repmgr选举原理
从墨天轮上看到一篇非常详细的repmgr的选举原理文章
https://www.modb.pro/db/1717061449015713792
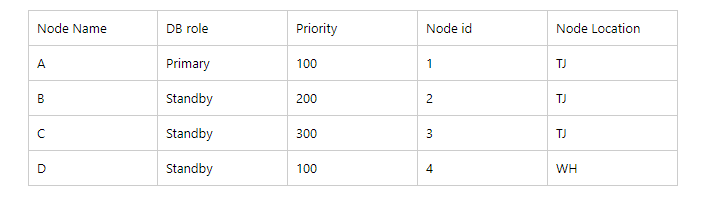
1)很不幸,由于某种原因主库 A 节点 down掉了
2)B,C,D 尝试等待重连主库A节点: checking state of node 1, N of 6 attempts…
3)连接超时后,BCD会各自进入选举的过程:由于D的location 和 A 节点的location 是不一样的,直接返回 =》 ELECTION_NOT_CANDIDATE
4)B和 C 节点会执行获取last lsn的操作:如果无法获取LSN的值,直接返回 =》 ELECTION_LOST
5)如果发现WAL的日志应用的停止的,则尝试resume wal log的应用, 如果尝试resume_wal_replay 失败, 直接返回 =》 ELECTION_LOST
6)候选者B和C来进行如下的比较:经过一系列的比较,我们B和C之间的 LSN是一样的, 但是B的 priority 200 小于 C的 priority 300.这个时候C节点为理想的candidate.
7)进行防治网络脑裂的检测: 检查在主节点所在的location, 是否还有存活的节点,如果不存在,则视为网络脑裂,直接返回 =》 ELECTION_CANCELLED
8)老的主库是否依旧存活 nodes_with_primary_still_visible > 0 ? , 如果是由于某些网络原因,造成主库的连接不稳定, 主库恢复之后, 直接返回 =》 ELECTION_CANCELLED
9)同一个location中是否存在大多数节点存活判断: 存活节点如果小于等于 3/2.0 = 1.5 的话 直接返回 =》 ELECTION_CANCELLED
10)判断候选的ID是否和本地的ID是一致的。目前candidate是 C节点, C节点上的 do_election 直接返回选举获胜 ELECTION_WON B节点,直接返回 ELECTION_LOST
11)至此,C 节点成为选举的winner
选举优先级:LSN>priority>node_id。同时强烈建议使用NodeLocation来区分不通的DC,防止脑裂情况的发生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号