
xml解析的多种方式
1.解析xml
java解析xml的4种经典方法:
https://bbs.csdn.net/topics/290027113
http://www.blogjava.net/orangelizq/archive/2009/07/19/287330.html
1.dom解析
1.dom组成部分
DOM 定义了访问诸如 XML 和 XHTML 文档的标准。
DOM有3个部分组成:

在此只介绍xml DOM

2.DOM文档树
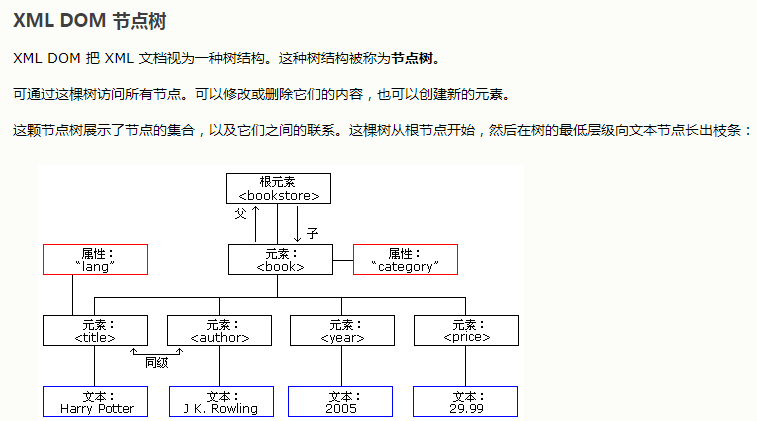
其中每个属性、标签、文本、根标签都称之为节点Node。
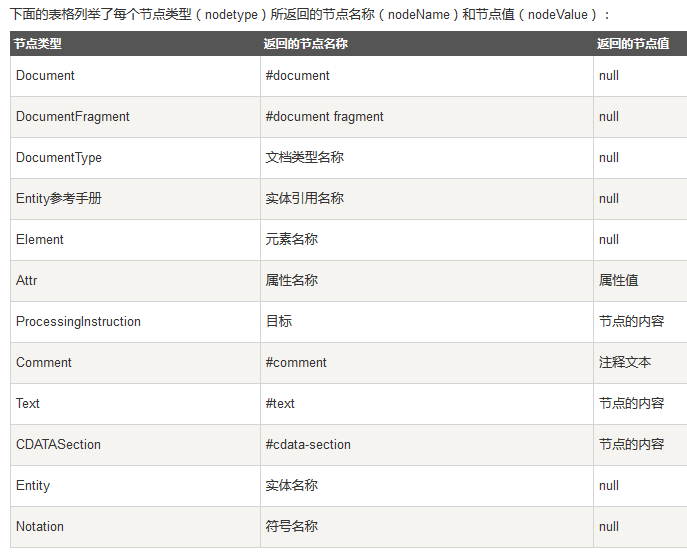
3.API介绍
使用DOM方式解析xml时不需要导入额外的jar文件,因为jdk已经包含了DOM方式解析需要的接口与类了,javax.xml.parser包中包含了创建文档Document的类,而org.w3c.dom包中包含了一些与节点树相关的类。
javax.xml.parser包结构如下:
org.w3c.dom包结构如下:


其中,
Node:代表文档树中的一个单独的节点。
Element:代表标签
Document:代表文档树
注意:
使用dom解析时,无法直接使用document对象获取根标签元素。但是使用jdom时可以
4.解析xml实例
package dom; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DomTest2 { public static void main(String[] args) { // TODO Auto-generated method stub //1.创建DocumentBuilderFactory对象 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //2.根据factory创建DocumentBuilder对象 DocumentBuilder builder=null; //3.创建document文档对象 Document document=null; //4.加载读取的xml文件 File f=new File("books.xml"); if(!f.exists()) { System.out.println("xml文件不存在"); } try { builder=factory.newDocumentBuilder(); document=builder.parse(f); NodeList nodeList=document.getElementsByTagName("bookstore"); Node book1=nodeList.item(0); Node book_name=book1.getFirstChild(); System.out.println(); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
注意:DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准。DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。DOM以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。
2.SAX解析
SAX(simple API for XML)是一种XML解析的替代方法。相比于DOM,SAX是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。而且相比于DOM,SAX可以在解析文档的任意时刻停止解析,但任何事物都有其相反的一面,对于SAX来说就是操作复杂。
1.工作原理

2.解析xml步骤

3.JDOM解析
使用这种方式解析时,需要导入jdom-xxx.jar文件
1.JDOM简介

DOM的缺点主要是来自于由于Dom是一个接口定义语言(IDL),它的任务是在不同语言实现中的一个最低的通用标准,并不是为JAVA特别设计的。JDOM的最新版本为JDOM Beta 9。最近JDOM被收录到JSR-102内,这标志着JDOM成为了JAVA平台组成的一部分。
在 JDOM 中,XML 元素就是 Element 的实例,XML 属性就是 Attribute 的实例,XML 文档本身就是 Document 的实例。
2.JDOM组成部分

3.解析步骤
一共2步:
1.创建SAXBuilder,使用构造方法创建。
2.创建Document,通过SAXBuilder对象的build()方法创建。
获得document对象之后就可以进行相应的操作了。
4.解析xml实例
package jdom; import java.io.File; import java.io.IOException; import org.jdom2.Document; import org.jdom2.Element; import org.jdom2.JDOMException; import org.jdom2.input.SAXBuilder; public class JDOM_demo { public static void main(String[] args) { SAXBuilder builder=new SAXBuilder(); try { Document document=builder.build(new File("books.xml")); Element rootElement=document.getRootElement(); //获取根标签的名称,注意不是属性名称 String name=rootElement.getName(); System.out.println(name); } catch (JDOMException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
4.DOM4J解析
dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的。
Dom4j是一个易用的、开源的库,用于XML,XPath和XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX和JAXP。
1.解析程序步骤
1.获得文档对象
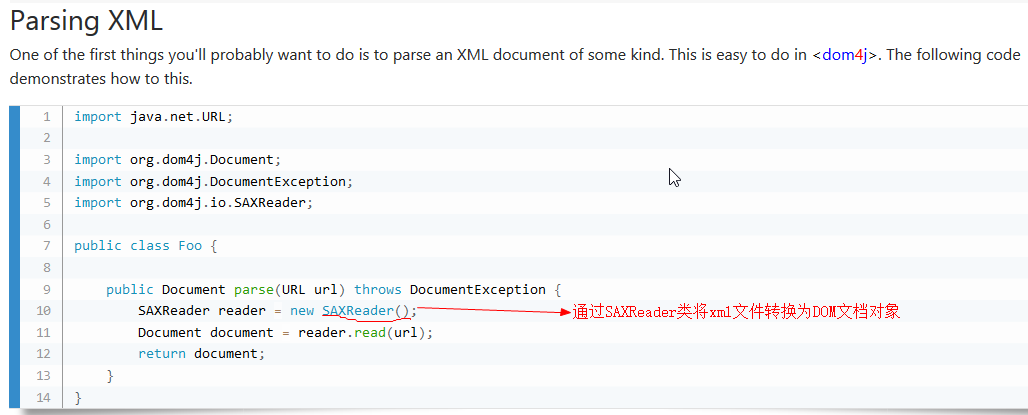
2.获得根标签元素
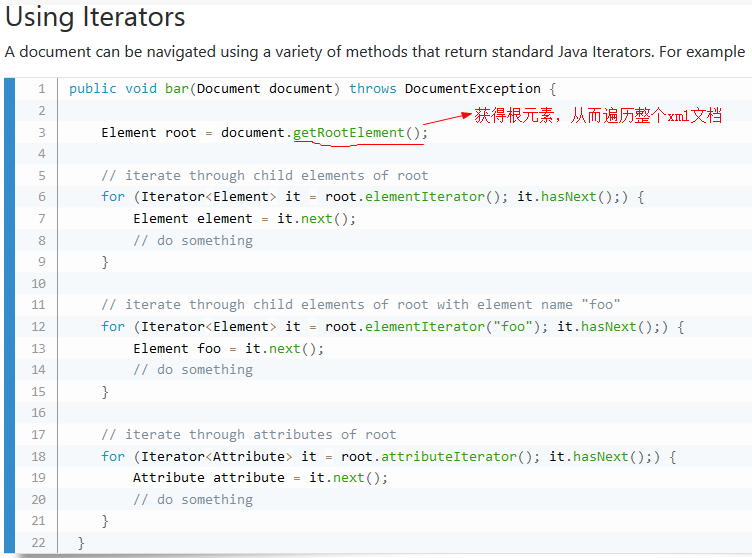
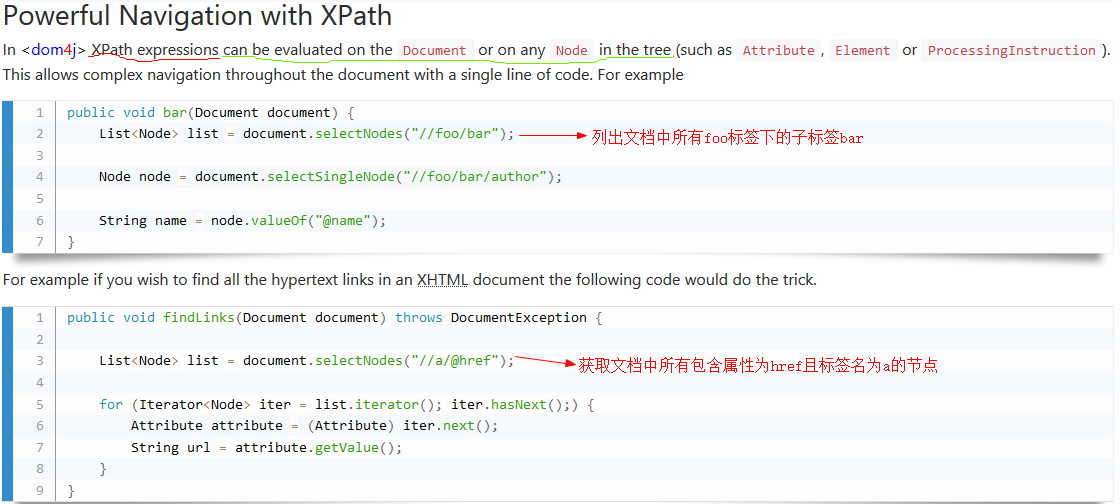
3.通过xpath表达式寻找特定的节点
XPATH路径表达式的语法详细介绍请跳转https://www.runoob.com/xpath/xpath-syntax.html
4.使用快速循环方法遍历文档树
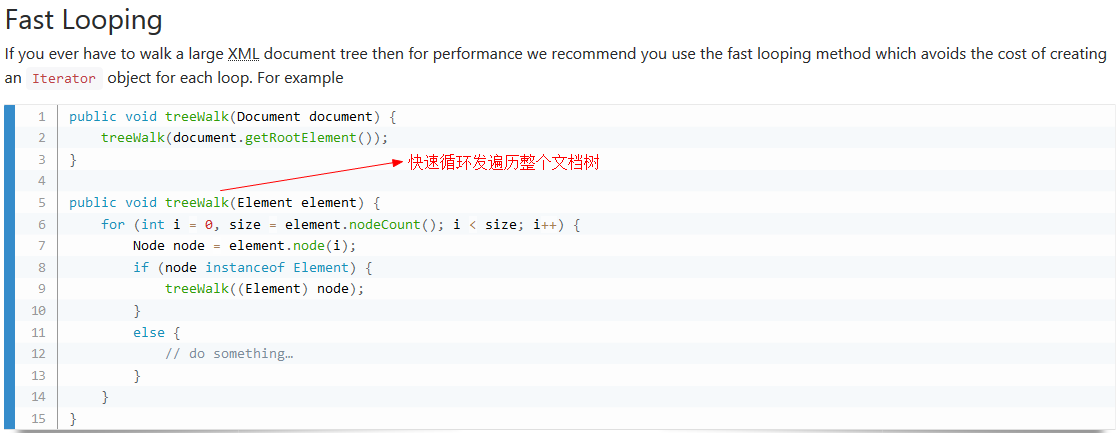
这个是遍历整个文档的好方法
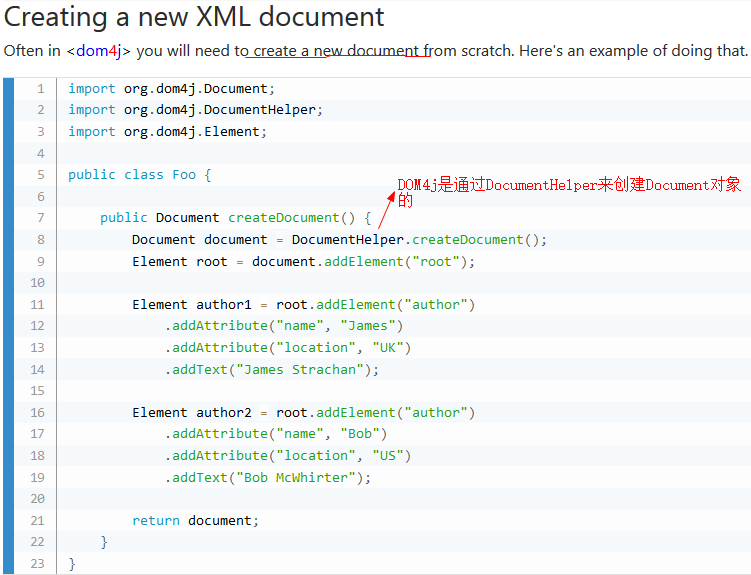
5.创建文档对象
6.String对象与文档对象Document之间的转换
1.String转换为Document

2.Document转换为String类型

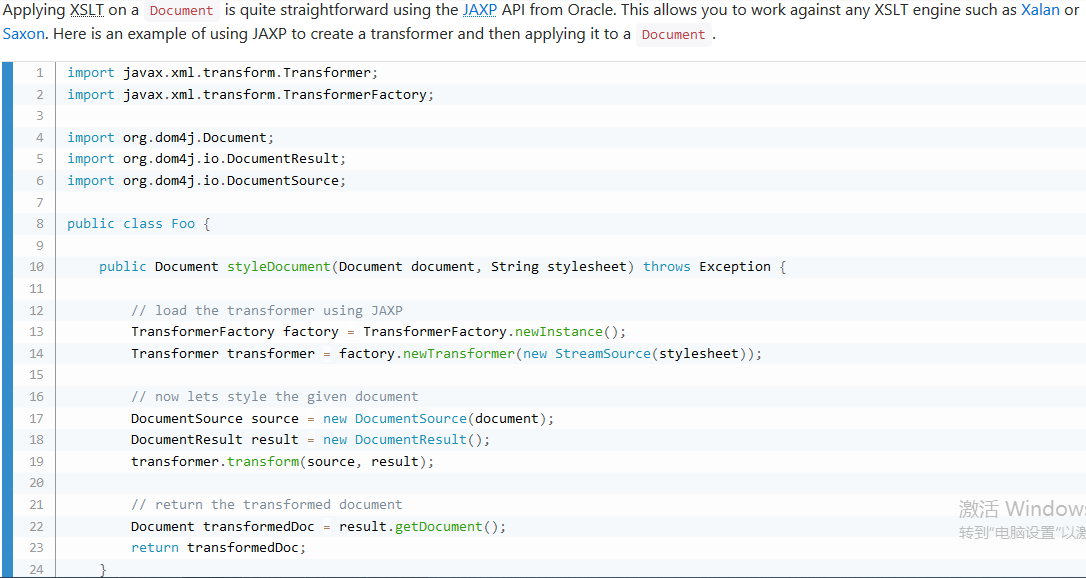
7.用XSLT转换文档
2.生成xml
java生成xml的4种经典方法:https://blog.csdn.net/qq_39237801/article/details/78378486


