Hadoop入门
1、概述
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构(http://hadoop.apache.org/),用java语言开发而成。其可以在大量计算机组成的集群中对海量数据进行分布式计算,让用户在不了解分布式底层细节的情况下,开发出可靠、可扩展的分布式计算应用。Hadoop框架中最核心的设计包括HDFS、YARN、MapReduce:
1、HDFS集群负责提供海量数据存储,集群中的角色主要有NameNode、DataNode、SecondaryNameNode;
- NameNode是Hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
- DataNode是负责存储数据的节点,每个存储数据的节点运行一个datanode守护进程。
- SecondaryNameNode提供周期检查点和清理任务。
2、MapReduce提供对数据的计算;
3、YARN负责对海量数据运算时的资源调度,集群中的角色主要有ResourceManager、NodeManager。
- ResourceManager负责接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,并负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
- NodeManager是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
当以分布式模式运行时,NameNode、SecondaryNameNode、ResourceManager是master,DataNode、NodeManager是worker。
2、安装
1、环境准备:Hadoop及Java。
- Hadoop:http://hadoop.apache.org/releases.html,下载并解压。
- JDK:Hadoop依赖于Java,JDK版本跟具体选用的Hadoop版本有关,比如这里用Hadoop-3.0.0, 其要求Java版本至少为Java 8。
Hadoop目录说明:
1. bin:Hadoop最基本的管理脚本和使用脚本所在目录
2. etc:Hadoop配置文件所在的目录,包括core-site.xml、hdfs-site.xml、mapred-site.xml等
3. include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++语言访问HDFS或者编写MapReduce程序
4. lib:该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
5. libexec:各个服务对应的Shell配置文件所在目录,可用于配置日志输出目录、启动参数(比如JVM参数)等基本信息。
6. sbin:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
7. share:Hadoop各个模块编译后的JAR包所在目录。
(看一些教程上说ssh 必须安装并且保证 sshd 一直运行,以便用 Hadoop 脚本管理远端Hadoop 守护进程: sudo apt-get install ssh ; sudo apt-get install rsync 。由于进行此实践时机子已具备这些条件,所以不知此说法是否为真)
2、将Hadoop、Java添加到环境变量:
编辑/etc/profile,将java、Hadoop添加到环境变量中,并执行source命令使配置生效。(当然也可以在其他位置配置如/etc/bash.bashrc,视希望的生效范围而定)
1 export JAVA_HOME=/usr/jdk/jdk1.8.0_73 2 export HADOOP_HOME=/root/zsm/hadoop-3.0.0 3 export PATH=$PATH:$HADOOP_HOME/bin:$JAVA_HOME/bin
设置好环境变量后,试着执行 hadoop version ,若正确显示结果,则安装成功。示例如下:
root@test-cu08:/usr/jdk/jdk1.8.0_73# hadoop version Hadoop 3.0.0 Source code repository https://git-wip-us.apache.org/repos/asf/hadoop.git -r c25427ceca461ee979d30edd7a4b0f50718e6533 Compiled by andrew on 2017-12-08T19:16Z Compiled with protoc 2.5.0 From source with checksum 397832cb5529187dc8cd74ad54ff22 This command was run using /root/zsm/hadoop-3.0.0/share/hadoop/common/hadoop-common-3.0.0.jar
3、运行
Hadoop可以以三种模式运行:单机模式(单机上一个Hadoop进程)、伪分布式(单机上多个Hadoop进程)、完全分布式。执行 hadoop version 就是以单机模式运行。当要以伪分布式或完全分布式模式运行时,需要在/etc/hadoop/hadoop-env.sh中设置JAVA_HOME。
当以分布式模式运行时,NameNode、SecondaryNameNode、ResourceManager是master,DataNode、NodeManager是worker。
下面分别以三种模式运行Hadoop自带的wordcount示例。
3.1、单机模式
以单机模式运行系统自带的wordcount示例(假定当前在hadoop的根目录~/hadoop-3.0.0):
- 创建目录用来放输入文件: mkdir input
- 复制输入文件到该目录: cp etc/hadoop/*.xml input
- 运行wordcount并将结果输出到指定文件夹: ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount input myoutput
- 查看结果: cat myoutput/* ,会列出每个单词出现的次数且单词按字母排序
3.2、伪分布式模式
3.2.1、运行
Hadoop 可以在单节点上以所谓的伪分布式模式运行,此时每一个 Hadoop 守护进程都作为一个独立的 Java 进程运行。
(一些教程中说需要配置机器免秘钥登录,进行此实践时机子已具备该条件,故不知该条件是否为必须)
1、配置Java:在 /etc/hadoop/hadoop-env.sh 设置好JAVA_HOME
2、编辑 etc/hadoop/core-site.xml :
1 <!--HDFS NameNode的master节点的URL地址--> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://test-cu05:9000</value> 5 </property> 6 7 <!-- Hadoop的运行时文件存放路径,hdfs的NameNode、DataNode等数据存放在此下。也可通过dfs.namenode.name.dir、dfs.namenode.data.dir分别配置。--> 8 <property> 9 <name>hadoop.tmp.dir</name> 10 <value>/root/zsm/hadoop-3.0.0/zsmtmp</value> 11 </property>
3、编辑 etc/hadoop/hdfs-site.xml :
1 <!-- 副本的数量,默认是3,应小于datanode机器数量 --> 2 <configuration> 3 <property> 4 <name>dfs.replication</name> 5 <value>1</value> 6 </property> 7 </configuration>
4、执行:
- 初次执行时,格式化HDFS: bin/hdfs namenode -format ,包含“INFO common.Storage: Storage directory /root/zsm/hadoop-3.0.0/zsmtmp/dfs/name has been successfully formatted.”则说明格式化成功。
- 运行 sbin/start-dfs.sh 启动NameNode、DataNode、SecondaryNameNode守护进程; sbin/stop-dfs.sh 可停止之。
- 运行 sbin/start-yarn.sh 启动ResourceManager、NodeManager是进程; sbin/stop-yarn.sh 可停止之。
也可以执行 sbin/start-all.sh 、 sbin/stop-all.sh 来启动上述的HDFS、YARN。此外,也可以 bin/hdfs --daemon start namenode 分别启动或停止namenode、datanode等。结果如下:
root@test-cu05:~/zsm/hadoop-3.0.0# jps 4928 NodeManager 4562 SecondaryNameNode 4331 DataNode 4813 ResourceManager 4222 NameNode 5326 Jps
此时,访问http://ip:9870 和 http://ip:8088 分别可以看到HDFS(NameNode)、YARN(ResourceManager)的管理页面:

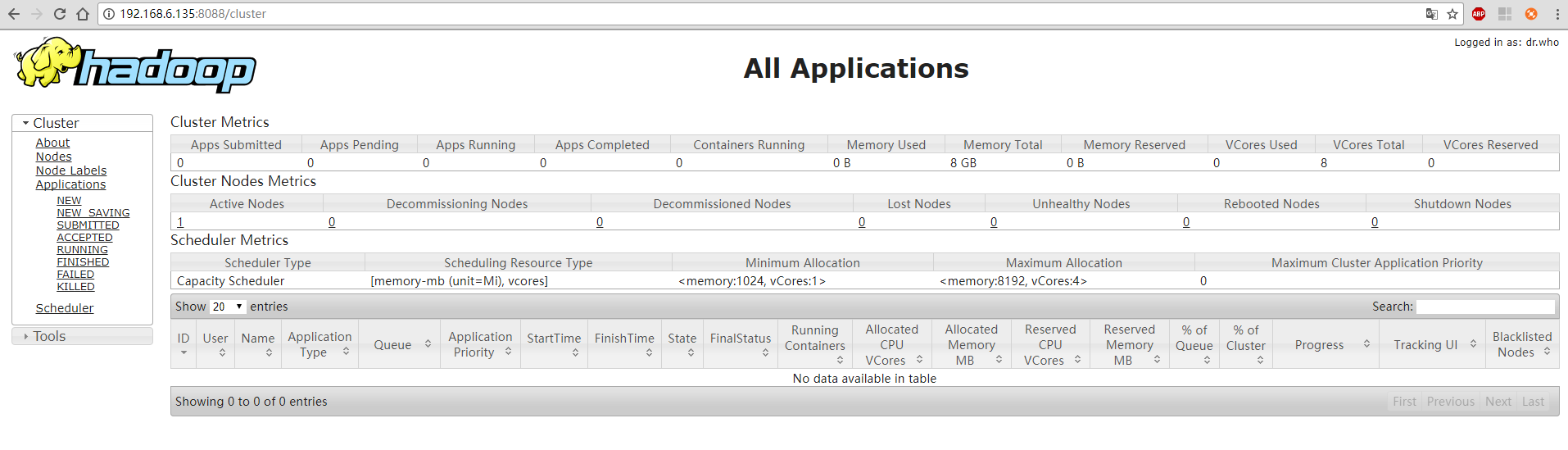
注(几个坑):
1、执行上面dfs的 sbin/start-dfs.sh 或 sbin/stop-dfs.sh 命令可能报 ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch. 等错误,这是由于缺少用户定义造成的,解决方法是在两个sh文件的顶部添加相应定义,如:
HDFS_DATANODE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
相似地,执行yarn相关的命令时会有 ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation. 等错误,解决方法相似,在脚本顶部添加如下定义:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
2、HDFS的管理页面端口在Hadoop 3.0中改为了9870,而在此前的版本中为50070
3、在重新执行格式化NameNode的命令 bin/hdfs namenode -format 后,再次启动HDFS时可能DataNode起不起来。解决:重新格式化之前需要清空所配置的hadoop.tmp.dir下的dfs下的name和data文件夹以解决datanode无法启动的问题,若未配置存储路径,则在Linux下默认为/tmp。
3.2.2、wordcount示例
Hadoop自带wordcount示例,我们可以通过Hadoop shell运行之(关于Hadoop shell可以参见后文)。命令如下(假定 pwd 的结果为 ~/hadoop-3.0.0 ):
- 在HDFS上创建文件夹放输入文件: hadoop fs -mkdir /input
- 从本地将输入文件复制到HDFS上该文件夹下: hadoop fs -put etc/hadoop/*.xml /input
- (官方教程上说在执行wordcount之前需要创建 /user/<username>目录,实际上不手动创建也可,执行时会自动创建)
- 执行wordcount并把结果输出到指定目录: ./bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input /myoutput 。
- 查看结果: hadoop fs -cat /myoutput/* (也可以将结果通过 hadoop fs -get 命令拷回到本地查看),会列出每个单词出现的次数并按单词字母序排序。
与上面单机模式下wordcount的运行不同,这里输入和输出内容都放在HDFS中,而单机模式下是放在本地文件系统中。
3.3、完全分布式模式
3.3.1、运行
我们这里有四台测试机子,hostname分别为test-cu05、test-cu06、test-cu07、test-cu08并配置好了免密码登录。其使用规划如下:
| 主机名 | ip | 功能 | 运行的角色 |
| test-cu05 | 192.168.6.135 | master | NameNode/SecondaryNameNode/ResourceManager |
| test-cu06 | 192.168.6.136 | worker | DataNode/NodeManager |
| test-cu07 | 192.168.6.137 | worker | DataNode/NodeManager |
| test-cu08 | 192.168.6.138 | worker | DataNode/NodeManager |
完全分布式运行方法与上面所述伪分布式的类似,上述伪分布式模式运行在test-cu05上,在该配置基础上只要做少量修改:
- 指定作为worker的机子:编辑 etc/hadoop/workers ,添加test-cu06、test-cu07、test-cu08,各占一行
- 将整个配置好的hadoop复制到剩下三台机子上。
- 前面在core-site.xml中已通过fs.defaultFS配置NameNode运行在test-cu05上,因此在NameNode所在的test-cu05上运行: ./sbin/start-all.sh 。
正常的话在test-cu05上会启动NameNode/SecondaryNameNode/ResourceManager、在其他三个上会启动DataNode/NodeManager,此外,在http://192.168.6.135:9870上可以看到worker:
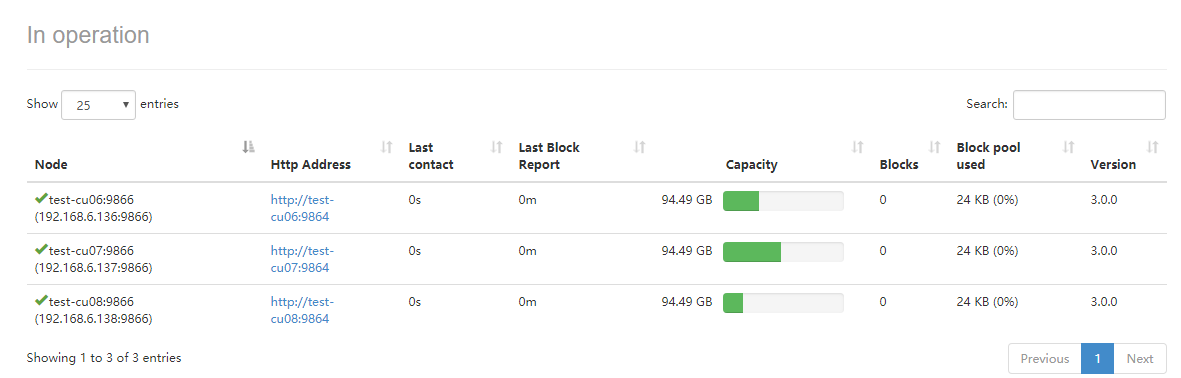
这里只介绍了最简配置,还有很多配置项,如 core-site.xml里dfs.namenode.name.dir、dfs.datenode.name.dir,yarn-site.xml、mapred-site.xml的配置等,可以参考官方文档。
3.3.2、wordcount示例
完全分布式模式下wordcount运行示例与上面伪分布式模式下的一样,不再赘述。
4、HDFS操作
4.1、Hadoop shell
既然HDFS是一种文件系统,那么对HDFS的操作类似于对普通文件系统的操作。如文件/文件夹的创建、修改、删除、重命名等,相应的命令与Linux shell命令类似,如ls、mkdir、rm等。
命令格式: hadoop fs [generic options] ,如 hadoop fs -mkdir /gps 。
其中,选项部分与Linux shell中的命令类似,只不过文件路径的表示格式不同,使用URI格式,即scheme://authority/path。对HDFS文件系统,scheme是hdfs,如;对本地文件系统,scheme是file,均可省略。当“hdfs://namenode:namenodeport”简写为“/parent/child”,此时默认使用core-site.xml里配置项fs.defaultFS的值,即-NameNode的master节点的URL地址。如按上面的配置,“/hadoop”就是指“hdfs://localhost:9000/hadoop”。
主要命令:
1 -help 查看命令使用方法,如hadoop fs -help ls 2 3 文件创建与删除: 4 -ls 列出某个目录下的文件和目录 5 -mkdir 创建目录 6 -count 统计某个目录下的文件和目录个数 7 -du 统计某个目录下各文件大小 8 -rm 删文件或空白目录 9 -rmr 递归删除目录下的文件及子目录 10 11 文件查看: 12 -touchz 创建空白文件 13 -stat 显示某个文件的信息 14 -cat 显示某个文件的内容 15 -text 同上 16 -tail 查看文件尾部内容 17 18 文件修改: 19 -chmod 修改文件权限 20 -chown 修改文件属主 21 -chgrp 修改文件属组 22 23 文件或目录在hdfs文件系统内部复制或移动: 24 -mv 25 -cp 26 27 文件或目录在本地文件系统与hdfs文件系统间复制: 28 -put file1 file2 [hdfs://localhost:9000]/gps 29 -get [hdfs://localhost:9000]/gps/record.txt ./
更多详情,可参见官方文档FileSystem Shell。
4.2、Java API
通过Java API实现上面Hadoop Shell的操作。
1、建立Java Maven项目,pom.xml里引入hadoop-common、hadoop-mapreduce-client-core依赖:


<!-- 引入hadoop-common Jar包 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <!--未引入如下依赖时,运行时候总是报:org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs"--> <!-- 引入hadoop-mapreduce-client-core Jar包 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.0.0</version> </dependency>
注:若只引入第一个依赖,则运行时候总是报:org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs",通过引入后一个依赖解决。
2、Java API实现Hadoop Shell操作,主要是借助FileSystem对象的open、create、delete等方法来实现。示例如下:
1 import java.io.FileInputStream; 2 import java.io.FileOutputStream; 3 import java.io.InputStream; 4 import java.io.OutputStream; 5 import java.net.URI; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.IOUtils; 11 12 /** 13 * HDFS文件系统操作,通过FileSystem对象的create、delete等方法实现。 14 */ 15 public class HadoopShell { 16 private static final String namenodeURI = "hdfs://192.168.6.135:9000"; 17 private static final String fileName = "log4j.properties"; 18 19 private static final String localFilePath = "./test/" + fileName; 20 private static final String hdfsFilePath = "/test/" + fileName; 21 22 public static void main(String[] args) throws Exception { 23 // uploadFile(); 24 downloadFile(); 25 // deleteFile(); 26 // makeDir(); 27 } 28 29 // 读取文件。从HDFS文件系统复制文件到本地 30 public static void downloadFile() throws Exception { 31 // 获得FileSystem对象 32 FileSystem fileSystem = FileSystem.get(new URI(namenodeURI), new Configuration());// namenode master uri 33 // 调用open方法进行下载,参数HDFS路径 34 InputStream in = fileSystem.open(new Path(hdfsFilePath)); 35 // 创建输出流,参数指定文件输出地址 36 OutputStream out = new FileOutputStream(localFilePath); 37 // 使用Hadoop提供的IOUtils,将in的内容copy到out,设置buffSize大小,是否关闭流设置true 38 IOUtils.copyBytes(in, out, 4096, true); 39 } 40 41 // 创建文件。从本地文件上传到HDFS文件系统上 42 public static void uploadFile() throws Exception { 43 // 获得FileSystem对象,指定使用root用户上传 44 FileSystem fileSystem = FileSystem.get(new URI(namenodeURI), new Configuration(), "root");// namenode master uri 45 // 调用create方法指定文件上传,参数为HDFS上传路径 46 OutputStream out = fileSystem.create(new Path(hdfsFilePath)); 47 // 创建输入流,参数指定文件地址。需要确保该文件存在。 48 InputStream in = new FileInputStream(localFilePath); 49 // 使用Hadoop提供的IOUtils,将in的内容copy到out,设置buffSize大小,是否关闭流设置true 50 IOUtils.copyBytes(in, out, 4096, true); 51 } 52 53 // 删除文件。文件可以为目录 54 public static void deleteFile() throws Exception { 55 // 获得FileSystem对象,指定使用root用户删除 56 FileSystem fileSystem = FileSystem.get(new URI(namenodeURI), new Configuration(), "root");// namenode master uri 57 // 调用delete方法,删除指定的文件。参数:false:表示是否递归删除 58 boolean flag = fileSystem.delete(new Path("/dir1"), false); 59 System.out.println(flag); 60 } 61 62 // 创建目录 63 public static void makeDir() throws Exception { 64 // 获得FileSystem对象,指定使用root用户创建 65 FileSystem fileSystem = FileSystem.get(new URI(namenodeURI), new Configuration(), "root");// namenode master uri 66 // // 调用mkdirs方法,在HDFS文件服务器上创建文件夹 67 boolean flag = fileSystem.mkdirs(new Path("/dir1")); 68 System.out.println(flag); 69 } 70 }
5、MapReduce示例
(参考自 MapReduce教程)
5.1、MapReduce简介
MapReduce是一种编程模型,用于大规模数据集的离线批量并行运算,用于解决海量数据的计算问题。
MapReduce整体上包括Map和Reduce两个过程,当向MapReduce框架提交一个计算作业时,它首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce任务的主要目标是把前面若干个Map的输出汇总到一起并输出。Map的输入和Reduce的输出数据都存在HDFS上。其模型实现图如下:
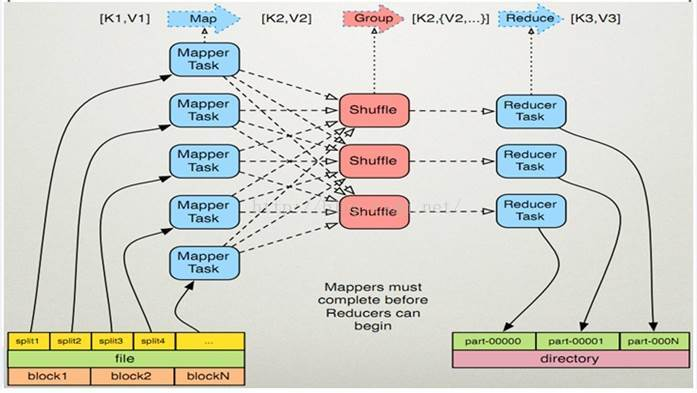
更细地看,MapReduce包括Map、Partition、Shuffle、Reduce几个过程。
输入和输出:
MapReduce框架运行在<key, value>键值对上,也就是说,框架把作业的输入看为是一组<key, value>键值对,同样也产出一组<key,value>键值对做为作业的输出,这两组键值对的类型可能不同。由于框架需要对key和value的类(classes)进行序列化操作,因此,key、value类要实现Writable接口。另外,为了方便框架执行排序操作,key类必须实现 WritableComparable接口。
从图中可以看出,在Reduce之前会进行shuffle操作,其作用是将同一key的value收集在一起也就是对key分类,并对同一类的按key进行排序,其结果作为Reduce阶段的输入,也就是reduce 的Iterable value;Map的输出分配到shuffle上的过程就是partition的过程,Hadoop MapReduce有默认的HashPartitioner,其将所有结果写入一个partition文件,用户可以重写之。
5.2、wordcount示例
我们用Java写MapReduce wordcount示例,运行在上节完全分布式模式的Hadoop上。
1、数据准备:输入数据放在HDFS的 /wordcount/words.txt 下。
2、编码,比较简单:
- 建立Maven项目,依赖hadoop-common、hadoop-mapreduce-client-core(与4.2节所列依赖相同)。
- 重写map、reduce函数,编写main函数指定输入和输出信息。
- WCMapper.java:
View Code
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 /* 8 * 继承Mapper类需要定义四、输出类型泛型: 9 * 四个泛型类型分别代表: 10 * KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...) 11 * ValueIn Mapper的输入数据的Value,这里是每行文字 12 * KeyOut Mapper的输出数据的Key,这里是一个单词如"hello" 13 * ValueOut Mapper的输出数据的Value,这里是该单词出现的次数,为1 14 * 15 * Writable接口是一个实现了序列化协议的序列化对象。 16 * 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。 17 * LongWritable类型:Hadoop.io对Long类型的封装类型 18 */ 19 public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> { 20 21 /** 22 * 重写Map方法 23 */ 24 @Override 25 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) 26 throws IOException, InterruptedException { 27 // 获得每行文档内容,并且进行折分 28 String[] words = value.toString().split(" "); 29 30 // 遍历折份的内容 31 for (String word : words) { 32 // 每出现一次则在原来的基础上:+1 33 context.write(new Text(word), new LongWritable(1)); 34 } 35 } 36 }
- WCReducer.java:
View Code
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 /* 8 * 继承Reducer类需要定义四个输出、输出类型泛型: 9 * 四个泛型类型分别代表: 10 * KeyIn Reducer的输入数据的Key,这里是一个单词如"hello" 11 * ValueIn Reducer的输入数据的Value,这里是该单词分别出现的次数,这里都为1 12 * KeyOut Reducer的输出数据的Key,这里是一个单词 13 * ValueOut Reducer的输出数据的Value,这里是该单词出现的总次数 14 */ 15 public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { 16 /** 17 * 重写reduce方法 18 */ 19 @Override 20 protected void reduce(Text key, Iterable<LongWritable> values, 21 Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { 22 long sum = 0; 23 for (LongWritable i : values) { 24 // i.get转换成long类型 25 sum += i.get(); 26 } 27 // 输出总计结果 28 context.write(key, new LongWritable(sum)); 29 } 30 }
- WordCount.java:
View Code
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 public class WordCount { 12 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 13 // 创建job对象 14 Job job = Job.getInstance(new Configuration()); 15 // 指定程序的入口 16 job.setJarByClass(WordCount.class); 17 18 // 指定自定义的Mapper阶段的任务处理类 19 job.setMapperClass(WCMapper.class); 20 job.setMapOutputKeyClass(Text.class); 21 job.setMapOutputValueClass(LongWritable.class); 22 // 数据HDFS文件服务器读取数据路径 23 FileInputFormat.setInputPaths(job, new Path("/wordcount/words.txt")); // 需要保证该文件存在 24 25 // 指定自定义的Reducer阶段的任务处理类 26 job.setReducerClass(WCReducer.class); 27 // 设置最后输出结果的Key和Value的类型 28 job.setOutputKeyClass(Text.class); 29 job.setOutputValueClass(LongWritable.class); 30 // 将计算的结果上传到HDFS服务 31 FileOutputFormat.setOutputPath(job, new Path("/wordcount/wordsResult"));// 会自动创建该目录并把结果写在该目录下 32 33 // 执行提交job方法,直到完成,参数true打印进度和详情 34 job.waitForCompletion(true); 35 System.out.println("Finished"); 36 } 37 }
- WCMapper.java:
- 导出为jar 文件并指定主函数,得到wc.jar。
- 将wc.jar放在Hadoop NameNode上,执行 hadoop jar wc.jar ,结果会写入到代码中指定的输出目录下。与前面几节中介绍的wordcount示例一样,得到每个单词的词频且单词按字母序排序。如下:
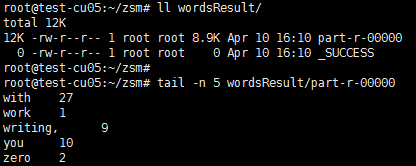
5.3、自定义Partition示例
如5.1节所述,Map的输出会根据key被划分到不同地方进行Shuffle,也就是进行Partition。Hadoop MapReduce默认实现为HashPartition,该实现将结果分到一个分区上。我们可以重写该类的getPartition方法实现自定义划分规则,从而实现某些功能并把最终的输出数据分到不同的文件中。如将手机号分段,不同段写入不同文件;按省份把数据划分到不同文件中等。
这里示例实现的功能为:将电话号码归属地数据按运营商分为四类,每一类内按记录的id降序排。
1、数据准备:输入文件为电话号码归属地数据,每条格式如下:212909,"1709996","广东","东莞","虚拟运营商","0769","511700" , (下载:2016phonelocation.txt)
2、编码:与上面wordcount类似,不同的是需要重写Partition并指定用此分区规则。
- UserMapper.java:
View Code
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.NullWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 /* 9 * 继承Mapper类需要定义四、输出类型泛型: 10 * 四个泛型类型分别代表: 11 * KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...) 12 * ValueIn Mapper的输入数据的Value,这里是每行文字 13 * KeyOut Mapper的输出数据的Key,这里是序列化对象UserRecord 14 * ValueOut Mapper的输出数据的Value,这里是NullWritable 15 * 16 * Writable接口是一个实现了序列化协议的序列化对象。 17 * 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。 18 * LongWritable类型:Hadoop.io对Long类型的封装类型 19 */ 20 public class UserMapper extends Mapper<LongWritable, Text, MyUserRecordBean, NullWritable> { 21 @Override 22 protected void map(LongWritable key, Text value, 23 Mapper<LongWritable, Text, MyUserRecordBean, NullWritable>.Context context) 24 throws IOException, InterruptedException { 25 26 // 将每行的数据以逗号切分数据,获得每个字段数据。一条数据记录示例:1,"1300000","山东","济南","中国联通","0531","250000" 27 String[] fields = value.toString().split(","); 28 29 // 赋值userRecord 30 MyUserRecordBean user = new MyUserRecordBean(Integer.parseInt(fields[0]), fields[1], fields[2], fields[3], fields[4], 31 fields[5], fields[6]); 32 33 // 将对象序列化 34 context.write(user, NullWritable.get()); 35 } 36 }
- MyPartitioner.java:
View Code
1 import java.util.HashMap; 2 import java.util.Map; 3 4 import org.apache.hadoop.io.NullWritable; 5 import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 6 7 /** 8 * HashPartitioner是MapReduce中默认的Partitioner,用于将Map的结果根据key分配到不同的Reduce中去。<br> 9 * 分区的数量与reduce的数量一样,默认是1,每个分区京Reduce处理后分别写入到一个文件中。 10 */ 11 public class MyPartitioner extends HashPartitioner<MyUserRecordBean, NullWritable> { 12 13 private static Map<String, Integer> myMap = new HashMap<String, Integer>(); 14 static { 15 myMap.put("\"中国联通\"", 0); 16 myMap.put("\"中国移动\"", 1); 17 myMap.put("\"中国电信\"", 2); 18 } 19 20 /** 21 * 实现自定义的getPartition()方法,自定义分区规则。这里按运营商划分,包括联通、移动、电信,其他 四个。<br> 22 * 返回值必须在[0,numPartitions)范围内。否则运行报错 23 */ 24 @Override 25 public int getPartition(MyUserRecordBean userRecord, NullWritable value, int numPartitions) { 26 String operator = userRecord.getOperator(); 27 Integer partion = myMap.get(operator); 28 if (partion == null) { 29 partion = 3; 30 // System.out.println("******partition is null," + operator + "," + myMap.get(operator)); 31 } 32 return partion; 33 } 34 }
- UserReducer.java:
View Code
1 import java.io.IOException; 2 3 import org.apache.hadoop.io.NullWritable; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 /* 7 * 继承Reducer类需要定义四个输出、输出类型泛型: 8 * 四个泛型类型分别代表: 9 * KeyIn Reducer的输入数据的Key,这里是序列化对象UserRecord 10 * ValueIn Reducer的输入数据的Value,这里是NullWritable 11 * KeyOut Reducer的输出数据的Key,这里是序列化对象UserRecord 12 * ValueOut Reducer的输出数据的Value,这里是NullWritable 13 */ 14 public class UserReducer extends Reducer<MyUserRecordBean, NullWritable, MyUserRecordBean, NullWritable> { 15 16 @Override 17 protected void reduce(MyUserRecordBean userRecord, Iterable<NullWritable> values, 18 Reducer<MyUserRecordBean, NullWritable, MyUserRecordBean, NullWritable>.Context context) 19 throws IOException, InterruptedException { 20 21 // do nothing... 22 context.write(userRecord, NullWritable.get()); 23 } 24 }
- MainUserGroup.java:
View Code
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.NullWritable; 4 import org.apache.hadoop.mapreduce.Job; 5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 7 8 /** 9 * @author zsm 10 * @date 2018年4月10日 下午5:43:15 11 */ 12 public class MainUserGroup { 13 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 14 // 创建job对象 15 Job job = Job.getInstance(new Configuration()); 16 // 指定程序的入口 17 job.setJarByClass(MainUserGroup.class); 18 19 // 指定自定义的Mapper阶段的任务处理类 20 job.setMapperClass(UserMapper.class); 21 job.setMapOutputKeyClass(MyUserRecordBean.class); 22 job.setMapOutputValueClass(NullWritable.class); 23 // 数据HDFS文件服务器读取数据路径 24 FileInputFormat.setInputPaths(job, new Path("/usergroup/user.txt")); // 需要保证该文件存在 25 26 // 指定自定义的Reducer阶段的任务处理类 27 job.setReducerClass(UserReducer.class); 28 // 设置最后输出结果的Key和Value的类型 29 job.setOutputKeyClass(MyUserRecordBean.class); 30 job.setOutputValueClass(NullWritable.class); 31 32 // 设置定义分区的处理类 33 job.setPartitionerClass(MyPartitioner.class); 34 35 // 默认ReduceTasks数是1 36 // 我们根据运营商分成四类,故设为4。结果会被分别写入到四个文件中。 37 job.setNumReduceTasks(4); 38 39 // 将计算的结果上传到HDFS服务 40 FileOutputFormat.setOutputPath(job, new Path("/usergroup/groupResult"));// 会自动创建该目录并把结果写在该目录下 41 42 // 执行提交job方法,直到完成,参数true打印进度和详情 43 job.waitForCompletion(true); 44 System.out.println("Finished"); 45 46 } 47 }
- MyUserRecordBean.java:
View Code
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.WritableComparable; 6 7 /** 8 * 此类作为Map和Reduce中间过渡文件里结构化对象。<br> 9 * 作为key、value的类必须实现Writable接口,该接口包括readFields、write方法;此外key还必须实现WritableComparable接口的compareTo方法。WritableComparable接口是Writable接口的子类。 10 */ 11 public class MyUserRecordBean implements WritableComparable<MyUserRecordBean> { 12 13 int id;// 记录的id 14 String phonePrefix;// 号码段 15 String province; 16 String city; 17 String operator;// 运营商 18 String areaCode;// 区号 19 String postCode;// 邮编 20 21 public MyUserRecordBean() {// 必须有默认构造方法 22 } 23 24 public MyUserRecordBean(int id, String phonePrefix, String province, String city, String operator, String areaCode, 25 String postCode) { 26 super(); 27 this.id = id; 28 this.phonePrefix = phonePrefix; 29 this.province = province; 30 this.city = city; 31 this.operator = operator; 32 this.areaCode = areaCode; 33 this.postCode = postCode; 34 } 35 36 public int getId() { 37 return id; 38 } 39 40 public void setId(int id) { 41 this.id = id; 42 } 43 44 public String getPhonePrefix() { 45 return phonePrefix; 46 } 47 48 public void setPhonePrefix(String phonePrefix) { 49 this.phonePrefix = phonePrefix; 50 } 51 52 public String getProvince() { 53 return province; 54 } 55 56 public void setProvince(String province) { 57 this.province = province; 58 } 59 60 public String getCity() { 61 return city; 62 } 63 64 public void setCity(String city) { 65 this.city = city; 66 } 67 68 public String getOperator() { 69 return operator; 70 } 71 72 public void setOperator(String operator) { 73 this.operator = operator; 74 } 75 76 public String getAreaCode() { 77 return areaCode; 78 } 79 80 public void setAreaCode(String areaCode) { 81 this.areaCode = areaCode; 82 } 83 84 public String getPostCode() { 85 return postCode; 86 } 87 88 public void setPostCode(String postCode) { 89 this.postCode = postCode; 90 } 91 92 @Override 93 public String toString() { 94 return id + "," + phonePrefix + "," + province + "," + city + "," + operator + "," + areaCode + "," + postCode; 95 } 96 97 @Override 98 public void readFields(DataInput in) throws IOException {// 必须实现 99 this.id = in.readInt(); 100 this.phonePrefix = in.readUTF(); 101 this.province = in.readUTF(); 102 this.city = in.readUTF(); 103 this.operator = in.readUTF(); 104 this.areaCode = in.readUTF(); 105 this.postCode = in.readUTF(); 106 } 107 108 @Override 109 public void write(DataOutput out) throws IOException {// 必须实现 110 out.writeInt(this.id); 111 out.writeUTF(phonePrefix); 112 out.writeUTF(province); 113 out.writeUTF(city); 114 out.writeUTF(operator); 115 out.writeUTF(areaCode); 116 out.writeUTF(postCode); 117 } 118 119 @Override 120 public int compareTo(MyUserRecordBean o) {// 定义排序方式,这里定义按id倒序排。若此类作为key,则必须实现此方法。 121 122 return o.id - this.id; 123 } 124 }
注:在MapReduce中作为key、value的类必须实现Writable接口,该接口包括readFields、write方法;此外key还必须实现WritableComparable接口的compareTo方法。WritableComparable接口是Writable接口的子类。上述MyUserRecordBean是作为Map与Reduce两过程的中间数据的。Map会将输出数据序列化,Shuffle根据数据流反序列化该对象,因此必须实现WritableComparable接口的相关方法。此外,该类必须明确写出一个不带参数的构造方法以便序列化框架对它们进行实例化。
3、导出jar文件并运行,过程与上面类似。
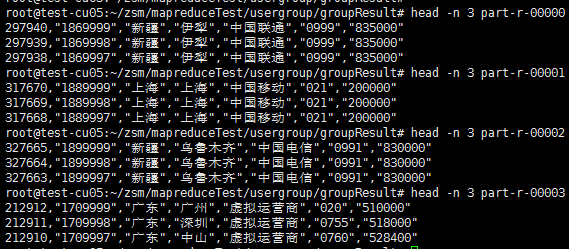
4、结果如下,可见分成了四个区并分别写入到四个文件中:

查看其中一个文件,可见按要求分类和排序了:
6、参考资料
https://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-common/SingleCluster.html
http://blog.csdn.net/yuan_xw/article/details/50039325
https://blog.csdn.net/yuan_xw/article/details/50867819

 浙公网安备 33010602011771号
浙公网安备 33010602011771号