设置child_stopped=0
- 直到第1000次,不会再暂停子进程,令
__afl_area_ptr指向无关的__afl_area_initial,随后子进程结束。指向一个无关值主要是因为程序仍然会进行插桩,导致向__afl_area_ptr中写值。我们选择向一个无关的位置写值而不影响到共享内存等。
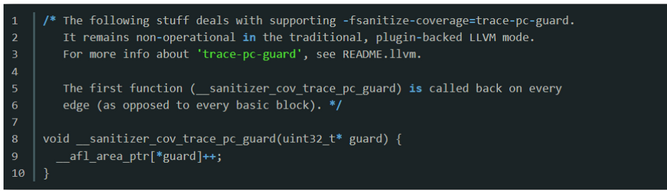
trace-pc-guard mode
- 该模式是依靠了LLVM本身的新功能,因此其具体实现由LLVM完成。AFL项目中仅实现了使用LLVM-trace-pc-guard功能的两个回调函数
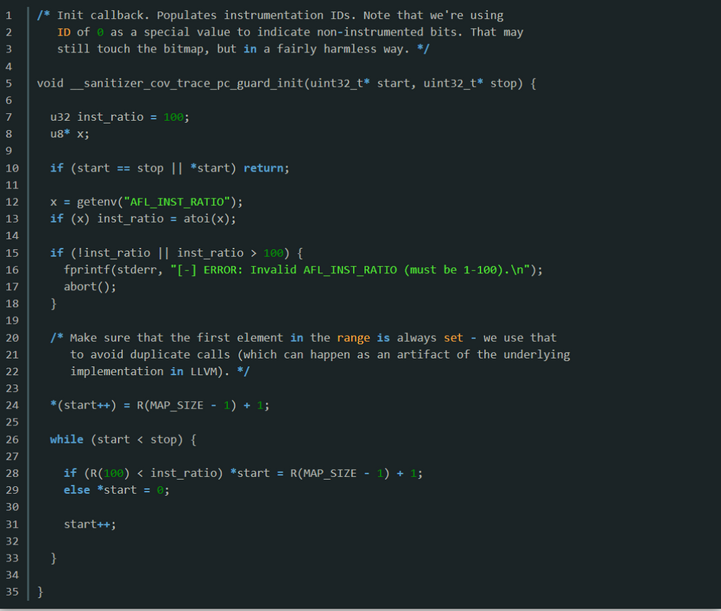
__sanitizer_cov_trace_pc_guard(uint32_t* guard):每个代码块的尾部都会插入这个函数的代码,并且每个代码块都有独立的guard变量可以操作。此处通过guard变量的值来代表各个代码块的ID,从而使用如下代码来标记目标代码块被执行到,以此作为新路径的判断依据:
__sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop):对guard做了一些初始化的工作,给每个代码块的guard都分配一个随机的ID。如果用户通过AFL_INST_RATIO环境变量来设置了插桩覆盖比例,则根据这个比例的值来对部分代码块的ID标记为0,代表不用插桩。主要逻辑代码如下:
其他
- stat:获取文件属性
- mmap:将普通文件映射到内存中,addr设为0,则由系统自动选定地址,映射成功后返回该地址
- strchr:返回字符第一次出现在字符串中的位置,strstr返回一个字符串在另一个中的位置
- access:检查文件是否能访问
- gettimeofday:返回当前时间
- alloc_printf:申请堆块,将字符串printf到堆块中
- link:硬链接相当于别名,内存中创建一份新文件,但共用一个inode,改变会影响
- symlink:软链接相当于快捷方式,文件内存储的是原文件的inode
- 复制是完全拷贝,全新文件,完全无关
- unlink:删除文件链接,如果是最后一个连接点,则删除文件
- 运行时链接动态库:dl_open将AFL_POST_LIBRARY指定的库加载进来,通过dlsym将afl_postprocess符号地址读入到post_handle
- memem:在内存中寻找匹配另一块内存的内容的位置(比如字符串查找)
- getopt(argc, argv, "option"):单个字符表示选项;单个字符后接一个冒号,表示选项后跟一个参数,用空格隔开;接两个冒号,表示选项后跟一个参数,不用空格分开;optarg指向选项后的参数,optind存储第一个不包含选项的命令行参数
- ftruncate(int fd, off_t length):将fd指向文件改变为length指定大小
- getrlimit:获取进程的各种资源限制
- setrlimit:设置进程的各种资源限制
问题
- resuming sessions是什么
- dumb_mode
- crash_mode
- clion调试子进程,查看源码
- 怎么抓OU

 浙公网安备 33010602011771号
浙公网安备 33010602011771号