


论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333)
传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平凡的信息恰恰是深度学习所具备的特点.论文对基于深度的学习的推荐系统方法进行了对比以及分类.文章的主要贡献有以下三点:
> 对基于深度学习技术的推荐模型进行系统评价,并提出一种分类和组织当前工作的分类方案.
> 提供现有技术的概述和总结
> 我们讨论挑战和开放性问题,并确定本研究中的新趋势和未来方向,以分享愿景并拓展基于深度学习的推荐系统研究的视野。
OVERVIEW OF RECOMMENDER SYSTEMS AND DEEP LEARNING
推荐系统算法:协同过滤算法,基于内容的推荐系统以及混合推荐系统(混合推荐系统是指整合两种或者多种推荐策略的推荐系统).前面的笔记都有大致的描述,这里就不展开.
>深度学习:旨在获取深层次,愈加抽象的数据表示.和文章有关一些深度学习方法如下:
(1) Multilayer Perceptron(MLP) 多个隐层的前匮神经网络,感知器可以用任意的激活函数,MLP可以被表示为非线性变换的堆叠层,用来学习层次化的特征.
(2) Autoencoder(AE) Autoencoder 一种无监督模型,用于在输出层重构输入数据.一般而言bottlenect layer(最中间的网络层也叫做瓶颈层)用来表示输入数据的显著性表示.(后续看情况要不要补充学习一下稀疏自编码器和变分自编码器)
(3) Convolutional Neural Network(CNN) 卷积神经网络是一种特殊的前馈神经网络.包含了池化以及卷积操作.能获取输入数据的局部以及全局特征并且可以显著性的提高准确率以及效率. (看情况去补补基础的,之间看的大概都忘记了)
(4) Restricted Boltzmann Machine (RBM) 受限波尔兹曼机是一个由可见层和隐藏层组成的双层神经网络。 它可以很容易地堆叠到深网。 此处受限制意味着可见层或隐藏层中没有层内通信。(看情况细化翻花书)
(5) Neural Autoregressive Distribution Estimation (NADE) 神经自回归密度估计器是一个在自回归模型和前馈神经网络之上构建的无监督神经网络。 它是用于建模数据分布和密度的易处理且有效的估计器。(和(4)一样)
(6) Adversarial Networks(AN) 对抗网络是一个生成神经网络,由判别器和生成器组成。 通过在极小极大游戏框架中相互竞争,同时训练两个神经网络.(GANS)
(7) Attentional Models (AM) 注意力机制是基于输入序列(或图像)上的内容寻址操作的可靠的神经架构。 注意力机制通常无处不在,并在计算机视觉和自然语言处理领域被接受。 然而,它也是深度推荐系统研究的新兴趋势。(nlp中的self-attention)
(8) Deep Reinforcement Learning (DRL) 强化学习是在一种反复试验的范例下运作的。 整个框架主要由以下组件组成:代理,环境,状态,动作和奖励。 深度神经网络和强化学习之间的结合形成了DRL,它在游戏和自动驾驶汽车等多个领域实现了人性化的表现。 深度神经网络使代理能够从原始数据中获取知识并导出高效的表示,而无需手工编写特征.
>深度学习为什么能够应用于推荐系统:
(1) 深度学习端到端的稳定性(不是很明白)
(2) 提供适合的对输入数据归纳偏差的方法,也就是说如果数据本身具有内部结构的话,深度学习相关的技术能够较好的发掘其内部的结构.例如RNN和CNN长期的利用图像以及人类语言内在的结构来达到预期的效果.类似地,会话或点击日志的顺序结构非常适合于循环/卷积模型提供的归纳偏差.
(3) 深度学习的可组合性以及稳定的端到端学习方式比较使用与基于内容的推荐系统例如,为了处理评论,人们将不得不执行昂贵的预处理(例如,关键短语提取,主题建模等),而新的基于深度学习的方法能够端到端地摄取所有文本信息.
(4) 在之考虑item-user交互的情况下,也就是最基础的协同过滤过程,user-item相似矩阵在之前的传统推荐系统算法中是用机器学习的方法训练出来,然而当交互过于复杂的时候,传统的方法并不能较好的表示,抽象复杂的数据是深度学习的强项.
>基于深度学习的推荐模型优势:
(1) 非线性表示 传统的MF算法都是建立在线性模型的基础之上的,使用线性模型会限制模型的表达能力.而深度学习的激活函数例如sigmoid,relu,tanh都是非线性表示.非线性的表示能扩大模型的可表示空间,进而获取效果很好的模型.
(2) 表示学习 深度学习方法能够有效的从输入数据中学习潜在的解释因素以及有用的表示形式.在基于内容的推荐算法中,深度学习这个特性能够避免繁琐的特征工程以及其能使推荐模型包括异构信息,比如文本,视频以及图像数据并存的数据集合.深度学习具备从各种来源学习的表现形式的潜力.
(3) 序列模型 CNN以及RNN在NLP,语音识别领域有着重大的突破,他们在处理时间序列上有着很不错的成效.对顺序信号建模是挖掘用户行为和物品演变的时间动态的重要主题,深度学习在时间序列模型处理上的优势能够在推荐系统解决时效问题上得到充分发挥.
(4) 灵活性 深度学习的一些热门框架都是基于模块化的开发模式.基于模块化的开发模式能够是工程的构建快速且有效.
>潜在的局限性
(1) 可解释性 深度学习的表示为黑盒子,提供可解释性是深度学习(2017年)存在的问题(现在2019了不知道啥情况,后面有空去看看).目前(2017)而言,解释单个神经元还是一个问题,但是整体上的可解释性得到了软性的解决.基于深度学习的推荐方法在某种程度上不受影响
(2) 数据要求 深度学习需要大量的数据来学习其丰富的参数以及深层次的特征.RS不太需要考虑这一点,或许大量的数据不是难事.
(3) 大量的超参数调整问题
DEEP LEARNING BASED RECOMMENDATION: STATE-OF-THE-ART
>基于深度学习方法的推荐系统分类
(1) 基于神经结构的推荐系统 划分为八个子类别,分别为MLP, AE, CNNs, RNNs, RBM, NADE, AM, AN and DRL 为基础的推荐系统算法.这一类的推荐系统算法使用的深度学习方法都含有神经网络结构.
(2) 基于混合模型的推荐系统 指使用多个深度学习技术的推荐系统方法
分类的图示如下:

MLP推荐算法
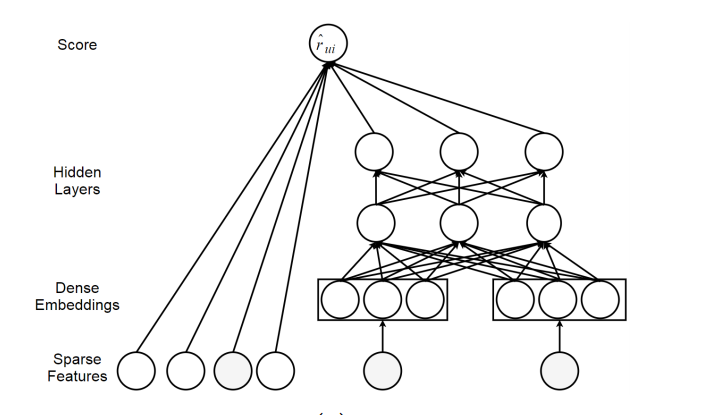
主要为推荐算法提供非线性表达.核心思想为使用神经网络来计算用户以及物品之间的交互行为(相似度).Neural Network Matrix Factorization (NNMF)以及Neural Collaborative Filtering (NCF)是该思想具有代表性的方法.NCF的网络结构图如下所示:

评分预测的函数如下所示:
![]()
其中$s_{u}^{user}$以及$s_{i}^{item}$表示辅助信息,例如标签信息.f()表示MLP,$\theta$为网络训练的参数.在训练的时候可以使用交叉熵损失作为loss function.负采样方法能够减少未被观测实例的数量.
DeepFM(Deep Factorization Machine).FM的详细介绍见https://blog.csdn.net/asd136912/article/details/78318563,核心思想是其分解的时候采取了交叉项的形式.DeepFM的网络结构收到wide&deep模型的启发而来.wide指广义的线性模型,deep指的是深度神经网络.DeepFM使用MLP获取高阶的交互信息,使用FM获取低阶的交互信息.相较于原始的wide&deep模型,DeepFM不需要繁琐的特征工程(也是深度学习的特性).DeepFM网络概念图如下所示:
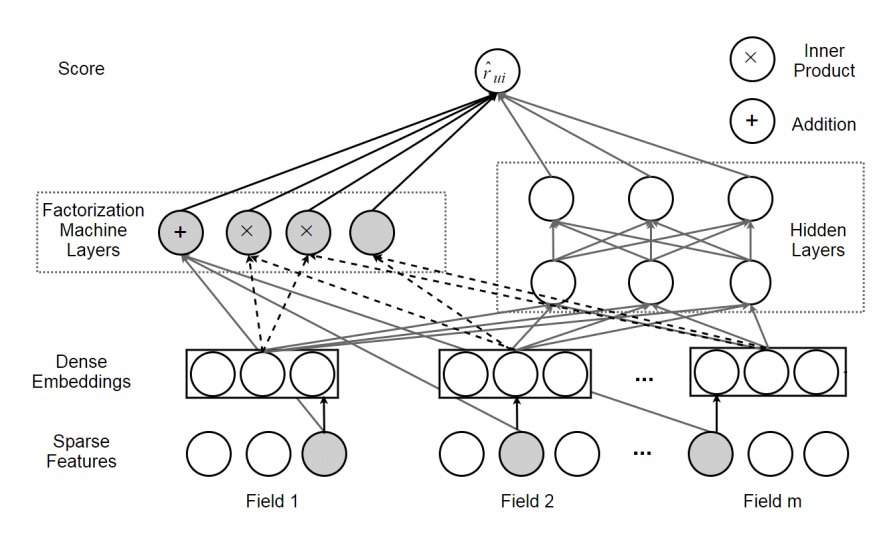
FM Layer是的是wide compent,对应的Hidden Layyers是指MLP,最后的结果$\hat{r_{ui}} = \sigma(Y_{Fm}(x) +Y_{MLP}(x)) $,$\sigma()$是sigmod函数
>Feature Representation Learning with MLP
Wide&Deep learning.是一个生成模型.Wide learning对应单层的感知机,通过获取直接的历史信息来获取"memorization";Deep learning对应的是多层感知机,通过抽象以及深层次的特征表示来获取"generalization".部署这个模型需要进行特征工程,选择好的特征来获取其"memorization"以及"generalization"结构如下所示:
>Recommendation with Deep Structured Semantic Model
Deep Semantic Similarity based Personalized Recommendation (DSPR).其中物品和用户用标签表示,用cosine函数sim(u,i)来表示用户u以及物品i相似度,loss函数如下: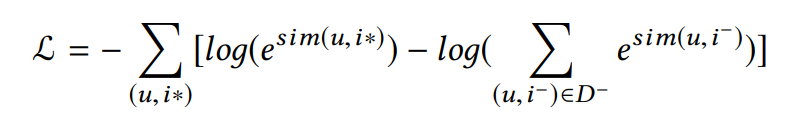
其中$(u,i^-)$指的是副样本.
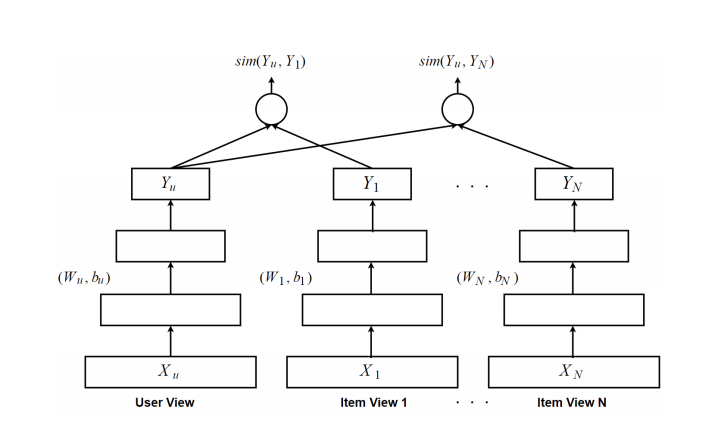
Multi-View Deep Neural Network (MV-DNN)用于交叉领域的推荐.其将用户的视角作为主视图,item作为辅助视图,loss函数如下所示:

其中$Y_u$对应的用户视角的输出,a对应视角的index,$R^{da}$是之输入域对应的视角集合.网络结构如下所示:
基于自编码器的推荐系统
主要策略:(1) 使用自编码器来学习数据低维的特征(在瓶颈层是数据的显著性表示) (2) 在重构层直接填补交互矩阵.
> Autoencoder based Collaborative Filtering.
主要介绍基于物品item-based AutoRec.给定输入$r^{(i)}$,重构之后的结构为:$h(r^{(i)},\theta) = f(W*g(V*r^i+\mu)+b)$g(.)以及f(.)为激活函数.I-AutoRec对应的目标函数为:
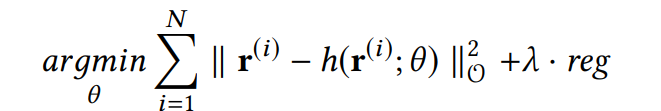
![]() 指的是只考虑观测值,I-AutoRec有值得关注的以下几点:
指的是只考虑观测值,I-AutoRec有值得关注的以下几点:
> I-AutoRec 表现比U-AutoRec好
> f(.)以及g(.)的选择对表现有比较明显的影响
> 适当的提高hidden layers unit的个数有助于获得更好的表现
>Adding more layers to formulate a deep network can lead to slightly improvement.
CFN是AutoRec的一个扩展,它有两个特点.(1) 部署了去噪技术,提高了系统的鲁棒性. (2)它结合了诸如用户专业和项目描述之类的辅助信息,以减轻数据稀疏性问题以及缓解冷启动问题.
CDAE特别用来排名预测(降噪自编码器看情况补一下,要去看看源码实现的一个过程).CDAE的输入一般是用户的隐性反馈,且一般用高斯噪声做一个修正.重构函数如下所示:
![]()
$\hat{r_{pref}^{(u)}}$指的是高斯噪声,对应的损失函数如下:

Muli-VAE and Multi-DAE 是基于变分自编码器的推荐系统,表现比CDAE要好一些.(变分自编码留个坑)
>Feature Representation Learning with Autoencoder.
Collaborative Deep Learning (CDL) CDL将perception component (deep neural network 例如SDAE,堆叠的降噪自编码器) and task-specific componet(PMF概率矩阵分解)组合在一起构成一个基于贝叶斯的框架,CDL的流程如下所示:
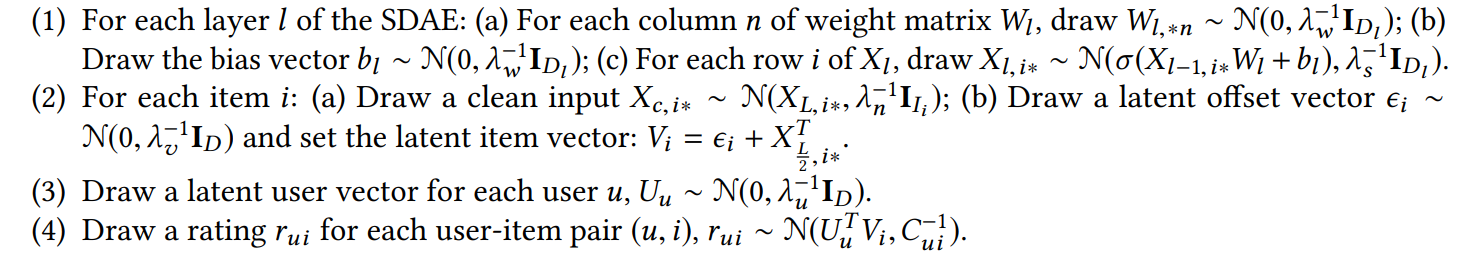
采用EM的方式来学习模型模型的参数,具体的见CDL论文.relational stacked denoising autoencoders (RSDAE)与CDL的不同之处在于RSME替换PMF为一个关系信息矩阵.CVAE把CDL中的DAE变成为VAE.CVAE学习内容信息的概率潜变量,并且可以轻松地合并多媒体(视频,图像)数据源。
Collaborative Deep Ranking (CDR) CDR尤其使用于成为框架的top-n推荐系统.最新的研究表明成对的模型更适合于排名列表的生成.过程和CDL类似,不过CDR第三步以及第四步为:
![]()
CDL以及CDR结构图如下所示(其中$\lambda_{w}$,$\lambda_{s}$,$\lambda_{n}$,$\lambda_{v}$,$\lambda_{u}$都是超参数):

Deep Collaborative Filtering Framework 是一个融合深度学习方法和协同过滤模型的一般框架,有了这个框架,我们就很容易利用深度学习技术来辅助协同推荐。正式地,深度协同过滤框架定义如下:
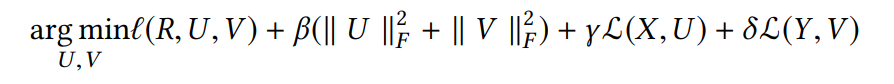
其中$\beta \gamma \delta$是用来均衡其对应三个部分对系统的影响,X,Y对应边的信息,I(.)是协同过滤损失,L(X,U),L(Y,V)用来链接深度学习以及协同过滤模型以及链接边的信息和隐式因子.这个框架的顶部,作者提出了基于协同过滤模型的marginalized denoising autoencoder(mDA-CF)。和CDL相比,mDA-CF是一个autoencoder计算高效的变体。它通过边缘化损坏的输入,以节省了寻找充足的损坏输入版本(searching sufficient corrupted version of input)的代价,这使得mDA-CF比CDL可拓展性更强。另外,mDA-CF嵌入了用户和物品的内容信息,而CDL只考虑物品特征的影响。结构图如下(图来自https://blog.csdn.net/w5688414/article/details/78651363):
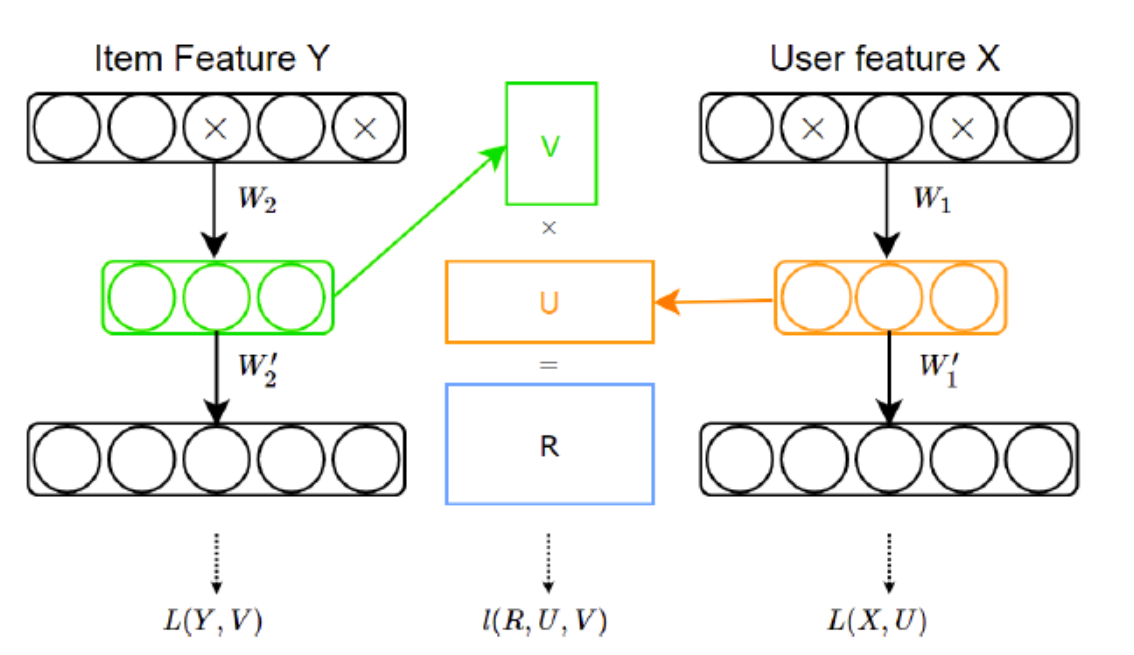
松耦合模型
AutoSVD++利用的是contractive autoencoder去学习物品的特征表示,之后把特征整合到经典的推荐模型,SVD++。提出的模型有如下的优点:(1)和其它autoencoder变体相比,contractive autoencoder能捕获无穷小的输入变化;(2)它对隐式反馈进行建模,以进一步提高精度;(3)有一个高效的训练算法,可以减少训练时间。
HRCD是一个基于autoencoder和timeSVD++的混合协同模型,这是一个时间感知模型,它使用SDAE学习从原始特征中学习物品表示,目的是解决冷启动问题。可是,基于相似度的冷物品的推荐就算代价很高。
Convolutional Neural Networks based Recommendation
Feature Representation Learning with CNNs POIRes利用CNN提取图像的特征(CNN对非结构化的多媒体数据提取特征有着显著的效果).基于CNN的推荐系统通过融合CNN提取的视觉信息以及文本的信息来作为输入信息,结合传统的MF,FM,BPRMF(Bayesian personalized ranking BPR)算法进行个性化推荐. ConTagNet(context-aware tag recommender system),VBPR(visual Bayesian personalized ranking)等都是这类方法的代表作.
CNNs for Text Feature Extraction DeepCoNN用两个并行的CNNs来对用户的行为以及物品的特征建模,通过embedding技术把文本信息映射到低维语义空间并保存其信息.DeepCoNN只有当user-target-item三者关系成立的时候是有效的(可以通过一个增加一个隐层来表示user-target-item关系解决这个问题).ConvMF类似于CDL,CDL使用AE来获得物品的抽象信息,ConvMF使用CNN来获取物品的抽象信息(CNN能够获取更加准确的文本抽象信息).
CNNs for Audio and Video Feature Extraction. 使用CNN提取内容信息的推荐系统能够较好的解决冷启动问题
(未完待续)

