哈工大李治军老师《操作系统》课程学习笔记
- 1 什么是操作系统
- 2 操作系统boot
- 3 操作系统启动
- 4 操作系统接口
- 5 系统调用的实现
- 6 操作系统历史
- 7 CPU管理
- 8 多进程图像
- 9 用户线程
- 10 内核级线程
- 11 内核级线程实现
- 12 操作系统的那棵“树”
- 13 CPU调度策略
- 15 一个实际的schedule函数
- 16 进程同步与信号量
- 17 对信号量的临界区保护
- 18 信号量的代码实现
- 19 死锁处理
- 20 内存使用与分段
- 21 内存分区与分页
- 22 多级页表和快表
- 23 段页结合的实际内存管理
- 24 内存换入—请求调页
- 25 内存换出
- 26 IO与显示器
- 27 键盘
- 28 生磁盘的使用
- 29 从生磁盘到文件
- 30 文件使用磁盘的实现
- 31 目录与文件系统
- 32 目录解析代码实现
1 什么是操作系统
- 是计算机硬件和应用之间的一层软件
- CPU管理、内存管理、终端管理、磁盘管理、文件管理
- 操作系统除了内核,还有一些其他组件,比如文本编辑器,编译器,用来与用户交互的程序、接口库、驱动程序等
2 操作系统boot
- 启动盘由boot引导扇区、setup的4个扇区和system模块(OS代码)组成
- boot位于0磁道0扇区(256字节)
- boot代码bootsect.s使用汇编写的,目的是完整控制不出错,包括内存地址
(1)BIOS启动
-
CPU运行在实模式下
-
CS:IP指向0xFFFF0的BIOS ROM区
-
检查RAM,外设
-
将boot扇区读入0x7c00处并跳转
(2)boot引导
- 将boot代码拷贝到0x9000处并跳转,挪动目的是腾出空间
- 将setup4个扇区内容拷贝到0x9100
- 显示"Loading system"和logo
- 读入system模块
- 转入setup执行
3 操作系统启动
3.1 setup
-
setup模块,即setup.s也是用汇编写的,完成OS启动前的设置
-
读硬件参数存储到内存数据结构中,比如扩展内存后将大小放到0x9002
-
将system移动到0地址
-
初始化gdt表
-
启动保护模式,跳转到0地址处
3.2 关于保护模式
-
通过mov cr0, 1进入保护模式
-
CPU、寄存器、地址线从16位切换到32位模式,段寄存器仍为16位
-
寻址方式改变,走另外一条电路,不再是CS*16+IP
-
CS里放的是段选择子,用于查gdt表项,取基址,再加偏移,查表是硬件实现的
-
每个表项称为段描述符,包含4个部分,共8字节
-
intel8086汇编格式变为32位汇编代码AT&T
-
使用idt来查中断向量
-
idt和gdt可以放在内存中任意位置,相关寄存器指向起始地址
3.3 system模块
-
操作系统源码通过Makefile编译为image
-
system中的第一个模块是head.s,完成初始化idt、gdt的工作,通过ret main从进入main函数
-
main.c完成初始化工作,如trap_init、mem_init,推出后进入死循环
-
mem_init初始化了mem_map页表
4 操作系统接口
-
用户使用计算机:命令行、图形按钮、应用程序
-
命令行:shell程序在死循环中执行命令,命令也是一段程序
-
图形按钮:硬件输入存到系统消息队列中,通过消息循环GetMessage获取消息并处理
-
用户使用计算机的本质是通过程序,即重要函数和普通c代码
-
本质都是c程序,调用了重要函数进入操作系统
-
操作系统提供的这类重要函数,就是操作系统接口,也叫系统调用
5 系统调用的实现
- 系统调用的作用:提供统一接口供上层使用;作为用户态通往内核态的大门
5.1 为什么要隔离用户态和内核态
- 内核中存储重要数据,不让用户态访问
- 用户态不能通过jmp到内核中,也不能通过mov指令访问内核数据
5.2 如何隔离用户态和内核态
- CPU提供了特权环的机制来实现特权级检查(硬件实现检查)
- CPL(当前特权级)和DPL(描述符特权级):只有CPL<=DPL时,指令才能被执行
- 特权检查发生在访问/跳转到一个目标内存区域(段)之时
- CPL位于CS段寄存器的最后两位,即当前指令所在段的特权级
- DPL位是GDT表中的段描述符,即目标内存段的特权级
- 普通的用户态指令不能访问/跳转内核态
5.3 系统调用如何进入内核态
- 中断是进入内核的唯一方法
(1)系统调用的核心
- 系统调用是一段包含中断的代码
- 操作系统写中断处理,获取想掉程序的编号
- 操作系统根据编号执行相应代码
(2)系统调用的实现
- 应用程序调用printf->库函数printf->库函数write->系统调用write
- 库函数write中调用了一个_syscall3的宏,传入write常量
- syscall3宏中包含c语言内嵌汇编,包含 int0x80,通过寄存器传入参数和返回值存到eax,__NR_write系统调用号
(3)IDT的初始化
- sched_init
- set_system_gate设置中断处理,向IDT表中写入system_call偏移地址,段选择符和DPL=3
- 由于DPL=3,所以当前指令能够执行,成功调用内核态函数system_call,并且CS段选择符被置为内核区域
(4)int0x80中断的处理
- 在跳转中断处理程序时,DPL被强行置为3,成功跳转到内核态
- 跳转后CPL被置为0,可以访问任何内存区域
- 执行中断处理程序system_call
(5)system_call
- call _sys_call_table(, %eax, 4),全局函数指针数组
- 通过eax传入系统调用号,找到sys_write
- 调用sys_write内核态函数
6 操作系统历史
- 多进程图谱,CPU、内存,Unix的出现
- 文件操作图谱,文件、磁盘、IO,DOS/Windows的出现
7 CPU管理
- CPU的核心:取指执行
- 单程序运行的问题:遇到IO指令后卡住,CPU利用率太低
- 解决办法是在卡住后切到另一个程序运行,之后再切回来
- 需要一个结构来保存程序运行中的信息(PC等寄存器)
- 引出了进程的概念:运行中的程序,使用PCB来存放运行信息
- 多进程并发执行是CPU管理的核心
8 多进程图像
- main函数最后一行,创建初始化进程,启动shell/桌面,在其中启动其他进程
8.1 如何组织多进程
-
操作系统用PCB组织多进程,将相应的PCB放到队列中
-
正在执行的进程:运行态
-
等待执行的进程:就绪态
-
等待事件的进程:阻塞态
8.2 多进程如何交替
- 启动磁盘读写后,将pCur设为阻塞态,放入阻塞队列
- schedule函数中,通过getNext调度函数,从队列中找到下一个PCB
- 通过操作pCur和pNew,切换到下一个进程
8.3 多进程的内存隔离
-
进程之间相互访问内存会带来问题
-
通过映射表实现进程内存隔离
-
多进程管理连带形成内存管理
8.4 多进程合作
-
如word和ppt放入打印机队列
-
生产者进程往共享缓冲区中放内容,消费者进程取内容,会带来counter计算错误
-
通过给counter上锁,合理的推进顺序,实现进程同步
9 用户线程
9.1 线程的引入
-
进程=内存资源+指令序列,进程的切换分为两部分:指令切换和内存切换
-
线程共享内存资源,切指令不切映射表,保留并发优点,降低进程的切换代价
-
如浏览器线程:接收数据、显示文本、显示图片
9.2 用户线程的切换
- 核心是线程创建Create和线程切换Yield
(1)Yield
-
两个线程需要用两个栈,保证当前函数调用使用当前栈,不乱套
-
栈切换需要用TCB保存栈顶指针
-
不需要主动切换pc,因为pc已经在栈里了(不用jmp,直接返回)
(2)Create
- 创建TCB,通过malloc分配内存
- 创建线程栈,通过malloc分配内存
- 将函数地址压栈
- TCB保存栈顶指针
(3)组合

(4)用户线程和内核线程
-
操作系统完全感知不到用户级线程,线程阻塞时CPU可能会切换到另一进程,而不是另一用户线程
-
内核线程:ThreadCreate是系统调用,内核维护TCB,通过Schedule切换,系统决定调度,
-
内核级线程由操作系统托管,并发性更好
10 内核级线程
- 进程都是内核级的,需要分配内存资源,访问外设
10.1 多核
-
多处理器是每个CPU都有一套Cache和MMU(映射),多核是多个CPU共用一套Cache和MMU
-
只有内核级线程才能发挥多核特点(分配给另一个核心执行)
10.2 用户级和核心级线程的不同
- ThreadCreate是系统调用,内核管理TCB,内核负责切换线程
- 每个内核线程都有用户栈和内核栈
- 切换时由两个栈变为两套栈,用户栈和内核栈都切
- 关联:
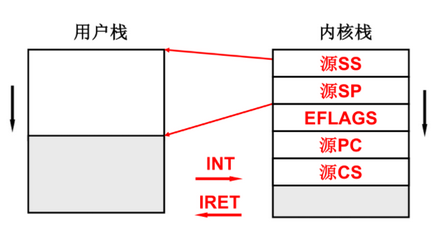
10.3 内核线程切换的五段论
- 线程S int中断引发中断处理,同时通过硬件进入内核栈,在内核执行代码
- 中断处理函数中进行磁盘读,引发切换,schedule
- 通过调度找到下一个线程T的TCB(TCB指向内核栈SP)
- 通过TCB进行线程T的内核栈切换
- 通过IRET返回线程T的用户栈
10.4 内核线程的创建
- 创建TCB
- 创建用户栈和内核栈并关联
- TCB指向内核栈顶
- TCB进入队列
11 内核级线程实现
- 以fork为例,通过中断进入内核,复制了一份子进程后退出内核
(1)切换
-
schedule
-
linux0.1使用TSS(PCB的一部分)而不是内核栈进行切换
-
通过ljmp一条指令跳转切换,过慢(不能使用指令流水)
-
ljmp:把当前CPU的寄存器现场放到TSS中,根据TSS(n)找到新TSS,覆盖到CPU的寄存器上
-
EIP也通过TSS覆盖,没有用到栈传递
(2)创建
- _sys_fork中调用了_copy_process,将当前所有寄存器作为参数传入
- 首先申请一页内存p作为PCB和TSS
- 在PCB上方创建内核栈并用tss->esp0指向栈顶
- 和父进程共用一个用户栈,并用tss->esp指向栈顶
- tss的eip和cs通过传入参数赋值,eax置为0(作为子进程的返回值)
(3)执行目标代码
- 子进程调用exec(cmd)函数
- 调用sys_execve系统调用,进入内核态
- 调用do_execve,将内核栈的ret_eip置为cmd程序的入口地址(从可执行文件的head处读取),SS:SP处被置为新的用户栈顶
- iret返回后,执行目标程序代码
12 操作系统的那棵“树”
- 操作系统的内核:CPU管理和内存管理
(1)一个实例,屏幕上交替打A和B

-
父进程进入内核,将两个子进程的PCB填写好,并修改tss-eip为printf("A")和printf("B")
-
父进程wait后阻塞,进入内核,调用schedule,调度策略选择next,switch_to(next),目标tss覆盖当前CPU寄存器,切换到子进程
-
子进程间利用时钟中断,进入内核,分配时间片counter,为0调用schedule切换(调度点)
13 CPU调度策略
-
前台任务关注响应时间(从操作到响应),后台任务关注周转时间(从任务进入到结束)
-
响应时间小,切换次数多,系统内耗大,吞吐量小
-
IO约束性任务(前台任务),优先级应该高,CPU约束性任务(后台任务)
(1)SJF算法
- 短作业优先,平均周转时间最小
(2)RR算法
- 按时间片来轮转调度,减小响应时间
(3)优先级算法
-
前台任务队列用轮转调度
-
后台用短作业
-
之间用优先级调度,照顾前台进程
-
优先级调度可能造成进程饥饿,还需综合考虑
15 一个实际的schedule函数

- counter既可以作为时间片,进行轮转调度,并且时间片是收敛的(除以2+p),保证响应时间的界
- counter还可以作为优先级,找到优先级最高的任务,并且优先级可以动态调整(在时间片都为0后,除以2加初值,就绪队列counter不变,阻塞队列即经过IO的进程counter会变大),照顾了前台进程
- 后台进程一直按照counter轮转,近似SJF调度
16 进程同步与信号量
-
进程间合理有序的推进:需要停下来等待,根据信号判断继续执行(让进程走走停停)
-
信号量用来判断可供使用的资源数量
-
信号量的定义:

- V{s.value++; if(s.value <= 0){wakeup}}
- 操作PCB,P和V做成了系统调用
- 用信号量解决生产者—消费者问题

- 思路:空闲单元为0时生产者停下来(p(empty)),消费者对应增加(V(empty));生产内容为0时消费者停下 来(p(full)),生产者对应增加(V(full))
- empty表示空闲单元数量,full表示生产内容的数量
- mutex表示只能让一个进程修改缓冲区
- 再次思考:一个信号量的含义是表示能让对应的进程能够使用多少次
17 对信号量的临界区保护
-
错误由多个进程并发操作共享数据(信号量)引起
-
解决办法:给共享变量上锁,临界区是成对出现的,一方进入,另一方不能进入对应临界区
-
关键是写进入区和退出区的代码
-
基本原则:互斥进入;有空让近;有限等待
-
Peterson算法:标记+轮转
-
简单的:使用cli和sti来上锁,防止另一进程被调度(仅限单核CPU)
-
另一简单的:硬件原子指令法,不能用信号量来上锁(信号量本身可能被打断),但可以用一条指令来上锁
18 信号量的代码实现
(1)用户态程序
1.sd=sem_open("empty")
typedef struct {
char name[20];
int value;
task_struct * queue;
} semtable[20];
sys_sem_open(char * name)
{
在semtable中寻找name对应的结构体,没找到则创建,返回下标;
}
2.sem_wait(sd)
sys_sem_wait(int sd){
cli();
if(semtable[sd].value-- < 0){
设置自己为阻塞;
加入semtable[sd].queue;
schedule();
}
sti();
}
- 信号量在内核中,涉及到pcb切换
- task_struct(tss)就是linux的pcb,tcb是线程用的
(2)内核态程序
-
bread启动磁盘读后睡眠,等待磁盘读完后通过磁盘中断将其唤醒,也是利用了信号量同步
-
while和if的区别:if是将阻塞队列中第一个唤醒,while是全部唤醒
19 死锁处理
(1)死锁的成因
- 资源互斥使用,一旦占有别人无法使用
- 进程占有了一些资源不释放,再去申请其他资源
- 各自占有的资源和申请的资源形成了环路等待
(2)死锁的处理方法
- 死锁预防:破坏死锁出现的条件
- 死锁避免:检测每个资源请求,如果造成死锁就拒绝
- 死锁检测+恢复:检测到死锁出现时,让一些进程回滚,让出资源
- 死锁忽略:就好像没有死锁一样,如重启
20 内存使用与分段
(1)重定位
-
修改程序中的地址
-
编译时重定位:只能放到固定位置
-
载入时重定位,进程交换内存后(阻塞后换入换出),载入地址被修改,不能满足换入换出的需求
-
运行时重定位:每执行一条指令都要从逻辑地址计算出物理地址(地址翻译),基址放到PCB中,进程运行时赋值给基地址寄存器
(2)分段
-
每个段特点不同,不是将整个程序,而是分段放入内存
-
段表:用来保存每个段的地址,包含段号,段基址,长度和段属性
-
操作系统的段表叫GDT,每个进程的段表叫LDT
-
载入时将LDT赋值给PCB,进程运行时将PCB赋值给LDT,计算各段指令的物理地址
21 内存分区与分页
- 内存管理:编译时程序分段,在内存中找到空闲分区,磁盘读写载入内存并建立LDT
(1)内存分区
-
将程序的各个段载入到相应的内存分区
-
可变分区算法:最先适配、最差适配、最佳适配
-
分区用于虚拟内存,分页用于物理内存
(2)内存分页
-
可变分区内存碎片造成的问题
-
将每个段分成4K的页
-
按照给出的逻辑地址计算出第几页和页内偏移,通过页表找到对应页框,计算出物理地址
-
页表:保存页框和页号的对应关系 ,CR3寄存器指向页表
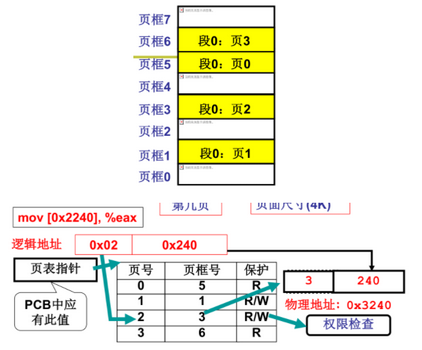
22 多级页表和快表
(1)问题
- 为了提高内存空间利用率,页应该小,页表项就多,页表就大
- 程序只用到很小部分逻辑页,大部分页表项用不到
- 如果只存放用到的页表项,页表就需要比较查找,费时,所以页表项必须连续存放
(2)多级页表
-
通过页目录表(章)和页表(节)形成多级页表查找
-
通过一个顶级页表为真正用到的页表提供索引,用不到的二级页表不放入内存
-
既保证连续,又能减小内存空间占用
-
每个页4k,每个二级页表有1k个表项
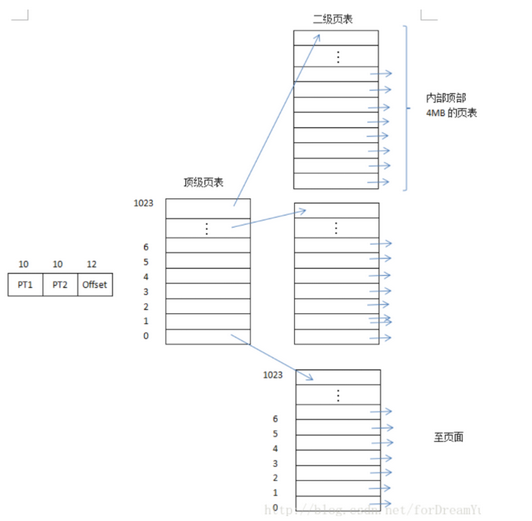
(2)快表
-
多级页表增加了访存的次数,用时多
-
TLB是一组快速存储寄存器,保存经常用到的页表项,通过硬件实现查找
-
快表未命中时,通过多级页表补充查找
-
TLB页表项可以很少的原因:程序访问内存的局部性(程序多为循环和顺序结构)
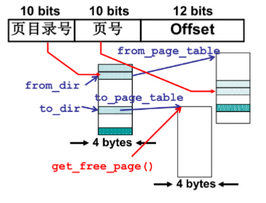
23 段页结合的实际内存管理
-
操作系统实现了虚拟内存,从用户角度看,实现了段,从物理内存上看,实现了页
-
使用内存 需要经过两层地址翻译
-
一个实际的段、页式内存管理
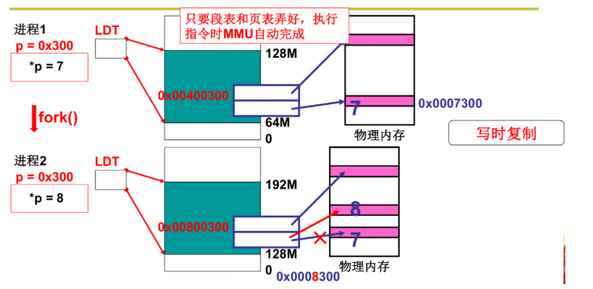
23.1 载入(以fork为例)
(1)分配虚存,建段表
- set_base(p->ldt[1], new_data_base)
(2)分配内存,建页表
* 虚拟地址作为页号来查找
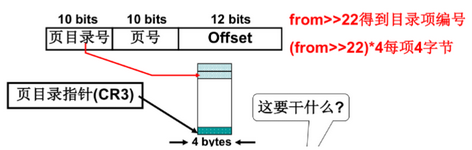
- 父子进程用同一个物理页,子进程按照虚拟地址换算来建立新的顶级页表,并分配内存建立新的二级页表,并拷贝父进程的二级页表
23.2 使用(以*p=7为例)
- 查段表和页表,通过MMU硬件完成地址转换
- 父子进程公用一块物理页并设置为只读,写入7时重新分配一块物理页(写时复制)
- 父子进程通过段表和页表进行内存分离
24 内存换入—请求调页
-
虚拟内存是实现分段分页的关键,内存换入换出是实现虚拟内存的关键
-
虚拟地址就是线性地址
-
用换入换出实现大内存,请求的时候才换入并建立映射
-
换入的核心—请求调页(通过缺页中断从磁盘读入到内存空间页)
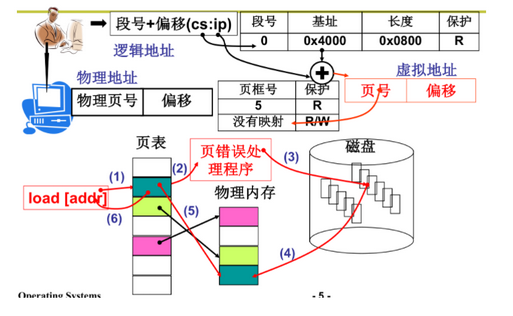
- 处理缺页中断
do_no_page:
1.page=get_free_page(); //获取物理空闲页
2.bread_page(page, current->executable->i_dev, ) //从磁盘设备读入到物理页
3.put_page(page, address); //虚拟地址和物理页关联
put_page{
page_table[(address>>12)&0x3ff] = page|7; //页表
}
25 内存换出
- 在get_free_page中实现,内存有限,不能总是获得新的页,需要按照算法选择一页淘汰,换出到磁盘
- 算法目标:降低缺页次数
- FIFO页面置换:缺页次数高
- MIN算法:选最远将使用的页淘汰,是最优反感,但理论不可行,不知道后来的页框
25.1 LRU算法
- 选最近最长一段时间没有使用的页淘汰
(1)实现1
- 每页维护一个时间戳,选数值最小的页换出
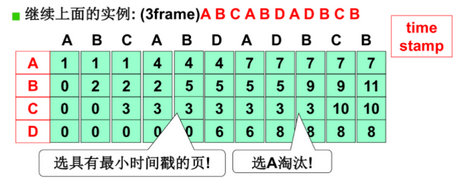
- 每次地址访问都要打时间戳,时间代价太高
(2)实现2
- 维护一个页码栈,每次地址访问都要修改栈,同样时间代价高
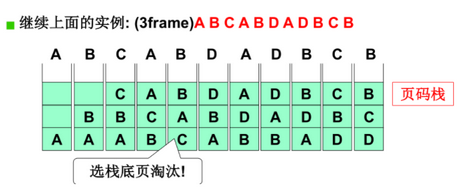
25.2 LRU的近似实现
- 将时间计数变为是和否,记录最近一段时间有没有使用
- 只用修改一位,可以放到页表中,查表时顺便写入
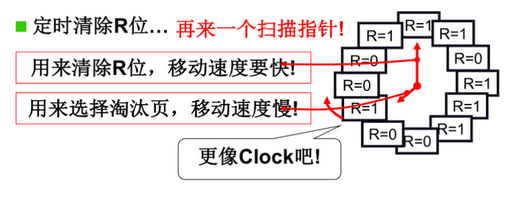
- clock算法,缺页的时候转指针,为0则换出,访问页时置1
- 缺页很少时,退化为FIFO,即很长一段时间内页都使用过
- 解决办法:定时清除R位,再来一个快速扫描指针
26 IO与显示器
26.1 外设工作的三个部分
- CPU向外设发读写指令,外设控制器对寄存器进行读写(in/out)
- 操作系统提供文件视图,使得对寄存器的读写方便
- 中断处理
26.2 操作外设的程序
int fd = open(“/dev/xxx”);
for (int i = 0; i < 10; i++) {
write(fd,i,sizeof(int));
}
close(fd);
- 不论什么设备都是用open、read、write、close,操作系统为用户提供统一的接口
- 不同的设备对应不同的设备文件,根据设备文件找到控制器的地址、内容格式等等
26.3 显示器的输出
(1)找到设备
printf(“Host Name: %s”, name);
->write(1, buf, ...);
->sys_write(fd, buf, ...); //通过fd找到文件的索引
sys_write{
struct file *file;
file = current->filp[fd]; //current进程
inode = file->f_inode; //显示器信息保存在inode中
}
- fd=1的filp从父进程shell fork拷贝而来
void init(void)
{open(“dev/tty0”,O_RDWR,0);dup(0);dup(0); //dup用来复制一个文件描述符,并指向同一个设备
execve("/bin/sh",argv,envp)}
- open系统调用
int sys_open(const char* filename, int flag)
{ i=open_namei(filename,flag,&inode); //inode保存设备信息
cuurent->filp[fd]=f; // 第一个空闲的fd
f->f_mode=inode->i_mode; f->f_inode=inode;
f->f_count=1; return fd; }

(2)准备好后,向屏幕输出
- inode->i_zone[0]获取设备号,crw_table是字符设备接口,从中找到tty
- tty_write是输出的核心函数,往write_q缓冲区队列中写
- tty->write,在tty_struct中,从缓冲区队列中往屏幕上写,内部用到mov ax, pos,往显存中写字符
- 统一编址用pos,独立编制用out
- 写设备驱动,就是包装out,编写驱动函数并注册到tty_struct中
27 键盘
- 从键盘中断开始,从0x60端口读扫描码,调用key_table
- key_table:函数表,包含do_self等
- do_self专门用于处理可显示字符,从key_map中获取arscii码
- 将arscii码放入read_q缓冲队列中,供程序使用
28 生磁盘的使用
28.1 磁盘的基本知识
-
扇区(基本单位)、磁道和柱面
-
IO过程
- 控制器
- 寻道:磁头移动到相应磁道
- 旋转:旋转磁盘到相应扇区
- 传输:磁生电(读缓冲区),电生磁(写缓冲区)
-
要往控制器中写柱面、磁头、扇区和缓存位置(通过out)
28.2 从盘块号读写磁盘(一层抽象)
- 磁盘驱动负责从block计算CHS
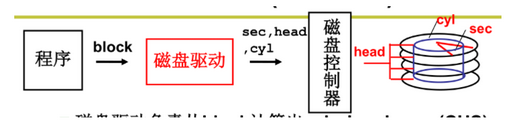
- block编址方式要满足相邻的盘块可以快速读出,即将block相邻的区域放到相邻扇区中
28.3 多个进程通过队列使用磁盘(第二层抽象)
- 磁盘调度的目的是减少寻道时间
- FCFS
- SSTF(最短寻道):存在饥饿问题
- SCAN(SSTF+中途不回折):每个请求都有处理机会
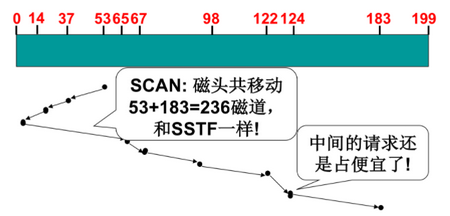
- C-SCAN(电梯算法,真实用的):SCAN+直接移动到另一端,保证两端请求都能很快处理
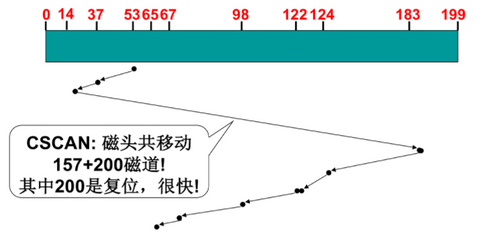
28.4 生磁盘(raw disk)的使用整理
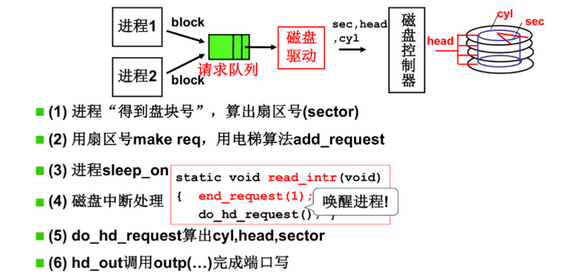
- 读:进程发出请求后睡眠,磁盘将数据准备到缓冲内存,通过中断唤醒进程
- 写:通过out往CHL写
29 从生磁盘到文件
- 第三层抽象,从盘块号到文件
- 用户眼中的文件是字符序列,磁盘上的文件是盘块集合
- 文件的关键是建立字符流到盘块集合的映射关系
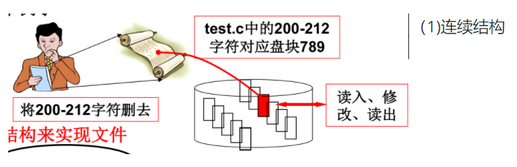
- 连续存放字符
- 映射关系:根据文件名找到FCB,FCB中存放起始块和块数
- 不适合动态增长
(2)链式结构
- 读取慢,增长快
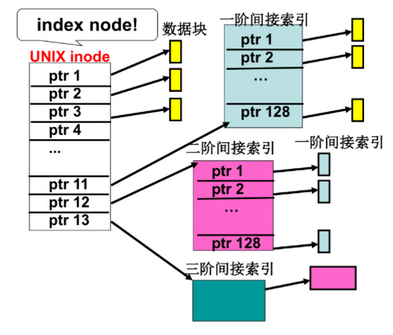
(3)索引结构
- index,linux下FCB为inode
- 找到文件对应的inode,并找到索引块(专门用来存放索引的盘块),从中找到目标字符序列对应的盘块号
- 多级索引(可以表示很大的文件,很小的文件也能高效访问)
30 文件使用磁盘的实现
- 一个盘块占两个扇区
- 本节是磁盘到文件的核心代码实现
(1)sys_write
- 处理字符流中的一段,写到磁盘上
int sys_write(int fd, const char* buf, int count) {
struct file *file = current->filp[fd];
struct m_inode *inode = file->inode;
if(S_ISREG(inode->i_mode))
return file_write(inode, file, buf, count);
}
- file中放字符流的某一段(如200-212),从file中取出200,从count获得个数12,根据inode得到盘块号,对buf进行读写
- file中有一个读写指针file->f_pos,顺序后移,fseek就是修改它的
(2)file_write

(3)m_inode
- inode是文件抽象,形成统一文件视图
- 数据文件的inode用来映射盘块
- 设备文件的inode存放主从设备号信息
- i_mode是文件类型
- i_zone是映射关系或者主从设备号
- 根据文件名找到inode
(4)文件视图
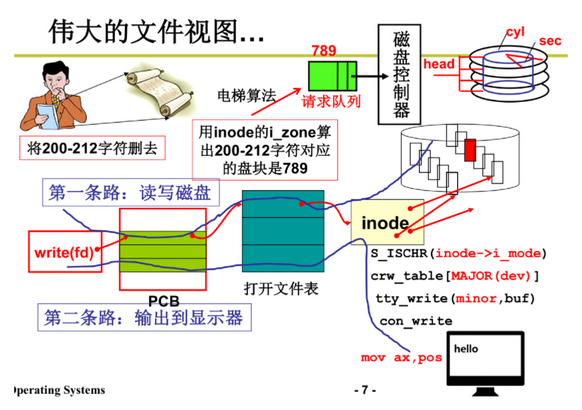
- 路1:根据inode找到盘块号
- 路2:根据inode找到一堆函数,包装了out
- 在用户看来都是字符流
(5)实践项目—实现proc文件
- S_ISPROC
- proc_read,按照file->f_pos和count将task_struct内容拷贝到buf中,形成字符流
31 目录与文件系统
- 磁盘的最后一层抽象,整个磁盘变成一颗目录树
- 文件,抽象为一个磁盘块集合;文件系统,抽象整个磁盘
(1)目录树
- 引入目录树,表示清晰
- 关键是根据树状结构产生的路径名,找到对应文件的inode
(2)树状目录的完整实现
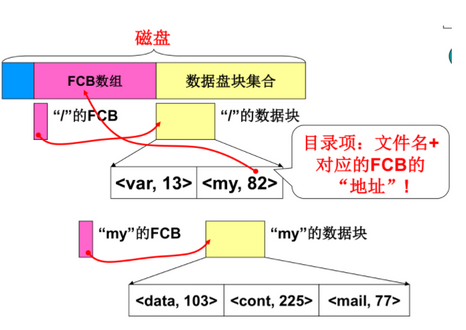
- FCB和对应的数据盘块是在磁盘上的
- 目录项包含FCB的编号和字符串,通过字符串匹配编号,通过编号找到FCB位置
- 根目录FCB编号固定为0,根据根目录的izone索引项找到数据块,文件里面保存目录项
(3)文件系统自举
- 磁盘需要按特定形式格式化
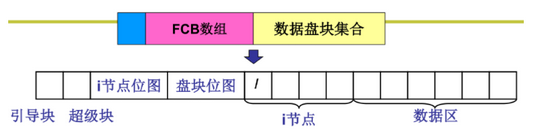
- 盘块位图:表明盘块空闲情况
- i节点位图:创建/删除了哪些inode
- 引导块:引导扇区
- 超级块:各个部分位置信息,mount就是读超级块,挂载到根目录位置
(5)全部映射下磁盘的使用
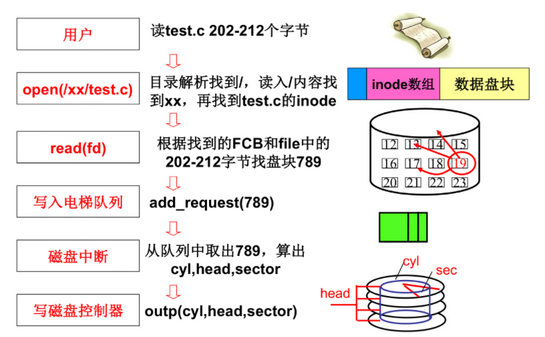
32 目录解析代码实现
(1)open
- 关键是弄懂sys_open
- open的作用是按照文件名,在PCB中通过一个指针数组指向对应inode,fd就是数组下标,形成一个链,write是利用链
- 核心是解析路径
(2)get_dir

(3)根目录
inode=current->root;
//shell进程初始化时指向了根目录的inode,其他进程fork出来
void mount_root(void)//在fs/super.c中
{
mi=iget(ROOT_DEV,ROOT_INO)); //#define ROOT_INO 1
current->root = mi;
}
(4)iget
- 从inode编号找到inode位置
(5)find_entry
- 从inode->i_zone中取出盘块号,读数据,获得目录项,匹配字符串后返回inode编号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号