

推荐系统实践笔记(四)
第四章 利用用户标签数据
流行的三个推荐系统联系用户和物品的方式:
(1) item-base itemCF
(2) user-base userCF
(3) feature_base 隐语义模型以及UGC(User Generated Content)模型(用户标签模型)
利用用户标签推荐的简单算法流程:
(1) 统计每个用户最常用的标签。
(2) 对于每个标签,统计被打过这个标签次数最多的物品
(3) 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
针对上述描述,用户u对物品i的兴趣公式为:$p(u,i) = \sum_{b}n_{u,b}n_{b,i}$b为标签集合,$n_{u,b}$表示用户u打过标签b的次数,$n_{b,i}$是物品i被打过标签b的次数
算法改进:
(1) 兴趣计算公式$p(u,i) = \sum_{b}n_{u,b}n_{b,i}$一样存在倾向于对热门标签有很大权重的问题,借助TF-IDF的思想对公式进行改进:![]() 这里$n_{b}^u$记录了标签b被多少个用户标记过.这个算法记为 TagBasedTFIDF 。同理,我们也可以借鉴 TF-IDF 的思想对热门物品进行惩罚,从而得到如下公式:
这里$n_{b}^u$记录了标签b被多少个用户标记过.这个算法记为 TagBasedTFIDF 。同理,我们也可以借鉴 TF-IDF 的思想对热门物品进行惩罚,从而得到如下公式: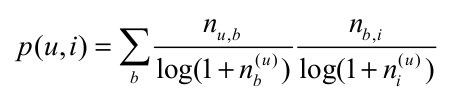
$n_{i}^u$记录了物品i被多少个不用的用户打过标签.
(2) 标签扩展
用户兴趣和物品的联系是通过两者标签集合的交集来计算的,在冷启动问题中,新用户和新物品的标签很少,我们可以为其添加一些已有标签的相似标签.常用的方法有话题模型.
(3) 标签清理
> 去除词频很高的停止词
> 去除因词根不同造成的同义词,比如 recommender system 和 recommendation system ;
> 去除因分隔符造成的同义词,比如 collaborative_filtering 和 collaborative-filtering 。
标签的推荐以及一些实现就略过不记了,要用的时候再深入理解.
