Redis学习
(PS:总体似流水账,以备忘)
以下所述为针对Redis 4.0的版本。
1、简介
Redis(REmote DIctionary Server) 是一个由意大利人 Salvatore Sanfilippo 编写的开源的内存key-value存储数据库,使用ANSI C语言编写、遵守BSD协议。
用途:它可被用作数据库、缓存、消息中间件、队列、发布订阅系统等,用途主要有:
当被作为数据库使用时,需要考虑数据库的一些问题,如数据持久化。
功能特点:
其通常被称为数据结构服务器,因为值(value)可以是字符串(String)、列表(list)、哈希(Hash)、集合(Set) 和 有序集合(Sorted Set)类型,此外还支持GEO(地理数据类型,如经纬度,基于Sorted Set实现)类型数据结构。
Redis 内置了复制(Replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(Transactions) 和不同级别的磁盘持久化(Persistence),并通过 Redis哨兵(Sentinel)和自动分区(Cluster)支持以集群运行从而提供高可用性(High Availability)。
其是内存数据库,同时也支持数据持久化。目前有RDB、AOF两种持久化方式。
Redis与其他key-value缓存产品(如memcache)有以下几个特点。
- Redis不仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- 单线程模型和其IO模型使得并发处理IO性能极高。
- Redis支持高可用(主从、哨兵、分布式集群)。
学、考察Redis内容主要就是弄懂上述几个不同点的内容,即 丰富的数据结构、持久化、性能、高可用 几个方面。
Redis为什么这么快?至少有如下原因:
完全内存操作,速度快,且数据在内存中以字典(理解为HashMap)存储,存取O(1)时间复杂度;
数据结构简单,所支持的对数据的操作也简单,数据结构的底层实现经过极致优化(例如会根据元素个数和值采用不同的底层实现以提升存储和读写效率);
IO模型:采用了IO多路复用和Reactor模式处理IO,并发处理IO的能力极高;
单线程模型:实现简单、命令间顺序执行,无需加锁和考虑线程安全问题,也没有多线程或进程创建及切换开销;
横向比较:
分布式缓存,有Memcached、Redis、Tair等,其中应用最广泛的是Redis。Redis很好用,相比memcached多了很多数据结构,支持持久化。但在很长一段时间里,原生是不支持分布式的。后来就出现了很多redis集群类产品,阿里的Tair是其中胜出的优秀作品之一,其特性都是一些集群的特性,比如:容错、解决单点故障、跨机房管理、多集群管理、支持副本等。总而言之,Tair是基于Redis的高可用版本。
2、安装
这里通过源码安装,直接从 https://download.redis.io/releases/ 下载解压即可用。这里所用版本为 Redis 4.0.10
数据默认存在redis根目录的dump.rdb,默认免密码连接。
允许其他机子访问:
默认只允许本机访问且只能通过localhost访问。其他机子虽能连接但运行命令会报权限错误:
(error) DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients. In this mode connections are only accepted from the loopback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command 'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the '--protected-mode no' option. 4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside.
解决:
若启动时未指定配置文件,如上述提示中第一条所示可以在运行时修改并REWRITE到文件,否则重启后会失效(猜测是因为运行时修改只修改程序内变量值所以重启后失效)。虽执行CONFIG REWRITE 会报(error) ERR The server is running without a config file,但此后其他机子可以连接了。
若指定了配置文件,则按上述提示修改配置文件后重启即可:
法1:(上述信息说改一条即可,本次实践行不通,得改两个)
bind 127.0.0.1,默认生效,注释掉
protected-mode yes,默认为yes,改为no
法2:将 bind 127.0.0.1 改为 0.0.0.0
安全:
默认没有密码,可以直接在配置文件redis.conf里配requirepass字段来设置密码,也可以登录后设置:
获取密码: config get requirepass
设置密码: config set requirepass
验证密码:auth xxx,成功后才能进行其他命令操作
密码不对时可以连接,但是连接上后执行各种操作都会提示没权限: ”(error) NOAUTH Authentication required.“
取消密码:可将密码设置为空串,此时相当于没有密码
启动: ./src/redis-server [ redis.conf ] ,可以指定配置文件,若不指定配置文件则不会默认使用目录下的redis.conf而是使用程序内建的默认值。
连接: redis-cli -h {redis_host} -p {redis_port}
3、数据类型
类型:String、List、Hash、Set、Sorted Set
数据量:用unsigned int表示长度,故最大长度为A=2^32(四十多亿),从而:String类型一个key的值最多存A个bit 即 512MB、List类型一个key最多存A个元素、Hash类型一个key最多存A个键值对、Set/Sorted Set类型一个key最多存A个元素。
详情:这里列出各类型的主要操作命令以便于查找(以下各操作命令都是原子的,help xx 查看指定命令的用法简介,具体用法可参阅官方文档翻译 http://redisdoc.com/index.html )
3.1、String
SET key value [EX seconds] [PX milliseconds] [NX|XX]、setnx、setex、mset、msetnx、psetnx、setrange (setnx、setex可由set及其参数搭配来实现)
get、mget、getset、getrange、scan
incr、incrby、decr、decrby、incrbyfloat
append、substr、strlen
setbit、getbit、bitcount、bitfield、bitop(and、or、xor、not):字符串二进制的位操作,这里位的offset 0、1、2...是从高位到低位的。bitcount用了HyperLogLog算法实现。
位操作的用途:
布隆过滤器,如Redis客户端Redisson的布隆过滤器底层就是用Redis bit实现。
位操作可用于统计应用的活跃用户数等。示例:


127.0.0.1:6379> set name 0 # 0的ascll值是0x30 OK 127.0.0.1:6379> GETBIT name 0 (integer) 0 127.0.0.1:6379> GETBIT name 1 (integer) 0 127.0.0.1:6379> GETBIT name 2 (integer) 1 127.0.0.1:6379> GETBIT name 3 (integer) 1 127.0.0.1:6379> GETBIT name 4 (integer) 0
Redis String类型的set等命令,在内部最终是用dict(或叫hash)存的。
内部用SDS(即 Simple Dynamic String)实现。
特点:动态、二进制安全、可存储数值等非字符串数据、不负责编解码。其中第一种最根本,后三种是第一种的附带效果。
动态:动态体现在字符串可伸缩、可追加、可修改、甚至可当做bit序列修改。‘
SDS内部用动态分配的字符数组来表示字符串,并且字符数组采用预分配和惰性释放方案(会比实际所需的多分配一些内存,用len、free表示字符数组中实际占用、不再占用的空间大小,字符串变短时不会立马回收而是把空间留着)、并可动态扩容,从而:可对某个字符修改(而不是像字符串常量一样不可修改)、也可将字符串视为bit串对某位进行位操作,可以常数时间知道字符串长度、预分配和惰性释放可减少内存分配和释放次数。在实现上类似于Java ArrayList采用预分配内存的方式减少频繁分配,扩容方式:若字符串长度小于1M则加倍,否则多扩1M,字符串最大长度为512M。
二进制安全:用len记录实际长度而非像C那样根据结束符来标记字符串结尾,从而是二进制安全的(不用担心读取或输出数据时二进制数据被结束符截断)。字符串在Redis内部是二进制安全的,可以包含任何数据,如视频、图片、其他文件等或者序列化的对象,一个键最大能存储512M的值(二进制安全:只关心二进制化的字符串而不关心具体格式,只会严格按照二进制的数据存取,不会妄图以某种特殊格式解析数据,如不会像C语言一样将 \0 视为字符串结尾,因此C不是二进制安全的)
存储非字符串数据:String类型也可以用来存储整数、浮点数等数值(其实Redis内部仍当成String存储,但也提供了incr等针对数值的操作),还可以存储用户信息如JSON对象等(写/读时用户负责序列化/反序列化)。
不负责字符编解码:Redis不关心字符串以什么格式编码,其内部存储时就是存储字节数组,故客户端(Terminal、Java等)在存取时需要负责字符串和字节数组间的编解码。
上面说了一大堆,实际上,Redis的String是基于所谓的SDS,Simple Dynamic String 实现的,SDS就是C中的动态分配内存加上字符串长度的管理。源码很简单,可参阅 https://github.com/antirez/sds/blob/master/sds.h#L36。上面的一堆结论都可以从源码上找到原因,比如:
为什么是512?因为用了SDS中 sdshdr32 类型字符串,其用 uint32_t 来表示字符串长度。
3.2、List
lpush、lpushx、rpush、rpushx、lpop、rpop、lindex、lset、linsert
llen、lrange、ltrim、lrem
blpop、brpop
rpoplpush
内部用双向链表实现,因此可以作为队列、栈等使用。消息队列的四大作用:解耦使得交互简化、异步使得响应变快、流量削峰/缓存。
注:对于List,index从0起且是从push的那一头开始算的,即最后一个入队的元素的index始终为0,另一头则为n-1。
3.3、Hash
hset、hsetnx、hget、hgetall、hmset、hmget、hexists、hdel、hincrby、hincrbyfloat
hlen、hstrlen、hkeys、hvals、hscan
内部用字典实现。
3.4、Set
sadd、srem、spop、srandmember、smove
scard、smembers、sismember、sscan
sinter、sinterstore、sunion、sunionstore、sdiff、sdiffstore:集合交、并、差集操作
内部用 intset 或 hashtable 实现。当数据都是整数且个数少于512(可配置)时用前者否则用后者。
3.5、Sorted Set(ZSet)
(默认排序为升序,加rev则表示降序)
zadd、zrem、zscan
zscore、zincrby:score操作
zrank、zrevrank:根据数据查排名
zcard、zrange、zrevrange、zremrangebyrank:根据排名查数据
zcount、zrangebyscore、zrevrangebyscore、zremrangebyscore:据权重范围搜索
zlexcount、zrangebylex、zrevrangebylex、zremrangebylex:据值字典范围搜索。各元素权值必须相同!如果有序集合中的成员权值有不一致的,返回的结果就不准。
zinterstore、zunionstore
包含 数据、分数、排名 三个主题,两两间组合,故有 根据数据查分数(zscore)或排名(zrank)、根据分数查数据(zrangebyscore)或排名、根据排名查数据(zrange)查分数。
内部用hashtable + 跳跃表实现,为何不用红黑树等多叉树而用跳表实现?考虑应用场景(内存还是磁盘)、查询类型。
两者效率都很高,在大数据量场景下树层数少、跳表层数多,故对于有IO场景的存储前者更适合(这也是MySQL为何用B+树而不用跳表的一种原因)、对于内存存储两者都可行,但后者实现上更简单、内存占用更少、且范围查询时定位到头尾节点后一次遍历即可而树需要中序遍历且若未改造树则中序遍历不好做。
适合做优先队列使用,如可以用于排行榜等场景。
例如笔者借助zset实现了【时间滑动窗口计数】,实际上就是限流器,可用于各种限流场景。
简洁版:滑动窗口内的计数
private static int TIME_PERIOD_SECONDS = AuthConfigParam.captchaTriggerPeriodSeconds; private static int MAX_FAIL_COUNT_IN_PERIOD = AuthConfigParam.captchaTriggerFailCount; /** 增加指定用户在统计时间段内的登录失败次数 */ public static void addLoginFailedCountInPeriod(String customerCode, String username) { String key = generateRedisKey(customerCode, username); long score = System.currentTimeMillis(); JedisPoolClientUtil.zadd(key, score + "", score); JedisPoolClientUtil.expire(key, TIME_PERIOD_SECONDS); } /** 删除指定用户在统计时间段内的登录失败次数的记录 */ public static long delLoginFailedCountInPeriod(String customerCode, String username) { String key = generateRedisKey(customerCode, username); return JedisPoolClientUtil.del(key); } /** 获取指定用户在统计时间段内的登录失败次数 */ public static long getLoginFailedCountInPeriod(String customerCode, String username) { String key = generateRedisKey(customerCode, username); double nowScore = System.currentTimeMillis(); Set<String> sets = JedisPoolClientUtil.zrangeByScore(key, nowScore - TIME_PERIOD_SECONDS * 1000, nowScore); return sets == null ? 0 : sets.size(); } /** 判断指定用户在统计时间段内的登录失败次数是否达到上限 */ public static boolean reachMaxLoginFailedCountInPeriod(String customerCode, String username) { return getLoginFailedCountInPeriod(customerCode, username) >= MAX_FAIL_COUNT_IN_PERIOD; } private static String generateRedisKey(String customerCode, String username) { return String.format("LF:%s_%s", customerCode, username);// LoginFailed mark }
更完整的实现:滑动窗口内的计数,若达到指定的上限则锁定一定时间
import java.util.stream.Collectors; import java.util.stream.Stream; import com.ss.ss.jedispool_client.JedisPoolClientUtil; import lombok.Getter; import lombok.ToString; import lombok.extern.slf4j.Slf4j; /** * 限流器,用于记录一个滑动窗口时间内事件发生的次数,该窗口表示最近一段时间的时长,该时间段的右端点始终是"现在"。<br> * <br> * 可借此实现接口限流等功能(例如“同一个用户最近十分钟内连续三次登录错误则要求输入验证码”、"同一个客户端最近一分钟内最多调用50次验证码查询接口"、"同一客户端在最近一分钟内连续输错十次验证码则锁定该验证码功能一分钟"),甚至可将此工具作为一个Timed * Lock或并发量控制器来使用。<br> * <br> * <b>注:各方法线程安全</b><br> * <br> */ @Slf4j @ToString public class RateLimitUtil { // TODO 多进程部署场景下数据的并发修改问题 // 本工具的演进过程:简单的LoginFailCountUtil(借助Redis ZSet实现)-> // 更通用的EventCountInPeriodRecoder -> 完整的RateLimiter private static final String keyPrefixForCount = "EvtCnt_"; private static final String keyPrefixForLock = "EvtLK_"; /** 特殊值以表示事件不做最大次数的限制 */ public static final int MAX_COUNT_LIMIT_DISABLED = -1; /** 特殊值以表示事件到最大次数时不执行禁用操作 */ public static final int LOCK_OPT_DISABLED = -1; /** * 根据给定的配置创建一个实例 * * @param periodSeconds 滑动窗口时长,表示最近一段时间的时长 * @param maxCountInPeriod 滑动窗口内允许的事件发生的最大次数。值为0或负数时表示不限制 * @param lockSecondsIfReachMax 禁用时长,表示当达到最大次数时,将进入禁用状态以不允许继续增加事件次数,该状态的时长。值为0或负数表示不禁用 * @param eventType 事件类型,表示此事件记录器记录的是哪种事件。在内部将被作为keyPrefix * @param eventTypeDesc 事件类型描述,如"获取验证码"、"校验验证码"、"加锁"等 * @return */ public static RateLimitUtil with(int periodSeconds, int maxCountInPeriod, int lockSecondsIfReachMax) { // 参数校验 if (periodSeconds <= 0) { throw new RuntimeException("periodSeconds should be positive"); } if (maxCountInPeriod <= 0) { maxCountInPeriod = MAX_COUNT_LIMIT_DISABLED; } if (lockSecondsIfReachMax <= 0) { lockSecondsIfReachMax = LOCK_OPT_DISABLED; } RateLimitUtil instance = new RateLimitUtil(); instance.periodSeconds = periodSeconds; instance.maxCountInPeriod = maxCountInPeriod; instance.lockSeconds = lockSecondsIfReachMax; log.info("init done: {}", instance.toString()); return instance; } @Getter private int periodSeconds; @Getter private int maxCountInPeriod; @Getter private int lockSeconds; private RateLimitUtil() { } /** 增加一次指定事件在最近一段指定时长内的发生次数。若该时长内该事件次数已达上限则添加失败,否则添加成功,返回值表示是否添加成功 */ public synchronized boolean addCountInPeriod(String... eventId) { if (reachCountLimitInPeriod(eventId)) { return false; } long nowScore = System.currentTimeMillis(); String keyForCount = generateRedisKey(keyPrefixForCount, eventId); JedisPoolClientUtil.zadd(keyForCount, nowScore + "", nowScore);// 增加事件 JedisPoolClientUtil.zremrangeByScore(keyForCount, 0, nowScore - periodSeconds * 1000);// 将早于统计时间段的事件删除 JedisPoolClientUtil.expire(keyForCount, periodSeconds);// 借此实现"整个时间段内无该事件时数据自动清除"的效果 if (lockSeconds != LOCK_OPT_DISABLED && reachCountLimitInPeriod(eventId)) {// 锁定 String keyForLock = generateRedisKey(keyPrefixForLock, eventId); JedisPoolClientUtil.set(keyForLock, nowScore + "", "nx", "ex", lockSeconds); } return true; } /** 删除指定事件在最近一段指定时长内的发生次数的记录 */ public synchronized long clearCountInPeriod(String... eventId) { if (inDisabled(eventId)) {// 被禁用时不允许操作 return 0; } else { String keyForCount = generateRedisKey(keyPrefixForCount, eventId); return JedisPoolClientUtil.del(keyForCount); } } /** * 修改滑动时间窗口长度。若新长度比原长度短则对于减少的时间区间(区间右端点对齐进行比较)内的事件将被丢弃,否则不对已有的事件做任何修改。<br> * 当将本工具作为一个Timed Lock使用时,可借此方法实现修改Lock时长的目的。 */ public synchronized void updatePeriod(int newPeriodSeconds) { if (newPeriodSeconds <= 0) { throw new RuntimeException("newPeriodSeconds should be positive"); } if (newPeriodSeconds < this.periodSeconds) { // 移除位于减少的时间区域内的事件 boolean lazyRemove = false; if (lazyRemove) { // do nothing。延迟更新:当使用者调用上面的的add方法时达到此效果 } else { double nowScore = System.currentTimeMillis(); String keyPattern = generateRedisKey(keyPrefixForCount, "*"); JedisPoolClientUtil.keys(keyPattern).forEach(keyForCount -> { JedisPoolClientUtil.zremrangeByScore(keyForCount, 0, nowScore - periodSeconds * 1000);// 将早于统计时间段的事件删除 }); } } this.periodSeconds = newPeriodSeconds; } /** 获取指定事件在最近一段指定时长内的发生次数 */ public long getCountInPeriod(String... eventId) { if (inDisabled(eventId)) {// 被禁用时不返回真实值而是固定的最大值 return maxCountInPeriod; } else { String keyForCount = generateRedisKey(keyPrefixForCount, eventId); // return JedisPoolClientUtil.zcard(keyForCount);因时间长度可能动态改变,故用下面的方式 double nowScore = System.currentTimeMillis(); return JedisPoolClientUtil.zcount(keyForCount, nowScore - periodSeconds * 1000, nowScore); } } /** * 判断指定事件在最近一段指定时长内的发生次数是否达到上限。达到次数上限时可能会将该事件置为禁用状态一段时间,见 * {@link #inDisabled(String...eventId) } */ public boolean reachCountLimitInPeriod(String... eventId) { return ((maxCountInPeriod != MAX_COUNT_LIMIT_DISABLED) && getCountInPeriod(eventId) >= maxCountInPeriod); } /** * 判断指定事件是否处于禁用状态(若启用了禁用功能且事件发生次数达到上限则会被设为该状态。达到次数上限是变成禁用状态的必要不充分条件)。<br> * 处于该状态时将无法继续增加事件次数(即 {@link #addCountInPeriod(String...eventId)}) */ public boolean inDisabled(String... eventId) { if (lockSeconds != LOCK_OPT_DISABLED) { String keyForLock = generateRedisKey(keyPrefixForLock, eventId); return JedisPoolClientUtil.exists(keyForLock); } else { return false; } } /** 获取指定事件禁用状态的剩余时长,单位为妙。参考{@link #inDisabled(String...eventId)} */ public long ttlOfDisabled(String... eventId) { long res = 0; if (lockSeconds != LOCK_OPT_DISABLED) { String keyForLock = generateRedisKey(keyPrefixForLock, eventId); long tmpRes = JedisPoolClientUtil.ttl(keyForLock); res = res < tmpRes ? tmpRes : res; } return res; } /** 生成key,将会将各元素值拼接在一起 */ private String generateRedisKey(String keyPrefix, String... eventId) { if (null == eventId) { throw new RuntimeException("eventId should not be null"); } for (String s : eventId) { if (null == s) { throw new RuntimeException("element in eventId should not be null"); } } StringBuilder builder = new StringBuilder(); builder.append(keyPrefix); builder.append(Stream.of(eventId).collect(Collectors.joining("_"))); return builder.toString(); } }
用于:同一用户近1分钟内三次登录密码错则要输验证码、客户端近一分钟内最多调用50次验证码接口、客户端近一分钟内连续10次验证码错则锁定其验证码申请1分钟。
3.5.1、geo
geoadd
geopos
geodist
georadius
georadiusbymember
geohash
内部用Sorted Set实现
4、常用命令
command help
- command:获取所有命令
- help xx:查看指定命令的用法
To get help about Redis commands type:
"help @<group>" to get a list of commands in <group>
"help <command>" for help on <command>
"help <tab>" to get a list of possible help topics
"quit" to exit
To set redis-cli preferences:
":set hints" enable online hints
":set nohints" disable online hints
Server
./redis-cli -h host -p port -a password:以指定密码登录到指定host:port上的redis
auth password:验证密码,成功后才能进行其他命令操作
ping:测试当前连接是否存活
quit:退出连接
echo message:打印message
info:获取服务器的相关信息
time:服务器时间
config get pattern:获取服务端配置信息
config get/set/rewrite/set/resetstat:服务器配置相关
client list/getname/setname/pause/kill:管理客户端连接
role:获取主从实例所属的角色
slaveof host port:将当前服务器变为指定服务器的从属服务器
debug segfault:让Redis服务崩溃,服务会死,需要重新启动
monitor:实时打印Redis服务器接收的命令
slowlog subcommand:管理redis的慢日志
key
keys pattern:列出所有key,如 keys * 、keys nam*
randomkey:随机选择一个key
type key:查看key存储的数据类型
exists key [key ...]:确认key是否存在
del key [key ...]:删除key及其数据
rename key newkey,renamenx key newkey:重命名key,前者newkey存在则会被覆盖、后者则newkey不存在时才重命名。
debug object key:获取指定key的调试信息
TTL:
expire key seconds(pexpire key millseconds):设置一个key的多久后过期
expireat key second-timestamp(pexpireat key millisecond-timestamp) :设置key在指定时间过期
ttl key(pttl key):查看剩余存活时间,返回:-2为key不存在了、-1为未设置过期时间、其他为剩余存活时间。ttl、pttl区别在于单位为s、ms
persist key:移除设置的过期时间
Serialize and Deserialize:
dump/restore key:序列化/反序列化给定key的key-value数据并返回序列化/反序列化结果值。可用于迁移部分数据而不用迁移整个数据库
DB
select dbIndex:设置所在的数据库,默认为0。默认配置下最多16个即值为[0,15],如select 2 后提示就变成了 127.0.0.1:6379[2]>
move key dbIndex:将当前数据库的某个数据移动到其他数据库,源数据库上的该key数据就不存在了
dbsize:返回当前数据库中key的数量
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
恢复与备份
save:数据备份,即把内存数据持久化到磁盘,默认保存到的文件名为dump.rdb;如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
bgsave:在后台异步保存当前数据库的数据到磁盘
lastsave:返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 时间戳格式表示
shutdown:异步保存数据到磁盘,并关闭服务器
bgrewriteaof:异步执行一个 AOF(Append Only File) 文件重写操作。
其他:
Redis 提供三种将客户端多条命令打包发送给服务端执行的方式:Pipeline、事务、Lua脚本
5、使用
5.1、发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的消息源。
命令:
publish:向指定channel发布消息
subscribe、unsubscribe、psubscribe、punsubscribe:前两个订阅或退订若干个精确指定的channel,后两者可以模糊匹配channel
pubsub:查看发布订阅系统相关状态,如pubsub channels
5.2、事务
(严格来说不算事务,因为不保证组合操作的原子性,只能算是一种批量操作。中间某条指令的失败不会导致前面已做指令的回滚、也不会造成后续的指令不做,但会保证其他客户端命令不会中间插进来执行。)
原理:所有的指令在 exec 之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到 exec 指令,才开执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入服务端中的队列缓存而不执行。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败不会回滚,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中,也就不会打断当前事务中命令的执行。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
命令:
multi、exec、discard、watch、unwatch
示例:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
关于Jedis Transaction、Pipeline等的使用可参阅:http://www.blogways.net/blog/2013/06/02/jedis-demo.html
慎用 Redis 事务,因其不支持回滚,且集群版本要求一个事务操作的key必须都在同一slot上(可用hashtag功能解决)。
5.3、脚本
跟事务一样也是一种批量操作的方式,不保证组合原子性因为出错不会滚。
script load:加载lua脚本到服务器(不执行),得到一个sha hash值。示例:SCRIPT LOAD "return 'hello moto'"
script exist:检查服务器是否存在指定sha hash值的lua脚本
script debug:Set the debug mode for executed scripts
script flush:清除所有lua脚本
script kill:杀死尚未执行写操作的正在执行的lua脚本
evalsha:执行指定lua脚本
eval:加载并执行lua脚本。从 Redis 2.6.0 版本开始,通过内置的 Lua 解释器,可以使用 EVAL 命令对 Lua 脚本进行求值。script 参数是一段 Lua 5.1 脚本程序,它会被运行在 Redis 服务器上下文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
Java执行Lua脚本示例:
public class RedisQueueSample { private Jedis jedis; private static String lua_script = "local n = redis.call('LLEN', KEYS[1]) - 1\n" + " for i=0,n do\n" + " if redis.call( 'LINDEX', KEYS[1], i ) == ARGV[1] then\n" + " return i\n" + " end\n" + " end\n" + " return -1"; public RedisQueueSample() { this.jedis = new Jedis("localhost", 6379); this.jedis.auth("afbbf950b2e9415d:Zhy973526"); } public Object getIndex(String value) { jedis.scriptLoad(lua_script); Object object = jedis.eval(lua_script, 1, "sensestudy:client", value); return object; } public static void main(String[] args) { RedisQueueSample test = new RedisQueueSample(); System.out.println(test.getIndex("{\"test2\"}")); } }
6、其他
6.1、基数计算(HyperLogLog,HLL)
HyperLogLog:Redis 在 2.8.9 版本添加了 HyperLogLog 结构,用来做基数统计。
优点:固定的时间、空间复杂度。在输入元素的数量或者体积非常非常大时,计算基数所需的时间、空间总是固定的、并且是很小的,而不会随着输入数据的增加而变大。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算最大近 2^64 个不同元素的基数(且误差率小于1%),这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
缺点:因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
命令:pfadd、pfcount、pfmerge、pfselftest、pfdebug
原理:(详见 https://blog.csdn.net/firenet1/article/details/77247649)利用了统计学原理,用局部信息估计总体。
原理示意图:
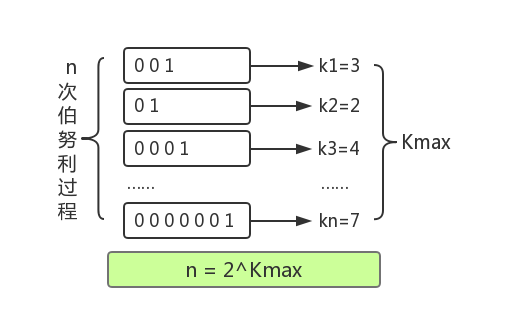
对于过程 “连续抛硬币直到第一次出现正面时停止,此时抛掷的次数为k”,进行n次这样的过程,则可以用kmax来估计n:即n≈2 ^ kmax ,由于是估计故通常输入的数据量越大越准确。
HyperLogLog算法基于上述原理,从待估基数的集合中的取样出若干元素,将每个元素(通过hash等)转成比特串并得到每个比特串中从低位起第一个1出现的位置(即k),从而得到kmax ,这样就估算出集合中元素基数。
为了减少偶然因素的影响,通常会对取出来的数据分组,分别得到各组估算的基数,再对各基数求均值(HLL用了调和平均)。
Redis中HLL的实现,可参阅源码 https://github.com/redis/redis/blob/unstable/src/hyperloglog.c。
6.2、持久化
Redis 有RDB、AOF两种持久化,可同时使用。
The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
the AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset.
rdb(Redis Database):在指定的时间生成内存数据集的快照(point-in-time snapshot)到一个文件中
Redis 对于数据备份是非常友好的, 因为你可以在服务器运行的时候对 RDB 文件进行复制: RDB 文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的 RDB 文件时, 它先将文件内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才原子地用临时文件替换原来的 RDB 文件。这也就是说, 无论何时, 复制 RDB 文件都是绝对安全的,而不会得到一个中间状态的半成品数据库。
优缺点(从保存、恢复、文件大小、持久化完整性、实时性考虑):
优点:从文件恢复成数据库时速度比aof快、保存后的文件小(内容紧凑,非常适合备份、全量复制的场景)
缺点:相比aof保存更耗时因为aof只要append一个指令而已、相比aof更容易丢失数据(两次保存之间发生故障时,前一次保存后做的改变丢失)、实时性低
原理:
阻塞客户端操作请求直到全量持久化完成,会导致阻塞时间太长故不可取 ->
允许客户端操作请求和数据持久化同时进行,会导致数据一致性太差故不可取 ->
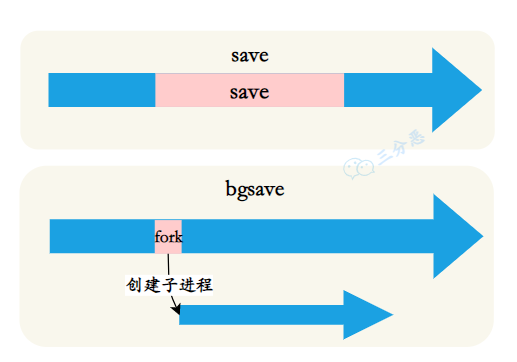
阻塞客户端操作请求直到在内存中复制一份全量数据完成,之后由其他线程基于复制的数据进行持久化。原理是这样,但实现上直接创建个子进程去做数据持久化即可而不用显式复制数据,因为:1 Linux OS fork子进程时会将原有进程内存复制一份,且是 2写时复制的(父或子进程对该内存有写操作时才会真正复制内存),因此效率很高。当持久化到临时文件完后,原子性地替换原rdb文件。
实际上,Redis支持第一种和第三种,即save、bgsave
aof(Append Only Log):记录服务器执行的所有写操作命令(append到日志文件),并在服务器启动时,通过重新执行这些命令来还原数据集。Redis还会在后台自动重写aof内容以只保存恢复当前数据集所需的最小指令集合。
AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。很像MySQL例的redo log。
优缺点:可以视为与上相反。文件更大、恢复更慢,但保存快、不易丢失数据(数据完整性更好)、实时性高。
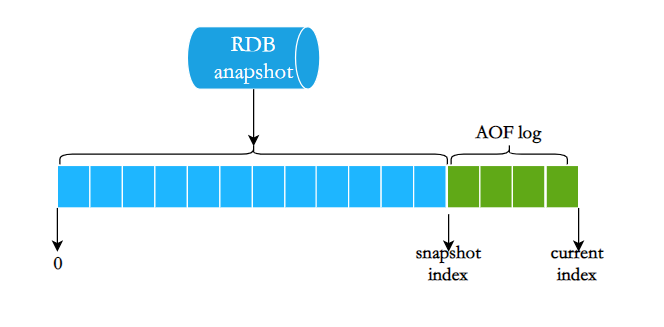
混合持久化(rdb+aof):根据持久化数据恢复到内存时,纯靠aof慢导致启动慢、纯靠rdb数据不完整,为解决该问题Redis4.0有了两者结合的混合持久化。即把rdb快照时间点到当前时间点这期间的aof日志(即所谓的增量日志)也保存到rdb文件中,这样要恢复数据时直接使用该文件即可。
用哪种?
- 一般来说, 如果想达到足以媲美数据库的数据持久性,应该同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载入 AOF 文件来恢复原始的数据,因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
- 如果 可以接受数分钟以内的数据丢失,那么可以 只使用 RDB 持久化。
- 有很多用户都只使用 AOF 持久化,但并不推荐这种方式,因为定时生成 RDB 快照(snapshot)非常便于进行数据备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,除此之外,使用 RDB 还可以避免 AOF 程序的 bug。
- 如果只需要数据在服务器运行的时候存在,也可以不使用任何持久化方式。
如何恢复数据到内存?
rdb或aof文件复制到Redis数据目录下,启动redis-server就行,会判断:
若用了混合持久化则加载rdb文件;
否则:
若开启aof且aof文件存在则优先加载aof文件,否则加载rdb文件;若文件存在则启动成功,否则启动失败并打印错误信息。
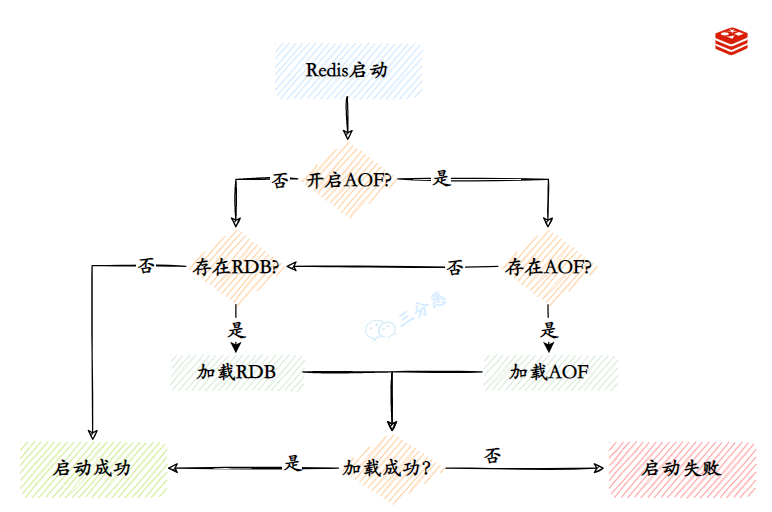
更多详情可参阅:https://my.oschina.net/davehe/blog/174662
6.3、性能测试
redis自带性能测试工具(src目录下): redis-benchmark [option] [option value]
7、实践
7.1、Jedis与JedisPool
Jedis是线程不安全的,因此在多线程使用同一个Jedis instance进行操作时可能出错;而JedisPool则是线程安全的。
Jedis示例:
使用Jedis java客户端,当redis server重启后,jedis客户端不会发现连接已断(jedis.isConnected仍为true),解决:客户端捕获异常手动关闭连接,并重建连接:
public class JedisClientUtil { private static Jedis jedis = null; /** 获取新连接 */ private static Jedis getNewJedisInstance() { Jedis jedis = new Jedis(CommonConfigParam.redisHost, CommonConfigParam.redisPort); if (null != CommonConfigParam.redisPwd && !CommonConfigParam.redisPwd.equals("")) { jedis.auth(CommonConfigParam.redisPwd); } return jedis; } /** 更新jedis client以应对redis server关闭或重启等情况 */ private static synchronized Jedis renewSharedJedisClient() { if (null == jedis) { jedis = getNewJedisInstance(); } else if (!jedis.isConnected()) { jedis.close(); jedis = getNewJedisInstance(); } return jedis; } public static String psetex(final String key, final long ttlMs, final String value) { renewSharedJedisClient(); String res = null; try { res = jedis.psetex(key, ttlMs, value); } catch (JedisConnectionException e) {// redis server关闭或重启时,连接着的jedis client未收到通知(isConnected仍为true),故手动关闭之。后面的方法同此 jedis.close(); e.printStackTrace(); } return res; } public static String get(final String key) { renewSharedJedisClient(); String res = null; try { res = jedis.get(key); } catch (JedisConnectionException e) { jedis.close(); e.printStackTrace(); } return res; } public static Long llen(String key) { renewSharedJedisClient(); Long res = null; try { res = jedis.llen(key); } catch (JedisConnectionException e) { jedis.close(); e.printStackTrace(); } return res; } public static Long lpush(final String key, final String... values) { renewSharedJedisClient(); Long res = null; try { res = jedis.lpush(key, values); } catch (JedisConnectionException e) { jedis.close(); e.printStackTrace(); } return res; } public static Object eval(String script, int keyCount, String... params) { renewSharedJedisClient(); Object res = null; try { res = jedis.eval(script, keyCount, params); } catch (JedisConnectionException e) { jedis.close(); e.printStackTrace(); } return res; } private static ThreadLocal<Jedis> threadLocalJedisInstance = new ThreadLocal<>();// brpop等不能与其他llen等共用一个连接,否则阻塞数据互相影响,故在另外线程中block,用threadlocal /** * 此操作不能与其他llen等共用一个连接,否则阻塞数据互相影响,因此这里为每个调用者线程创建一个独立的Redis连接。阻塞获取值(调用者线程会阻塞):超时时间设为0表示一直阻塞;连接异常时返回null,否则返回两个值分别为key、value */ public static List<String> brpop(int timeout, String key) { if (null == threadLocalJedisInstance.get()) { threadLocalJedisInstance.set(getNewJedisInstance()); } else if (!threadLocalJedisInstance.get().isConnected()) { threadLocalJedisInstance.get().close(); threadLocalJedisInstance.set(getNewJedisInstance()); } try { return threadLocalJedisInstance.get().brpop(timeout, key); } catch (JedisConnectionException e) { threadLocalJedisInstance.get().close(); e.printStackTrace(); return null; } } /** 此操作不能与其他llen等共用一个连接,否则阻塞数据互相影响,因此这里为每个调用者线程创建一个独立的Redis连接。调用者线程会阻塞 */ public static void subscribe(JedisPubSub jedisPubSub, String... channels) { if (null == threadLocalJedisInstance.get()) { threadLocalJedisInstance.set(getNewJedisInstance()); } else if (!threadLocalJedisInstance.get().isConnected()) { threadLocalJedisInstance.get().close(); threadLocalJedisInstance.set(getNewJedisInstance()); } try { threadLocalJedisInstance.get().subscribe(jedisPubSub, channels); } catch (JedisConnectionException e) { threadLocalJedisInstance.get().close(); e.printStackTrace(); } } }
JedisPool示例:
/** * * is be thread-safe * * @author zsm * */ public class JedisPoolClientUtil { private static JedisPool jedisPool = null; static { jedisPool = getNewJedispoolInstance(); } public static JedisPool getNewJedispoolInstance() { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // // 连接超时时是否阻塞,false时报异常,ture阻塞直到超时, 默认true // jedisPoolConfig.setBlockWhenExhausted(true); // // 逐出策略(默认DefaultEvictionPolicy(当连接超过最大空闲时间,或连接数超过最大空闲连接数)) // jedisPoolConfig.setEvictionPolicyClassName("org.apache.commons.pool2.impl.DefaultEvictionPolicy"); // // // 最大空闲连接数, 默认8个 // jedisPoolConfig.setMaxIdle(8); // // // 最大连接数, 默认8个 // jedisPoolConfig.setMaxTotal(8); // // // 获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, 默认-1 // jedisPoolConfig.setMaxWaitMillis(-1); // // // 逐出连接的最小空闲时间 默认1800000毫秒(30分钟) // jedisPoolConfig.setMinEvictableIdleTimeMillis(1800000); // // // 最小空闲连接数, 默认0 // jedisPoolConfig.setMinIdle(0); // // // 每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3 // jedisPoolConfig.setNumTestsPerEvictionRun(3); // // // 对象空闲多久后逐出, 当空闲时间>该值 且 空闲连接>最大空闲数 时直接逐出,不再根据MinEvictableIdleTimeMillis判断 (默认逐出策略) // jedisPoolConfig.setSoftMinEvictableIdleTimeMillis(1800000); // // // 获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, // // 默认-1 // jedisPoolConfig.setMaxWaitMillis(100); // // // 对拿到的connection进行validateObject校验 // jedisPoolConfig.setTestOnBorrow(true); // // // 在进行returnObject对返回的connection进行validateObject校验 // jedisPoolConfig.setTestOnReturn(true); // // // 定时对线程池中空闲的链接进行validateObject校验 // jedisPoolConfig.setTestWhileIdle(true); return new JedisPool(jedisPoolConfig, CommonConfigParam.redisHost, CommonConfigParam.redisPort); } public static String psetex(final String key, final long ttlMs, final String value) { String res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.psetex(key, ttlMs, value); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static String get(final String key) { String res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.get(key); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static Long llen(String key) { Long res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.llen(key); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static Long lpush(final String key, final String... values) { Long res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.lpush(key, values); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static Object eval(String script, int keyCount, String... params) { Object res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.eval(script, keyCount, params); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static List<String> brpop(int timeout, String key) { List<String> res = null; Jedis jedis = jedisPool.getResource(); try { res = jedis.brpop(timeout, key); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } return res; } public static void subscribe(JedisPubSub jedisPubSub, String... channels) { Jedis jedis = jedisPool.getResource(); try { jedis.subscribe(jedisPubSub, channels); } catch (JedisConnectionException e) { e.printStackTrace(); } finally { jedis.close(); } } }
参数设置:
资源设置和使用:
| 序号 | 参数名 | 含义 | 默认值 | 使用建议 |
|---|---|---|---|---|
| 1 | maxTotal | 资源池中最大连接数 | 8 | - |
| 2 | maxIdle | 资源池允许最大空闲的连接数 | 8 | - |
| 3 | minIdle | 资源池确保最少空闲的连接数 | 0 | - |
| 4 | blockWhenExhausted | 当资源池用尽后,调用者是否要等待。只有当为true时,下面的maxWaitMillis才会生效 | true | 建议使用默认值 |
| 5 | maxWaitMillis | 当资源池连接用尽后,调用者的最大等待时间(单位为毫秒) | -1:表示永不超时 | 不建议使用默认值 |
| 6 | testOnBorrow | 向资源池借用连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 业务量很大时候建议设置为false(多一次ping的开销)。 |
| 7 | testOnReturn | 向资源池归还连接时是否做连接有效性检测(ping),无效连接会被移除 | false | 业务量很大时候建议设置为false(多一次ping的开销)。 |
| 8 | jmxEnabled | 是否开启jmx监控,可用于监控 | true | 建议开启,但应用本身也要开启 |
空闲资源检测:
| 序号 | 参数名 | 含义 | 默认值 | 使用建议 |
|---|---|---|---|---|
| 1 | testWhileIdle | 是否开启空闲资源监测 | false | true |
| 2 | timeBetweenEvictionRunsMillis | 空闲资源的检测周期(单位为毫秒) | -1:不检测 | 建议设置,周期自行选择,也可以默认也可以使用JedisPoolConfig中的默认配置 |
| 3 | minEvictableIdleTimeMillis | 资源池中资源最小空闲时间(单位为毫秒),达到此值后空闲资源将被移除 | 100060 30 = 30分钟 | 可根据自身业务决定,大部分默认值即可,也可以考虑使用JeidsPoolConfig中的配置 |
| 4 | numTestsPerEvictionRun | 做空闲资源检测时,每次的采样数 | 3 | 可根据自身应用连接数进行微调,如果设置为-1,就是对所有连接做空闲监测 |
参考资料:Jedis Pool资源优化--阿里云
8、原理
各数据类型的内部编码和实现
目前有8种编码类型,抽象给用户的几种数据类型(对象类型)在Redis内部可用不同的编码类型实现,对应关系如下:
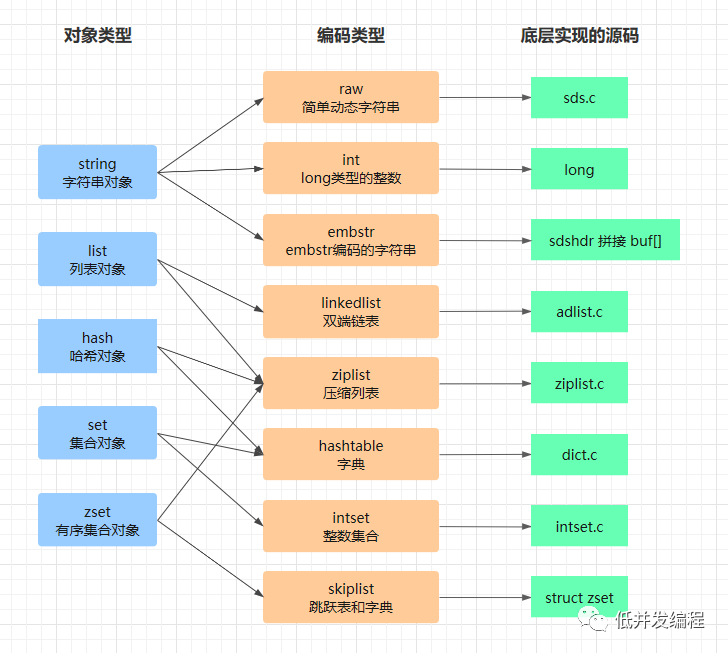
详情可参阅公众号“低并发编程”这篇文章。
sds header的定义:
struct sdshdr { unsigned int len; unsigned int free; char buf[]; };
string、list、hash、set等在Redis源码中的定义?struct redisObject:
typedef struct redisObject { unsigned type:4; // 对象类型 unsigned encoding:4; // 编码类型 void *ptr; // 值的指针 ...(省略一些不重要的字段) } robj;
以string对象在Redis内部的编码为例,用到的一些优化(详情可参阅源码redis/Object.c,不用记,从源码去看和理解非常简单!):
string的raw、emdstr编码的区别?sdshdr与redisObject在内存上是否挨在一起,挨在一起从而可减少一次内存分配操作和销毁操作、且挨在一起更能利用缓存优势,raw否emdstr是,字符串长度小于39则用后者否则用前者。
类似的,若string串可转为8个字节的长整型,则转为long类型整数存储,即所谓的int编码类型,同时与Java类似对于10000内的整数会直接使用缓存的对象从而大大减少内存占用。
其他类似,都是根据一定的条件选用不同的编码类型,以提升存储和读写效率。
编码类型
同一种数据类型在内部会根据条件动态采用不同的编码类型来实现以提高存储和读写性能。
String的编码类型
int:8 个字节的长整型
embstr:小于等于 39 字节的字符串
raw:大于 39 字节的字符串
List的编码类型
ziplist:元素个数小于 512,且所有值都小于 64 字节
linkedlist:除上述条件外
Hash的编码类型
ziplist:元素个数小于 512,且所有值都小于 64 字节
hashtable:除上述条件外
Set的编码类型
intset:元素个数小于 512,且所有值都小于 64 位
hashtable:除上述条件。key为元素值、value为null。
前者用于节省内存,但时间复杂度比后者高,不过由于元素少,故值得。
ZSet的编码类型
ziplist:元素个数小于 128,且所有值都小于 64 字节
hashtable + skiplist:除上述条件外
Redis ZSet 用 hashtable + skiplist 实现,前者key、value分别是数据、分数,后者则分别是分数、数据。以在 数据、分数、排名 三者中根据一者可查另外两者。
编码类型的实现
详情可参阅这篇文章:
ziplist:无序数组。就是用一块连续的内存来存储数据,各数据长度可不一样但是是紧密相邻存在一起的。优点是省内存,缺点是查询需要遍历、插入需要移动数据甚至要重新分配内存来扩容(都是O(n)时间复杂度)。通常在数据量较少、数据长度较小时使用。
ziplist结构: <zlbytes><zltail><zllen><entry>...<entry><zlend> ,每个entry的结构: <prevrawlen><len><data>

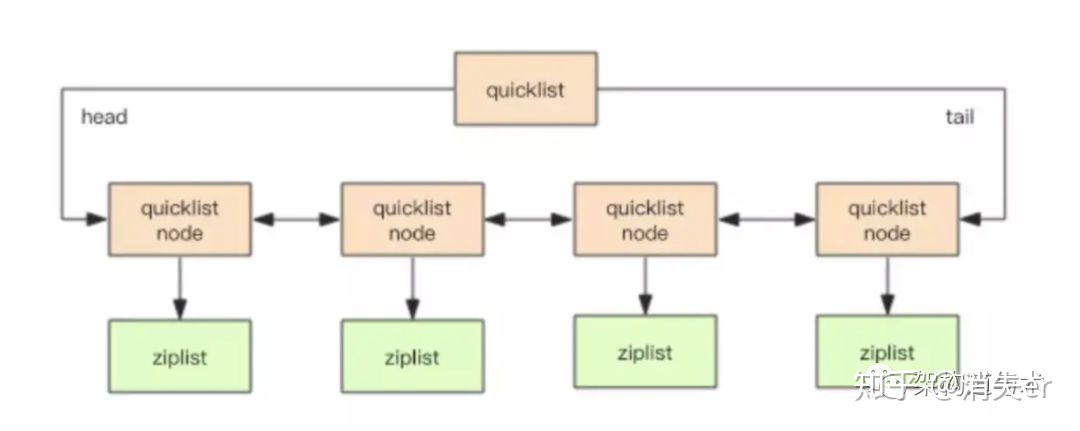
linkedlist:双向链表。早期版本是普通的双向链表,Redis3.2起实现成 quicklist,即 ziplist & linkedlist 的结合体(即数组顺序存储和链表存储的结合):与普通的双向链表不同的是,链表节点不是只存一个数据而是可将ziplist作为linkedlist的节点、且可以对不在linkedlist两端的这种ziplist节点内容进行压缩。即节点可能是普通的节点、ziplist、压缩的ziplist。有参数配置一个ziplist类型的linkedlist节点中最多包含多少个数据项、最多包含多少字节的数据,也有参数配置两端多少节点不能被压缩。
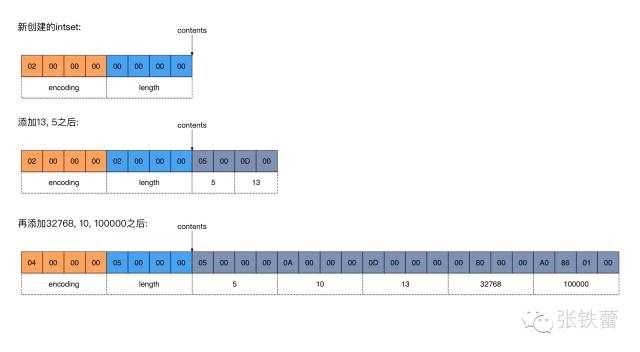
intset:有序数组,二分查找。header(用于表示1个元素的字节数、元素个数)+ content(各元素的字节内容),小端存储。
hashtable:即字典dic,实现几乎与Java中HashMap的桶链法一样,不同之处在于这里加倍扩容后rehash时不是一蹴而就而是增量hash(incremental hash),以免rehash时耗时太长阻塞其他请求。
incremental rehash:
两个表表示原表和rehash目标表、rehashIndex记录下一次要rehash的原表桶位置、通过rehashIndex是否-1判断是否正在rehash、当原表元素个数为0则rehashIndex变为-1、每次rehash一个桶(为空则跳过,可配置最多跳过空桶个数)、rehash全完成时用新表替换原表且新表置NULL。在增删改查时若没有别人在迭代则顺便rehash。
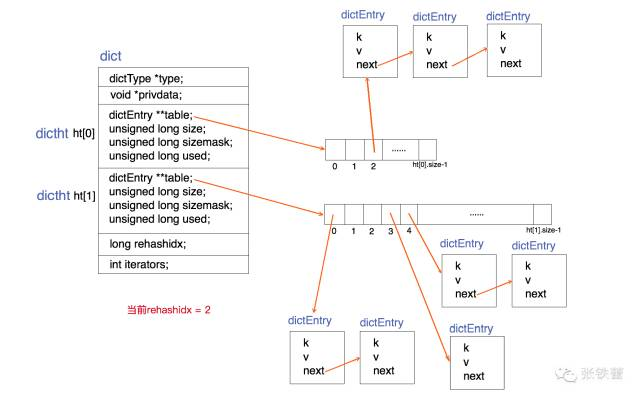
查询时若无在rehash则查原表否则都查;增时若无在rehash则插入原表否则插入到新表;删时若无在rehash则从原表删否则两表都删;修改时先插入,元素已存在则插入失败此时再查出来更新。
虽然采用双表,但本质上与Java HashMap的单表一样因为后者是扩容时创建新表、一次全rehash、替换原表;而前者因为要增量rehash所以只能把两表都保留着。实际上也可只用一张表完成扩容、增量rehash过程。
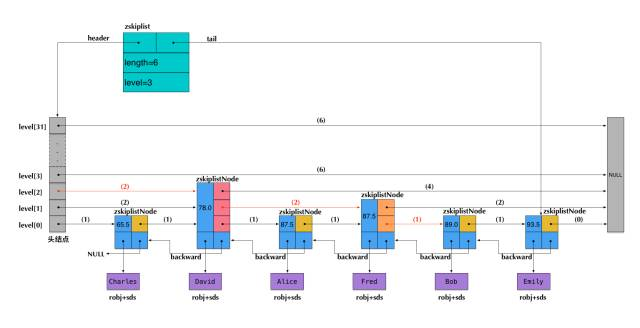
skiplist:跟普通的skiplist比,Redis中的后向指针附着了跨越的节点数 span,这样除可支持 根据分数查数据 外还可 根据分数查排名、根据排名查分数、根据排名查数据。而根据数据查分数、查排名是借助hashtable实现。
#define ZSKIPLIST_MAXLEVEL 32 #define ZSKIPLIST_P 0.25 typedef struct zskiplistNode { robj *obj; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned int span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
Redis 的IO处理模型
基于IO多路复用和Reactor模式的单线程IO处理。
只用一个线程来处理所有客户端连接和客户端命令请求和命令响应,即所谓的单线程模型(也属于IO多路复用的思想),并在连接等事件到来时交给专门的事件处理器(函数)去处理(即所谓的Reactor模式)。Java NIO中的Reactor模型本质上同理,示例可参阅 Java Reactor使用-MarchOn。
好处:这样一方面(借助IO多路复用使得)并发处理IO性能高,另一方面,(单线程模型使得)实现简单、命令间顺序执行,无需加锁和考虑线程安全问题,也没有多线程或进程创建及切换开销。
另外,也正由于redis 都是很简洁的命令,且设计的数据通信协议(见下节)很紧凑,所以一次IO的数据量不大,故很适合用多路复用IO。
与阻塞IO模型相比,使用非阻塞IO(或多路复用IO、信号驱动IO、异步IO)模型的主要目的是提高并发处理IO(用户线程不用为步骤1执行而等待)的能力,后者一般也只在IO请求量大且每个请求读写的数据量较少的场景下才比前者有优势(因为通常一个线程要处理多个就绪的IO,若数据量大则处理当前的IO太久会影响其他待处理的就绪IO,极端情况下就退化成了阻塞)
详情可参阅 Redis为什么那么快。
Redis单线程模型
严格来说Redis运行起来并非只有一个线程,一个正式的Redis Server会有其他线程或子进程,但除了主线程之外其它线程只是起辅助作用,它们是一些在后台运行做异步耗时任务(如持久化)的线程。
redis是基于单线程模型来处理数据操作请求的(javascript、redis、python异步编程都是单线程模型,单线程模型通常是用事件驱动实现的),官方提供的数据是可以达到100000+的QPS(每秒内查询次数),这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
单线程的缺点是如果存在耗时命令则会导致整个Redis实例的读写吞吐量下降,优点是实现简单且无锁故不用考虑多线程问题。
故原因:利大于弊——内存操作和CPU不是性能瓶颈,网络IO才是(使用IO多路复用提高并发了IO能力,且单线程模型使得代码实现上很简单),虽然多线程IO可提高IO吞吐量,但与单线程的优势(见上节)相比微不足道,故权衡后采用单线程。
更多可参考:Redis为什么这么快且为什么是单线程模型的。
为充分利用多核CPU,进一步提高并发IO能力,不纯是单线程,包括:
Redis6.0起允许有多个线程读取和解析命令,但执行命令仍是单线程;允许有多个IO多路复用器;服务器上持久化等功能会有多线程执行;多启几个Redis实例来利用多核CPU资源,即采用多进程-单线程架构。
现代计算机有多个CPU,如果死脑筋地只用一个线程,则无疑相当于浪费了CPU资源,因此实际场景中通常会有少量的多个线程来并发处理这些IO,即通常会有多个IO多路复用器。示例可参阅 Java Reactor使用-MarchOn,包括:
单Reactor模式:一个线程来处理连接、监听就绪事件、进行读写操作。
单Reactor的多线程模式:一个线程来处理连接、监听就绪工作,多线程来处理读写操作。
多Reactor模式:一个线程来处理连接工作,多线程来处理监听就绪及读写操作。
实际上,为了充分利用多核CPU,Redis6.0起、Java NIO、Netty 都支持多个多路复用器处理IO,它们本质相同,可见,“众纷繁技术本质相通”。
Redis 服务端客户端的通信协议
Redis 设计了一种【实现简单、对计算机来说解析速度快、对人类来说可读性强】的服务端客户端数据通信协议,称为 RESP (REdis Serialization Protocol)。
详情参阅 Redis是如何与客户端交互的。
Redis 主从复制/读写分离架构
(与MySQL的很像,万变不离其宗)
Redis 有三种运行模式:Standalone、Sentinel、Cluster,即单点、主从、集群(实际上是分布式)。
从分布式系统本质上来说,三种模式分别是【单点、主从读写分离、主备+主主】架构。主从、主备、主主的区别,可参阅分布式系统小结-marchon。
是什么
是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 主节点(master),后者称为从节点(slave)。且数据的复制是 单向 的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
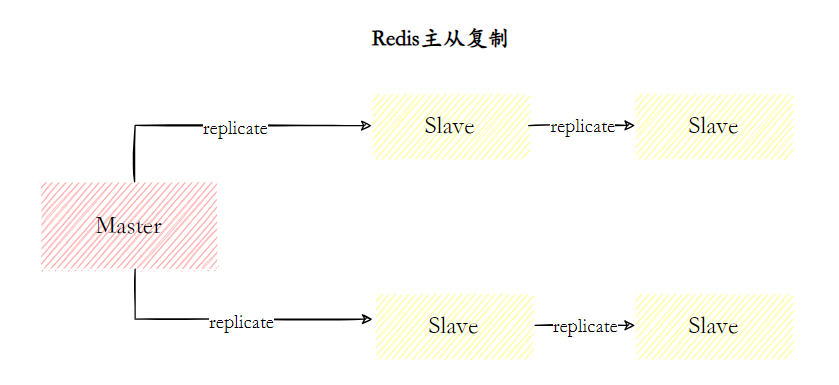
主从架构是 主从架构+哨兵集群 和 主从架构+Redis分布式 两种方案的基础。
拓扑结构
一主一从、一主多从(也称星型结构)、树状结构(由从节点复制到从节点,减少主节点同步负担)。
实际中推荐用单链表结构,减少主节点同步压力。
主从复制的原理
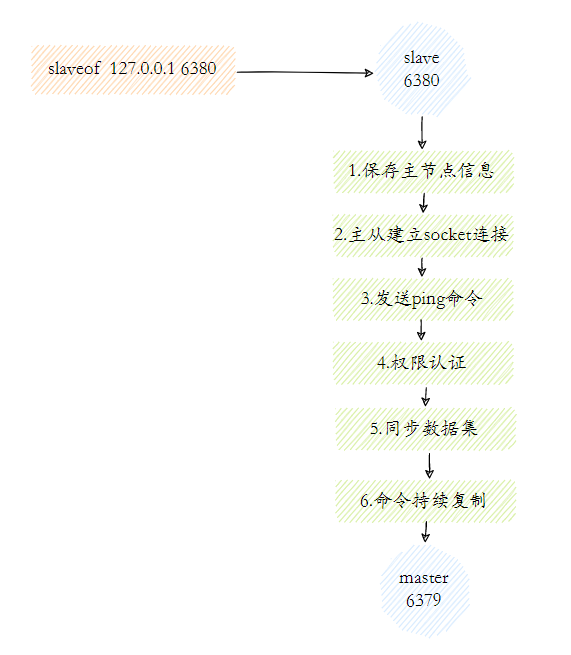
- 保存主节点(master)信息
这一步只是保存主节点信息,保存主节点的ip和port。 - 主从建立连接
从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接。 - 发送ping命令
连接建立成功后从节点发送ping请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令。 - 权限验证
如果主节点要求密码验证,从节点必须正确的密码才能通过验证。 - 同步数据集
主从复制连接正常通信后,主节点会把持有的数据全部发送给从节点。 - 命令持续复制
接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
整个主从同步过程有两种复制方式——全量复制、部分复制(增量复制)。不管是上面的同步数据集还是命令持续复制,都可能执行这两种。
(八股文如是说而已,实际上没必要专门拎出并区分这两种复制方式,因为正常还是数据集复制+命令持续复制,引入offset只是为了使得网络故障恢复时能从最近一次复制位置继续复制,即所谓的部分复制)。
全量复制用于初次复制的场景:
1 主节点执行bgsave命令生成RDB文件,然后把该文件发给从节点;
2 从节点接收该RDB文件作为自己的数据文件;
3 在主节点生成RDB文件到从节点接收完RDB文件期间,主节点还接收读写操作,这些写命令存在其aof复制缓冲区。在从节点接收完RDB文件后主节点将缓冲区内容发给从节点,以尽可能维持两节点数据一致。
4 从节点接收完上述全部数据后,清空自身内存数据并加载数据文件和aof命令执行以恢复数据到内存。
部分复制用于应对网络故障场景,根据主从节点的数据offset来复制,类似于端点续传
1 主节点的写操作复制到从节点时会优先放到复制缓冲区(默认最大1MB),从节点会记录主节点ID和从其已复制的数据的offset;
2 当主从间网络故障时主节点正常接收读写命令,待复制的写命令写入复制缓冲区;
3 当网络恢复时,从节点请求从最近成功复制的offset后的数据开始复制;
4 主节点根据offset从复制缓冲区取数据发给从节点;
主从复制的优点和存在的问题
优点:
数据冗余提高了数据可靠性;
故障时从节点顶上,提高了故障应对能力;
读写分离提高了并发处理能力。
问题:
主从延迟、网络故障等导致数据不一致;
主节点接收写任务外还要往多节点复制,网络等开销增大;这也是推荐用单链表结构的原因。
主节点单点故障问题(哨兵集群、Redis分布式集群 都可解决该问题,见下文)。
注:【主从架构+哨兵集群】、【主从架构+Redis分布式】都可解决单点故障问题,区别是后者有多个主节点存无交集的数据而前者只有一个主节点、后者主节点接受读写而前者主节点只接受写,故存储容量和并发读写能力大大提高了。
Redis 哨兵集群 Sentinel
是什么
用于解决主从复制架构中主节点的单点故障问题。本质上就是一个用于监控主从架构中多节点的健康状态、在主节点故障时选举新主节点、选举完后进行故障转移的系统。它是Redis中单独运行的节点(即哨兵节点)且也是多节点部署(高可用嘛。。)的。
(详情可参阅公众号“低并发编程”的这篇简单易懂的文章)
传统做法中,自己实现分布式系统时通常【1 借助zookeeper/consul等 + 2 节点状态监控和主节点选举逻辑】来管理分布式系统中的节点,该管理功能属于系统中的一部分,Redis Sentinel 做的就相当于这两点所做的事,只不过它没借助zookeeper/consul等协调服务来实现,而是作为独立的节点运行,即 哨兵节点(对应的,原来的master、slave叫数据节点),哨兵节点不存数据。
也即哨兵集群相当于常见的分布式系统中的元数据服务(例如HBase中的 zk+master节点)的角色。
哨兵集群的作用(单点故障解决)
数据节点监控和下线判断:每个哨兵节点周期性地给数据节点ping,若节点在设置的时间阈值 down-after-milliseconds 内无响应则认为该数据节点主观下线了;此时该哨兵节点会咨询其他哨兵节点,若系统中超过半数哨兵节点也认为下线了则是客观下线否则就未下线;客观下线的节点若是主节点则哨兵集群需要进行主节点选举。
如何监控?第一次给master节点地址并执行info命令,得到数据节点列表;取其中master节点返回的节点列表,info出去,得到响应列表;取响应列表中的master节点返回的响应列表,继续上述过程。若info出去的节点超过时间阈值无响应则故障,若故障的节点是主节点则需要进行主节点选举。
主节点是否真下线了(主观下线/客观下线)及哨兵集群主节点选举?一个哨兵节点自己认为主节点故障时(主观下线),需要咨询其他哨兵节点,半数以上的哨兵节点认为该主节点故障了才是真的故障(客观下线)。题外话,此时该哨兵节点也成为哨兵集群的Leader。
主节点选举:从有ping响应的节点列表(因主节点故障了故这些节点都是从节点)中选响应时间最短且数据复制了最多的节点作为新主节点。
故障协调处理:
通知客户端连接新主节点(客户端连的是哨兵节点从而直到新的主节点地址)进行交互。
通知其他从节点连接新主节点进行数据同步。
原主节点设置为新主节点的从节点。
哨兵集群Leader选举
为免单点故障,哨兵节点也有多个,且需要有leader角色,其内部通过Rafr选举产生。为啥主节点选举不也用Raft?太随机了,考虑不到数据复制进度等情况。
选举哨兵集群主节点的过程也是主节点客观下线的确认过程,如下:
1 每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令, 要求将自己设置为领导者。
2 收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。
3 如果该Sentinel节点发现自己的票数已经大于等于max(quorum, num(sentinels)/2+1),那么它将成为领导者。
4 如果此过程没有选举出领导者,将进入下一次选举。
Redis 分布式
是什么
(Redis中称为Redis Cluster即Redis集群。实际上叫分布式更准确,前面的主从架构才是集群。。)
主从架构存在主节点单点故障问题,【主从架构+哨兵集群】方案解决了该问题,另一种方案是【主从架构+分布式】方案。后者就是本节的内容。
注意后者中没有哨兵集群,实际上后者相当于把前者哨兵的功能搬到了各主节点上;另外,跟主从架构主节点仅写不同,这里的主节点读写都可,从节点仅当做是主节点的副本备份。
多个主从架构的主节点互相连接组成一个整体,不同主节点存无交集的数据,这些主节点构成了Redis分布式系统(Redis称之为集群Cluster),即多个主从架构的结合,形如:
从节点---| |----从节点--从节点
从节点----|主节点——主节点|----从节点--从节点
从节点---| |----从节点
因此,要考虑的是,数据分区算法(数据如何分布到不同主节点上)、系统建立(多个主节点间怎么感知彼此的存在以组成一个整体)、主节点的单点故障如何处理。
可见,这种模式的Redis系统跟我们通常理解中的分布式系统大差不差了。
--marchon
分布式系统中,实现可扩展性(节点冗余)是实现系统高可用性、数据可靠性的重要手段,因为冗余使得节点挂了备用节点可顶上、数据丢了备用节点的数据还在。这些冗余节点组成了集群,且通常是主从模式。其运行模式通常有两种:
一种是主可写从可读。比如MySQL主从复制、Redis主从复制架构。
另一种是主可读写从不可读写。比如Kafka 的 partition replacation,前面Redis 分布式模式下主从的关系。这种模式在分布式系统中很常用,从节点不提供读写,只作为主节点的备份,在主节点故障时顶上发挥作用。
可扩展性(节点冗余)下,必须思考的问题有:主节点选举、不同节点间的数据一致性等。
作用
解决主从架构的主节点单点故障问题。
多节点分别存不同数据,大大增加存储容量;
每个主节点所在的主从集群都可对外提供读写服务,大大提高了系统读写处理能力;
数据分区算法
通常有(类似于MySQL分表的算法,万变不离其宗 again):
范围路由、哈希路由(取模、一致性哈希等)、配置路由。哈希算法有几种:
取余:数据分布均匀,问题是节点增减时可能有多节点的数据要迁移。
普通的一致性哈希(无虚拟节点):节点增减时最多一个节点上的数据要迁移,问题是可能数据分布不够均匀。
带虚拟节点的一致性哈希:使得数据分布更均匀。
Redis的数据分区算法叫虚拟槽分区(slot partition),本质上就是个带虚拟节点的一致性哈希算法。
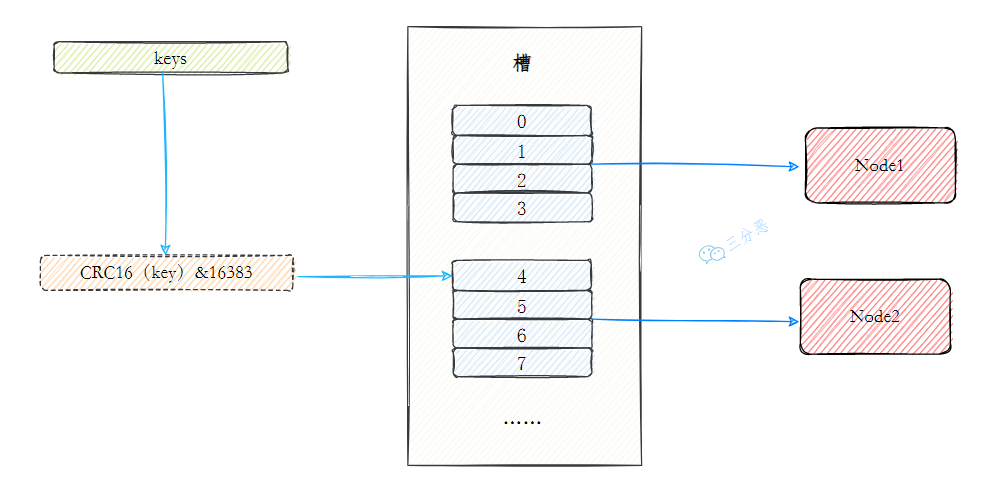
节点定位:预定义了环的大小为 2^14=16k=16384 个虚拟槽(slot),将这些槽通过 cluster addslots 命令手动分给各主节点。
可见,这实际上不符合一致性哈希的流程,因为按理节点应该通过ip哈希等手段定位到一个或若干个槽,但这里却是手动分配。节点增减时也需要运维手动去维护槽的分配关系。
疑问:槽区间与节点的映射关系保存在哪?
数据定位:哈希算法是 CRC16(key) % (2^14),2^14=16384,故即 CRC16(key) & 16383,数据存、取时根据该算法算得虚拟槽位置从而对应到某个主节点。
系统的建立
即如何让各主从架构的主节点知道其他主节点的存在,彼此如何交互以作为一个整体对外提供读写服务。主要步骤:
节点配置:通过配置 cluster-enabled yes 使每个节点(包括从节点)运行在此模式下;
节点握手:通过命令 cluster meet{ip}{port} 让主节点互相感知到其他主节点的存在并互相通信,构成一个整体。节点间是通过Gossip协议通信的,n个节点需要执行n-1次。
槽区间分配:通过命令 cluster addslots 为各主节点分配要管理的slot区间。
可见,这种模式下,系统中有哪些节点、每个节点管理哪些区间的槽都需要运维者手动设定而不自动化,很不友好。
节点的增减
增时需要通过命令【把节点加到系统、指定哪些slot对应给该新节点、并迁移数据】;删时通过命令【把该节点的slot分给其他节点、迁移数据、从系统移出该节点】。
可见,虽是“分布式系统”,但不够智能不够自动化。
单点故障解决
(实际上是把哨兵集群的功能搬到了分布式系统各主节点上,故流程与哨兵集群的非常像)
节点监控和下线判断:(跟哨兵集群的主节点类似)每个主节点周期性地给其他节点ping,若节点在设置的时间阈值 down-after-milliseconds 内无响应则认为该节点主观下线了;此时该主节点会咨询其他主节点,若系统中超过半数的主节点认为是下线了则是客观下线否则就未下线;客观下线的节点若是主节点则系统需要从该下线节点的从节点中选出新主节点。
主节点选举:从该客观下线节点的从节点中选响应时间最短且数据复制了最多的节点作为新主节点。(这里跟哨兵集群的不同)客观下线的主节点的各从节点向在线的各主节点发起投票以让自己成为新主节点,若同意者超过半数则该从节点成为新主节点并通告系统其他节点。主节点对于epoch相同的多个从节点的投票请求只会投其中一个。
详见:
slave发现自己的master不可用;
slave将记录集群的currentEpoch(选举周期)加1,并广播FAILOVER_AUTH_REQUEST 信息进行选举;
其他节点收到FAILOVER_AUTH_REQUEST信息后,只有其他的master可以进行响应,master收到消息后返回FAILOVER_AUTH_ACK信息,对于同一个Epoch,只能响应一次ack;
slave收集maste返回的ack消息
slave判断收到的ack消息个数是否大于半数的master个数,若是,则变成新的master;
广播Pong消息通知其他集群节点,自己已经成为新的master。
故障协调处理:(跟哨兵集群的主节点类似)通知连接该下线节点的客户端和其他主节点连接新主节点、通知该下线节点的其他从节点连接新的主节点进行数据同步、将该下线节点设为新主节点的从节点。
可见,下线判断、主节点选举都是少数服从多数的处理过程。
Note:
Redis 的分布式方案是不是真的分布式?严格来说不是,因为【节点需要手动添加或移除、虚拟槽需要手动分配到节点】而不能系统自动感知更新。正因为其“分布式”比较鸡肋。所以有很多管理Redis 分布式集群的实现,比如阿里的Tair。
哨兵集群和Redis分布式的异同:
同:都可解决单点故障,且解决方案中的节点监控、下线判断(都是少数服从多数)、故障处理几乎一样。
不同:单点故障解决方案中的主节点选举方式不同,一个是简单的选举一个是少数服从多数的选举;后者存储容量更多、主节点读写均可故读写并发能力更强。
https://www.cnblogs.com/z-sm/p/7400366.html:
Consul 满足CP,是强一致性,用 强一致性Raft 算法进行节点状态感知与选举。
Zookeeper 满足CP,是强一致性,用 强一致性Paxos 算法进行节点状态感知与选举。
Eureka 满足AP,是弱一致性,不用一致性算法。
Redis:
主从复制架构不满足一致性,用哨兵集群进行主节点选举(选举很简单)。
哨兵集群用 Raft 算法进行Leader选举。
分布式系统各主节点(即数据分区的各节点)间用 弱一致性算法Gossip 通信。
Redis 缓存设计相关问题
Redis等内存存储与持久层数据库(如MySQL)搭配工作时称前者为后者的缓存,缓存问题指这两者之间的数据一致性问题。
Caching Pattern
(可参阅这篇AWS文章)
两类cache pattern,通常配合使用,分别用于读、写操作时的缓存更新:
reactive approach(响应式):cache-aside(或称 lazy loading)pattern,读时用,数据被请求时缓存无该数据才将数据设置到缓存。
基本逻辑:客户端请求某个数据,后端检查,若缓存存在则返回、若不存在则查数据库并设置到缓存然后返回。
优缺点(时间换空间):优点是数据真正被需要时才会被缓存故减少不必要的内存占用;流程符合直觉、实现简单。不足是首次请求数据耗时会长点。
proactive approach(预应式):write-through pattern,写时用,数据更新到持久层后立马更新缓存。
优缺点(空间换时间):优点是缓存中与数据库中的数据更可能一致故应用性能及用户体验更好,且减少了读操作时数据库读取操作故效率更高。缺点是更新操作效率较低、且即使不频繁甚至不被读的数据也会放入缓存故空间占用多。
可见,cache-aside、write-through 是互补的关系,其优缺点也刚好互补。实际中两者配合使用,通过为缓存的数据设置过期时间来平衡两者的缺点:
写时设置的缓存如果一段时间没用就会被删除从而避免了这部分内存占用、而当该数据之后又被需要时可被读操作重新设置到缓存里。
关于 write-through 的问题:
为什么不先更新缓存再更新数据库?1是逻辑上是以数据库数据为准的故自然地认为数据库更新了数据才真正变了;2是更新数据库比更新缓存需要更多时间(想象10s、1s的区别),考虑两者间数据不一致的时间,先更新数据库再更新缓存(1s) 与 先更新缓存再更新数据库(10s) 相比显然更少。
实际中更新数据库后,在接下来更新缓存时用删除还是设置缓存(前者也即让缓存的更新交由 read 时的 cache-aside 去做了)?没法一概而论,如果是读的场景比较少则这样做可以减少不必要的内存占用;若读多则显然用设置更合适。
有时可能也会看到 read through 的概念,表示客户端读缓存时若读不到则背后由服务端去数据库查询数据并由服务端更新到缓存,这样对客户端是透明的。
写的问题(缓存更新的一致性问题和更新策略)
是什么
这里的缓存一致性问题指同一个key在 缓存中 和 数据库中 的值不一样。
原因
缓存不一致的两种主要原因:
1 删除失败。
2 并发导致写入缓存的是脏数据。例如若是先删缓存再更新数据库则在数据库更新完成前有可能旧值被其他线程读出并设置会缓存,导致不一致。
怎么办
1 选择合适的更新策略,以尽可能减少不一致的时间长:
删除缓存而不是更新缓存。因为Redis数据的删除比更新快,这样在缓存操作过程中其他线程来读到操作前的数据的可能性更低也即不一致可能性更低。
先更新数据库再删除缓存。因为这样缓存与数据库数据不一致的时间更短。此时的数据不一致的时间区间是数据库更新完到缓存删除完这段时间;若是先删除再更新数据库则有可能在数据库更新完成前其旧值又被读出且设置到缓存,从而不一致时间持续到下次更新,如此循环往复。可以以更新数据库、删除环境分别要10s、1s为例来看两方式的差别。
2 思路就是想法把缓存删了,使得数据库数据之后会被读出设置到缓存。主要有:
设置缓存过期时间。
双删:
队列双删:删除失败时key扔入队列,由专门线程去队列取出删。
延时双删:解决原因2示例的场景,即延时到更新好数据库后去删缓存。
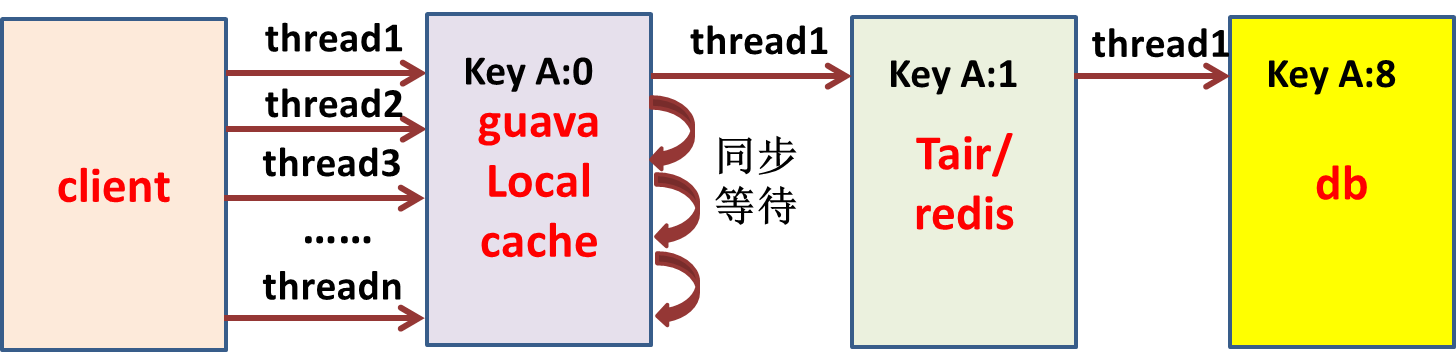
本地缓存与分布式缓存的一致性问题
在日常的开发中,我们常常采用两级缓存:本地缓存+分布式缓存。如何保证两机缓存一致?
本地缓存指服务器的内存缓存,比如HashMap/ConcurrentHashMap、Ehcache、Guava Cache、Caffeine等,分布式缓存基比如 Redis、Memcache、Tair 等。
Redis缓存,数据库发生更新,直接删除缓存的key即可,因为对于应用系统而言,它是一种中心化的缓存。但是本地缓存是非中心化的,散落在分布式服务的各个节点上,没法通过客户端的请求删除本地缓存的key,所以得想办法通知集群所有节点,删除对应的本地缓存key。
方案(与上同理,核心在于删除本地缓存):借助Redis的发布订阅模式,本地缓存各节点订阅删除事件;或者各节点设置缓存过期时间。
读的问题(缓存穿透/缓存击穿/缓存雪崩)
三种情况都会导致数据库压力大增。
缓存穿透
是什么:数据库中不存在要查的数据,故缓存中也无,从而请求都打到数据库,故缓存完全不发挥作用像不存在一样。
原因:自身业务代码问题;恶意攻击。
解决:
设置空值:第一次数据库中查不到则设置空值到缓存,以后的查询直接走缓存。
问题:太多无用的key占用内存;若数据库有值则一段时间内数据不一致(你看回到前一节的内容了)。
解决:设置过期时间;更新数据库后删除缓存。
布隆过滤器:在缓存之前加布隆过滤器。
缓存击穿
是什么:数据库中存在要查的数据而缓存中的数据过期了,大量对该key的请求打到数据库。
解决:数据不要过期;加多级缓存比如本地缓存;对多个请求进行加分布式锁控制,第一个请求从数据库查得数据后更新到数据库,这样后续请求就可命中缓存。带加锁操作的示例:
public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value; } }
缓存雪崩
是什么:缓存击穿的升级版,大量的key过期导致请求打到数据库。三大问题里最严重的,容易导致数据库宕机。
解决:热点数据不要过期;过期时间分散而不是集中一起;多级缓存;服务降级甚至熔断。
增加本地缓存除了可使得访问整体变快外,更重要的是可使中心缓存的流量高峰变得可预测。后者某种程度上来说比前者更重要。
第二个作用的例子:假如有500个Client访问Redis的同一个key,每个Client可能包含多个线程访问,则对Redis来说该key的并发量不可预测。但如果加了本地缓存则Redis该key的并发量最大为500。
注:综合以上读或写缓存的问题可发现,问题出现的直接原因是多了缓存或少了缓存从而对数据库或业务查询造成影响,其中一种解决思路就是对应地删掉或增加缓存。如:
缓存不一致是因多了缓存,解决是删掉缓存(设置过期时间或双删)。
缓存穿透是因少了缓存,解决是加缓存(设空值)。设空值导致缓存不一致,解决是删缓存(设置过期时间、更新数据库后删除缓存)。
缓存击穿是因少了缓存,解决是加缓存(设置不过期)。
缓存雪崩是因少了缓存,解决是加缓存(设置不过期、设置过期时间分散)。
内存数据管理
Redis 内存不足有这么几种处理方式:
修改可用内存大小:修改配置文件 redis.conf 的 maxmemory 参数,增加 Redis 可用内存;或通过命令set maxmemory动态设置内存上限。
修改内存淘汰策略,及时释放内存空间。
使用 Redis 集群模式,进行横向扩容。
过期数据回收策略
两种结合:
惰性删除:当查询key时才检测是否过期,已过期则删除。缺点是若key一直不再被访问则会一直占用内存不被删除。
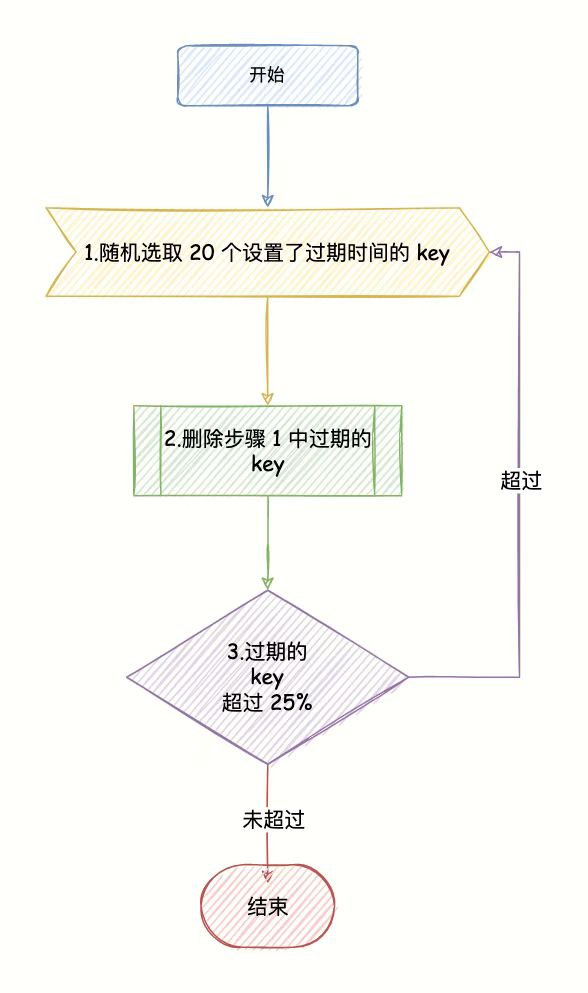
定期删除:每隔一段时间(默认100ms一次)从设置过期时间的key中随机抽20个检查是否过期,已过期的删除;随机抽删过程直到过期key比例降到25%以下或定期删除耗时超过25ms。特点:抽删、两种条件结束当次抽查、是在主线程中进行的故可能阻塞用户请求。
大量key集中过期的问题
如果有大量的key在某个固定时间点集中过期,在这个时间点访问Redis时,就有可能导致延迟增加。
Redis的过期策略采用主动过期+懒惰过期两种策略:
- 主动过期:Redis内部维护一个定时任务,默认每隔100毫秒会从过期字典中随机取出20个key,删除过期的key,如果过期key的比例超过了25%,则继续获取20个key,删除过期的key,循环往复,直到过期key的比例下降到25%或者这次任务的执行耗时超过了25毫秒,才会退出循环
- 懒惰过期:只有当访问某个key时,才判断这个key是否已过期,如果已经过期,则从实例中删除
注意,Redis的主动过期的定时任务,也是在Redis主线程中执行的,也就是说如果在执行主动过期的过程中,出现了需要大量删除过期key的情况,那么在业务访问时,必须等这个过期任务执行结束,才可以处理业务请求。此时就会出现,业务访问延时增大的问题,最大延迟为25毫秒。
而且这个访问延迟的情况,不会记录在慢日志里。慢日志中只记录真正执行某个命令的耗时,Redis主动过期策略执行在操作命令之前,如果操作命令耗时达不到慢日志阈值,它是不会计算在慢日志统计中的,但我们的业务却感到了延迟增大。
此时你需要检查你的业务,是否真的存在集中过期的代码,一般集中过期使用的命令是expireat或pexpireat命令,在代码中搜索这个关键字就可以了。
如果你的业务确实需要集中过期掉某些key,又不想导致Redis发生抖动,有什么优化方案?
解决方案是,在集中过期时增加一个随机时间,把这些需要过期的key的时间打散即可。
伪代码可以这么写:
暂时无法在飞书文档外展示此内容
这样Redis在处理过期时,不会因为集中删除key导致压力过大,阻塞主线程。
另外,除了业务使用需要注意此问题之外,还可以通过运维手段来及时发现这种情况。
做法是我们需要把Redis的各项运行数据监控起来,执行info可以拿到所有的运行数据,在这里我们需要重点关注expired_keys这一项,它代表整个实例到目前为止,累计删除过期key的数量。
我们需要对这个指标监控,当在很短时间内这个指标出现突增时,需要及时报警出来,然后与业务报慢的时间点对比分析,确认时间是否一致,如果一致,则可以认为确实是因为这个原因导致的延迟增大。
内存淘汰策略
有八种:
noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息,此时Redis只响应读操作。
只针对设置了过期时间的key:
volatile-lru:设置了过期时间的key中,最近最久未使用的淘汰,直到腾出足够空间为止,若无法腾够空间则回退到noeviction策略。
volatile-lru。
volatile-random:随机选一个设了过期时间的key删。
volatile-ttl:根据key的ttl属性,删除最快要过期数据。
针对所有数据:
allkeys-lru:按lru删,不管key有没有设置超时属性。
allkeys-lfu。
allkeys-random:随机选择key删,不管key有没有设置超时属性。
用什么策略?
用random还是lru/lfu?应用中数据若有明显冷热数据区别则用volatile的lru或lfu以进来保存热点数据,否则用radmon。
用alwaykeys还是volatile类别?若业务上有不能删的数据则用volatile类别的否则用allkeys。
正是由于内存预分配、惰性回收等原因,会产生内存碎片,所以会发现运行一段时间后占用的物理空间比数据实际大小大。Redis 自身提供了内存碎片整理功能。
9、参考资料
http://www.runoob.com/redis/redis-hyperloglog.html Redis 教程-菜鸟入门
http://redisdoc.com/index.html Redis 命令参考(官方文档翻译)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号