
PA1-总结
前言
代码全是自己写的,没看过参考代码,思路也有部分和指导书不一样,算是个原创?然后毕竟pa1是简单的部分,也没有什么值得骄傲的地方,只是作为一次记录。
毕竟自己的水平还是有限,可能部分地方会有些bug。自己成绩也不太好吧,程序设计不会,计算机系统基础说实话是0,只有在acm训练的经历,然后再代码的能力上有些微薄的储备,但是认识我的那些人都应该会有一个共识:这个人还是挺菜的。
所以也算是对自己过去不够努力的补救,毕竟谁有有些成长和困境,好不容易出来还是要努力补足一下
不算是什么指导书和心得,更多是想作为一个良好的开始,记录一下自己
如果能帮到什么那是最好的了
有好多地方的处理策略都是从简处理的,不完全是指导书上的KISS,也算是半个吧。比如说再判断优先级的时候会有(-5)之类的算式,其中的-不会被认为是负号来处理,
此处有一个心得,算是在过程中瞎搞然后最后发现有出乎意料的作用,首先是KISS原则,然后再很多地方建议不要直接使用assert(0),而是自己写一次panic把此处的判断信息打出来,这样的话如果后面一个合法的式子但是中间断开了,也方便去发现在哪里断开的。
还要在确定bug位置的时候由于acm的习惯,不太会用gdb,依然是使用把过程中的变量全都printf输出出来然后看是不是有什么错误的地方。但是对于这种很长的工程文件来说在找到错误之后修正后需要把一些东西都注释掉或者删除,因为代码很长,会忘记在哪里打过printf,所以建议每一处的debug都要加一个独特的注释,之后用 查找 功能,可以方便的定位到这些位置,防止不需要的时候输出额外的信息
回归负号的处理,这个地方,在输入(-5)的时候,因为我判断负号的优先级使用的如果负号不是第一个位置,并且前面不是括号,不是数字那么就是减号。。。。。。我突然想到。。这个负号和正号的处理有更好的方法。。。。。请看代码
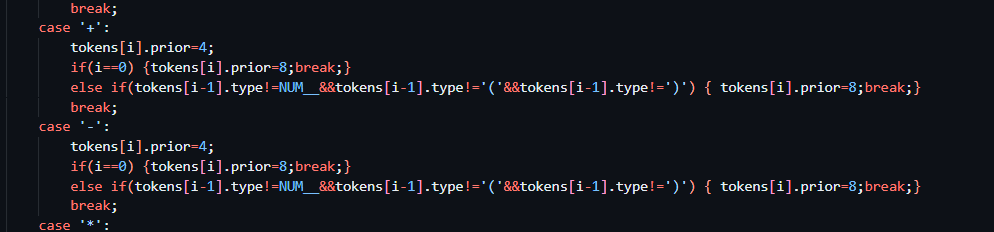
关于这个的解释,如果是正常的运算符+-那么优先级就是4,正负号的优先级是8,但是注意到如果修改成
else if(tokens[i-1].type!=NUM__&&tokens[i-1].type!=')') { tokens[i].prior=8;break;}
就不会把(-5)中的负号误判成减号了,并且这样也确实是完善的地方。。。。。。确实是刚刚想到
好了,这是一个意外,继续说我本来是怎么修改的,我在expr这里有一个panic如下

其实第二个paninc是不会起作用的,那是我最初写的,后来没舍得删除,因为是我的一个过程吧,有些念旧情结。
是的,return0就是我的解决方法,因为在输入(-5)的时候会进到这个地方打出这个panic的信息
让我很快的定位到这里,然后·把优先级用printf打出来之后发现误判了,为什么return 0,相信对代码有充分理解的同学可能会知道为什么会出现 l>r 然后就会知道为什么是return 0 了
详细要看代码细节,只能简单说下:
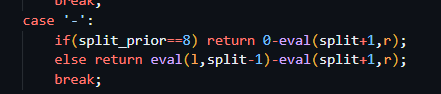
split 是切割点。你说什么是切割点?你肯定没有尝试看过指导书,不然会熟悉的。
如果是正常的加减会进入到这个第二个return,但是第一个eval会出现 l>r 的情况,同时我测试了许多样例,只有这个会进入到里面,然后就索性return 0吧,hhhh,这样结果也就对了
但是其实不太严谨,还是按照刚刚想到的方法才是更为准确的方法。
在这些的记录里面我还会放进去我过程中的许多写的乱起八糟的东西,但是可能会有点用,其实是和日记相类似,
从前自己说过自己写博客更像是一种自恋
所以就随便放进别的文章了,不指望有什么用处
详细的来一次,
我按照一生一芯的思路讲起
也只有代码实现了,框架的理解说实话也就只是一瓶子不满,半瓶子咣当,并且这个部分要写很多字才能说清楚,我可能有时间会开另外一个文件。
第一次运行nemu
第一次输入
make run
c
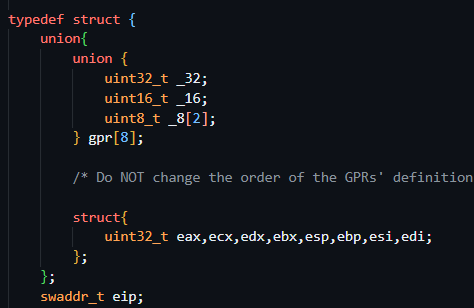
的时候会报错,这是因为寄存器的结构不对
这里就直接贴代码吧
typedef struct {
union{
union {
uint32_t _32;
uint16_t _16;
uint8_t _8[2];
} gpr[8];
/* Do NOT change the order of the GPRs' definitions. */
struct{
uint32_t eax,ecx,edx,ebx,esp,ebp,esi,edi;
};
};
swaddr_t eip;
union {
struct {
uint32_t CF:1;
uint32_t pad0:1;
uint32_t PF:1;
uint32_t pad1:1;
uint32_t AF:1;
uint32_t pad2:1;
uint32_t ZF:1;
uint32_t SF:1;
uint32_t TF:1;
uint32_t IF:1;
uint32_t DF:1;
uint32_t OF:1;
uint32_t IOPL:2;
uint32_t NT:1;
uint32_t pad3:1;
uint16_t pad4;
};
uint32_t val;
} eflags;
} CPU_state;
nemu的实验就是从这一步开始的,说实话我也是抄的,因为ppt里有,老师分析过,能抄为什么不抄(
涉及到联合体这个还比较特殊的结构,自己没有怎么用过这个结构,还是不太熟悉,但是改完代码之后去理解一下,还是能感受到些东西
以下碎碎念:
虽然我是从手册里面的文件路径一路找到这里,把他改了,但是后来真的去分析框架还是觉得挺难的这里,要知道用联合体我感觉只有把main里面验证寄存器结构的部分看懂是如何验证的,然后去想象这些部分的联系,要想到之后如何调用这些变量,这些变量的值从何而来,才能知道要如何修改
可能还是我太菜了
我只能抽象的写下了,因为太长了,自己水平确实各方面都有些差
从这里跳转。你说什么是跳转?学习一下ctags的使用吧,vscode里面也有类似的插件的
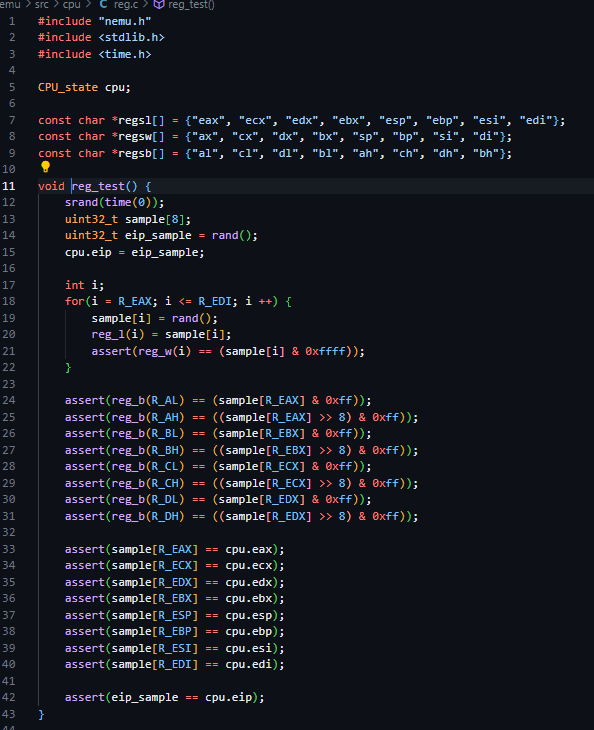
这里就是寄存器结构验证的关键的部分,
首先是3个字符串数组,这一块其实很好用,后面要使用很多次
reg_相关的“函数”实际上只是一些宏,可以自己跳转过去看,起到的作用就是把
cpu.gpr[i].__32还有16 8,这些东西调用出来,听不懂我在说什么?两个原因,一个是我语言表达能力太差,建议换一个博客(主要原因吧,扣咩那赛orz),另一个是你可能并没有去自己亲自看看这个代码,实验最重要的是一边看手册一边看代码,我甚至有换个屏幕的冲动(因为太小了,放不下两个并排的页面)
然后会发现,这一部分其实只有一次赋值,只对了32赋值,然后就要调用其他的各类变量,他们的值从何而来?
代码不是玄学!
联合体的作用就是如此。
你会想,32的值就是寄存器的值了,我从来没有修改过,为什么还要验证?对的,但是原版本的代码这里的32 16 8用的都是结构体,这样的话寄存器就不会有值了,所以才需要验证你的结构,hh
(说实话我也有很多,有疑问的地方,比如eip的验证,没有修改过的值还需要验证么?可能是怕在我们在实现的时候产生的不必要的修改,所以干脆全都验证一次,算是KISS原则吧)
到这里其实感觉差不多了
实现基本功能
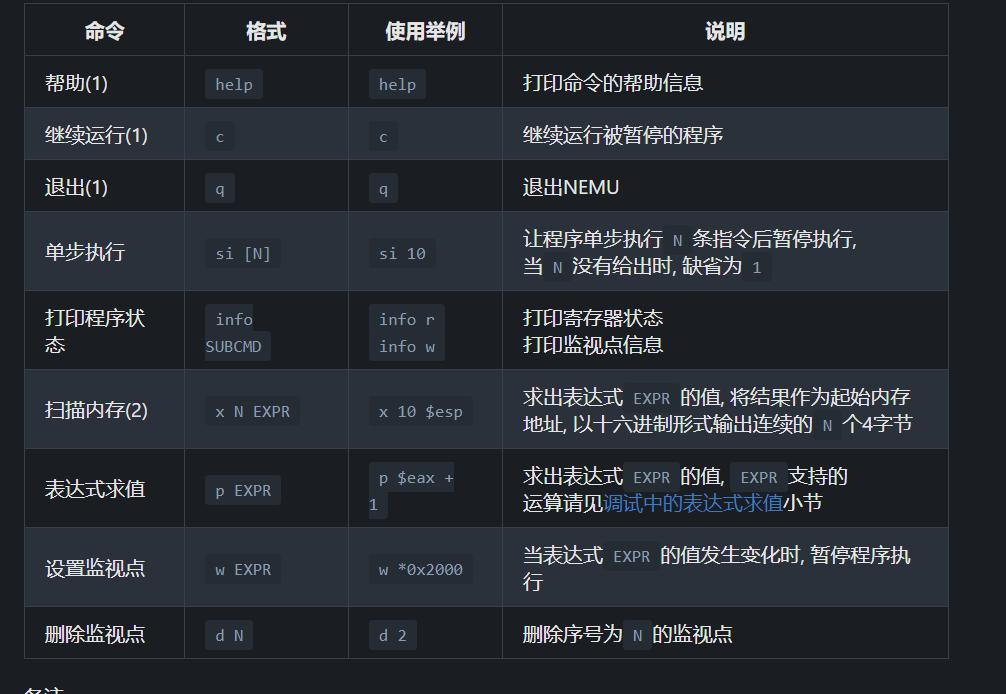
help肯定如果没有特殊的心情的话我猜是都没有使用过 hhhhh
首先想要定位到实现命令的位置应该是这样的过程:
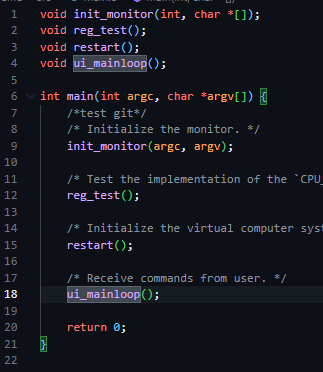
分析结构的时候进入到ui-mainloop
然后看到内部的结构
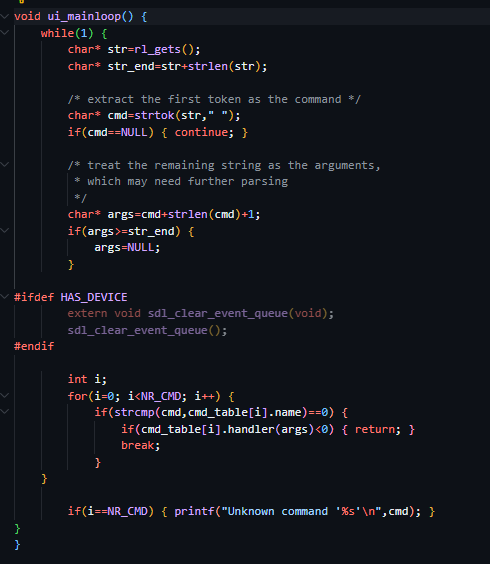
一定有超级多的地方云里雾里(可能也只有我会这样了orz
首先有一些常用的变量名忘记说了,在main里面又2个参数一个是整数argv,一个是字符串argc,他们的意义是接下来要执行的命令的个数,命令是什么。
main函数是怎么把这2个参数提取出来的,,,,,我不会啊(汗颜
但是不重要orz
此处有几个很重要的函数,我使用了很多次gpt,查询了许多函数和命令行的使用,关于这些,我也会单独开一个文章可能,需要的话直接用查找功能找到需要的部分就好了
函数:strtok ,strlen
strtok用来提取字符串的
具体的原理自行查询吧,有什么细节的东西,更重要的是自己亲身去实践,去重新开一个文件,然后使用一下试试就知道了
这里的产生的结果是:
比如我输入一个
info r得到的结果是 cmd 的内容是 info
argc 的内容就是 r
关于那个条件编译我不知道是什么,但是因为是灰色的,可能是也暂时没有用上,之后在看看吧
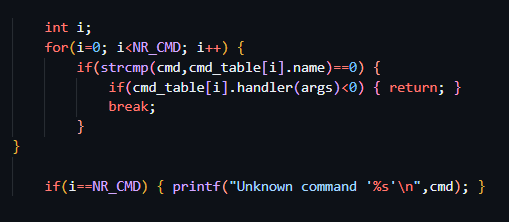
这里是关键的部分
尝试去跳转nr-cmd的含义,会知道它的意义是cmd-table中一共有几个元素,这样的for循环就是要去遍历一遍这个cmd-table
再去看内部内容:
strcmp 的具体使用也是查一下资料吧
从名字上也可以看出是字符串比较,如果相同就会进入
handler这个函数
此处关系到很多东西
要去看一下cmd-table的结构体的内容
其中有一个函数指针,就是handler,关于函数指针也建议去查一下,总之就是相当于调用了那个结构体里面的函数,我也是查了这个类型才知道(orz真的不会啊
然后具体的细节先不看,先看下如果没有判断到的话会怎么样,就是i会成为nr-cmd,这样就是没有找到这个命令,输出unkown
回去看这个结构体
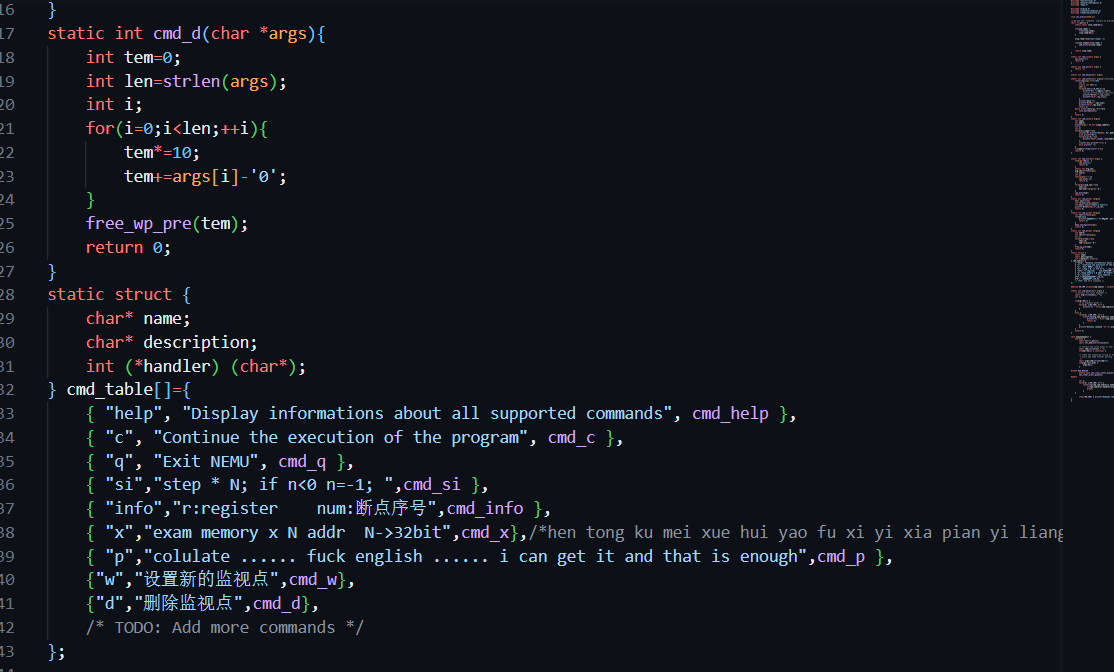
在最初的时候实现一些最基本的内容会感觉到是有些拘束的,但是大概是写p的过程中对于c语言更加熟悉后,动作也会更大,会有更多的发挥的地方
name 就是 info
之后的describe就是对于这个函数的描述。你说这一段字符串为什么没有用呢?试着用一次help吧,看一下help的函数
当你已经分析道这个地方,接下来就是具体的实现了。
c q
先来简单看一下这些已经有了的函数,看看会不会得到什么启发呢,毕竟道目前为止nemu这个系统还是一个谜团重重的代码团,尽管不断的告诫自己 : 代码不是玄学,但是始终会害怕些东西。鄙人真的非常感同身受orz,如果没有这样的感受,看来对于做这样的实验还是有很高的天赋在的。
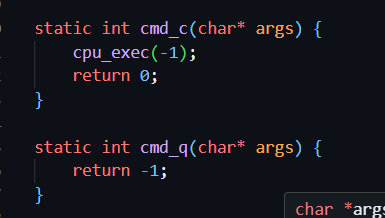
真的是非常简单的函数呢
注意到他们的return是不一样的,起到什么作用呢?

还记得这里么?什么你忘了????只能说我讲述的还是太抽象了orz
这里有一个判断返回值和0的大小关系的地方,如果是小于0的就会直接return回去,这样这个系统就结束了,这个很显而易见就不多解释了
所以q的指令直接返回一个-1,这样就直接退出程序了
并且其他的函数都要返回一个大于等于0的数字,为了一个统一就都返回0吧
仔细看下 c的内部的cpu-exec
传值传了一个-1
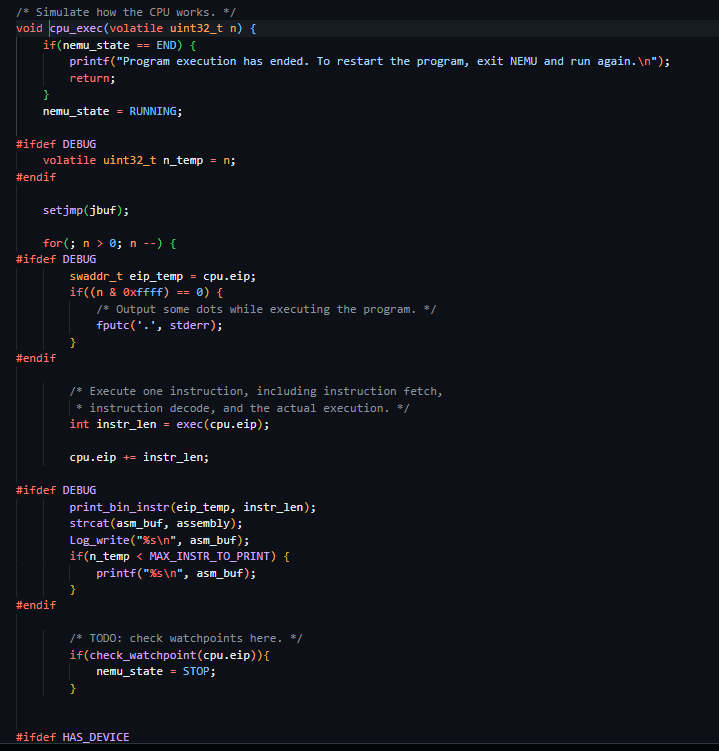
真是。。。。。。。看不懂啊
即便有万千的抱怨和疑惑,但是还是尽可能的看到了这里
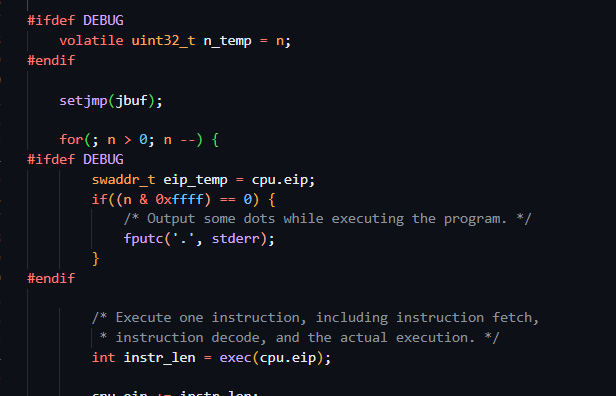
可以有充分的 感觉上的依据 告诉你这个的运行看的就是n,n是多少就会运行几次,(具体是可以分析一下的,但是那样写的就太长了,还有不要陷入代码的细节)
注意到n是一个无符号数,前面的修饰符是什么,我没去看说实话,但是这样就足够分析了
-1在无符号数里面就是最大的数字对吧
c的命令是要求一直运行下去,所以使用一个最大的数字就是能把程序跑完了
si
si在分析完c之后,看过可恶的手册之后,会想到是调用这个cpu-exec来完成的,你要做的就是把传进来的这个argc转换成为一个数字就好了,
这样就是一个简单的程序设计问题了,对我来说还是不会难
以下是代码
static int cmd_si(char* args) {
if(args==NULL) {
cpu_exec(1);
return 0;
}
static int arg_len;
arg_len=strlen(args);
int num=0;
int i;
if(*(args)=='-'){
cpu_exec(-1);
return 0;
}
for(i=0;i<arg_len;++i){
num*=10;
num=num+*(args+i)-'0';
}
cpu_exec(num);
return 0;
}
我采取的是如果输入是一个负数,不管是多少就直接按照-1跑,主要懒得写了
采用的思路就是顺着整个字符串从 0-len 跑下去,然后把一路上的数字都提取出来,其实没有什么好讲的,就是最朴素的思路了
info r
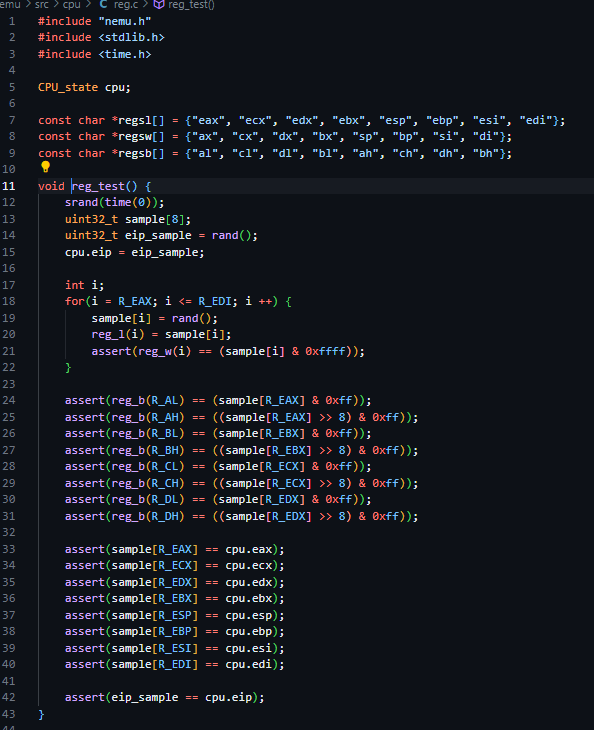
是否还记得我说过这个上面的三个数组会用很多很多次,并且是很好用的东西
并且它们是顺序是一样的
这样的话会很方便调用了,还是要有写过写程序设计题才会感受到这样的用法
直接看代码吧,不太好讲其实,算是写的很多了,然后条件反射就能想到的东西
static int cmd_info(char* args){//finished_correct?
if(strcmp(args,"r")==0){
int i;
static int cnt=-1;
cnt=-1;
for(i=R_EAX;i<=R_EDI;i++){
printf("$%s ",regsl[++cnt]);
//print_little_endian(reg_l(i));
printf("0x%08x ",reg_l(i));
printf("%d\n",reg_l(i));
}
printf("$eip ");
printf("0x%08x ",cpu.eip);
printf("%d\n",cpu.eip);
return 0;
}else if(strcmp(args,"w")==0){
info_watchpoint();
}
return 0;
}
只要看匹配 r 的部分就好了,如果已经有好好理解过了,应该也会知道 w 是另外的功能了,暂且还用不到
对的,这些东西都是要自己写的,你有充分的发挥的空间!
不要照抄啊!抄我这种水平的人的代码的你还是需要好好反思一下有没有再好好学习啊(orz
扫描内存
这一段的代码其实真的我花了很长时间,因为看不懂
nemu自己的访问内存的函数
真的看不懂
如果你也看不懂,还是没必要继续研究下去了,还有更多的事情做,先不要在这里浪费时间了,将来会有必要再回去看的
所以我直接说是怎么用的吧
swadder_read如果你一路跳转会发现非常多的宏
这个函数的2个参数的意思就是
第一个代表着你要访问的地址,第二个参数是你要访问的这个数据类型的大小
比如 int 4个字节 char 1个字节
在nemu中提供的是1个字节,2个字节,和4个字节的数据,2个字节的我还不知道是怎么用的,可能是_16的寄存器或者 _16的类型?但是这里不重要
所以你想要得到这个地址的数据,就直接是传参数是 : 地址,4
就可以了
所以就很简单了思路,要做的就只有去重新计算一下接下来要求的地址的位置,然后调整一下输出格式就好了,以下是代码,
即便是很简单的代码也不要抄啊,我的本心是想能尽可能有一些指导上的帮助,如果不去理解就直接抄,如果提供了这样的帮助,我真的会很愧疚的 orz,呜呜呜呜呜呜
static int cmd_x(char* args){
int capa;
int addre;
sscanf(args," %d %x",&capa,&addre);
int i;
int j;
for(i=0;i<capa;++i){
if(i%4==0) printf("0x%02x: 0x",addre+i*4);
else printf("0x");
for(j=3;j>=0;--j){
printf("%02x",swaddr_read(addre+i*4+j,1));
}
if(i%4==3){ printf("\n"); }
else printf(" ");
}
if(capa%4!=3){printf("\n");}
return 0;
}
此处涉及到一个格式是输出问题:你在输出16进制的时候需要补位,对于没有用过c(比如我)就不会用这个函数
举例子来说明吧:%08x 知道的%x是直接输出一个16进制,08就表示我要输出8位,输不完的地方会填充0,这个其实会用很多次,也没有什么复杂的,我就直接说吧,但是要学习这个函数还是要自己去查资料的
其实如果真心想获得些提示,后面的功能拓展我就不会再贴这里ui里面的代码了,只会贴具体的实现了
然后这样就是最基本的部分已经完成了,记得在cmd-table把加入的命令补充上
计算器
这里真的是大头啊,真的不好写。。。
有时间再来梳理,可以直接去看我在前言中提及的碎碎念,里面可能会有点思路上的东西?记不清了,还是最好换一篇博客看看吧
以下是函数的实现,怎么调用的我才不告诉你,哼哼orz
关于前言里面的提及的优化的思路,我还没改,这里是原始代码,或许可以尝试改改,我就不在这里做了(
int expr(char *e, bool *success) {/////yun suan
if(!make_token(e)) {
*success = false;
return 0;
}
bool formula_legal=true;
int cnt=0;
int i;
for(i=0;i<nr_token;++i){ //判断是不是合法括号
if(tokens[i].type=='(') cnt++;
else if(tokens[i].type==')') cnt--;
if(cnt<0) panic("this formula is not legal 算式不合法,可以告知是括号匹配有问题\n");
}
if(cnt!=0) panic("this formula is not legal 算式不合法,可以告知是括号匹配有问题\n");
judge_prior(0,nr_token-1);
formula_legal=judge_operator_legal(0,nr_token-1);//这个地方我其实还没有实现,省事就写了函数名然后返回值直接就是true,hhhhh
if(!formula_legal) panic("this formula is not legal 算式不合法,可以告知是运算符使用有问题\n");
int re=eval(0,nr_token-1);
return re;
/* TODO: Insert codes to evaluate the expression. */
}
int check_register(char *str,int len){
if(len>3) panic("寄存器的格式不对\n");
int num=0;
if(len==3){
// printf("%s debug\n",str);
int i;
for (i = R_EAX; i <= R_EDI; i ++){if (strncasecmp (str,regsl[i],3) == 0)break;}
if (i > R_EDI)
if (strncasecmp (str,"eip",3) == 0)
num = cpu.eip;
else panic ("no this register! 没有这个寄存器?\n");
else num = reg_l(i);
}
else if(len==2){
if (str[1] == 'x' || str[1] == 'p' || str[1] == 'i') {
int i;
for (i = R_AX; i <= R_DI; i ++)
if (strncasecmp (str,regsw[i],2) == 0)break;
num = reg_w(i);
}
else if (str[1] == 'l' || str[1] == 'h') {
int i;
for (i = R_AL; i <= R_BH; i ++)
if (strncasecmp (str,regsb[i],2) == 0)break;
num = reg_b(i);
}else{
panic ("no this register! 没有这个寄存器?\n");
}
}
return num;
}
static struct rule {
char *regex;
int token_type;
} rules[] = {
/* TODO: Add more rules.
* Pay attention to the precedence level of different rules.
*/
{"0[xX][0-9a-fA-F]+",HEX__},
{"\\$[a-zA-Z]+",REG__},
{"[0-9]+",NUM__}, //NUM
{"-",'-'}, //substraction
{"\\(",'('}, //left bracket
{"\\)",')'}, //right ____
{"\\/",'/'}, // chufa
{"\\*",'*'}, // muti
{" +", NOTYPE}, // spaces
{"\\+", '+'}, // plus
{"==", EQ}, // equal
{"&&",AND__},
{"\\|\\|",OXR__},
{"!=", UEQ},
{"!", NEG},
};
enum {
NOTYPE = 256,
NUM__ = 1,
AND__ =2,
OXR__ =3,
EQ = 4,
UEQ = 5,
NEG = 6,//非的优先级很高
HEX__ = 7,
REG__ = 8,
/* TODO: Add more token types */
};
typedef struct token {
int type;
char str[32];
int num;
int prior;
} Token;
Token tokens[32];
int nr_token;
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
nr_token = 0;
while(e[position] != '\0') {
/* Try all rules one by one. */
for(i = 0; i < NR_REGEX; i ++) {
if(regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;//eo 存放的位置是正则表达式结束的位置
Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s", i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
if(nr_token==32){
panic("Array overreach token 放不下那么多,调整一下式子长度");
return false;
}
switch(rules[i].token_type) {
case '-':
tokens[nr_token++].type='-';
break;
case '+':
tokens[nr_token++].type='+';
break;
case NUM__:{
int j;
int tem=0;
for(j=0;j<substr_len;++j){
tokens[nr_token].str[j]=*(substr_start+j);
tem*=10;
tem+=*(substr_start+j)-'0';
}
tokens[nr_token].type=NUM__;
tokens[nr_token++].num=tem;
break;
}
case NOTYPE: break;
case '/':
tokens[nr_token++].type='/';
break;
case '*':
tokens[nr_token++].type='*';
break;
case '(':
tokens[nr_token++].type='(';
break;
case ')':
tokens[nr_token++].type=')';
break;
case EQ:
tokens[nr_token++].type=EQ;
break;
case UEQ:
tokens[nr_token++].type=UEQ;
break;
case AND__:
tokens[nr_token++].type=AND__;
break;
case OXR__:
tokens[nr_token++].type=OXR__;
break;
case NEG:
tokens[nr_token++].type=NEG;
break;
case REG__:
strncpy (tokens[nr_token].str,substr_start+1,3);
*(tokens[nr_token].str+4)='\0';
tokens[nr_token].num=check_register(tokens[nr_token].str,substr_len-1);
tokens[nr_token++].type=NUM__;
break;
case HEX__:{
int j;
int temm=0x80000000;
uint32_t tem=0;
// printf("%d ----- \n",substr_len);
for(j=0;j<substr_len-2;++j){
tokens[nr_token].str[j]=*(substr_start+2+j);
// printf("%c+",tokens[nr_token].str[j]);
tem*=16;
if(*(substr_start+2+j)<='9')
tem+=*(substr_start+2+j)-'0';
else if(*(substr_start+2+j)<='f')
tem+=*(substr_start+2+j)-'a'+10;
else if(*(substr_start+2+j)<='F')
tem+=*(substr_start+2+j)-'A'+10;
}
int re;
// printf("0x%x debug////\n",tem);
uint32_t tem2=tem;
uint32_t tem3=tem;
int x=(tem2&0x7fffffff);
if((tem3&0x80000000)==0){re=tem;}
else re=temm+x;
tokens[nr_token].type=NUM__;
tokens[nr_token++].num=re;
break;
}
default: panic("在正则表达式中找到了,但是我没匹配到的运算符???????what fuck??? here is %d\n",rules[i].token_type);
}
// printf("%d****%d\n",nr_token,tokens[nr_token-1].type);
break;
}
}
if(i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}
int sum_parentheses(int l,int r){//维护括号,返回值用来调整 l 和 r的位置
int yuchuli=0;//预处理拼音
while(tokens[l+yuchuli].type=='('){
yuchuli++;
}
if(yuchuli==0) return 0;
int k=l;
int eeee=0;//e wai de (
int rrrb=yuchuli;//zuo kuo hao
for(k=l+yuchuli;k<=r;++k){
if(tokens[k].type=='(') eeee++;
else if(tokens[k].type==')'){
if(eeee==0)
rrrb--;
else eeee--;
}
if(r-k==rrrb&&eeee==0){
break;
}
}
return rrrb;
}
int eval(int l,int r){
int i;
int cntrightb=0;
int split=0xffff;
int split_prior=0xffff;
/*debug*/
// printf("%d %d ",l,r);
int change_l_r=sum_parentheses(l,r);
// printf("%d /****",change_l_r);
l+=change_l_r;
r-=change_l_r;
// printf("%d %d \n",l,r);
if(l>r){
/*jian yao de xiu fu*/
return 0;
panic("this formula is not legal 算式不合法,应该是不合法,感觉上不合法就不会进到这一步,可能有什么bug\n");
panic("why? l>r?????? here is l %d and r %d",l,r);
}
if(l==r){
return tokens[l].num;
}
for(i=r;i>=l;--i){
if(tokens[i].type=='(') { cntrightb++;continue;}
else if(tokens[i].type==')') {cntrightb--;continue;}
if(cntrightb!=0) continue;
if(cntrightb<0) {panic("括号不匹配????在eval里面,按理说是不会进入到这个函数的?\n");}
if(tokens[i].prior<split_prior){
split_prior=tokens[i].prior;
split=i;
}
}
// printf("%d %d %d debug\n",tokens[split].type,split,tokens[split].prior);
switch (tokens[split].type){
case '+':
if(split_prior==8) return eval(split+1,r);
else return eval(l,split-1)+eval(split+1,r);
break;
case '-':
if(split_prior==8) return 0-eval(split+1,r);
else return eval(l,split-1)-eval(split+1,r);
break;
case '*':
if(split_prior==7) return swaddr_read(eval(split+1,r),4);
else return eval(l,split-1)*eval(split+1,r);
break;
case '/':
return eval(l,split-1)/eval(split+1,r);
break;
case EQ:
// printf("%d %d\n",eval(l,split-1),eval(split+1,r));
if(eval(l,split-1)==eval(split+1,r)) return 1;
else return 0;
break;
case UEQ:
if(eval(l,split-1)==eval(split+1,r)) return 0;
else return 1;
break;
case NEG:
return (!eval(split+1,r));
break;
case AND__:
return (eval(l,split-1)&&eval(split+1,r));
case OXR__:
return (eval(l,split-1)||eval(split+1,r));
default: panic("在split中没有找到匹配的符号,多半是漏写了\n");
}
}
先这样吧,之后会整理下可能
