


机器学习--PCA与SVD
一、主成分分析(PCA)
主成分分析中,首先对给定数据进行规范化,使得数据每一变量的平均值为0,方差为1。之后对数据进行正交变换,原来由线性相关变量表示的数据,通过正交变换变成由若干个线性无关的新变量表示的数据。新变量是可能的正交变换中变量的方差的和(所需要保存的信息量)最大的,方差表示在新变量上信息的大小。将新变量依次称为第一主成分、第二主成分等。
1.1 基本定义
假设$x = (x_{1},x_{2},...,x_{m})^T$是$m$维随机变量,其均值为$\mu$
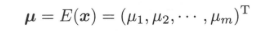 协方差矩阵为$\sum$
协方差矩阵为$\sum$
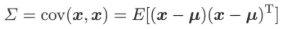 考虑由$m$维随机变量$x$到m维随机变量$y = (y_{1},y_{2},...y_{m})^T$的线性变换:
考虑由$m$维随机变量$x$到m维随机变量$y = (y_{1},y_{2},...y_{m})^T$的线性变换:
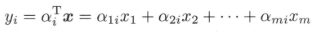 其中$a_{i}^T = (a_{1i},a_{2i},...,a_{mi}), i = 1,2,...,m$。由随机变量的性质可知:
其中$a_{i}^T = (a_{1i},a_{2i},...,a_{mi}), i = 1,2,...,m$。由随机变量的性质可知:
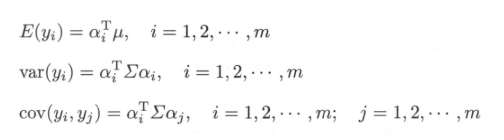 给定一组随机变量$y = (y_{1},y_{2},...y_{m})^T$,如果它们满足以下三个条件:
给定一组随机变量$y = (y_{1},y_{2},...y_{m})^T$,如果它们满足以下三个条件:
- 系数向量$a_{i}^T$是单位向量,即$a_{i}^{T}a_{i} = 1, i = 1,2,...,m$;
- 变量$y_{i}$与变量$y_{j}$互不相关,既$cov(y_{i},y_{j}) = 0 (i \neq j)$;
- 变量$y_{1}$是$x$的所有线性变换中方差最大的;$y_{2}$是与$y_{1}$不相关的$x$的所有线性变换中方差最大的;一般地,$y_{i}$是与$y_{1},y_{2},...,y_{i-1}$都不相关的$x$的所有线性变换中方差最大的;
这时分别称$y_{1},y_{2},...,y_{m}$为$x$的第一主成分、第二主成分、...第$m$主成分。
1.2 主要性质以及证明
假设$x$是$m$维随机变量,$\sum$是$x$的协方差矩阵,$\sum$的特征值分别是$\lambda_{1} \geq \lambda_{2} \geq ... \geq \lambda_{m} \ geq 0$,特征值对应的单位特征向量分别是$a_{1},a_{2},...a_{m}$,则$x$的第$k$个主成分为:
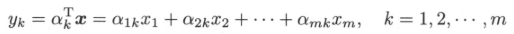
$x$的第$k$个主成分的方差为:
即协方差矩阵$\sum$的第$k$个特征值。下面用拉格朗日乘子法给出证明:
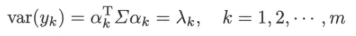 首先求$x$的第一主成分$y_{1} = a_{1}^{T}x$,既求系数向量$a_{1}$。由于系数向量是单位特征向量,则第一主成分的$a_{1}$是在$a_{1}^{T}a_{1}$条件下,$x$的所有线性变换方差$var(a_{1}^{T}x) = a_{1}^{T} \sum a_{1} $达到最大。那么求解第一主成分就是求解约束最优化问题:
首先求$x$的第一主成分$y_{1} = a_{1}^{T}x$,既求系数向量$a_{1}$。由于系数向量是单位特征向量,则第一主成分的$a_{1}$是在$a_{1}^{T}a_{1}$条件下,$x$的所有线性变换方差$var(a_{1}^{T}x) = a_{1}^{T} \sum a_{1} $达到最大。那么求解第一主成分就是求解约束最优化问题:
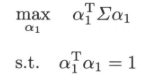 定义拉格朗日函数:
定义拉格朗日函数:
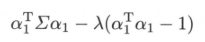
其中$\lambda$是拉格朗日乘子。将拉格朗日函数对$a_{1}$求导,并令其为0,得:
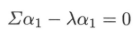
因此,$\lambda$是$\sum$的特征值,$a_{1}$是对应的单位特征向量。于是,目标函数:

假设$a_{1}$是$\sum$的最大特征值$\lambda_{1}$对应的特征向量,显然$a_{1}$与$\lambda_{1}$是最优化问题的解。接下来求解$x$的第二主成分,第二主成分除了要保证自己是单位特征向量之外,还需要与$y_{1}$线性无关,求解$x$的第二主成分等价于如下约束最优化问题:
 注意到:
注意到:
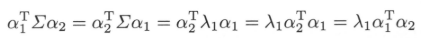 以及:
以及:
 定义拉格朗日函数:
定义拉格朗日函数:
 其中$\lambda,\phi$是拉格朗日乘子。对$a_{2}$求导,并令其为0,得:
其中$\lambda,\phi$是拉格朗日乘子。对$a_{2}$求导,并令其为0,得:
 将方差左乘$a_{1}^{T}$有:
将方差左乘$a_{1}^{T}$有:
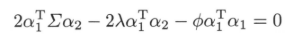 此式前两项为0,且$a_{1}^{T}a_{1} = 1$,导出$\phi = 0$,因此有:
此式前两项为0,且$a_{1}^{T}a_{1} = 1$,导出$\phi = 0$,因此有:
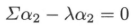
由此可知$a_{2},\lambda_{2}$是以上问题的最优解。按照上述方法可依次证明第$k$个主成分由协方差矩阵$\sum$的特征向量构成,证毕。
1.3 主成分分析求解过程
假设对$m$维随机变量$x = (x_{1},x_{2},...,x_{m})^T$进行$n$次独立观测,$x_{1},x_{2},...,x_{n}$表示观测样本,其中$x_{j} = (x_{1j},x_{2j},...,x_{jm})^T$表示第$j$个样本,$x_{ij}$表示第$j$个观测样本的第$i$个变量,$j = 1,2,..,n$。观测数据样本用样本矩阵$X$表示,极作:
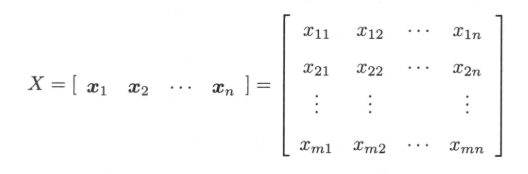
给定样本矩阵$X$,可以估计出均值以及样本方差。样本均值向量$\bar{x}$为:
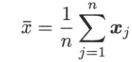 样本协方差矩阵为:
样本协方差矩阵为:
 其中$\bar{x}_{i}$表示第$i$个变量的均值。样本的相关矩阵$R$为:
其中$\bar{x}_{i}$表示第$i$个变量的均值。样本的相关矩阵$R$为:
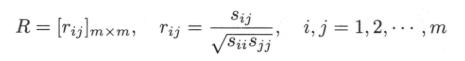 在实际使用$PCA$的时候,一般假设样本是规范化的,即对样本矩阵作如下变换:
在实际使用$PCA$的时候,一般假设样本是规范化的,即对样本矩阵作如下变换:
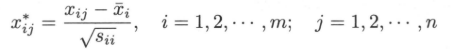 其中:
其中:
 为了方便描述,把规范化之后的样本矩阵记作$X$。这时样本方差矩阵$S$就是样本相关矩阵$R$:
为了方便描述,把规范化之后的样本矩阵记作$X$。这时样本方差矩阵$S$就是样本相关矩阵$R$:
![]() 样本协方差矩阵$S$是总体协方差矩阵$\sum$的无偏估计,样本相关矩阵R是总体相关矩阵的无偏估计。$S$的特征值和特征向量是$\sum$的特征值和特征向量的极大似然估计。接下来介绍求解$R$的$k$个特征值和对应的$k$个单位特征向量的方法(即使用奇异值分解的方式求解PCA)。
样本协方差矩阵$S$是总体协方差矩阵$\sum$的无偏估计,样本相关矩阵R是总体相关矩阵的无偏估计。$S$的特征值和特征向量是$\sum$的特征值和特征向量的极大似然估计。接下来介绍求解$R$的$k$个特征值和对应的$k$个单位特征向量的方法(即使用奇异值分解的方式求解PCA)。
对于$m x n$实矩阵,假设其秩为$r$,$0 < k < r$,则可以将矩阵$A$进行阶段奇异值分解:
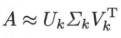
上式中$U_{k}$为$m x k$矩阵,$V_{k}$是$n x k$矩阵,$\sum_{k}$是$k$阶对角矩阵;$U_{k}$,$V_{k}$分别取自$A$的完全奇异值分解的矩阵$U$,$V$的前$k$列,$\sum_{k}$为$A$的完全奇异值分解的矩阵$\sum$的前$k$个对角线元素得到。定义一个新的$n x m$矩阵$X^{’}$:
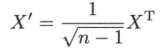 $X^{’}$的每一列均值为零。不难得知:
$X^{’}$的每一列均值为零。不难得知:
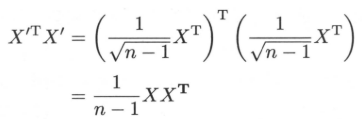 即$X^{'T}X^{'}$等于$X$的协方差矩阵$S_{X}$。
即$X^{'T}X^{'}$等于$X$的协方差矩阵$S_{X}$。
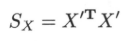 所以问题转化为求矩阵$X^{'T}X^{'}$的特征值以及对应的单位特征向量。假设$X^{'}$的截断奇异值分解为$X^{'} = U{\sum}V^{T}$,那么$V$的列向量就是$S_{X} = X^{'T}X^{'}$的单位特征向量。因此,$V$的列向量就是$X$的主成分。于是,求$X$主成分可以通过求$X^{'}$的奇异值分解来实现。算法流程如下:
所以问题转化为求矩阵$X^{'T}X^{'}$的特征值以及对应的单位特征向量。假设$X^{'}$的截断奇异值分解为$X^{'} = U{\sum}V^{T}$,那么$V$的列向量就是$S_{X} = X^{'T}X^{'}$的单位特征向量。因此,$V$的列向量就是$X$的主成分。于是,求$X$主成分可以通过求$X^{'}$的奇异值分解来实现。算法流程如下:

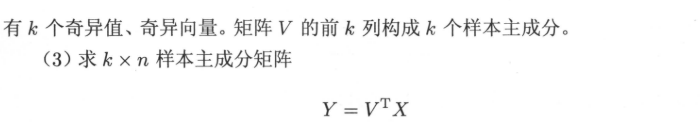
二、SVD(待整理)

