数据挖掘--模型融合
理论来说,如果不同的模型在评分上类似但是结果上差异较大,那么这些不同的模型融合效果会比较理想.
内容简介
1. 简单加权融合:
- 回归(分类概率):算术平均融合,集合平均融合(权重的差异不宜过大)
- 分类:投票(Voting)
- 综合: 综合排序(Rank averaging),log融合 (分线性)
2. stacking/blending
- 构建多层模型,并利用预测结果再拟合预测
3. boosting/bagging(xgboost,Adaboost,GBDT已经用到)
- 多树的提升方法
Stacking
简单来说stacking是使用初始训练集数据学习出若干个基学习器之后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。
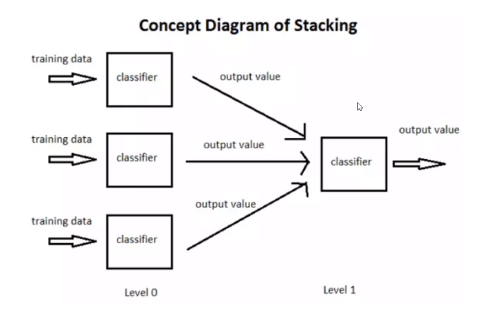
Stacking本质上就是这么直接的思路,但是直接这样有时对于如果训练集和测试集分布不那么一致的情况下是有一点问题的,其问题在于用初始模型训练的标签再利用真实标签进行再训练,毫无疑问会导致一定的模型过拟合训练集,这样或许模型在测试集上的泛化能力或者说效果会有一定的下降,因此现在的问题变成了如何降低再训练的过拟合性,这里我们一般有两种方法。
次级模型尽量选择简单的线性模型
- 利用K折交叉验证
- 次级分类器尽量选用简单的分类器
训练:

预测:

经验总结
比赛的融合这个问题,个人的看法来说其实涉及多个层面,也是提分和提升模型鲁棒性的一种重要方法:
-
结果层面的融合,这种是最常见的融合方法,其可行的融合方法也有很多,比如根据结果的得分进行加权融合,还可以做Log,exp处理等。在做结果融合的时候,有一个很重要的条件是模型结果的得分要比较近似,然后结果的差异要比较大,这样的结果融合往往有比较好的效果提升。
-
特征层面的融合,这个层面其实感觉不叫融合,准确说可以叫分割,很多时候如果我们用同种模型训练,可以把特征进行切分给不同的模型,然后在后面进行模型或者结果融合有时也能产生比较好的效果。
-
模型层面的融合,模型层面的融合可能就涉及模型的堆叠和设计,比如加Staking层,部分模型的结果作为特征输入等,这些就需要多实验和思考了,基于模型层面的融合最好不同模型类型要有一定的差异,用同种模型不同的参数的收益一般是比较小的。
# 记得看一下预测结果的统计信息,根据实际的情况做一些结果的后处理