JPA & Spring Data JPA学习与使用小记
什么是JPA
JPA(Java Persistence API)是Java标准中的一套ORM规范,借助JPA技术可以通过注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中(即Object Model与Data Model间的映射)。
JPA之于ORM(持久层框架,如MyBatis、Hibernate等,用于管理应用层Object与数据库Data之间的映射)正如JDBC之于数据库驱动。
JDBC是Java语言定义的一套标准,规范了客户端程序访问关系数据库(如MySQL、Oracle、Postgres、SQLServer等)的应用程序接口,接口的具体实现(即数据库驱动)由各关系数据库自己实现。
随着业务系统的复杂,直接用JDBC访问数据库对开发者来说变得很繁琐,代码难以维护,为解决此问题,ORM(Object Relation Mapping)框架出现了,如MyBatis、Hibernate等,百花齐放。
爱大一统的Java又出手了,Java针对ORM提出了JPA,JPA 本质上是一种 ORM 规范,不是 ORM 框架,只是定制了一些规范,提供了一些编程的 API 接口,具体实现由 ORM 厂商实现,如Hiernate、Eclipselink等都是JAP的具体实现,主要有:

另:关于Java Persistence规范的演进(OMG、EJB1.0 CMP、EJB2.0 CMP等)可参阅:https://en.wikibooks.org/wiki/Java_Persistence/What_is_JPA%3F
JPA was meant to unify the EJB 2 CMP, JDO, Hibernate, and TopLink APIs and products
It is a standard and part of EJB3 and Java EE.
JPA主要包括Statix Named Query、Criteria Query API两部分(Query包含select、update、delete、insert等)。分为静态查询和动态查询:
静态查询在编译期即确定查询逻辑,为Static Named Query,如getByName等。
动态查询运行时确定查询逻辑,主要是Criteria API。Spring的Specification Query API对Criteria API进行了简化封装,此外Spring还提供了Example动态查询(query by example (QBE))。
使用JPA Query时与SQL Query最大的区别在于前者是面向Object Model(即定义的Java Bean)而后者是面向Data Model(即数据库表)的。
JPQL allows the queries to be defined in terms of the object model, instead of the data model. Since developers are programming in Java using the object model, this is normally more intuitive. This also allows for data abstraction and database schema and database platform independence.
Spring data JPA与JPA的关系
如上面所述,JPA是Java标准中的一套规范。其为我们提供了:
- ORM映射元数据:JPA支持通过XML和注解两种元数据形式描述对象和表间的映射关系,并持久化到数据库表中。如@Entity、@Table等
- JPA的Criteria API:提供API来操作实体对象,执行CRUD操作,框架会自动将之转换为对应的SQL,使开发者从繁琐的JDBC、SQL中解放出来。
- JPQL查询语言:提供面向Java对象而非面向数据库自动的查询语言,避免程序与SQL语句耦合
关系图:

Spring Data JPA是Spring提供的一套简化JPA开发的框架(Criteria API还是太复杂了),按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
关系图:
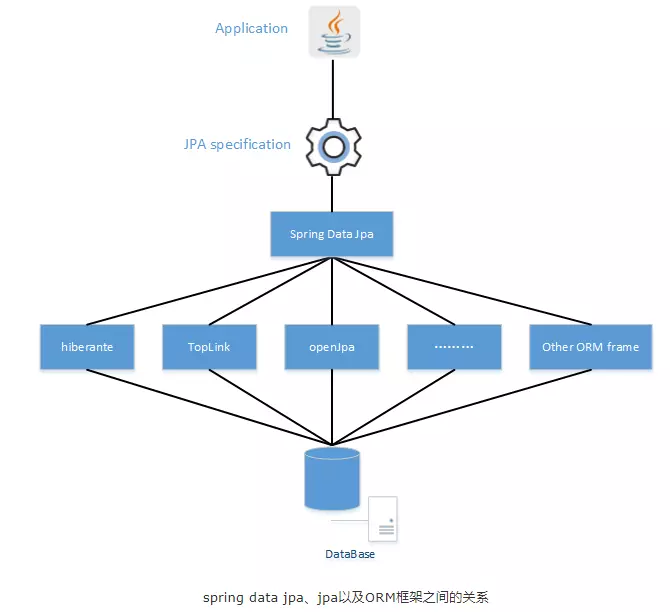
通过Repository来支持上述功能,默认提供的几种Repository已经满足了绝大多数需求:
JpaRepository( 为Repository的子接口:JpaRepository -> PagingAndSortingRepository -> CrudRepository -> Repository)
QueryByExampleExecutor
JpaSpecificationExecutor
后两者用于更复杂的查询,如动态查询、关联查询等;第一种用得最多,提供基于方法名(query method)的查询,用户可基于第一种继承创建自己的子接口(只要是Repository的子接口即可),并声明各种基于方法名的查询方法。
题外话:PagingAndSortingRepository及其继承的几个接口实际上不仅可用于Spring Data JPA,还可用于Spring Data MongoDB等,可见可复用性很好。
Spring Data JPA 其实并不依赖于 Spring 框架。
JPA注解
注解位置
通过JPA定义的Object至少需要@Entity、@Id注解,示例:


import javax.persistence.*; ... @Entity public class Employee { @Id private long id; private String firstName; private String lastName; private Address address; private List<Phone> phones; private Employee manager; private List<Employee> managedEmployees; ... ... }
这些注解的位置可以有两种(Access Type):Field(在变量上)上、Property(在变量的get方法)上。一个Ojbect内的JPA注解要么在Field上要么在Property上(当然可以在类上),不能两者同时有。详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Mapping#Access_Type
- Field:will be accessed directly to store and load the value from the database。It avoids any unwanted side-effect code that may occur in the application get/set methods.
- Property:
getandsetmethods will be used to store and load the value from the database. It allows the application to perform conversion of the database value when storing it in the object.
JPA 2.0开始允许通过@Acdess注解来指定默认access type并通过该注解来指定例外acess type,从而达到混合使用的效果。
注解使用
**@Entity**
@Entity 标注用于实体类声明语句之前,指出该Java 类为实体类,将映射到指定的关系数据库表。(类似的,使用@Document可以映射到mongodb)
应用了此注解后,将会自动将类名映射作为数据库表名、将类内的字段名映射为数据库表的列名。映射策略默认是按驼峰命名法拆分将类名或字段名拆分成多部分,然后以下划线连接,如StudentEntity -> student_entity、studentName -> student_name。若不按默认映射,则可通过@Table、@Column指定,见下面。
**@Table**
当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用
- schema属性:指定数据库名
- name属性:指定表名,不知道时表名为类名
**@id**
@Id 标注用于声明一个实体类的属性映射为数据库的一个主键列
@Id标注也可置于属性的getter方法之前。以下注解也一样可以标注于getter方法前。
若同时指定了下面的@GeneratedValue则存储时会自动生成主键值,否则在存入前用户需要手动为实体赋一个主键值。主键值类型可能是:
- Primitive types: boolean, byte, short, char, int, long, float, double.
- Equivalent wrapper classes from package java.lang:
Byte, Short, Character, Integer, Long, Float, Double. - java.math.BigInteger, java.math.BigDecimal.
- java.lang.String.
- java.util.Date, java.sql.Date, java.sql.Time, java.sql.Timestamp.
- Any enum type.
- Reference to an entity object.
- composite of several keys above
指定联合主键,有@IdClass、@EmbeddedId两种方法,可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Identity_and_Sequencing#Composite_Primary_Keys
**@IdClass**
修饰在实体类上,指定联合主键。如:@IdClass(StudentExperimentEntityPK.class),主键类StudentExperimentEntityPK需要满足:
- 实现Serializable接口
- 有默认的public无参数的构造方法
- 重写equals和hashCode方法。equals方法用于判断两个对象是否相同,EntityManger通过find方法来查找Entity时,是根据equals的返回值来判断的。hashCode方法返回当前对象的哈希码
示例:
package com.sensetime.sensestudy.common.entity; import java.io.Serializable; import java.util.Objects; import javax.persistence.Column; import javax.persistence.Id; import com.sensetime.sensestudy.common.entity.ddl.ColumnLengthConstrain; public class CustomerCourseEntityPK implements Serializable { /** * */ private static final long serialVersionUID = 1L; private String customerId; private String courseId; @Id @Column(name = "customer_id", length = ColumnLengthConstrain.LEN_ID_MAX) public String getCustomerId() { return customerId; } public void setCustomerId(String customerId) { this.customerId = customerId; } @Id @Column(name = "course_id", length = ColumnLengthConstrain.LEN_ID_MAX) public String getCourseId() { return courseId; } public void setCourseId(String courseId) { this.courseId = courseId; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CustomerCourseEntityPK that = (CustomerCourseEntityPK) o; return Objects.equals(customerId, that.customerId) && Objects.equals(courseId, that.courseId); } @Override public int hashCode() { return Objects.hash(customerId, courseId); } }
package com.sensetime.sensestudy.common.entity; import java.sql.Timestamp; import javax.persistence.Basic; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.IdClass; import javax.persistence.JoinColumn; import javax.persistence.ManyToOne; import javax.persistence.Table; import com.sensetime.sensestudy.common.entity.ddl.ColumnLengthConstrain; @Entity @Table(name = "customer_course", catalog = "") @IdClass(CustomerCourseEntityPK.class) public class CustomerCourseEntity { private String customerId; private String courseId; private Timestamp purchaseExpireTime; private Boolean isPurchaseExpire;// 由触发器自动更新 // TODO zmm 最大使用人数 private Integer maxNumber; private CourseEntity courseByCourseId; public CustomerCourseEntity() { } public CustomerCourseEntity(String customerId, String courseId, Timestamp purchaseExpireTime) { this.customerId = customerId; this.courseId = courseId; this.purchaseExpireTime = purchaseExpireTime; this.isPurchaseExpire = false; } public CustomerCourseEntity(String customerId, String courseId, Timestamp purchaseExpireTime, Integer maxNumber) { this.customerId = customerId; this.courseId = courseId; this.purchaseExpireTime = purchaseExpireTime; this.maxNumber = maxNumber; this.isPurchaseExpire = false; } @Id @Column(name = "customer_id", length = ColumnLengthConstrain.LEN_ID_MAX) public String getCustomerId() { return customerId; } public void setCustomerId(String customerId) { this.customerId = customerId; } @Id @Column(name = "course_id", length = ColumnLengthConstrain.LEN_ID_MAX) public String getCourseId() { return courseId; } public void setCourseId(String courseId) { this.courseId = courseId; } @Basic @Column(name = "purchase_expire_time", nullable = false) public Timestamp getPurchaseExpireTime() { return purchaseExpireTime; } public void setPurchaseExpireTime(Timestamp purchaseExpireTime) { this.purchaseExpireTime = purchaseExpireTime; } @Basic @Column(name = "is_purchase_expire", nullable = false) public Boolean getIsPurchaseExpire() { return isPurchaseExpire; } public void setIsPurchaseExpire(Boolean isPurchaseExpire) { this.isPurchaseExpire = isPurchaseExpire; } @Basic @Column(name = "max_number") public Integer getMaxNumber() { return maxNumber; } public void setMaxNumber(Integer maxNumber) { this.maxNumber = maxNumber; } @ManyToOne @JoinColumn(name = "course_id", referencedColumnName = "id", nullable = false, insertable = false, updatable = false) public CourseEntity getCourseByCourseId() { return courseByCourseId; } public void setCourseByCourseId(CourseEntity courseByCourseId) { this.courseByCourseId = courseByCourseId; } }
**@EmbeddedId**
功能与@IdClass一样用于指定联合主键。不同的在于其是修饰实体内的一个主键类变量,且主键类应该被@Embeddable修饰。
此外在主键类内指定的字段在实体类内可以不再指定,若再指定则需为@Column加上insertable = false, updatable = false属性
**@GeneratedValue**
@GeneratedValue 用于标注主键的生成策略,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment
- IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式
- AUTO: JPA自动选择合适的策略,是默认选项
- TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
- SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式
更多详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Identity_and_Sequencing#Sequence_Strategies
**@Basic**
表示一个简单的属性到数据表的字段的映射,对于没有任何标注的 getXxx() 方法,默认为 @Basic
fetch 表示属性的读取策略,有 EAGER 和 LAZY 两种,分别为立即加载和延迟加载
optional 表示该属性是否允许为 null,默认为 true
**@Column**
此注解不是必须的,无此字段也会将字段映射到表列。当实体的属性与其映射的数据库表的列不同名时需要使用 @Column 标注说明,其有属性 name、unique、nullable、length 等。
类的字段名在数据库中对应的字段名可以通过此注解的name属性指定,不指定则默认为将属性名按驼峰命名法拆分并以下划线连接,如createTime对应create_time。注意:即使name的值中包含大写字母,对应到db后也会转成小写,如@Column(name="create_Time")在数据库中字段名仍为create_time。
可通过SpringBoot配置参数 spring.jpa.hibernate.naming.physical-strategy 配置上述对应策略,如指定name值是什么数据库中就对应什么名字的列名。默认值为: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
**@Transient**
表示该属性并非一个到数据库表的字段的映射,ORM 框架将忽略该属性
如果一个属性并非数据库表的字段映射,就务必将其标识为 @Transient,否则ORM 框架默认为其注解 @Basic,例如工具方法不需要映射
**@Temporal**
在 JavaAPI 中没有定义 Date 类型的精度,而在数据库中表示 Date 类型的数据类型有 Date,Time,TimeStamp 三种精度(日期,时间,两者兼具),进行属性映射的时候可以使用 @Temporal 注解调整精度。目前此注解只能用于修饰java.util.Date、java.util.Calendar类型的变量,TemporalType取DATE、TIME、TIMESTAMP时在MySQL中分别对应的DATE、TIME、DATETIME类型。示例:
@Temporal(TemporalType.TIMESTAMP)
@CreationTimestamp //org.hibernate.annotations.CreationTimestamp,用于在JPA执行insert操作时自动更新该字段值
@Column(name = "create_time", updatable=false )//为防止手动set,可设false以免该字段被更新
private Date createTime;
@Temporal(TemporalType.TIMESTAMP) @UpdateTimestamp //org.hibernate.annotations.UpdateTimestamp,用于在JPA执行update操作时自动更新该字段值 @Column(name = "update_time") private Date updateTime;
@CreationTimestamp、@UpdateTimestamp是Hibernate的注解,SpringData JPA也提供了类似功能(推荐用此):@CreatedDate、@LastModifiedDate、@CreatedBy、@LastModifiedBy,可参阅https://blog.csdn.net/tianyaleixiaowu/article/details/77931903
**@MappedSuperClass**
用来修饰一个类,类中声明了各Entity共有的字段,也即数据库中多表中共有的字段,如create_time、update_time、id等。
标注为@MappedSuperclass的类将不是一个完整的实体类,他将不会映射到数据库表,但是他的属性都将映射到其子类的数据库字段中。
标注为@MappedSuperclass的类不能再标注@Entity或@Table注解,也无需实现序列化接口。
允许多级继承。
**@Inheritance**
用于表结构复用。指定被该注解修饰的类被子类继承后子类和父类的表结构的关系。通过strategy属性指定关系,有三种策略:
- SINGLE_TABLE:适用于共同字段多独有字段少的关联关系定义。子类和父类对应同一个表且所有字段在一个表中,还会自动生成(也可通过@DiscriminatorColumn指定)一个字段 varchar 'dtype' 用来表示一条数据是属于哪个实体的。为默认值(未使用@Inheritance或使用了但没指定strategy属性时默认采用此策略)。
- JOINED:子类和父类对应不同表,父类属性对应的列(除了主键)不会且无法再出现在子表中。子表自动产生与父表主键对应的外键与父表关联。同样地也可通过@DiscriminatorColumn为父类指定一个字段用于标识一条记录属于哪个子类。
- TABLE_PER_CLASS:子类和父类对应不同表且各类自己的所有字段(包括继承的)分别都出现在各自的表中;表间没有任何外键关联。此策略最终效果与@MappedSuperClass等同。
更多详情可参阅:https://www.ibm.com/developerworks/cn/java/j-lo-hibernatejpa/index.html
@Inheritance与@MappedSuperclass的区别:后者子类与父类没有外键关系、后者不会对应一个表等、前者适用于表关联后者适用于定义公共字段。另:两者是可以混合使用的。详见:https://stackoverflow.com/questions/9667703/jpa-implementing-model-hierarchy-mappedsuperclass-vs-inheritance。
总而言之,@Inheritance、@MappedSuperClass可用于定义Inheritance关系。详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Inheritance。这些方式的一个缺点是子类中无法覆盖从父类继承的字段的定义(如父类中name是not null的但子类中允许为null)。
除了 @Inheritance、@MappedSuperClass外,还有一种Inheritance方法(此法可解决上述不足):先定义一个Java POJO(干净的POJO,没有任何对该类使用任何的ORM注解),然后不同子类继承该父类并分别在不同子类中进行ORM定义即可。此法下不同子类拥有父类的公共字段且该字段在不同子类中对应的数据库列定义可不同。
实践示例:
翻译表与主表关联方案设计
多语言表(翻译表)与原表(主表)关联方案设计,需求:字段(列)复用以免重复代码定义、同一个列的定义如是否为空在不同表中可不一样(如有些字段主表中非空但翻译表中可空),有如下方案:
无关联,重复定义。pass
有关联
通过@MappeSuperclass,不同子类可以完全继承父类列定义且分别对应不同表,表结构完全相同,但不能覆盖父类的定义。pass
通过@Inheritance,三种策略:
SINGLE_TABLE:父、子类对应同一张表。子类无法覆盖父类的字段定义;源课程和翻译课程id一样,违背主键唯一约束。pass
JOINED:父、子类对应不同表且子类自动加与父类主键一样的字段与父类主键关联,但父表中除主键之外的所有字段无法在子表中再出现。pass
TABLE_PER_CLASS:父、子类对应不同表且表定义完全相同,无外键,但子类无法覆盖父类的字段定义(即同一字段在不同表中字段定义无法不同)。pass
定义个普通父类,子类继承父类并分别进行@Column定义:不同子类对应不同表,不同表含有的字段及定义可不一样。selected
注解扫描
这里针对SpringBoot而言。在SpringBoot中:
默认情况下,当Entity类、Repository类与主类在同一个包下或在主类所在包的子类时,Entity类、Repository类会被自动扫描到并注册到Spring容器,此时使用者无需任何额外配置。
当不在同一包或不在子包下时,需要分别通过在主类上加注解 @EntityScan( basePackages = {"xxx.xxx"}) 、 @EnableJpaRepositories( basePackages = {"xxx.xxx"}) 注解来分别指定Entity、Repository类的位置。
可多处使用@EntityScan:它们的basePackages可有交集,但必须覆盖到所有被Resository使用到的Entity否则会报错。
可多处使用@EnableJpaRepositories:它们的basePackages不能有交集否则会报重复定义的错(除非配置允许覆盖定义),必须覆盖到所有被使用到的Resository。
JPA对象属性与数据库列的映射
(attribute map between object model and data model)
基本类型(String、Integer等)、时间、枚举、复杂对象如何自动映射到数据库列,详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Basic_Attributes
以下是基本类型的映射:
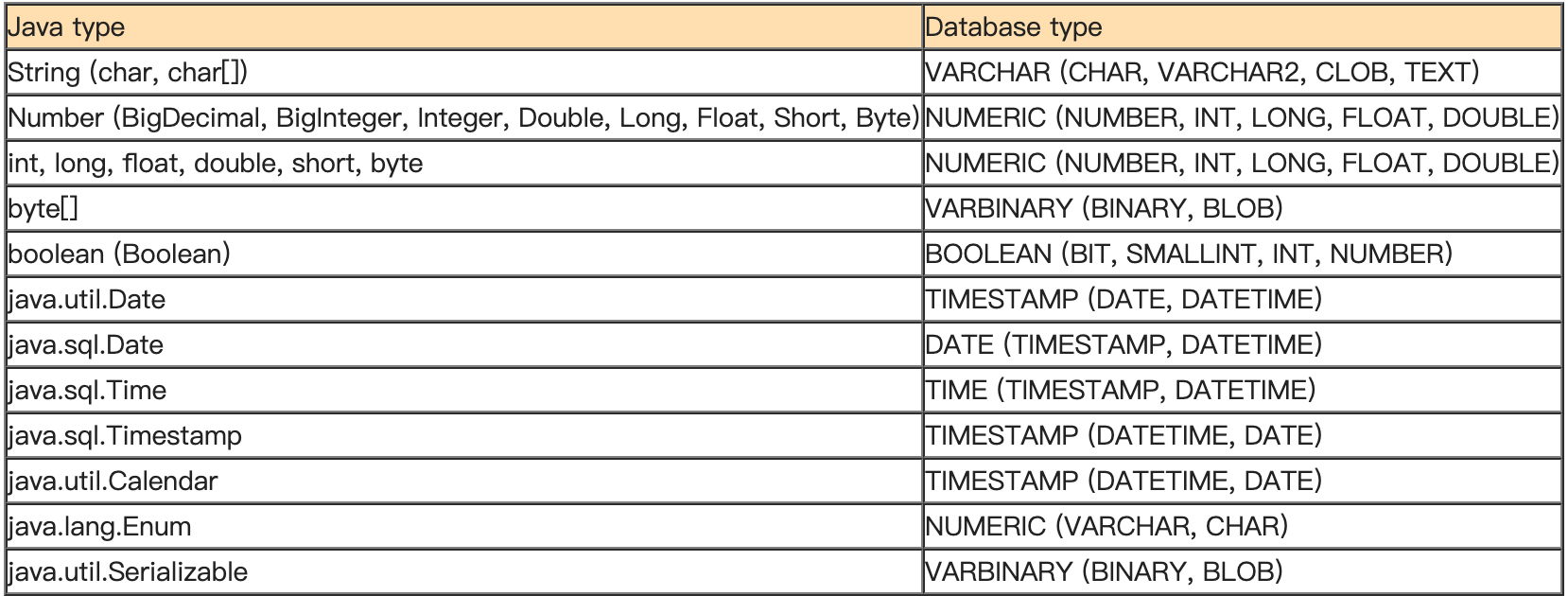
对于非基本类型的属性,其映射:
法1:
By default in JPA any
Serializableattribute that is not a relationship or a basic type (String, Number, temporal, primitive), will be serialized to aBLOBfield.
法2:JPA 2.1起可通过 @Convert 指定属性与数据库列间的映射逻辑,其可将任意对象映射到数据库的一个列(详见后文)。在这之前没有@Convert,可以通过get、set方法实现类似效果,示例:
@Entity public class Employee { ... private boolean isActive; ... @Transient public boolean getIsActive() { return isActive; } public void setIsActive(boolean isActive) { this.isActive = isActive; } @Basic private String getIsActiveValue() { if (isActive) { return "T"; } else { return "F"; } } private void setIsActiveValue(String isActive) { this.isActive = "T".equals(isActive); } }
Spring Data JPA使用小记
用法模板
1 将 spring-data-jpa 包,数据库驱动包等添加为项目依赖;
2 配置文件定义相应的数据源;
3 定义业务领域实体类,比如通过@Entity注解;
4 定义自己业务相关的的JPA repository接口,这些接口都继承自JpaRepository或者JpaSpecificationExecutor,如StudentRepository;
5 为应用添加注解@EntityScan、@EnableJpaRepositories,此步不是必须的,原因见前面的注解扫描一节;
6 将上面自定义JPA repository接口注入到服务层并使用它们进行相应的增删改查;
经过上述编写或配置后,就可以使用StudentRepository Bean了,即使没有实现该接口。
指定对象与数据库字段映射时注解的位置
如@Id、@Column等注解指定Entity的字段与数据库字段对应关系时,注解的位置可以在Field(属性)或Property(属性的get方法上),两者统一用其中一种,不能两者均有。推荐用前者。
详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Mapping
JPA命名查询的原理
基本用法:通过方法名来指定查询逻辑,而不需要自己实现查询的SQL逻辑,示例:List<Student> getByName(String name)
方法名解析原理:对方法名中除了保留字(findBy、top、within等)外的部分以and为分隔符提取出条件单词,然后解析条件获取各个单词并看是否和Entity中的属性对应(不区分大小写进行比较)。get/find 与 by之间的会被忽略,所以getNameById与getById是等价的,会根据id查出整个Entity而不会只查name字段。(指定部分字段的查询见后面条目)
查询条件解析原理:假设School和Student是一对多关系,Student中有个所属的School school字段、School有个String addressCode属性,以如下查询为例:
Studetn getByNameAndSchoolAddressCode(String studentName, String addressCode)(先说结果:JPA会自动生成条件studentName和关联条件student.school.addressCode进行查询)
- 由And分割得到studentName、SchoolAddressCode;
- 分别看Student中是否有上述两属性,显然前者有后者没有,则后者需要进一步解析(见下步)
- JPA按驼峰命名格式从后往前尝试分解SchoolAddressCode:先得到 [SchoolAdress、Code],由于Student没有SchoolAddress属性故继续尝试分解,得到[School、AdressCode];由于Student有School属性且School有addressCode属性故满足,最终得到条件student.school.addressCode。注:但若Student中有个SchoolAdress schoolAddress属性但schoolAddress中没有code属性,则会因找不到student.schoolAdress.code而报错,所以可通过下划线显示指定分割关系,即写成: getByNameAndSchool_AddressCode
查询字段解析原理:默认会查出Entity的所有字段且返回类型为该Entity类型,有两种情况可查询部分字段(除此外都会查出所有字段):
1、通过@Query写的自定义查询逻辑中只查部分字段。这种不属于直接通过方法名指定查询,这里先不讨论(见后面查询指定部分字段的条目)。
2:返回类型为自定义接口或该接口列表,接口中仅包含部分字段的get方法,此时会根据接口方法名查询部分字段。示例:
//CourseRepository.java
List<MyCustomColumns> findCustomColumnsByGroupId(String groupId);//find和By间的部分在解析时会被忽略。为了见名知意,最好加上字段信息,如findVersionByGroupId public interface MyCustomColumns {//JPA生成查询语句时只会查下面get方法中指定的字段名。需要确保Entity中有该字段名否则会报错 public String getId(); public String getVersion(); public String getGroupId(); }
在查询时,通常需要同时根据多个属性进行查询,且查询的条件也格式各样(大于某个值、在某个范围等等),Spring Data JPA 为此提供了一些表达条件查询的关键字,大致如下:
And --- 等价于 SQL 中的 and 关键字,比如 findByUsernameAndPassword(String user, Striang pwd); Or --- 等价于 SQL 中的 or 关键字,比如 findByUsernameOrAddress(String user, String addr); Between --- 等价于 SQL 中的 between 关键字,比如 findBySalaryBetween(int max, int min); LessThan --- 等价于 SQL 中的 "<",比如 findBySalaryLessThan(int max); GreaterThan --- 等价于 SQL 中的">",比如 findBySalaryGreaterThan(int min); IsNull --- 等价于 SQL 中的 "is null",比如 findByUsernameIsNull(); IsNotNull --- 等价于 SQL 中的 "is not null",比如 findByUsernameIsNotNull(); NotNull --- 与 IsNotNull 等价; Like --- 等价于 SQL 中的 "like",比如 findByUsernameLike(String user); NotLike --- 等价于 SQL 中的 "not like",比如 findByUsernameNotLike(String user); OrderBy --- 等价于 SQL 中的 "order by",比如 findByUsernameOrderBySalaryAsc(String user); Not --- 等价于 SQL 中的 "! =",比如 findByUsernameNot(String user); In --- 等价于 SQL 中的 "in",比如 findByUsernameIn(Collection<String> userList) ,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数; NotIn --- 等价于 SQL 中的 "not in",比如 findByUsernameNotIn(Collection<String> userList) ,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数;
Containing --- 包含指定字符串
StargingWith --- 以指定字符串开头
EndingWith --- 以指定字符串结尾
findByFirstnameIgnoreCase
findByActiveTrue、findByActiveFalse
findByFirstnameContaining
findByFirstnameStartingWith、findByFirstnameEndingWith
JPA 集合类型查询参数
List<StudentEntity> getByIdInAndSchoolId(Collection<String> studentIdList, String schoolId); ,关键在于 In 关键字。参数用Collection类型,当然也可以用List、Set等,但用Collection更通用,因为此时实际调用可以传List、Set等实参。
nativeQuery
Repository尽可能避免使用nativeQuery,使得与数据库字段的耦合限制在Entity内而不扩散到Repository内,更易于维护
尽可能避免在JPQL、nativeQuery中进行联表查询,而是在Service层通过JPA Specification进行动态关联查询
Repository nativeQuery返回Entity
使用nativeQuery时SQL语句查询的字段名若没as则是数据库中的字段名,如school_id,而API返回值通常是schoolId,可以在SQL里通过 school_id as schoolId取别名返回。然而若查询很多个字段值则得一个个通过as取别名,很麻烦,可以直接将返回值指定为数据库表对应的Entity,不过此法要求查询的是所有字段名,如:
@Query(value = " select t.* from teacher t where t.school_id=?1 "// 以下为搜索字段 + "and (?4 is NULL or name like %?4% or job_number like %?4% or bz like %?4% or phone like %?4% or email like %?4%) " + " order by job_number limit ?2, x?3 ", nativeQuery = true) List<TeacherEntity> myGetBySchoolIdOrderByJobNumber(String schoolId, int startIndex, Integer size, String searchNameOrJobnumOrBzOrPhoneOrEmai);// nativeQuery返回类型可以声明为Entity,会自动进行匹配,要求查回与Entitydb中字段对应的所有db中的字段
延迟加载与立即加载(FetchType)
通常可以在@OneToMany中用LAZY、在@ManyToOne/Many中用EAGER,但不绝对,看具体需要。
FetchType.LAZY:延迟加载,在查询实体A时,不查询出关联实体B,在调用getxxx方法时,才加载关联实体,但是注意,查询实体A时和getxxx必须在同一个Transaction中,不然会报错:no session。即会表现为两次单独的SQL查询(非联表查询)
FetchType.EAGER:立即加载,在查询实体A时,也查询出关联的实体B。即会表现为一次查询且是联表查询
默认情况下,@OneToOne、@ManyToOne是LAZY,@OneToMany、@ManyToMany是EAGER。
有两个地方用到延迟加载:relationship(@OneToMany等)、attribute(@Basic)。后者一般少用,除非非常确定字段很少访问到。
JPA Join查询
只有有在Entity内定义的关联实体才能进行关联查询,示例:
@Query("select cd, d from CourseDeveloperEntity cd join cd.developer d where d.nickName='stdeveloper'")
该句实际上等价于:
@Query("select cd, cd.developer from CourseDeveloperEntity cd where cd.developer.nickName='stdeveloper'")
若将一个对象的关联对象指定为延迟加载LAZY,则每次通过该对象访问关联对象时(如courseDeveloper.developer)都会执行一次SQL来查出被关联对象,显然如果被关联对象访问频繁则此时性能差。解决:法1是改为EAGER加载;法2是使用join fetch查询,其会立即查出被关联对象。示例:
@Query("select cd from CourseDeveloperEntity cd join fetch cd.developer where cd.id='80f78778-7b39-499c-a1b6-a906438452a9'")
Join Fetch背后是使用inner join,可以显示指定用其他关联方式如 left join fetch
Join Fetch的缺点之一在于有可能导致“Duplicate Data and Huge Joins”,如多个实验关联同一课程,则查询两个实验时都关联查出所属课程,后者重复查询。
更多(join、join fetch等)可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Querying#Joining,_querying_on_a_OneToMany_relationship
JPA Paging and Sort
静态方式:直接在方法体现(如 getByNameOrderById),也可以在JPQL的@Query的逻辑中加上order by(此时字段名是Entity中的字段名)
动态方式:可以在Repository的方法的最后加一个Sort 或者 Pageable 类型的参数,便可动态生成排序或分页语句(编译后会自动在语句后加order by或limit语句)。
Repository中的一个方法myGetByCourseIdAndStudentId:
@Query("select se from StudentExperimentEntity se where se.studentId= ?2 and se.experimentId in ( select e.id from ExperimentEntity e where e.courseId= ?1 ) ")
List<StudentExperimentEntity> myGetByCourseIdAndStudentId(String courseId, String studentId, Pageable pageable);//没有写上述@Query语句也可以加Pageable。虽然实际传值时传PageRequest对象,但若这里生命为PageRequest则不会分页,总是返回所有数据,why?
调用:
studentExperimentRepository.myGetByCourseIdAndStudentId(courseId, studentId, PageRequest.of(0, count, new Sort(Sort.Direction.DESC, "lastopertime")));
编译后会在myGetByCourseIdAndStudentId所写SQL后自动加上 order by studentexp0_.lastopertime desc limit ?
注:上述用法也支持nativeQuery,示例:
@Query(value = "select d.*, u.username from developer d inner join user u on d.id=u.id " + " where (?1 is null or d.nick_name like %?1% ) ", nativeQuery = true) List<DeveloperEntity> myGetByNicknameOrPhoneOrEmailOrBz(String searchNicknameOrPhoneOrEmailOrBz, Pageable pageable);
如果要同时返回分页对象,则可用Page<XX>返回类型,如: Page<DeveloperEntity> myGetByNicknameOrPhoneOrEmailOrBz(String searchNicknameOrPhoneOrEmailOrBz, Pageable pageable);
需要注意的是,只有元素是Entity类型时才支持直接将返回值声明为Page对象,否则会出现Convert Exception。
进阶——可以通过JpaSort.unsafe实现待function的sort:
public interface UserRepository extends JpaRepository<User, Long> { @Query("select u from User u where u.lastname like ?1%") List<User> findByAndSort(String lastname, Sort sort); @Query("select u.id, LENGTH(u.firstname) as fn_len from User u where u.lastname like ?1%") List<Object[]> findByAsArrayAndSort(String lastname, Sort sort); } repo.findByAndSort("lannister", new Sort("firstname")); //repo.findByAndSort("stark", new Sort("LENGTH(firstname)")); //invalid repo.findByAndSort("targaryen", JpaSort.unsafe("LENGTH(firstname)")); repo.findByAsArrayAndSort("bolton", new Sort("fn_len"));
Repository中更新或创建并返回该Entity
如 UserEntity u=userRepository.save(userEntity) ,其中UserEntity包含成员变量private SchoolEntity schoolEntity。Repository的save方法会返回被save的entity,但若是第一次保存该entity(即新建一条记录)时u.schoolEntity的值会为null,解决:用saveAndFlush
查询Entity中的部分字段(Projections)
查询一个表的部分字段,称为投影(Projection)
若不需要联表查询则用下面的2中的方法,若需要联表查询则用1.3中的方法。
1、通过@Query注解
对于只返回一个字段的查询:
@Query(value = "select languageType from CourseTranslationEntity where courseId=?1") Set<Locale> myGetLanguageTypeByCourseId(String courseId);
对于返回多个字段的查询:
1.1、对于nativeQuery,直接select部分字段即可,结果默认会自动包装为Map。为了便于理解可以直接将结果声明为Map。示例:
@Query(value = "select g.id, g.school_id as schoolId, g.name, g.createtime, g.bz, count(s.id) as stuCount from grade g left join student s "
+ " on g.name=s.grade where g.school_id=(select a.school_id from admin a where a.id=?1)" // 以下为搜索条件
+ " and (?4 is null or g.name like %?4% or g.bz like %?4% ) "
+ " group by g.id limit ?2,?3", nativeQuery = true)
List<Map<String, Object>> myGetGradeList(String adminId, Integer page, Integer size,
String searchGradeNameOrGradeBz);
其可以达到目的,但缺点是sql里用的直接是数据库字段名,导致耦合大,数据库字段名一变,所有相关sql都得相应改变。
1.2、对于非nativeQuery:(sql里的字段名是entity的字段名,数据库字段名改动只要改变entity中对应属性的column name即可,解决上述耦合大的问题)
当Repository返回类型为XXEntity或List<XXEntity>时通常默认包含所有字段,若要去掉某些字段,可以去掉XXEntity中该字段的get方法。此法本质上还是查出来了只是spring在返回给调用者时去掉了。治标不治本。
也可以自定义一个bean,然后在Repository的sql中new该bean。此很死板,要求new时写bean的全限定名,比较麻烦。
更好的办法是与nativeQuery时类似直接在sql里select部分字段,不过非nativeQuery默认会将结果包装为List而不是Map,故不同的是:这里需要在sql里new map,此'map'非jdk里'Map';需要为字段名取别名,否则返回的Map里key为数值0、1、2... 。示例:
//为'map'不是'Map' @Query("select new map(g.name as name, count(s.id) as stuCount) from GradeEntity g, StudentEntity s where g.name=s.grade and g.schoolId=?1 group by g.id") List<Map<String, Object>> myGetBySchoolId(String schoolId);
需要注意的是,由于声明为Map时并不知道数据的返回类型是什么,故默认会用最大的类型(如对于数据库中的整型列,查出时Map中该字段的类型为BigInteger),除非不用Map而是指明了字段类型,见下面的1.3。
1.3、不管是否是nativeQuery,方法签名中返回值指定为Map不太好(指定为Map时,实际类型是 org.springframework.data.jpa.repository.query.AbstractJpaQuery$TupleConverter$TupleBackedMap ,该类型只能读不能改或写)。
更好的是用一个类:我们可以自定义一个接口,然后将返回类型声明为接口列表即可。接口get方法名中的字段与上面as后的字段名对应(当然,也可以不用接口而是用自定义包含部分字段的类,此时new时需要用类的全限定名)。此法不管是否nativeQuery均有效。示例:
1 //1 nativeQuery 2 @Query(value = "select g.id, g.school_id as schoolId, g.name, g.createtime, g.bz, count(s.id) as stuCount from grade g left join student s " 3 + " on g.name=s.grade where g.school_id=(select a.school_id from admin a where a.id=?1)" // 以下为搜索条件 4 + " and (?4 is null or g.name like %?4% or g.bz like %?4% ) " 5 + " group by g.id limit ?2,?3", nativeQuery = true) 6 List<IAdminInfo> myGetGradeList(String adminId, Integer page, Integer size, 7 String searchGradeNameOrGradeBz); 8 public interface IAdminInfo{ 9 public String getId(); 10 public String getSchoolId(); 11 ... 12 } 13 14 15 16 17 //2 nativeQuery 18 // JPQL查询部分字段时,默认返回List类型,可通过new map指定返回map,此时map key默认为顺序0 1 2 等,可通过as指定key名 19 @Query("select new map(id as idx, languageType as languageType) from CourseEntity where id in ?1 ") 20 List<IdAndLanguageType> myGetLanguagesTypeByCourseIdIn(Collection<String> courseIdCollection); 21 22 // 以下为为了查询Entity部分字段而定义的返回类型 23 public interface IdAndLanguageType { 24 public String getIdx(); //get方法中的字段名须与上面通过as取的key别名对应 25 26 public String getLanguageType(); 27 }
@Query用于查询时返回值总结 :
若是查询多个字段则返回时默认将这些字段包装为Object[]、若返回有多条记录则包装成List<Object[]>,若只查询一个字段则不用数组而是直接用该字段。示例:

select中仅有一个字段时(可以是表中的一个列名、Entity中的一个字段名、或一个Entity对象名,如language_type、languageType、courseEntity),方法返回类型须声明为该字段的类型或类型列表(如String、CourseEntity、List<String>、List<CourseEntity>)
select中有至少两个字段时,默认会将每条记录的几个字段结果包装为数组。可以手动指定包装为map,此时map的key为字段序号,故最通过as指定key为字段名。可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Querying#Query_Results
2、不通过@Query注解,直接通过方法名签名指定部分字段查询
实际上,在前面介绍JPA查询时介绍了直接通过方法签名实现只查询部分字段的方法。上面的查询不用@Query注解的等价写法如下:
List<IdAndLanguageType> getLanguagesTypeByCourseIdIn(Collection<String> courseIdCollection);
其内部原理是根据接口的get方法解析出要查询的字段,可以理解为JPA内部将之转成了用@Query注解的查询,内部生成的大概过程如下:
获得要查询的字段名:idx、languageType
生成@Query查询: @Query(" select new map(idx as idx, languageType as languageType) from CourseEntity where id in ?1 ") 。注意这里第一个字段名为idx而不是id,因为是根据接口方法产生的,可见:如果使用者不用@Query则需要确保接口中get方法名中的字段与Entity中的一致,而如果使用@Query则不需要,因为可以自己通过as取别名
上述1.3和2通过声明带get方法的接口来接收JPA Repository查询返回的部分字段,这其实就是投影(Projection)操作。可将接口换为POJO?实践发现不可以,只能为接口。
Projection相关的官方文档内容:https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#projections
Interface-based Projections
closed projectinos:接口get方法访问的属性名与目标domain class的属性名一样 的接口projection。(A projection interface whose accessor methods all match properties of the target aggregate is considered to be a closed projection. If you use a closed projection, Spring Data can optimize the query execution, because we know about all the attributes that are needed to back the projection proxy)
示例:见上面1.3所述
open projections:接口get方法访问的属性名有的在目标domain class不存在 的接口projection。这种属性的值可通过多种方式计算,包括:
通过@Value赋值,值如何确定?
直接引用目标domain class属性:
interface NamesOnly { @Value("#{target.firstname + ' ' + target.lastname}") String getFullName(); … }
通过SpEL引用Spring Bean方法计算:
@Component class MyBean { String getFullName(Person person) { … } } interface NamesOnly { @Value("#{@myBean.getFullName(target)}") String getFullName(); … }
引用方法的传参计算:
interface NamesOnly { @Value("#{args[0] + ' ' + target.firstname + '!'}") String getSalutation(String prefix); }
通过 interface default method:
interface NamesOnly { String getFirstname(); String getLastname(); default String getFullName() { return getFirstname().concat(" ").concat(getLastname()); } }
Class-based Projections
与Inteface-based Projections类似,只不过使用POJO(实践发现此法并不行,why?),示例:
class NamesOnly { private final String firstname, lastname; NamesOnly(String firstname, String lastname) { this.firstname = firstname; this.lastname = lastname; } String getFirstname() { return this.firstname; } String getLastname() { return this.lastname; } // equals(…) and hashCode() implementations }
Dynamic Projections
这种方式更灵活,更好用。示例:
interface PersonRepository extends Repository<Person, UUID> { <T> Collection<T> findByLastname(String lastname, Class<T> type); } void someMethod(PersonRepository people) { Collection<Person> aggregates = people.findByLastname("Matthews", Person.class); Collection<NamesOnly> aggregates = people.findByLastname("Matthews", NamesOnly.class); }
JPA的update、delete
(需要加@Transactional、@Modefying)
@Transactional //也可以放在service方法上
@Modifying @Query("delete from EngineerServices es where es.engineerId = ?1")//update与此类似 int deleteByEgId(String engineerId);
对于delete操作,可以与query的写法类似,直接通过方法名声明(注:update不支持这样写):
@Transactional @Modifying int deleteByEgId(String engineerId);
甚至更直接写为(此种写法成为 derived delete queries): int deleteByEgId(String engineerId); ,但此时记得需要在上层调用者部分添加@Transactional。
注:JPA中非nativeQuery的删除操作(如deleteByName)内部实际上是先分析出方法名中的条件、接着按该条件查询出所有Entity,然后根据这些Entity的id执行SQL删除操作( CrudRepository.delete(Iterable<User> users) )。
也正因为这样,软删除功能中指定 @SQLDelete("update student set is_delete='Y' where id=? ") 即可对所有非nativeQuery起作用。
JPA的update操作:
法1:Repository中@Modifying、@Query组合
法2:通过Repository的save方法。
方式1:JPA会判根据Entity的主键判断该执行insert还是update,若没指定主键或数据库中不存在该主键的记录则执行update。此法在通过在Entity指定@Where实现了软删除的情况下行不通,因为JPA通过内部执行查询操作判断是否是update时查询操作也被加上了@Where,从而查不到数据而被,进而最终执行insert,此时显然报主键冲突。
方式2:更好的做法是先通过Repository查出来,修改后再执行save,这样能确保为update操作
可参阅:https://stackoverflow.com/questions/11881479/how-do-i-update-an-entity-using-spring-data-jpa
JPA的count
Integer countByName(String name);
外键关联
相关注解:@ManyToOne/@OneToMany/@OneToOne 、 @JoinColumn/@PrimaryKeyJoinColumn、@MapsId,用法及区别见:https://www.cnblogs.com/chiangchou/p/mappedBy.html
- (1)@JoinColumn用来指定外键,其name属性指定该注解所在Entity对应的表的一个列名
- (2)@ManyToOne等用来指定对应关系是多对一等数量对应关系
通过(2)指定数量对应关系时,须在多的一方标注(@ManyToOne),一的一方注不注均可。(以下以School、Student为例,为一对多关系)
- 若只用(2)没用(1)则在生成表时会自动生成一张关联表来关联School、Student,表中包含School、Studeng的id
- 若在用了(2)的基础上用了(1)则不会自动生成第三张表,而是会在多的一方生成一个外键列。列名默认为 ${被引用的表名}_id (可以通过@JoinColumn的name属性指定列名),引用了目标表的id。
- 上法的缺点是在insert多的一方后会再执行一次update操作来设置外键的值(即使在insert时已经指定了),避免额外update的方法:在一的一方不使用@JoinColumn,而是改为指定@OneToMany的mappedBy属性。(1)和(2)的mappedBy属性不能同时存在,会报错。
示例:
进行如下设置后,JPA会自动生成为student表生成两个外键约束:student表school_id关联school表id自动、student表id字段关联user表id字段。
//StudentEntity //get set ... @Column(name = "id") private String sId; @Column(name = "school_id") private String schoolId; @ManyToOne @JoinColumn(name = "school_id", referencedColumnName = "id", insertable = false, updatable = false)//school.school_id字段外键关联到school.id字段;多个字段对应数据库同一字段时会报错,通过添加insertable = false, updatable = false即可 private SchoolEntity schoolBySchoolId; @OneToOne @JoinColumn(name = "id", referencedColumnName = "id", insertable = false, updatable = false) //student.id字段外键关联到user.id字段。也可用@PrimaryKeyJoinColumn @MapsId(value = "id") private UserEntity userByUserId;
对于外键属性(如上面student表的school_id),当该属性不是当前表的主键时,通过 @OneToOne/@ManyToOne + @JoinColumn 定义即可成功地在数据库中自动生成产生外键约束。但当该属性也是当前表的主键时(如为student.id定义外键来依赖user.id字段),单靠@OneToOne + @JoinColumn并不能自动产生外键约束,此时可通过加@MapIds来解决。
总结:
通过@ManyToOne/@OneToMany/@OneToOne + @JoinColumn/@PrimaryKeyJoinColumn定义外键,是否需要@MapsId视情况而定。
外键场景有两种:
外键属性不是当前表的主键(如上面student表的school_id字段不是主键)
外键属性也是当前表的属性(如上面student表的id字段是主键)
基于这两种场景,各注解使用时的组合及效果如下:
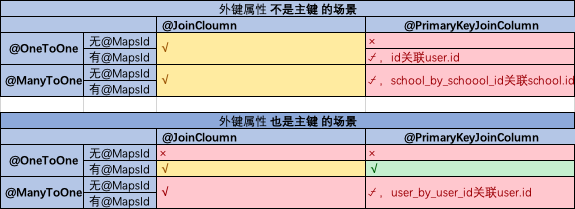
说明:
使用注解组合后是否会自动为表生成外键约束?打钩的表示会、打叉的表示不会、半勾半叉的表示会但是生成的不是预期的(如场景1中期望school_id关联了school id自动,但一种结果是id关联了user id、另一种是自动产生了school_by_school_id字段并关联到了school id,显然都不符合期望)。
结论:
1、外键属性不是主键的场景(第一种),用 @OneToOne/@ManyToOne + @JoinColumn 即可,为了简洁推荐不用@MapIds,示例见上面的school_id关联school id设置。
2、外键属性是主键的场景(第二种),用 @OneToOne + @JoinColumn + @MapsId,示例见上面的student id关联user id设置。
虽从表中可见场景二有三种组合都可以达到目标,但为了符合业务语义(主键嘛,当然是唯一的,因此是一对一)且为了和场景一的尽可能统一,我们采用这个的组合。
实践发现,使用@MapsId时,要求外键字段、被关联的字段 的数据库列名得相同且都得为"id"。why?如何避免?TODO
级联操作(CASCADE)
Use of the cascade annotation element may be used to propagate the effect of an operation to associated entities. The cascade functionality is most typically used in parent-child relationships.
用于有依赖关系的实体间(@OneToMany、@ManyToOne、@OneToOne等)的级联操作:当对一个实体进行某种操作时,若该实体加了与该操作相关的级联标记,则该操作会传播到与该实体关联的实体(即对被级联标记的实体施加某种与级联标记对应的操作时,与该实体相关联的其他实体也会被施加该操作)。包括:
CascadeType.PERSIST:持久化,即保存
CascadeType.REMOVE:删除当前实体时,关联实体也将被删除
CascadeType.MERGE:更新或查询
CascadeType.REFRESH:级联刷新,即在保存前先更新别人的修改:如Order、Item被用户A、B同时读出做修改且B的先保存了,在A保存时会先更新Order、Item的信息再保存。
CascadeType.DETACH:级联脱离,如果你要删除一个实体,但是它有外键无法删除,你就需要这个级联权限了。它会撤销所有相关的外键关联。
CascadeType.ALL:上述所有
注:
级联应该标记在One的一方。如对于 @OneToMany的Person 和 @ManyToOne的Phone,若将CascadeType.REMOVE标记在Phone则删除Phone也会删除Person,显然是错的。
慎用CascadeType.ALL,应该根据业务需求选择所需的级联关系,否则可能酿成大祸。
示例可参阅:http://westerly-lzh.github.io/cn/2014/12/JPA-CascadeType-Explaining/
like查询
对于单字段的可以直接在方法名加Containing
@Query("select s from SchoolEntity s where s.customerId=?1 "// 以下为搜索条件
+ " and (?2 is null or s.name like %?2% or s.bz like %?2% ) ")
List<SchoolEntity> getByCustomerId(String customerId, String searchSchoolnameOrBz, Pageable pageable);
Entity中将任意对象映射为一个数据库字段
借助JPA converter to map your Entity to the database.
在要被映射的字段上加上注解: @Convert(converter = JpaConverterJson.class)
实现JpaConverterJson:
public class JpaConverterJson implements AttributeConverter<Object, String> {//or specialize the Object as your Column type private final static ObjectMapper objectMapper = new ObjectMapper(); @Override public String convertToDatabaseColumn(Object meta) { try { return objectMapper.writeValueAsString(meta); } catch (JsonProcessingException ex) { return null; // or throw an error } } @Override public Object convertToEntityAttribute(String dbData) { try { return objectMapper.readValue(dbData, Object.class); } catch (IOException ex) { // logger.error("Unexpected IOEx decoding json from database: " + dbData); return null; } } }
需要注意的是,若Entity字段是一个 JavaBean 或 JavaBean 列表(如 TimeSlice 或 List<TimeSlice> ),则反序列化时相应地会反序列化成 LinkedHashMap 或 List<LinkedHashMap>,故强转成TimeSlice或List<TimeSlice>虽然编译期不会报错但运行时就出现类型转换错误。故需要进一步转换成JavaBean,示例:
1 public static class TimeTableConverter implements AttributeConverter<List<TimeSlice>, String> {// or specialize the Object as your Column type 2 3 private final static ObjectMapper objectMapper = new ObjectMapper(); 4 5 @Override 6 public String convertToDatabaseColumn(List<TimeSlice> data) { 7 try { 8 return objectMapper.writeValueAsString(data); 9 } catch (JsonProcessingException ex) { 10 throw new ApiCustomException(ApiErrorCode.OTHER, "fail to convert list to string"); 11 } 12 } 13 14 @Override 15 public List<TimeSlice> convertToEntityAttribute(String dbData) { 16 // return objectMapper.readValue(dbData, List.class);//直接return会报ClassCastException 17 18 Field[] fields = TimeSlice.class.getDeclaredFields(); 19 20 try { 21 List<Map<String, Object>> tmpMapList = objectMapper.readValue(dbData, List.class);// 对于键值对类型元素,默认反序列化成LinkedListMap类型,故需进一步转换成TimeSlice 22 List<TimeSlice> timeSliceList = null; 23 if (null != tmpMapList) { 24 timeSliceList = new ArrayList<>(); 25 for (Map<String, Object> map : tmpMapList) { 26 TimeSlice tmpTimeSlice = new TimeSlice(); 27 timeSliceList.add(tmpTimeSlice); 28 for (Field field : fields) {// 复制出所有属性 29 try { 30 field.setAccessible(true); 31 field.set(tmpTimeSlice, map.get(field.getName())); 32 } catch (IllegalArgumentException | IllegalAccessException e) { 33 e.printStackTrace(); 34 } 35 } 36 } 37 } 38 return timeSliceList; 39 } catch (IOException ex) { 40 throw new ApiCustomException(ApiErrorCode.OTHER, "fail to convert string to list"); 41 } 42 } 43 }
Collection类型与数据库字段的映射(20210620):
例如要将 CustomerEntity 的 List<GrantModule>grantModule 字段映射成数据库字段,如何做?
法1:借助上面介绍的方法,自定义converter。缺点:对于元素类型不同的每种List,都得写个相应的converter。
法2:借助 @ElementCollection,JPA2.0开始支持。示例: @ElementCollection(targetClass = GrantMdouleEnum.class) @Enumerated(EnumType.STRING) @Column(name = "grant_modules", length = ColumnLengthConstrain.LEN_ENUMSTRINGLIST_MAX, nullable = true) List<GrantMdouleEnum> grantModules; 。注:若元素类型是JPA默认支持的类型(前文介绍了),则@ElementCollection可单独使用,否则需要一些额外处理。缺点:默认会创建一张中间表用来存储元数据。
参考资料:https://stackoverflow.com/questions/416208/jpa-map-collection-of-enums
参考资料:https://stackoverflow.com/questions/25738569/jpa-map-json-column-to-java-object
将任意非基本数据类型(如java bean、list等)对应到数据库字段
本质上就是将数据序列化成基本数据类型如String。如要把List<String> gradeIdList对应到数据库中的字符串类型的courseSchedule字段。
法1:可以在业务层写代码将gradeIdList序列化成String: String res=objectMapper.writeValueAsString(gradeIdList);// 借助objectMapper.writeValueAsString(data); ,之后保存即可。从数据库中读取时: List<String> gradeIdList=objectMapper.readValue(dbData, List<String>.class); 。此法可以解决问题,但每个字段都得自己手动写此过程。
法2:实现一个AttributeConverter,并应用于Entity字段。此法相当于指定了AttributeConverter后让框架去自动做转换
@Column(name = "course_schedule") @Convert(converter = MyJpaConverterJson.class) private List<String> courseSchedule; public class MyJpaConverterJson implements AttributeConverter<List<String>, String> {// or specialize the Object as your // Column type private final static ObjectMapper objectMapper = new ObjectMapper(); @Override public String convertToDatabaseColumn(List<String> data) { try { return objectMapper.writeValueAsString(data); } catch (JsonProcessingException ex) { throw new ApiCustomException(ApiErrorCode.OTHER, "fail to convert list to string"); } } @Override public List<String> convertToEntityAttribute(String dbData) { try { return objectMapper.readValue(dbData, List.class); } catch (IOException ex) { throw new ApiCustomException(ApiErrorCode.OTHER, "fail to convert string to list"); } } }
枚举示例
@Column(name = "sex") @Enumerated(EnumType.ORDINAL)//持久化为0,1 private Sex sex; @Column(name = "type") @Enumerated(EnumType.STRING)//持久化为字符串 private Role role;
示例:
@Override public Page<CourseDeveloperEntity> listJoinedDevelopersOfGivenCourse(Integer page, Integer size, String courseId, String optionalExcludedDeveloperId, String optionalEmailOrNickName) { PageRequest pageRequest = PageRequest.of(page, size, Sort.by(Sort.Order.desc("developer.nickName"), Sort.Order.asc("role"))); return courseDeveloperRepository.findAll((Specification<CourseDeveloperEntity>) (root, query, criteriaBuilder) -> { List<Predicate> predicateList = new ArrayList<Predicate>(); predicateList.add(criteriaBuilder.equal(root.get("course").get("id"), courseId)); if (null != optionalExcludedDeveloperId) {// 排除指定开发者 predicateList.add(criteriaBuilder.notEqual(root.get("developer").get("id"), optionalExcludedDeveloperId)); } if (null != optionalEmailOrNickName && optionalEmailOrNickName.trim().length() > 0) { // Predicate p1 = criteriaBuilder.equal(root.get("developer").get("nickName"), optionalEmailOrNickName); // Predicate p2 = criteriaBuilder.equal(root.get("developer").get("email"), optionalEmailOrNickName); Predicate p1 = criteriaBuilder.like(root.get("developer").get("nickName"), "%" + optionalEmailOrNickName + "%"); Predicate p2 = criteriaBuilder.like(root.get("developer").get("email"), "%" + optionalEmailOrNickName + "%"); predicateList.add(criteriaBuilder.or(p1, p2)); } return criteriaBuilder.and(predicateList.toArray(new Predicate[predicateList.size()])); }, pageRequest); }
In查询
不管是否是nativeQuery都可以用in查询,如:
@Query( "select * from student where id in ?1", nativeQuery=true) //@Query( "select s from StudentEntity s where s.id in ?1")
List<StudentEntity> myGetByIdIn(Collection<String> studentIds );//复杂查询,自定义查询逻辑
List<StudentEntity> getByIdIn( Collection<String> studentIds );//简单查询,声明语句即可
不管是否自己写查询语句、不管是否是nativeQuery,都要求调用该方法时所传的id列表必须至少有一个元素,否则执行时会报错。
原因:运行时动态生成sql语句,如果id列表为null或空列表,则最终生成的sql语句中"where id in null"不符合sql语法。
有时候有特殊需求:
问题描述:如需要有两个方法,他们的查询逻辑及返回一样,只不过一个方法带Collection参数而另一个不带,此时在Repository中两个方法的查询语句会重复写,这给维护带来了麻烦。示例:
@Query("xxx1")
List<StudentEntity> myGetByIdAndNameIn(String id, Collection<String> names )//调用者须确保names至少有一个元素
@Query("xxx2")
List<StudentEntity> myGetById(String id)
在这种情况下,如何将两个方法合并为一个?
解决:将Collection参数视为非必须参数,为null时当成不将该参数作为查询条件
示例:
@Query( "select * from student where id=?1 and (coalesce(?2) is null or name in (?2))", nativeQuery=true) //@Query( "select s from StudentEntity s where id=?1 and (coalesce(?2) is null or s.name in (?2))") List<StudentEntity> myGetByIdAndNameIn(String id, Collection<String> optionalNames );// 调用者可通过myGetByIdAndNameIn(id, null)来达到myGetById(id)的目的
这样Repository中只有myGetByIdAndNameIn方法,调用者可通过 myGetByIdAndNameIn(id, null) 来达到 myGetById(id) 的目的。
当然,此法要求要么传null、要么须至少有一个元素,而不能为空列表。
进阶:
使用 (?2) is null or name in (?2) 可否?实践证明不行,因为在optionalNames有多个元素时最终转换成类似"(xx1, xx2) is null" 的sql,这时报?2 is null 会报sql Operand should contain 1 column(s) 的错。
另外,如果传了optionalNames(即非null)则要求至少有一个元素,否则转成sql后"name in ()"也会报错。
JPA Repository的save(xxx)方法
通过show-sql=true参数打印sql语句,可以发现其内部先是按被保存的Entity的主键查出该Entity,若存在则更新并保存、否则插入。
save方法以Entity为参数用于保存。其效果可能是插入新数据或修改已有数据,在执行时会根据Entity参数自动判断:如果该Entity参数中的主键值(可能是联合主键)在DB中已存在则是更新、否则为插入。因此,在某些场景下会有问题。
举个例子,我们有这么个场景:Entity为CourseDeveloperEntity,该Entity中有单独的id字段作为主键、且有course_id、developer_id联合唯一索引、还有个is_delete用于逻辑删除。
在该场景下,若我们删除了一个CourseDeveloperEntity,则该Entity被删除了(is_delete标记为true以逻辑删除,数据库中实际上还在,但上层业务查不到),因此若之后再插入(course_id、developer_id)一样的Entity但没指定id一样,则会因违背联合唯一索引而duplicate key的错。相关代码:
// 保存 CourseDeveloperEntity courseDeveloperEntity = courseDeveloperRepository.getByCourseIdAndDeveloperId(courseId, developerEntity.getId());//查不到被逻辑删除的记录 if (null == courseDeveloperEntity) { courseDeveloperEntity = new CourseDeveloperEntity(); } courseDeveloperEntity.setCourseId(courseId); courseDeveloperEntity.setDeveloperId(developerEntity.getId()); courseDeveloperEntity.setRole(developerRoleInTheCourse); return courseDeveloperRepository.save(courseDeveloperEntity);//由于主键自动新生成故courseDeveloperEntity被当成新的,故是执行insert而不是update,从而报错
JPA Repository的删除操作
方法名包含条件的删除操作,如 Integer deleteByNameAndSId(String name, String uuid); ,其执行时与save类似,也是先根据条件查出目标Entity再执行删除操作。对于 void delete(T entity); 则直接根据Entity的主键操作而不用先查。
逻辑删除
借助org.hibernate.annotations(所以不是JPA的标准)旳 @Where、@SQLDelete、@SQLDeleteALL 这三个注解来实现。
1、定义一个字段用于标识记录是否被逻辑删除。这里通过JPA的@MappedSuperclass定义各Entity共有的字段(该注解修饰的Entity不会对应数据库表,但其内定义的字段会被继承该Entity的子Entity对应到数据库字段),包含is_delete:
@Data @NoArgsConstructor @MappedSuperclass public abstract class BaseEntity { @Setter(value = AccessLevel.PRIVATE) @Temporal(TemporalType.TIMESTAMP) @CreationTimestamp @Column(name = "create_time", nullable = false) private Date createTime; @Setter(value = AccessLevel.PRIVATE) @Temporal(TemporalType.TIMESTAMP) @UpdateTimestamp @Column(name = "update_time", nullable = false) private Date updateTime; @Getter(value = AccessLevel.PRIVATE) @Setter(value = AccessLevel.PRIVATE) @Column(name = constant.ISDELETE_COLUMN_NAME, nullable = false) private Boolean isDelete = false; }
2、通过@Where、@SQLDelete、@SQLDeleteALL 三个注解修饰对应数据库表的Entity来实现逻辑删除:
@SQLDelete(sql = "update " + StudentEntity.tableName + " set " + constant.ISDELETE_COLUMN_NAME + " =true where sid=?") // 对非nativeQuery 旳delete起作用,包括形如deleteByName等,下同 @SQLDeleteAll(sql = "update " + StudentEntity.tableName + " set " + constant.ISDELETE_COLUMN_NAME + " =true where sid=?") @Where(clause = constant.ISDELETE_COLUMN_NAME + " = false") // 对非nativeQuery的select起作用(如count、非nativeQuery的String myGetNameByName等,前者本质上也是select) @Data @Entity @Table(name = StudentEntity.tableName) public class StudentEntity extends BaseEntity { public static final String tableName = "student"; @Id @Column(name = "sid", length = 36) private String sId; @Column(name = "name", length = 36) private String name; @Column(name = "age") private Integer age; }
需要注意的是:
- @Where会自动在查询语句后拼接@Where中指定的条件;该注解对所有的非nativeQuery的查询其作用,如getByName、count、自己写查询语句但非nativeQuery的myGetByName等。
- @SQLDelete会自动将删除语句替换为@SQLDelete中指定的sql操作;该注解对所有非nativeQuery的删除操作其作用,如delete(StudenEntity entity)、deleteBySId、deleteByName等,但由于指定的sql操作中条件不得不写死,所以要按期望起作用的话@SQLDelete中的sql操作应以Entity的主键为条件,且删除语句按上述前两者写法写(对于delete(StudenEntity entity)会自动取entity的主键给sid),而不能用第三种(会将name参数值传给sid)
- 通过JPQL的方法名指定删除操作(如 Integer deleteByName(String name))时背后是先根据条件查出Entity然后根据Entity的主键删除该Entity。所以通过@SQLDelete、@SQLDeleteALL实现逻辑删除时,由于其语句是写死的,故:
- @SQLDelete、@SQLDeleteALL同时存在时会按后者来执行软删除逻辑
- @SQLDeleteALL并不会批量执行软删除逻辑(因为一来不知具体有几个数据,二来in中只指定了一个元素)而是一个个删,即有多条待删除时会一条条执行软删除逻辑,每条语句中in中只有一个元素。故其效果与@SQLDelete的一样,然而in操作效率比=低,故综上,最好用前者。
关于软删除:对于关联表(一对一、一对多、多对多),若要启用软删除,则须为多对多关联表定义额外的主键字段而不能使用联合外键作为主键,否则软删除场景下删除关联关系再重新关联时会主键冲突。另外,特殊情况下多对多关联表可以不启用软删除(被关联表、一对多或多对一关联表则需要,因为它们侧重的信息往往不在于关联关系而是重要的业务信息)
指定时间或日期字段的返回格式
通过jackson的@JsonFormat注解指定,示例:(也可以注在get方法上)
@Basic @Column(name = "customer_expiretime") @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = CommonUtil.DATETIME_PATTERN_WITH_TIMEZONE) private Timestamp customerExpireTime;
指定关系数据库的存储引擎
SpringBoot 2.0后使用JPA、Hibernate来操作MySQL,Hibernate默认使用MyISM存储引擎而非InnoDB,前者不支持外键故会忽略外键定义,可通过如下SpringBoot配置指定用InnoDB:
spring:
jpa:
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect #不加这句则默认为myisam引擎
复杂Query(Criteria、QBE、Specification、Querydls)
注:软删除对Criteria API不起作用,但对Specification、QBE查询会起作用
1. 复杂的操作(复杂查询、批量更新、批量删除、SQL函数使用等)
Criteria API用于动态查询(在运行时才确定查询条件等,动态产生查询逻辑)。更多可参阅:见Criteria API:https://en.wikibooks.org/wiki/Java_Persistence/Criteria#CriteriaUpdate_.28JPA_2.1.29
示例:
// update。直接生成db操作语句,而非像named querxy那样先查出来再根据ID更新 CriteriaUpdate<CourseEntity> update = criteriaBuilder.createCriteriaUpdate(CourseEntity.class); Root<CourseEntity> root = update.from(CourseEntity.class); update.set("tag", "test"); update.where(criteriaBuilder.isNotNull(root.get("versionDescription"))); Query query = entityManager.createQuery(update); int rowCount = query.executeUpdate(); System.err.println(rowCount); // delete。直接生成db操作语句,而非像named query那样先查出来再根据ID删除 CriteriaDelete<CourseEntity> delete = criteriaBuilder.createCriteriaDelete(CourseEntity.class); root = delete.from(CourseEntity.class); delete.where(criteriaBuilder.isNull(root.get("versionDescription"))); query = entityManager.createQuery(delete); rowCount = query.executeUpdate(); System.err.println(rowCount); // select。软删除对Criteria同样有效 CriteriaQuery<CourseEntity> select = criteriaBuilder.createQuery(CourseEntity.class); root = select.from(entityManager.getMetamodel().entity(CourseEntity.class)); select.where(criteriaBuilder.isNotNull(root.get("versionDescription"))); query = entityManager.createQuery(select); List<CourseEntity> res = query.getResultList(); System.err.println(res);
2. 复杂条件(多条件和多表)查询和分页:Specification(Specification是Spring对Criteria的封装)
@Override public Page<CourseDeveloperEntity> listJoinedDevelopersOfGivenCourse(Integer page, Integer size, String courseId, String optionalExcludedDeveloperId, String optionalEmailOrNickName) { PageRequest pageRequest = PageRequest.of(page, size, Sort.by(Sort.Order.desc("developer.nickName"), Sort.Order.asc("role"))); return courseDeveloperRepository.findAll((Specification<CourseDeveloperEntity>) (root, query, criteriaBuilder) -> { List<Predicate> predicateList = new ArrayList<Predicate>(); predicateList.add(criteriaBuilder.equal(root.get("course").get("id"), courseId)); if (null != optionalExcludedDeveloperId) {// 排除指定开发者 predicateList.add(criteriaBuilder.notEqual(root.get("developer").get("id"), optionalExcludedDeveloperId)); } if (null != optionalEmailOrNickName && optionalEmailOrNickName.trim().length() > 0) { // Predicate p1 = criteriaBuilder.equal(root.get("developer").get("nickName"), optionalEmailOrNickName); // Predicate p2 = criteriaBuilder.equal(root.get("developer").get("email"), optionalEmailOrNickName); Predicate p1 = criteriaBuilder.like(root.get("developer").get("nickName"), "%" + optionalEmailOrNickName + "%"); Predicate p2 = criteriaBuilder.like(root.get("developer").get("email"), "%" + optionalEmailOrNickName + "%"); predicateList.add(criteriaBuilder.or(p1, p2)); } return criteriaBuilder.and(predicateList.toArray(new Predicate[predicateList.size()])); }, pageRequest); }
Spring还提供了QBE(query by example)查询,示例:
AclDomainSubject domainSubjectExample = AclDomainSubject.builder().domain(domainOptional.get()).build(); List<AclDomainSubject> subjects = domainSubjectRepository.findAll(Example.of(domainSubjectExample)); Example<AclDomainSubject> example = Example.of(domainSubjectExample, ExampleMatcher.matching() .withMatcher("domain.id", new ExampleMatcher.GenericPropertyMatcher().exact()));//更加复杂的example,指定匹配规则 subjects = domainSubjectRepository.findAll(example);
可参阅:https://blog.wuwii.com/jpa-specification.html
3 Querydsl
一般来说,上面的几种工具足够满足绝大多数查询场景了,但是对于查询部分字段、子查询、联表查询等会比较麻烦。
此时可考虑使用Querydsl,Spring Data JPA自身也整合了Querydsl,可以以代码方式实现类似于原生SQL的查询逻辑。其原理是由插件自动根据Entity类生成对应的query type类,用户就可在代码里通过这些query type来指定查询条件,框架会根据查询生成相应的SQL语句。
使用示例:
1 UserRepository直接继承QuerydslPredicateExecutor<T>,就可直接用UserRepository写查询逻辑,示例:
//UserRepository定义 @Repository public interface UserRepository extends QuerydslPredicateExecutor<UserEntity>,JpaRepository<UserEntity, String>{ } //UserRepository查询 QUserEntity qUserEntity=QUserEntity.userEntity; userRepository.findOne( qUserEntity.username.contains("zhangsan").and(qUserEntity.password.isNotNull()));
2 通过JPAQueryFactory实现更复杂的CRUD:
// 配置 JPAQueryFactory @Service public class BlogInfoServiceImpl implements BlogInfoService { private JPAQueryFactory queryFactory; @PostConstruct //指定初始化queryFactory public void init() { queryFactory = new JPAQueryFactory(entityManager); } @PersistenceContext private EntityManager entityManager; } //查询逻辑 JPAQuery jpaQuery = queryFactory.select(qBlogInfo, qBlogType.typeName) .from(qBlogInfo) .leftJoin(qBlogType) .on(qBlogInfo.blogTypeId.eq(qBlogType.id)) .orderBy(qBlogInfo.createTime.desc()) .offset(pageable.getPageNumber() * pageable.getPageSize()) .limit(pageable.getPageSize());
与Specification相比,Querydsl的优点有:以代码而不是字符串来指定字段名的,这样类型安全,不易写错;query的代码逻辑与SQL非常相似,易理解;等。
详情可参阅:https://zhuanlan.zhihu.com/p/99055340?utm_source=wechat_session
定义公共Repository
可以将业务中用到的公共方法抽离到公共Repository中,示例:
@NoRepositoryBean //避免Spring容器为此接口创建实例。不被Service层直接用到的Repository(如base repository)均应加此声明
public interface BaseRepository<T, ID> { @Modifying @Query("update #{#entityName} set isDelete='N' where id in ?1 ") Integer myUpdateAsNotDeleted(Collection<String> ids); }
通过JPA定义表结构的关联关系(如共用部分字段等)
这里以实际项目中课程、实验、步骤与其翻译数据的表结构关联方案设计为例:
更多可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Inheritance
对于关联表的定义
最好定义个外键变量、同时定义该外键对应的被关联表实体的一个变量,而不是只定义后者。只定义后者的话要获取被关联对象的主键时会做数据库查询被关联对象的操作,显然多了次IO
尽可能避免定义一对一关联关系(如目前的customer_schedule),即是业务真的是一对一,也可以按照一对多甚至多对多设计,利于后期扩展。当然也有不得不为一对一的,如developer与user等
Map类型的关联属性
JPA1.0起就支持Map类型的关联属性,可通过 @MapKey 定义。示例:
@Entity public class Employee { @Id private long id; ... @OneToMany(mappedBy="owner") @MapKey(name="type") private Map<String, PhoneNumber> phoneNumbers; ... } @Entity public class PhoneNumber { @Id private long id; @Basic private String type; // Either "home", "work", or "fax". ... @ManyToOne private Employee owner; ... }
In JPA 1.0 the map key must be a mapped attribute of the collection values. The
@MapKeyannotation or<map-key>XML element is used to define a map relationship. If theMapKeyis not specified it defaults to the target object'sId.
更多可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Relationships#Maps
JPA Repository save方法
具体实现如下:(SimpleJpaRepository)
@Transactional public <S extends T> S save(S paraEntity) { if (entityInformation.isNew(paraEntity)) {//根据id是否存在判断是否为new。这里的new是相对于Persistence Context而言的,而非针对db是否有该记录 em.persist(paraEntity); //将该entity变为managed的entity return entity; } else { return em.merge(paraEntity);//将该entity的数据更新到Persistence Context。若Persistence Context里尚未有同id的该entity,则会根据id执行一次db查询 } }
要明确下,这里的save的语义并不是保存到db,而是保存到Persistence Context(保存到db会在事务提交时或Persistence Context flush时做)。save时会根据paraEntity的id是否存在来判断paraEntity在Persistence Context中是否为新的:
1、若是新的,则persist:paraEntity直接保存到Persistence Context(即entity变为managed状态)。flush时产生sql insert操作
2、若否,则merge:认为Persistence Context中已有同id的entity,假设为existEntity(这里的'同id'当然不仅是值,还有entity类型,为便于表述只说id):
2.1、若Persistence Context中确有同id entity,则将paraEntity的数据更新到对应existEntity。flush时产生sql update操作(且字段值有发生变化才会产生sql update操作!)
此时,paraEntity与existEntity可能是同一个对象,也可能不是。
2.2、若Persistence Context中实际上尚未有同id的entity,则会根据id执行一次db查询:若查不到则同1,否则同2.1
可见:
1、save的执行实际上是将entity的数据和状态更新到Persist Context,只有当flush或事务提交时,才会将entity的数据insert或update到数据库。"At flush-time the entity state transition is materialized into a database DML statement."
2、调用save方法并不一定会产生db操作:数据字段值未发生改变时。如查出来再直接保存
3、另外,执行JPQL时(即下面说的结论对nativeQuery无效),只要JPA认为最后是insert或update操作,被@UpdateTimestamp修饰的字段就会自动更新为当前时间。同理只要认为需要执行insert,@CreationTimestamp修饰的字段会更新为当前值。
4、jpa persist操作对应sql insert 操作、jpa merge操作对应sql insert或sql update操作。
While a
savemethod might be convenient in some situations, in practice, you should never callmergefor entities that are either new or already managed. As a rule of thumb, you shouldn’t be usingsavewith JPA. For new entities, you should always usepersist, while for detached entities you need to callmerge. For managed entities, you don’t need anysavemethod because Hibernate automatically synchronizes the entity state with the underlying database record.
JPA事务内Entity变更自动更新到数据库(自动提交)
automatic dirty checking mechanism:
若启用了事务,则对于managed状态的entity,若在事务内该entity有字段的值发生了变化,则即使未调save方法,该entity的变化最后也会被自动同步到数据库,即sql update操作。即相当于在Persist Context flush时自动对各engity执行 save 方法。(org.hibernate.event.internal.AbstractFlushingEventListener中)
详情可参阅:https://vladmihalcea.com/the-anatomy-of-hibernate-dirty-checking/
By default Hibernate checks all managed entity properties. Every time an entity is loaded, Hibernate makes an additional copy of all entity property values. At flush time, every managed entity property is matched against the loading-time snapshot value.
Web Support
参阅:https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#core.web
Basic Web Support(Domain class、Pageable、Sort)
domain类(即被Spring Data CrudRepository管理的domain类,如Entity类)及Pageable、Sort可以直接作为handler方法的形参,框架会自动解析请求参数组装成相应的实参,示例:
@Controller @RequestMapping("/users") class UserController { @RequestMapping("/{id}") String showUserForm(@PathVariable("id") User user, Model model) { model.addAttribute("user", user); return "userForm"; } } @Controller @RequestMapping("/users") class UserController { private final UserRepository repository; UserController(UserRepository repository) { this.repository = repository; } @RequestMapping String showUsers(Model model, Pageable pageable) { model.addAttribute("users", repository.findAll(pageable)); return "users"; } }
对于domain类,会自动根据request的"id"参数调用repository的findById查得对象。request示例:/user?id=2
对于Pageable,会根据request"page"、"size"参数组装对象;request示例:/users?page=0&size=2
对于Sort,会根据request的"sort"参数组装对象,该参数值须遵循规则: property,property(,ASC|DESC)(,IgnoreCase) 。request示例:/users?sort=firstname&sort=lastname,asc&sort=city,ignorecase
内部原理:第一者是由 DomainClassConverter 类完成的,后两者是由 HandlerMethodArgumentResolver 完成的。
Querydsl Web Support
可以直接将Querydsl的Predicate作为handler方法的形参,框架会自动(默认只要Querydsl在classpath上就会生效)根据请求参数组装创建Predicate实例。示例:
@Controller class UserController { @Autowired UserRepository repository; @RequestMapping(value = "/", method = RequestMethod.GET) String index(Model model, @QuerydslPredicate(root = User.class) Predicate predicate, Pageable pageable, @RequestParam MultiValueMap<String, String> parameters) { model.addAttribute("users", repository.findAll(predicate, pageable)); return "index"; } }
原理篇
自定义JpaRespository接口却不用提供实现的原理
相关奥秘在 JpaRepositoriesAutoConfiguration 类中。
虽然用户没有为每个自定义的JpaRepository接口提供实现类,但Spring Data JPA 会将每个Repository bean最终映射到一个统一的实现类SimpleJpaRepository的代理对象,而这个代理对象能支持所有每个自定义的JpaRepository接口定义的功能和SimpleJpaRepository类中定义的所有功能。
详情参阅:https://blog.csdn.net/andy_zhang2007/article/details/84064862
Entity类的属性与数据库字段长度的对应
显然,ORM框架(JPA)内部会维护对象类型与数据库类型的对应关系,具体在 Hibernate 的 DB2Dialect 类中。对于不同的数据库(如MySQL、DB2)会继承该类实现不同的Dialect类,如 MySQL5Dialect 。Spring Data JPA会根据数据库类型采取对应的Dialect注册到容器中,相关代码在 org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter :
/** * Determine the Hibernate database dialect class for the given target database. * @param database the target database * @return the Hibernate database dialect class, or {@code null} if none found */ @Nullable protected Class<?> determineDatabaseDialectClass(Database database) { switch (database) { case DB2: return DB2Dialect.class; case DERBY: return DerbyTenSevenDialect.class; case H2: return H2Dialect.class; case HANA: return HANAColumnStoreDialect.class; case HSQL: return HSQLDialect.class; case INFORMIX: return InformixDialect.class; case MYSQL: return MySQL5Dialect.class; case ORACLE: return Oracle12cDialect.class; case POSTGRESQL: return PostgreSQL95Dialect.class; case SQL_SERVER: return SQLServer2012Dialect.class; case SYBASE: return SybaseDialect.class; default: return null; } }
注意类HibernateJpaVendorAdapter,其是接口JpaVendorAdapter的一个实现,而该接口是一个SPI: SPI interface that allows to plug in vendor-specific behavior into Spring's EntityManagerFactory creators. Serves as single configuration point for all vendor-specific properties. 在JpaVendorAdapter中会进行一系列配置,包括我们实践中常用的JPA show-sql、ddl配置等,源码:
package org.springframework.orm.jpa.vendor; import java.util.HashMap; import java.util.Map; import javax.persistence.EntityManager; import javax.persistence.EntityManagerFactory; import javax.persistence.spi.PersistenceProvider; import javax.persistence.spi.PersistenceUnitInfo; import javax.persistence.spi.PersistenceUnitTransactionType; import org.hibernate.cfg.AvailableSettings; import org.hibernate.dialect.DB2Dialect; import org.hibernate.dialect.DerbyTenSevenDialect; import org.hibernate.dialect.H2Dialect; import org.hibernate.dialect.HANAColumnStoreDialect; import org.hibernate.dialect.HSQLDialect; import org.hibernate.dialect.InformixDialect; import org.hibernate.dialect.MySQL5Dialect; import org.hibernate.dialect.Oracle12cDialect; import org.hibernate.dialect.PostgreSQL95Dialect; import org.hibernate.dialect.SQLServer2012Dialect; import org.hibernate.dialect.SybaseDialect; import org.springframework.lang.Nullable; /** * {@link org.springframework.orm.jpa.JpaVendorAdapter} implementation for Hibernate * EntityManager. Developed and tested against Hibernate 5.0, 5.1, 5.2 and 5.3; * backwards-compatible with Hibernate 4.3 at runtime on a best-effort basis. * * <p>Exposes Hibernate's persistence provider and EntityManager extension interface, * and adapts {@link AbstractJpaVendorAdapter}'s common configuration settings. * Also supports the detection of annotated packages (through * {@link org.springframework.orm.jpa.persistenceunit.SmartPersistenceUnitInfo#getManagedPackages()}), * e.g. containing Hibernate {@link org.hibernate.annotations.FilterDef} annotations, * along with Spring-driven entity scanning which requires no {@code persistence.xml} * ({@link org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean#setPackagesToScan}). * * <p><b>A note about {@code HibernateJpaVendorAdapter} vs native Hibernate settings:</b> * Some settings on this adapter may conflict with native Hibernate configuration rules * or custom Hibernate properties. For example, specify either {@link #setDatabase} or * Hibernate's "hibernate.dialect_resolvers" property, not both. Also, be careful about * Hibernate's connection release mode: This adapter prefers {@code ON_CLOSE} behavior, * aligned with {@link HibernateJpaDialect#setPrepareConnection}, at least for non-JTA * scenarios; you may override this through corresponding native Hibernate properties. * * @author Juergen Hoeller * @author Rod Johnson * @since 2.0 * @see HibernateJpaDialect */ public class HibernateJpaVendorAdapter extends AbstractJpaVendorAdapter { private final HibernateJpaDialect jpaDialect = new HibernateJpaDialect(); private final PersistenceProvider persistenceProvider; private final Class<? extends EntityManagerFactory> entityManagerFactoryInterface; private final Class<? extends EntityManager> entityManagerInterface; @SuppressWarnings("deprecation") public HibernateJpaVendorAdapter() { this.persistenceProvider = new SpringHibernateJpaPersistenceProvider(); this.entityManagerFactoryInterface = org.hibernate.jpa.HibernateEntityManagerFactory.class; this.entityManagerInterface = org.hibernate.jpa.HibernateEntityManager.class; } /** * Set whether to prepare the underlying JDBC Connection of a transactional * Hibernate Session, that is, whether to apply a transaction-specific * isolation level and/or the transaction's read-only flag to the underlying * JDBC Connection. * <p>See {@link HibernateJpaDialect#setPrepareConnection(boolean)} for details. * This is just a convenience flag passed through to {@code HibernateJpaDialect}. * <p>On Hibernate 5.1/5.2, this flag remains {@code true} by default like against * previous Hibernate versions. The vendor adapter manually enforces Hibernate's * new connection handling mode {@code DELAYED_ACQUISITION_AND_HOLD} in that case * unless a user-specified connection handling mode property indicates otherwise; * switch this flag to {@code false} to avoid that interference. * <p><b>NOTE: For a persistence unit with transaction type JTA e.g. on WebLogic, * the connection release mode will never be altered from its provider default, * i.e. not be forced to {@code DELAYED_ACQUISITION_AND_HOLD} by this flag.</b> * Alternatively, set Hibernate 5.2's "hibernate.connection.handling_mode" * property to "DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION" or even * "DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT" in such a scenario. * @since 4.3.1 * @see PersistenceUnitInfo#getTransactionType() * @see #getJpaPropertyMap(PersistenceUnitInfo) * @see HibernateJpaDialect#beginTransaction */ public void setPrepareConnection(boolean prepareConnection) { this.jpaDialect.setPrepareConnection(prepareConnection); } @Override public PersistenceProvider getPersistenceProvider() { return this.persistenceProvider; } @Override public String getPersistenceProviderRootPackage() { return "org.hibernate"; } @Override public Map<String, Object> getJpaPropertyMap(PersistenceUnitInfo pui) { return buildJpaPropertyMap(this.jpaDialect.prepareConnection && pui.getTransactionType() != PersistenceUnitTransactionType.JTA); } @Override public Map<String, Object> getJpaPropertyMap() { return buildJpaPropertyMap(this.jpaDialect.prepareConnection); } private Map<String, Object> buildJpaPropertyMap(boolean connectionReleaseOnClose) { Map<String, Object> jpaProperties = new HashMap<>(); if (getDatabasePlatform() != null) { jpaProperties.put(AvailableSettings.DIALECT, getDatabasePlatform()); } else { Class<?> databaseDialectClass = determineDatabaseDialectClass(getDatabase()); if (databaseDialectClass != null) { jpaProperties.put(AvailableSettings.DIALECT, databaseDialectClass.getName()); } } if (isGenerateDdl()) { jpaProperties.put(AvailableSettings.HBM2DDL_AUTO, "update"); } if (isShowSql()) { jpaProperties.put(AvailableSettings.SHOW_SQL, "true"); } if (connectionReleaseOnClose) { // Hibernate 5.1/5.2: manually enforce connection release mode ON_CLOSE (the former default) try { // Try Hibernate 5.2 AvailableSettings.class.getField("CONNECTION_HANDLING"); jpaProperties.put("hibernate.connection.handling_mode", "DELAYED_ACQUISITION_AND_HOLD"); } catch (NoSuchFieldException ex) { // Try Hibernate 5.1 try { AvailableSettings.class.getField("ACQUIRE_CONNECTIONS"); jpaProperties.put("hibernate.connection.release_mode", "ON_CLOSE"); } catch (NoSuchFieldException ex2) { // on Hibernate 5.0.x or lower - no need to change the default there } } } return jpaProperties; } /** * Determine the Hibernate database dialect class for the given target database. * @param database the target database * @return the Hibernate database dialect class, or {@code null} if none found */ @Nullable protected Class<?> determineDatabaseDialectClass(Database database) { switch (database) { case DB2: return DB2Dialect.class; case DERBY: return DerbyTenSevenDialect.class; case H2: return H2Dialect.class; case HANA: return HANAColumnStoreDialect.class; case HSQL: return HSQLDialect.class; case INFORMIX: return InformixDialect.class; case MYSQL: return MySQL5Dialect.class; case ORACLE: return Oracle12cDialect.class; case POSTGRESQL: return PostgreSQL95Dialect.class; case SQL_SERVER: return SQLServer2012Dialect.class; case SYBASE: return SybaseDialect.class; default: return null; } } @Override public HibernateJpaDialect getJpaDialect() { return this.jpaDialect; } @Override public Class<? extends EntityManagerFactory> getEntityManagerFactoryInterface() { return this.entityManagerFactoryInterface; } @Override public Class<? extends EntityManager> getEntityManagerInterface() { return this.entityManagerInterface; } }
Spring Data JPA官方文档阅读note
官方文档:https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#preface
Defining Repository Interfaces
Null Handling of Repository Method's Return:返回单实例时可能为null(可以用各种Optional包装类作为返回类型以避免null),为collections, collection alternatives, wrappers, and streams are guaranteed never to return null but rather the corresponding empty representation
Using Repositories with Multiple Spring Data Modules:Spring Data modules accept either third-party annotations (such as JPA’s @Entity) or provide their own annotations (such as @Document for Spring Data MongoDB and Spring Data Elasticsearch).
Defining Query Methods
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods
Repository方法的定义方式:
框架自动根据方法名生成,如findByEmailAddressAndLastname;
使用Named Queries:将查询逻辑写在domain class、方法声明写在Repository。查询语句多时此法会显得乱,故用得较少。示例:
@Entity @NamedQuery(name = "User.findByEmailAddress", query = "select u from User u where u.emailAddress = ?1") public class User { } public interface UserRepository extends JpaRepository<User, Long> { List<User> findByLastname(String lastname); User findByEmailAddress(String emailAddress); }
用户自定义Query逻辑,通常是通过@Query注解;
方法的查询条件:Like、GreatThan、Equal等,见前文
方法的返回值:void、Like、Sort、Page、Slice、List、Set、Iterable、Stream、Streamable、Future、CompletableFuture等
Using SpEL Expression:Spring Data Jpa 1.4起,内置了一些SpEL template表达式,包括 #{#entityName} 、 #{[0]} 、 ?#{escape([0])} 、 ?#{escapeCharacter()}" 等。
The entityName is resolved as follows: If the domain type has set the name property on the @Entity annotation, it is used. Otherwise, the simple class-name of the domain type is used.
Custom Implementations of Spring Data Repositories
Customizing Individual Repositories
通常用于将公共方法抽离在一个非业务Repository中然后被若干业务Repository继承,以实现方法共用。两步:
1 定义自己的Repository接口(称为fragment interface)及其实现类,实现类须以Impl结尾(当然也可以通过@EnableJpaRepositories的repositoryImplementationPostfix属性配置以什么结尾):
1 interface HumanRepository<T> { 2 void someHumanMethod(T user); 3 } 4 5 class HumanRepositoryImpl<T> implements HumanRepository<T> { 6 7 public void someHumanMethod(T user) { 8 // Your custom implementation 9 } 10 } 11 12 interface ContactRepository<T> { 13 14 void someContactMethod(T user); 15 16 User anotherContactMethod(T user); 17 18 <S extends T> S save(S entity); 19 } 20 21 class ContactRepositoryImpl<T> implements ContactRepository<T> { 22 23 public void someContactMethod(T user) { 24 // Your custom implementation 25 } 26 27 public User anotherContactMethod(T user) { 28 // Your custom implementation 29 } 30 31 public <S extends T> S save(S entity) { 32 // Your custom implementation 33 } 34 }
2 继承自定义的Repository接口:
interface UserRepository extends CrudRepository<User, Long>, HumanRepository, ContactRepository { // Declare query methods here }
这样UserRepository中就具有了自定义的Repository中定义的能力,框架会自动以"Impl"为后缀去找HumanRepository、ContactRepository的实现类;此外,当接口中有同名方法时,自定义的Repository中的优先级比框架提供的高(如上面HumanRepository的save方法优先级比CrudRepository的高)。
Spring Data repositories are implemented by using fragments that form a repository composition. Fragments are the base repository, functional aspects (such as QueryDsl), and custom interfaces along with their implementation. Each time you add an interface to your repository interface, you enhance the composition by adding a fragment. The base repository and repository aspect implementations are provided by each Spring Data module.
Repositories may be composed of multiple custom implementations that are imported in the order of their declaration. Custom implementations have a higher priority than the base implementation and repository aspects. This ordering lets you override base repository and aspect methods and resolves ambiguity if two fragments contribute the same method signature.
Customize the Base Repository
当想要修改所有业务Repository的某个行为时,一种做法是如上节所说的方式让所有业务Repository都显式继承某个自定义的Repository,更好的做法是修改框架的Base Repository。
以修改框架的save方法的实现为例,两步:
1 定义custom base repository:
1 //custom repository base class 2 class MyRepositoryImpl<T, ID> 3 extends SimpleJpaRepository<T, ID> { 4 5 private final EntityManager entityManager; 6 7 MyRepositoryImpl(JpaEntityInformation entityInformation, 8 EntityManager entityManager) { 9 super(entityInformation, entityManager); 10 11 // Keep the EntityManager around to used from the newly introduced methods. 12 this.entityManager = entityManager; 13 } 14 15 @Transactional 16 public <S extends T> S save(S entity) { 17 // implementation goes here 18 } 19 }
2 通过 @Enable${store}Repositories 的repositoryBaseClass参数指定自定义的Base Repository来替换框架默认者(默认的实现是SimpleJpaRepository)。
1 @Configuration 2 @EnableJpaRepositories(repositoryBaseClass = MyRepositoryImpl.class) 3 class ApplicationConfiguration { … }
此修改方式对所有的Repository有效,即各业务的Repository不用做任何改变(不用修改内部逻辑也不用继承修改后的Base Repository)就拥有自定义的Base Repository的行为。
Entity State-detection Strategies
Saving an entity can be performed with the
CrudRepository.save(…)method. It persists or merges the given entity by using the underlying JPAEntityManager. If the entity has not yet been persisted, Spring Data JPA saves the entity with a call to theentityManager.persist(…)method. Otherwise, it calls theentityManager.merge(…)method.Spring Data JPA offers the following strategies to detect whether an entity is new or not:
Version-Property and Id-Property inspection (default): By default Spring Data JPA inspects first if there is a Version-property of non-primitive type. If there is the entity is considered new if the value is
null. Without such a Version-property Spring Data JPA inspects the identifier property of the given entity. If the identifier property isnull, then the entity is assumed to be new. Otherwise, it is assumed to be not new.Implementing
Persistable: If an entity implementsPersistable, Spring Data JPA delegates the new detection to theisNew(…)method of the entity. See the JavaDoc for details.Implementing
EntityInformation: You can customize theEntityInformationabstraction used in theSimpleJpaRepositoryimplementation by creating a subclass ofJpaRepositoryFactoryand overriding thegetEntityInformation(…)method accordingly. You then have to register the custom implementation ofJpaRepositoryFactoryas a Spring bean. Note that this should be rarely necessary. See the JavaDoc for details.
JPA Annotation-based Configuration
通过代码配置使用的数据库、事务管理器、ddl等,示例:
@Configuration @EnableJpaRepositories @EnableTransactionManagement class ApplicationConfig { @Bean public DataSource dataSource() { EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder(); return builder.setType(EmbeddedDatabaseType.HSQL).build(); } @Bean public LocalContainerEntityManagerFactoryBean entityManagerFactory() { HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter(); vendorAdapter.setGenerateDdl(true); LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean(); factory.setJpaVendorAdapter(vendorAdapter); factory.setPackagesToScan("com.acme.domain"); factory.setDataSource(dataSource()); return factory; } @Bean public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) { JpaTransactionManager txManager = new JpaTransactionManager(); txManager.setEntityManagerFactory(entityManagerFactory); return txManager; } }
获取某个Entity所属的EntityManager
通常可通过Autowired获取,但当哟偶多讴歌EntityManager instance时可能会出错,除非通过@Qualifier指定名字。此时更好的做法是通过JpaContext获取:
class UserRepositoryImpl implements UserRepositoryCustom { private final EntityManager em; @Autowired public UserRepositoryImpl(JpaContext context) { this.em = context.getEntityManagerByManagedType(User.class); } … }
When working with multiple
EntityManagerinstances and custom repository implementations, you need to wire the correctEntityManagerinto the repository implementation class. You can do so by explicitly naming theEntityManagerin the@PersistenceContextannotation or, if theEntityManageris@Autowired, by using@Qualifier.As of Spring Data JPA 1.9, Spring Data JPA includes a class called
JpaContextthat lets you obtain theEntityManagerby managed domain class, assuming it is managed by only one of theEntityManagerinstances in the application. The following example shows how to useJpaContextin a custom repository:
趟过的坑
save/saveAndFlush
在一个事务内,调用save/saveAndFlush后再查询出来的数据实际上还是内存的数据(原因在于save是相对于Persistent Context而言而非DB而言的,见前面save方法的原理部分),因此如果数据库时间字段启用了CURRENT_TIMESTAMP ON UPDATE,则返回给调用者的时间实际上与数据库中的时间不一样。故,最好最好不要用自动更新时间,而是业务逻辑中手动设置更新时间。
时间类型的精度
如MySQL的DATETIME类型,默认是精确到秒的,故存入的时间戳的毫秒会被舍弃并根据四舍五入加入到秒(如1s573ms变成2s、1s473ms变成1s),从而保存进去与查出来的也会不一致。
关联删除
假设有user、admin两表,admin.user_id 与 user.id 对应。当要删除userId为"xx"一个管理员时:
1 若业务逻辑中未使用JPA软删除:
1.1 若后者通过外键关联前者,则直接从user删除id为"xx"的记录即可,此时会级联删除admin表的相应记录。当然要分别从两表删除记录也可,此时须保证先从admin表再从user表删除;
1.2 若无外键关联,则需要分别从user、admin删除该记录,顺序先后无关紧要;
2 若使用了软删除,对于软删除操作外键将不起作用(因为物理上并未删除记录),因此此时也只能分别从两表软删除记录。但不同的是,此时须先从admin再从user表删除记录。
若顺序相反,会发现user表的记录不会被软删除。猜测原因为:内存中存在userEntity、adminEntity且adminEntity.userByUserId引用了userEntity,导致delete userEntity时发现其被adminEntity引用了从而内部取消执行了delete操作。
在实际业务中一般都会启用软删除,所以物理删除的场景很少,从而上面1.1、1.2的场景很少。综上,在涉及到关联删除时,最好按拓扑排序的顺序(先引用者再被引用者)依次删除各Entity记录。
软删除的问题:
存储层面:数据未真正删除,因此数据只增不减, 量一大就会严重影响数据库读写性能。
SQL层面:查询语句都得加 isDelete=N,比较繁杂,特别是连表操作时;容易遗漏该条件导致查询结果出错,且不易发现。
代码层面:数据完整性需要由开发者维护——数据库的外键功能用不上了,需要开发者手动维护表间数据的关联关系,例如数据库本来自有的级联删除在软删除场景下需要有开发者手动一个个表中去删数据。显然编码更复杂了、产生的数据库操作语句更多了。
进阶
EntityManager

EntityManager定义了面向Object Model的各种操作的API接口,具体实现由各数据库厂商来提供。
Entity生命周期及相关Event
Entity的生命周期由EntityManager管理,其生命周期在persistence context内。EntityManager的生命周期(三种): a transaction、request、a users session
两个相关概念:persistence context(操作:persist、merge、detach、remove、clear、flush等)、transaction(操作:commit、rollback等)
Persistence Context:Acts as a Map of entities,the Map key is formed of the entity type (its class) and the entity identifier. 在一个应用内,一个Persistence Context 可对应多个EntityManager 。
Entity生命周期的四个状态:new、managed、detached、removed。其间转换关系如下:

Entity生命周期的四个基本操作(CRUD):(更多详情可参阅:https://en.wikibooks.org/wiki/Java_Persistence/Persisting、https://vladmihalcea.com/a-beginners-guide-to-jpa-hibernate-entity-state-transitions/、https://vladmihalcea.com/jpa-persist-and-merge/)
- persist(Insert)
- removed(Delete)
- merge(Update)
- find(Select)
这些操作为EntityManager的方法,所有的操作都先在persistence context进行,除非persistence context flush或transaction commit了。
应用实例:JPA Respsitory的saveAll方法内部实现是针对每个Entity去save,因此效率很低。可以稍加改造以批量save,工具代码:
@Component public class JpaBatchOperationUtilImpl implements JpaBatchOperationUtil{ /** 做一个保护,防止一个commit太长 */ private static final int MAX_BATCH_SIZE = 20000; @Autowired private EntityManager entityManager; @Override @Transactional(rollbackFor = RuntimeException.class) public <T> Iterable<T> batchInsert(Iterable<T> var1) { Iterator<T> iterator = var1.iterator(); int index = 0; while (iterator.hasNext()){ entityManager.persist(iterator.next()); index++; if (index % MAX_BATCH_SIZE == 0){ entityManager.flush(); entityManager.clear(); } } if (index % MAX_BATCH_SIZE != 0){ entityManager.flush(); entityManager.clear(); } return var1; } @Override @Transactional(rollbackFor = RuntimeException.class) public <T> Iterable<T> batchUpdate(Iterable<T> var1) { Iterator<T> iterator = var1.iterator(); int index = 0; while (iterator.hasNext()){ entityManager.merge(iterator.next()); index++; if (index % MAX_BATCH_SIZE == 0){ entityManager.flush(); entityManager.clear(); } } if (index % MAX_BATCH_SIZE != 0){ entityManager.flush(); entityManager.clear(); } return var1; } }
相关事件:
- @PrePersist/@PostPersist
- @PreRemove/@PostRemove
- @PreUpdate/@PostUpdate
- @PostLoad
The pre- and post-persist methods are useful for setting timestamps for auditing or setting default values.
详情参阅:https://dzone.com/articles/jpa-entity-lifecycle
实践踩坑:
实际使用过程中常会遇到“identifier of an instance of com.sensetime.sensestudy.common.entity.CourseEntity was altered from to” 之类的错
复现:在一个事务内修改entity的主键,此后执行其他任意查询或更新操作就会产生该错
原因:在entity处于managed生命周期时修改了entity主键导致的
解决:修改前先将该entity detach
在一个事务内对一个Entity 执行 delete 再执行 save,会报错:org.hibernate.ObjectDeletedException: deleted instance passed to merge: [com.xx1.xx2.teach_manage_dao.entity.eduadmin.InnolabcourseCustomerEntity#<null>];
Transaction
JPA提供两种transaction机制:Resource Local Transactions、JTA Transactions。详情参阅:https://en.wikibooks.org/wiki/Java_Persistence/Transactions
When a transaction commit fails, the transaction is automatically rolled back, and the persistence context cleared, and all managed objects detached.
Not only is there no way to handle a commit failure, but if any error occurs in an query before the commit, the transaction will be marked for rollback, so there is no real way to handle any error.
Cache
参阅:https://en.wikibooks.org/wiki/Java_Persistence/Caching
更多参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号