
【129期】看完这篇,再也不怕面试被问HashMap了~
总所周知 HashMap 是面试中经常问到的一个知识点,也是判断一个候选人基础是否扎实的标准之一,因为通过 HashMap 可以引出很多知识点,比如数据结构(数组、链表、红黑树)、equals 和 hashcode 方法。
除此之外还可以引出线程安全的问题,HashMap 是我在初学阶段学到的设计的最为巧妙的集合,里面有很多细节以及优化技巧都值得我们深入学习,话不多说先看看相关的面试题:
• 默认大小、负载因子以及扩容倍数是多少
• 底层数据结构
• 如何处理 hash 冲突的
• 如何计算一个 key 的 hash 值
• 数组长度为什么是 2 的幂次方
• 扩容、查找过程
如果上面的都能回答出来的话你就不需要看这篇文章了,那么开始进入正文。
数据结构
• 在 JDK1.8 中,HashMap 是由数组+链表+红黑树构成
• 当一个值中要存储到 HashMap 中的时候会根据 Key 的值来计算出他的 hash,通过 hash 值来确认存放到数组中的位置,如果发生 hash 冲突就以链表的形式存储,当链表过长的话,HashMap 会把这个链表转换成红黑树来存储。
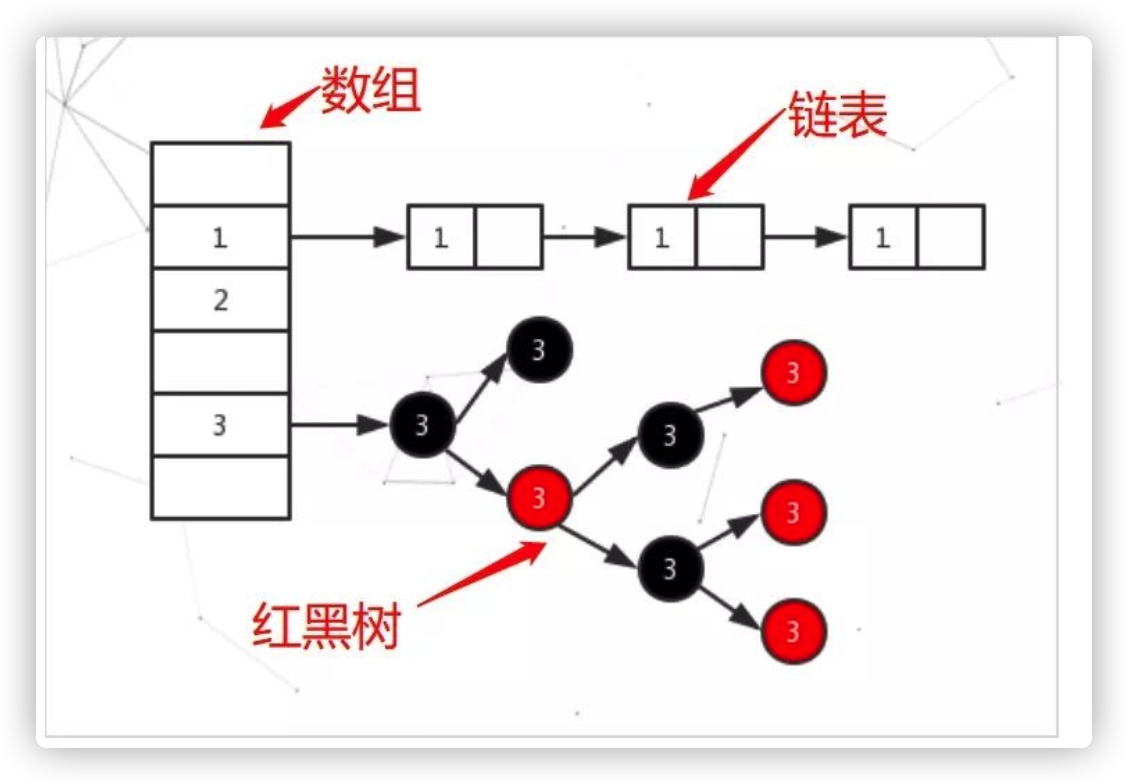

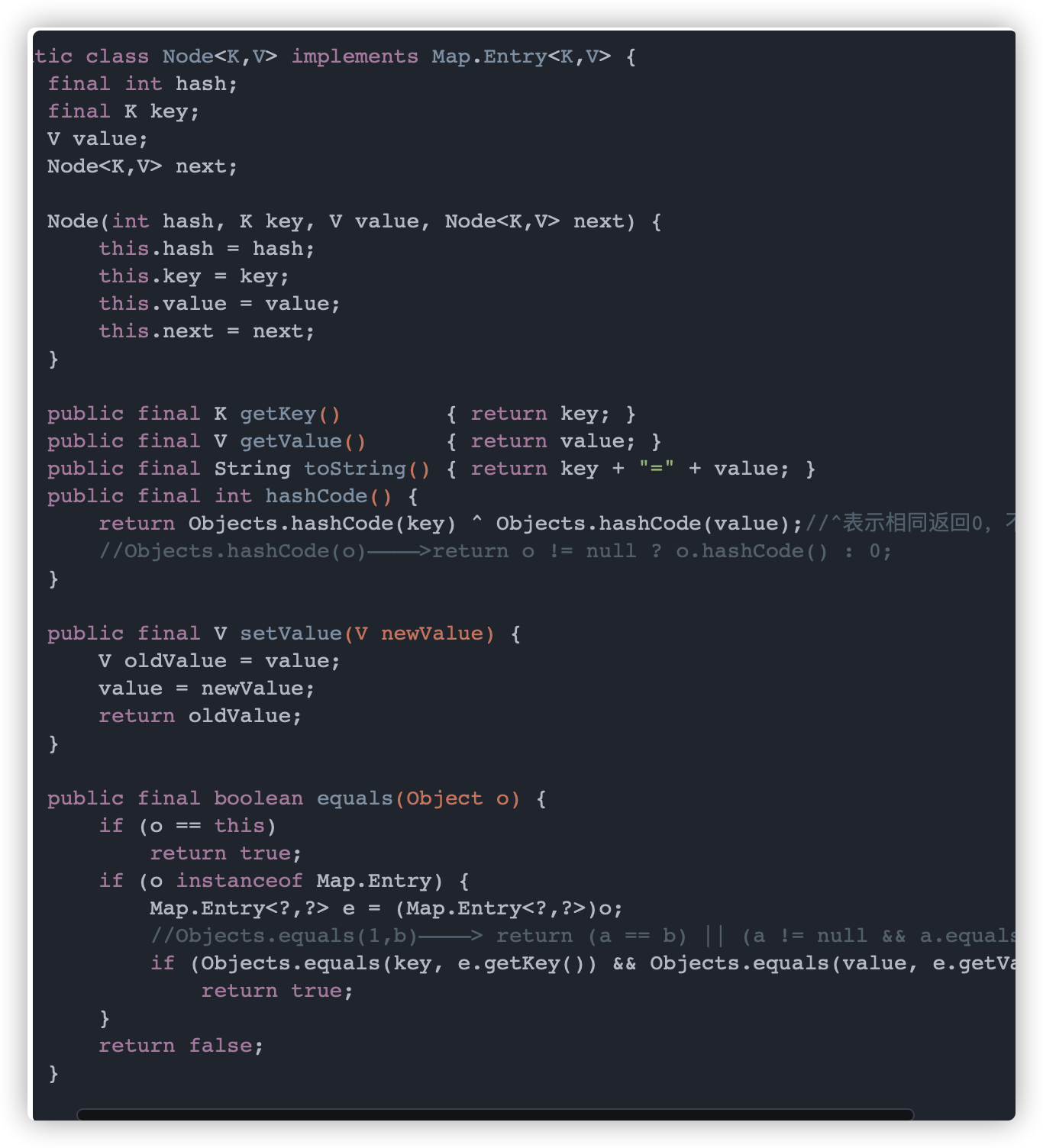
table 数组里面存放的是 Node 对象,Node 是 HashMap 的一个内部类,用来表示一个 key-value,源码如下:
总结:
• 默认初始容量为 16,默认负载因子为 0.75
• threshold = 数组长度 * loadFactor,当元素个数超过threshold(容量阈值)时,HashMap 会进行扩容操作
• table 数组中存放指向链表的引用
这里需要注意的一点是 table 数组并不是在构造方法里面初始化的,它是在 resize(扩容)方法里进行初始化的。
table 数组长度永远为 2 的幂次方
总所周知,HashMap 数组长度永远为 2 的幂次方(指的是 table 数组的大小),那你有想过为什么吗?
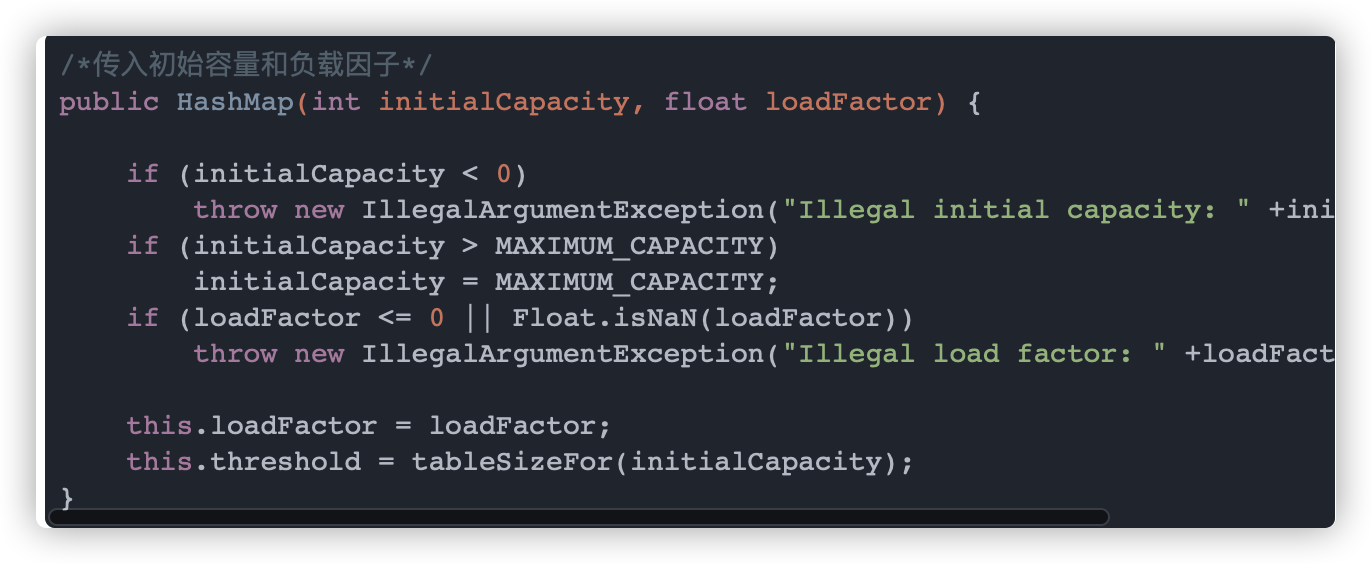
首先我们需要知道 HashMap 是通过一个名为 tableSizeFor 的方法来确保 HashMap 数组长度永远为2的幂次方的,源码如下:

tableSizeFor 的功能(不考虑大于最大容量的情况)是返回大于等于输入参数且最近的 2 的整数次幂的数。比如 10,则返回 16。
该算法让最高位的 1 后面的位全变为 1。最后再让结果 n+1,即得到了 2 的整数次幂的值了。
让 cap-1 再赋值给 n 的目的是另找到的目标值大于或等于原值。例如二进制 1000,十进制数值为 8。如果不对它减1而直接操作,将得到答案 10000,即 16。显然不是结果。减 1 后二进制为 111,再进行操作则会得到原来的数值 1000,即 8。通过一系列位运算大大提高效率。
那在什么地方会用到 tableSizeFor 方法呢?
答案就是在构造方法里面调用该方法来设置 threshold,也就是容量阈值。
这里你可能又会有一个疑问:为什么要设置为 threshold 呢?
因为在扩容方法里第一次初始化 table 数组时会将 threshold 设置数组的长度,后续在讲扩容方法时再介绍。
那么为什么要把数组长度设计为 2 的幂次方呢?
我个人觉得这样设计有以下几个好处:
-
当数组长度为 2 的幂次方时,可以使用位运算来计算元素在数组中的下标
HashMap 是通过 index=hash&(table.length-1) 这条公式来计算元素在 table 数组中存放的下标,就是把元素的 hash 值和数组长度减1的值做一个与运算,即可求出该元素在数组中的下标,这条公式其实等价于 hash%length,也就是对数组长度求模取余,只不过只有当数组长度为 2 的幂次方时,hash&(length-1) 才等价于 hash%length,使用位运算可以提高效率。 -
增加 hash 值的随机性,减少 hash 冲突
如果 length 为 2 的幂次方,则 length-1 转化为二进制必定是 11111……的形式,这样的话可以使所有位置都能和元素 hash 值做与运算,如果是如果 length 不是 2 的次幂,比如 length 为 15,则 length-1 为 14,对应的二进制为 1110,在和 hash 做与运算时,最后一位永远都为 0 ,浪费空间。
扩容
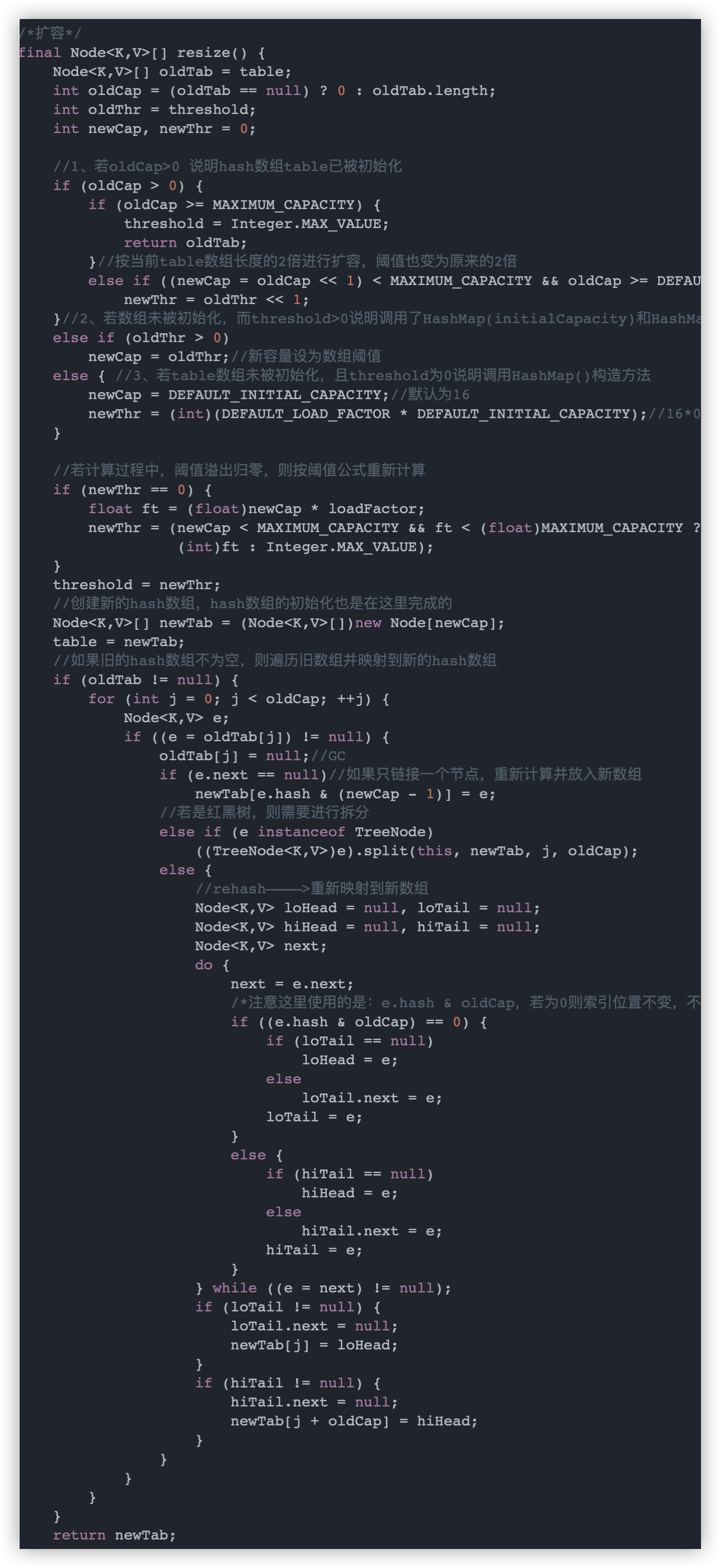
HashMap 每次扩容都是建立一个新的 table 数组,长度和容量阈值都变为原来的两倍,然后把原数组元素重新映射到新数组上,具体步骤如下:
-
首先会判断 table 数组长度,如果大于 0 说明已被初始化过,那么按当前 table 数组长度的 2 倍进行扩容,阈值也变为原来的 2 倍
-
若 table 数组未被初始化过,且 threshold(阈值)大于 0 说明调用了 HashMap(initialCapacity, loadFactor) 构造方法,那么就把数组大小设为 threshold
-
若 table 数组未被初始化,且 threshold 为 0 说明调用 HashMap() 构造方法,那么就把数组大小设为 16,threshold 设为 16*0.75
-
接着需要判断如果不是第一次初始化,那么扩容之后,要重新计算键值对的位置,并把它们移动到合适的位置上去,如果节点是红黑树类型的话则需要进行红黑树的拆分。
这里有一个需要注意的点就是在 JDK1.8 HashMap 扩容阶段重新映射元素时不需要像 1.7 版本那样重新去一个个计算元素的 hash 值,而是通过 hash & oldCap 的值来判断,若为 0 则索引位置不变,不为 0 则新索引=原索引+旧数组长度,为什么呢?具体原因如下:

在扩容方法里面还涉及到有关红黑树的几个知识点:
链表树化
指的就是把链表转换成红黑树,树化需要满足以下两个条件:
链表长度大于等于 8
table 数组长度大于等于 64
为什么 table 数组容量大于等于 64 才树化?
因为当 table 数组容量比较小时,键值对节点 hash 的碰撞率可能会比较高,进而导致链表长度较长。这个时候应该优先扩容,而不是立马树化。
红黑树拆分
拆分就是指扩容后对元素重新映射时,红黑树可能会被拆分成两条链表。
由于篇幅有限,有关红黑树这里就不展开了。
查找
HashMap 的查找是非常快的,要查找一个元素首先得知道 key 的 hash 值,在 HashMap 中并不是直接通过 key 的 hashcode 方法获取哈希值,而是通过内部自定义的 hash 方法计算哈希值,我们来看看其实现:

(h = key.hashCode()) ^ (h >>> 16) 是为了让高位数据与低位数据进行异或,变相的让高位数据参与到计算中,int 有 32 位,右移 16 位就能让低 16 位和高 16 位进行异或,也是为了增加 hash 值的随机性。
知道如何计算 hash 值后我们来看看 get 方法
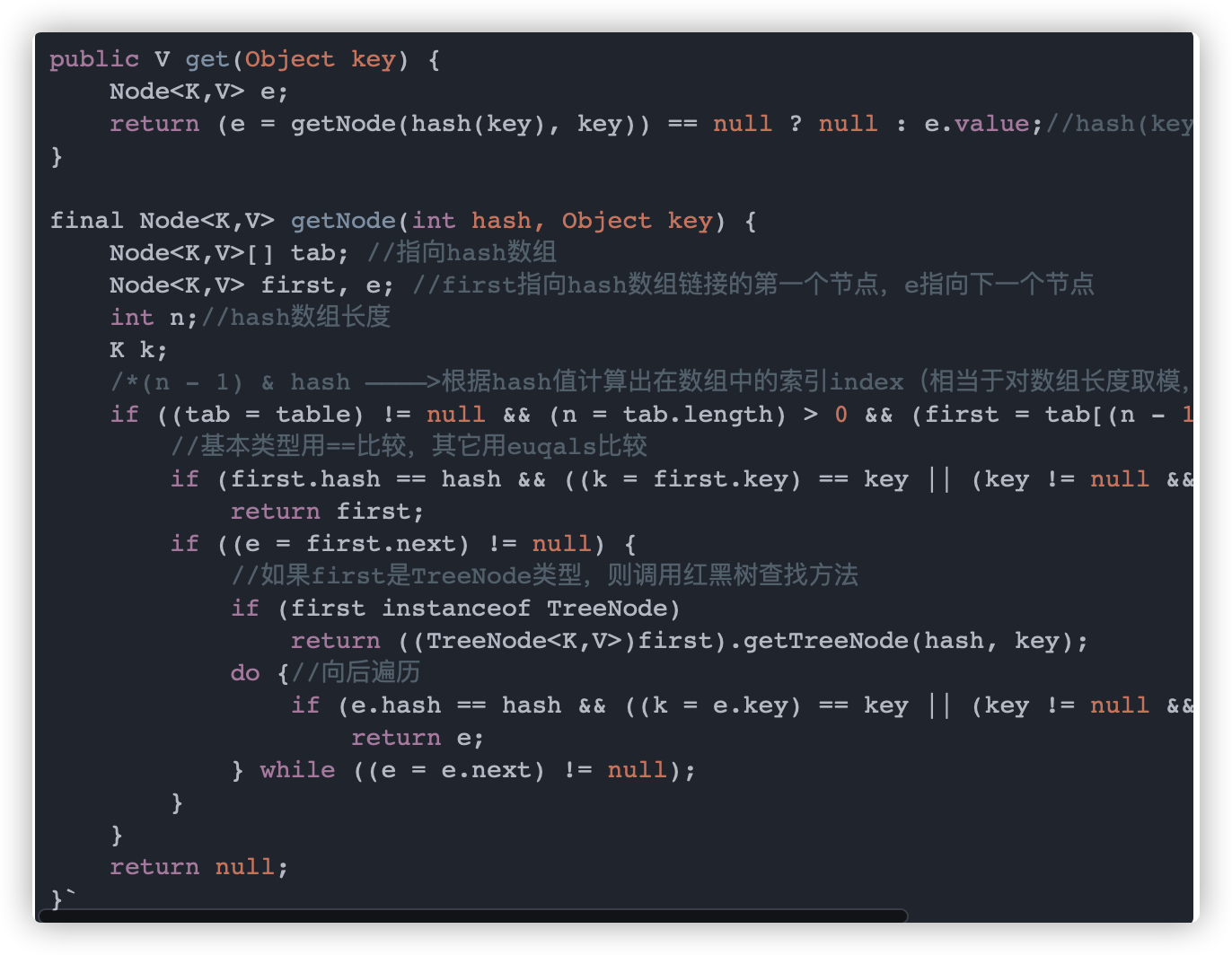
这里要注意的一点就是在 HashMap 中用 (n - 1) & hash 计算 key 所对应的索引 index(相当于对数组长度取模,这里用位运算进行了优化),这点在上面已经说过了,就不再废话了。
插入
我们先来看看插入元素的步骤:
-
当 table 数组为空时,通过扩容的方式初始化 table
-
通过计算键的 hash 值求出下标后,若该位置上没有元素(没有发生 hash 冲突),则新建 Node 节点插入
-
若发生了 hash 冲突,遍历链表查找要插入的 key 是否已经存在,存在的话根据条件判断是否用新值替换旧值
-
如果不存在,则将元素插入链表尾部,并根据链表长度决定是否将链表转为红黑树
-
判断键值对数量是否大于阈值,大于的话则进行扩容操作
先看完上面的流程,再来看源码会简单很多,源码如下:
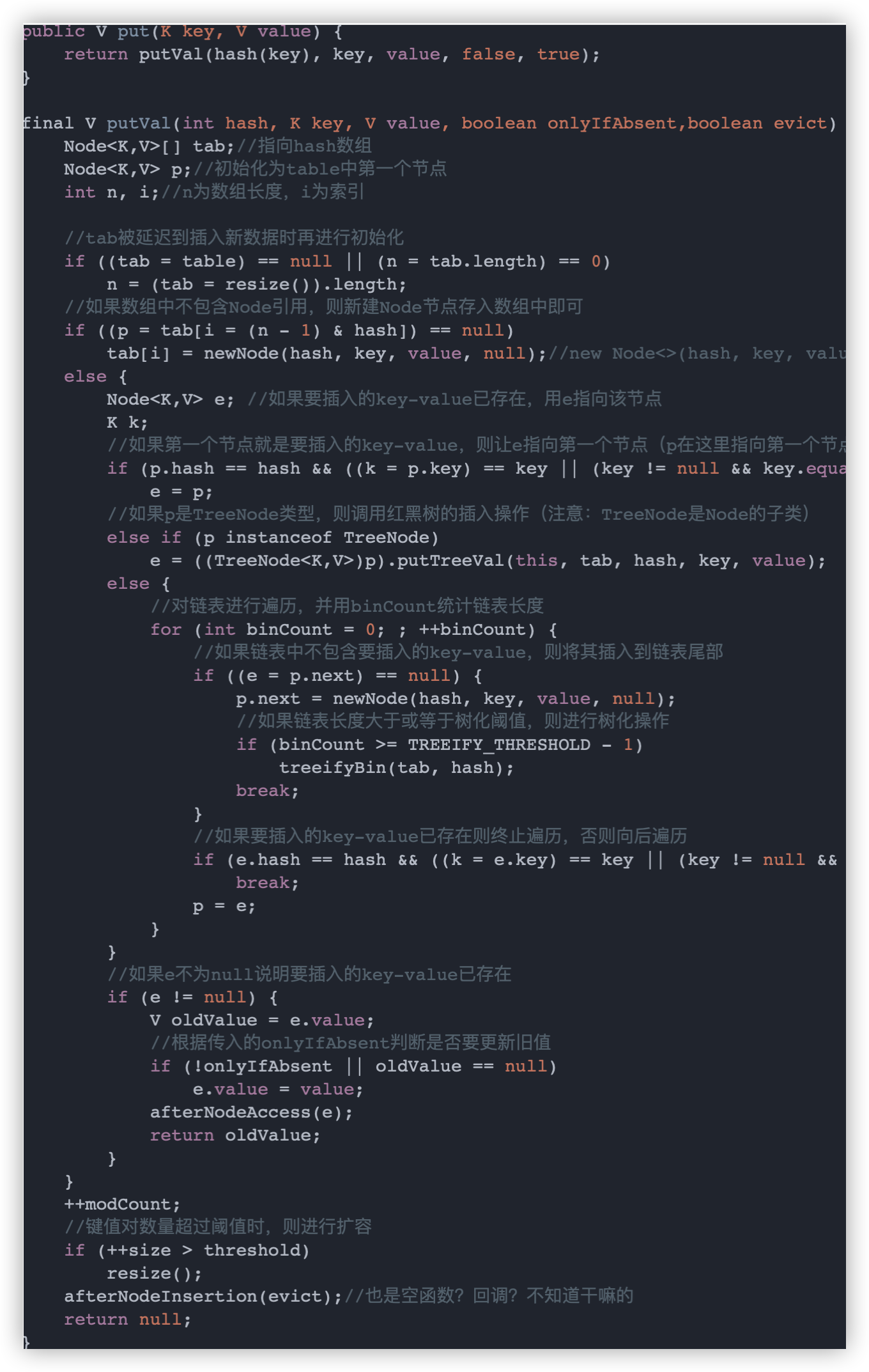
从源码也可以看出 table 数组是在第一次调用 put 方法后才进行初始化的。
删除
HashMap 的删除操作并不复杂,仅需三个步骤即可完成。
-
定位桶位置
-
遍历链表找到相等的节点
-
第三步删除节点
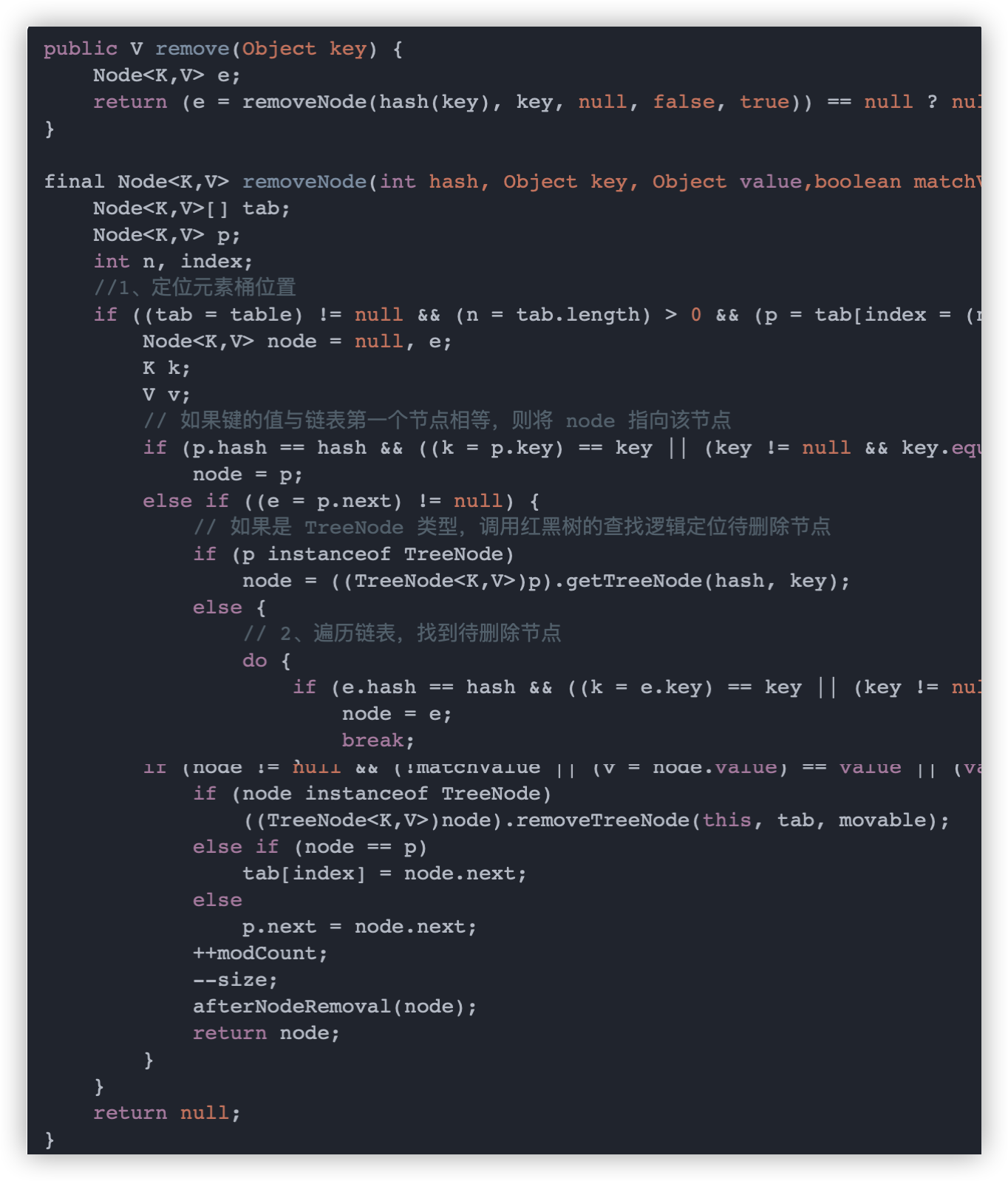
注意:删除节点后可能破坏了红黑树的平衡性质,removeTreeNode 方法会对红黑树进行变色、旋转等操作来保持红黑树的平衡结构,这部分比较复杂。
遍历
在工作中 HashMap 的遍历操作也是非常常用的,也许有很多小伙伴喜欢用 for-each 来遍历,但是你知道其中有哪些坑吗?
看下面的例子,当我们在遍历 HashMap 的时候,若使用 remove 方法删除元素时会抛出 ConcurrentModificationException 异常
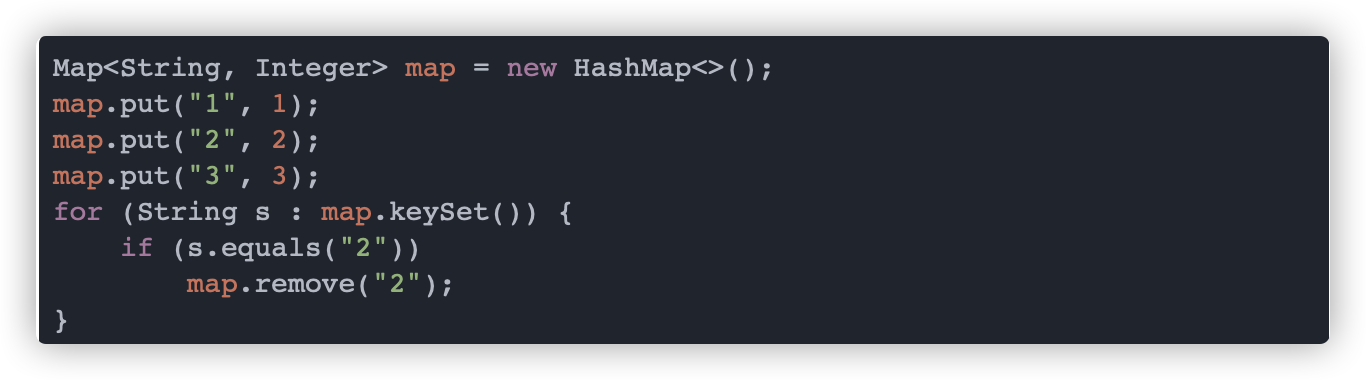
这就是常说的 fail-fast(快速失败)机制,这个就需要从一个变量说起

在 HashMap 中有一个名为 modCount 的变量,它用来表示集合被修改的次数,修改指的是插入元素或删除元素,可以回去看看上面插入删除的源码,在最后都会对 modCount 进行自增。
当我们在遍历 HashMap 时,每次遍历下一个元素前都会对 modCount 进行判断,若和原来的不一致说明集合结果被修改过了,然后就会抛出异常,这是 Java 集合的一个特性,我们这里以 keySet 为例,看看部分相关源码:
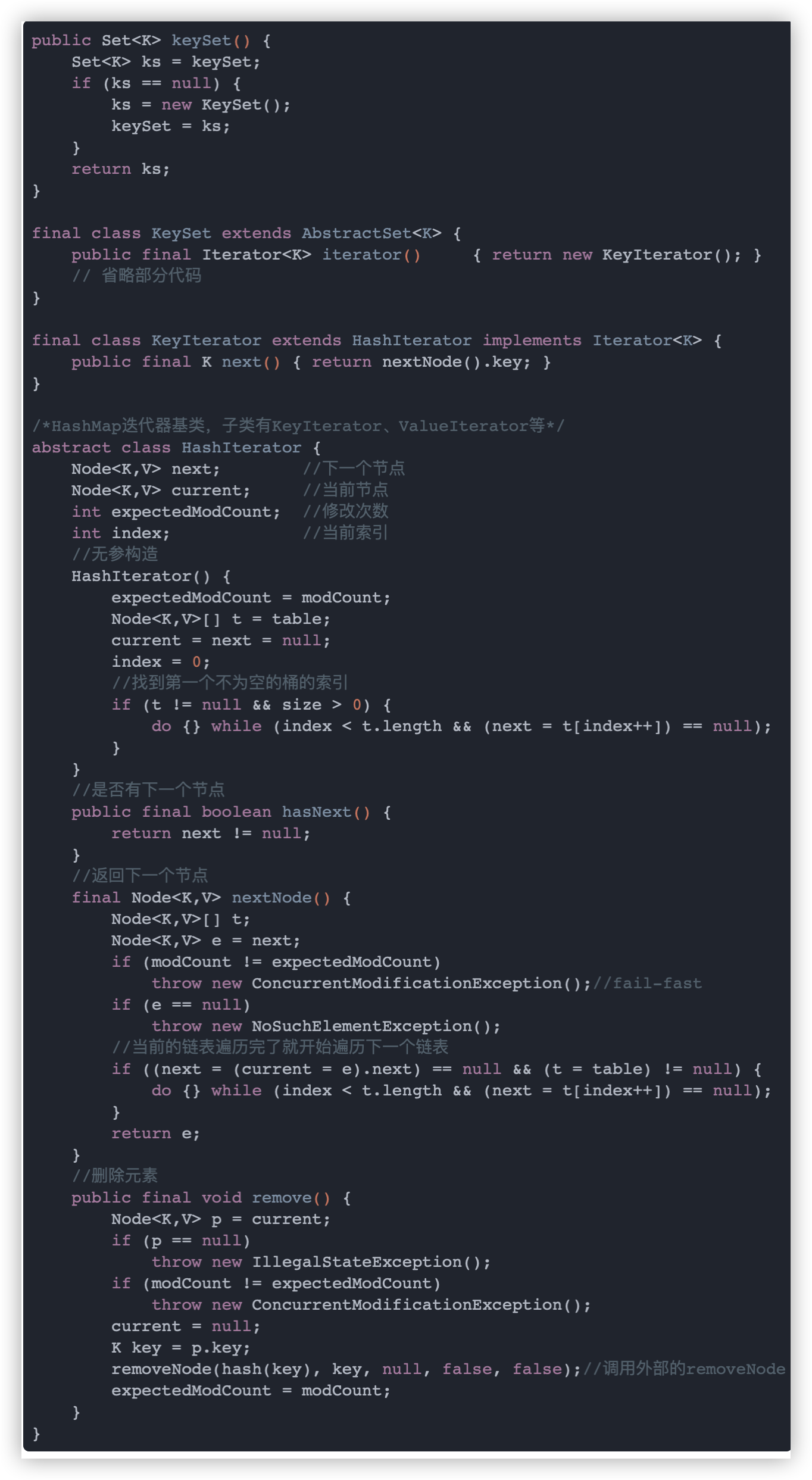
相关代码如下,可以看到若 modCount 被修改了则会抛出 ConcurrentModificationException 异常。

那么如何在遍历时删除元素呢?
我们可以看看迭代器自带的 remove 方法,其中最后两行代码如下:

意思就是会调用外部 remove 方法删除元素后,把 modCount 赋值给 expectedModCount,这样的话两者一致就不会抛出异常了,所以我们应该这样写:
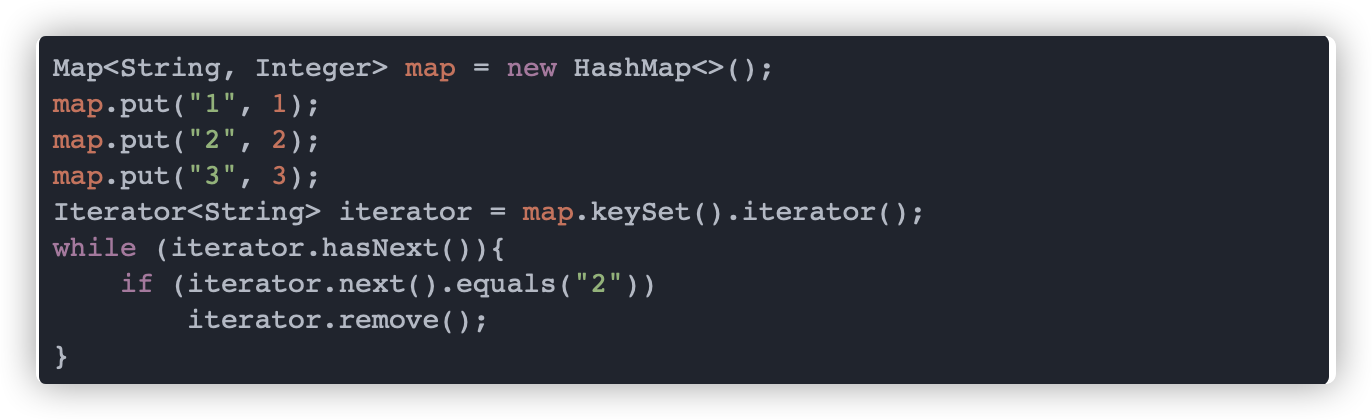
这里还有一个知识点就是在遍历 HashMap 时,我们会发现遍历的顺序和插入的顺序不一致,这是为什么?
在 HashIterator 源码里面可以看出,它是先从桶数组中找到包含链表节点引用的桶。然后对这个桶指向的链表进行遍历。遍历完成后,再继续寻找下一个包含链表节点引用的桶,找到继续遍历。找不到,则结束遍历。这就解释了为什么遍历和插入的顺序不一致,不懂的同学请看下图:
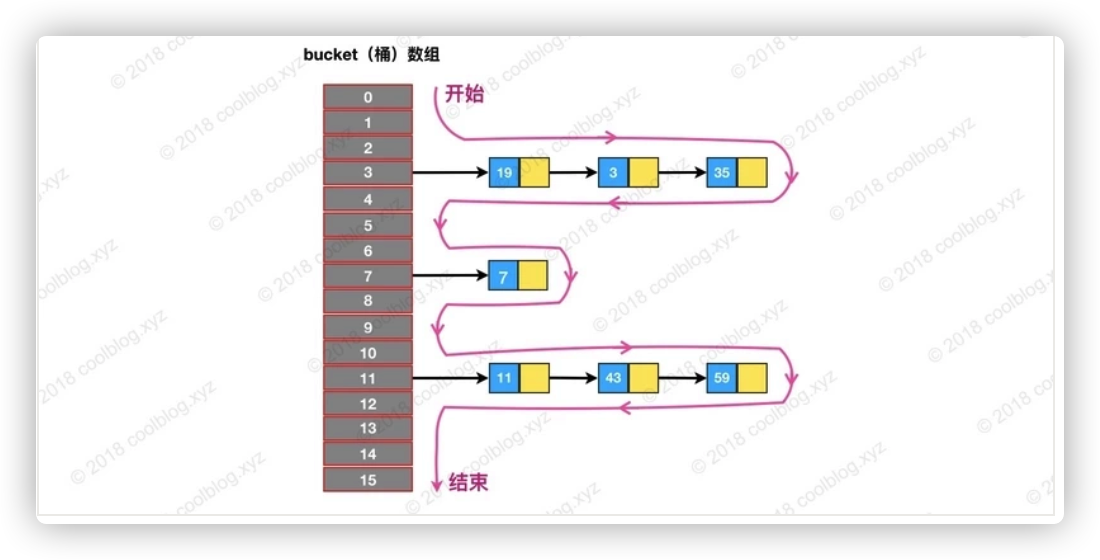
equasl 和 hashcode
为什么添加到 HashMap 中的对象需要重写 equals() 和 hashcode() 方法?
简单看个例子,这里以 Person 为例:
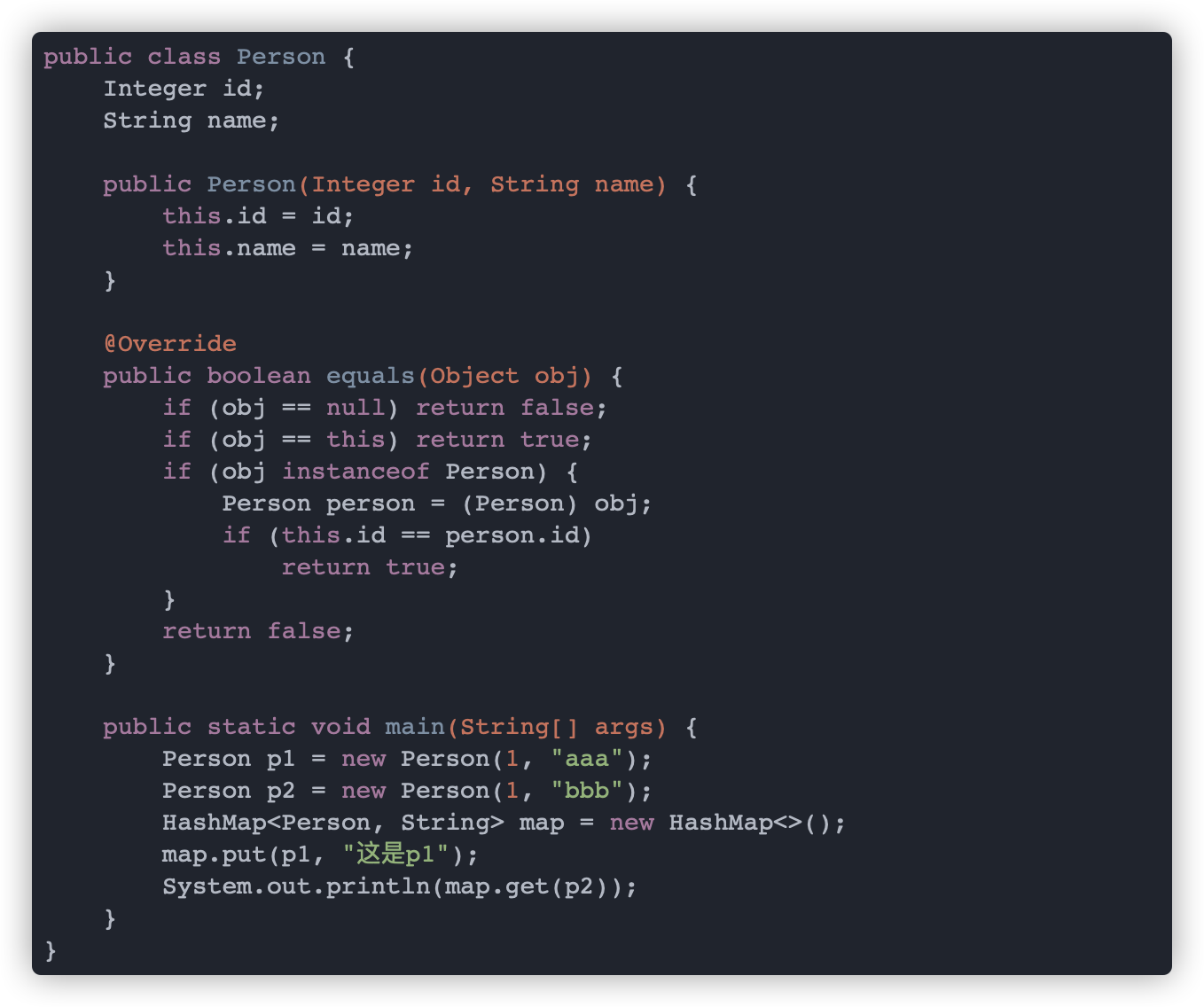
•原生的 equals 方法是使用 == 来比较对象的
•原生的 hashCode 值是根据内存地址换算出来的一个值
Person 类重写 equals 方法来根据 id 判断是否相等,当没有重写 hashcode 方法时,插入 p1 后便无法用 p2 取出元素,这是因为 p1 和 p2 的哈希值不相等。
HashMap 插入元素时是根据元素的哈希值来确定存放在数组中的位置,因此HashMap 的 key 需要重写 equals 和 hashcode 方法。
总结
本文描述了 HashMap 的实现原理,并结合源码做了进一步的分析,后续有空的话会聊聊有关 HashMap 的线程安全问题,希望本篇文章能帮助到大家,同时也欢迎讨论指正,谢谢支持!


