Docker入门学习总结
1 什么是Docker
1.1 What
Docker是一种基于Linux内核实现的虚拟化技术,其在容器的基础上进一步封装了文件系统、网络、进程隔离等等,从而极大地简化了容器的创建和维护。Docker使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的namespace、cgroup以及 AUFS 类的 Union FS 等技术,实现文件系统隔离、网络隔离、进程隔离等各种资源隔离。
Docker 底层的核心技术包括 Linux 上的命名空间(Namespace,如pid namespace、mount namespace、network namespace等分别用来隔离进程、文件系统、网络)、控制组(Control groups)、Union 文件系统(Union file systems,Docker的数据卷和挂载用到此)和容器格式(Container format)。
Docker利用命名空间来做权限的隔离控制(文件系统、网络、进程隔离等)、利用 cgroups 来做资源分配(CPU、内存、IO等)、利用UnionFS来层次化组织镜像、利用Container Format来设计容器实现虚拟化。详见后文“进阶实现”一节。
Docker很重要的作用之一:隔离进程——Docker容器内的进程无法看到宿主机以及其他Docker容器内的进程,这样可以防止一个进程被入侵恶意访问或破坏其他非本Docker容器内的进程。
Docker口号:Build、Ship、Run;Build Once、Run Anywhere.
1.2 与传统虚拟机的区别
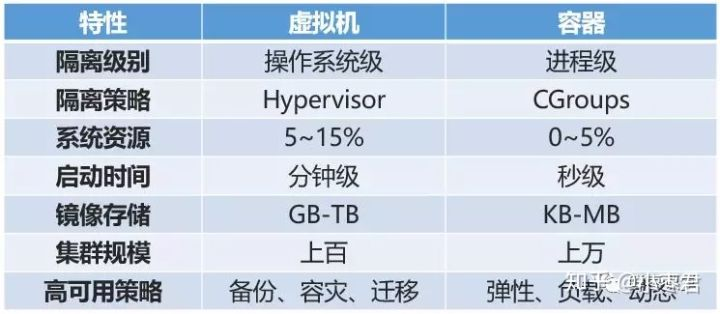
Docker和传统虚拟机的区别:传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。一个例子是,Docker容器内可通过卷、某种网络模式来访问宿主机的文件系统、网络等资源而虚拟机则做不到。
如下图展示了其区别:


传统虚拟机:在硬件和虚拟机间加了一层软件层Hypervisor(虚拟机管理程序),Hypervisor运行在宿主机OS上或直接运行在硬件上(rxxxxxx基于内核的KVM虚拟机)。运行在虚拟机上的操作系统是通过Hypervisor来最终分享硬件。运行在虚拟机上的操作系统是通过Hypervisor来最终分享硬件。
TODO...
更小(镜像大小、占用资源大小)、更快、更易扩展、更可靠。启动更快、一台服务器上可启动个数更多。
2 Docker四个核心概念
镜像Image:类似于虚拟机镜像,一般由一个基本操作系统环境和多个应用程序打包而成,是创建容器的模板。
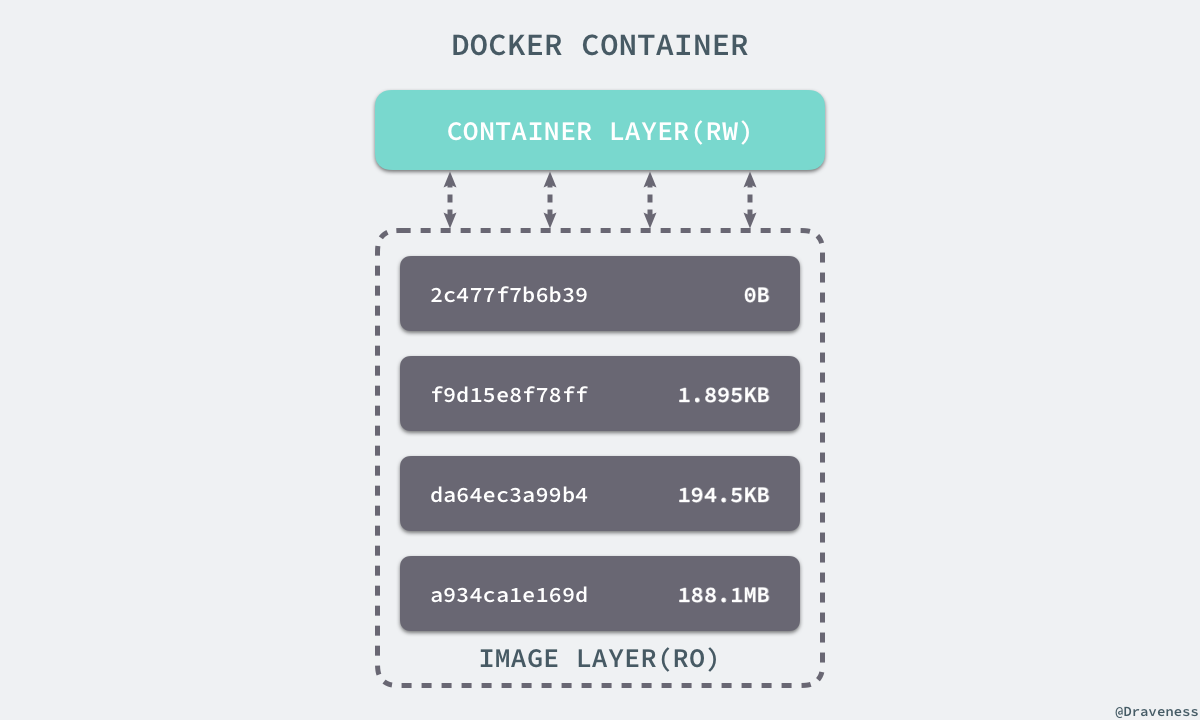
镜像本质是个文件系统,包含了容器所需的所有文件和运行容器所需的配置参数(用户、环境变量等)。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。


因为镜像包含操作系统完整的 root 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 Union FS 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 ISO 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
容器Container:可看作一个简易版的Linxu系统环境(包括root用户权限、进程空间、用户空间和网络空间等)以及运行在其中的应用程序打包而成的盒子。容器是以镜像为基础,再加一层容器存储层,组成多层存储结构去运行的。
该存储层随着容器的删除而删除,故该存储层应该保持无状态化即不写入任何数据。所有的文件写入操作都应该使用 数据卷(Volume)或者 绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
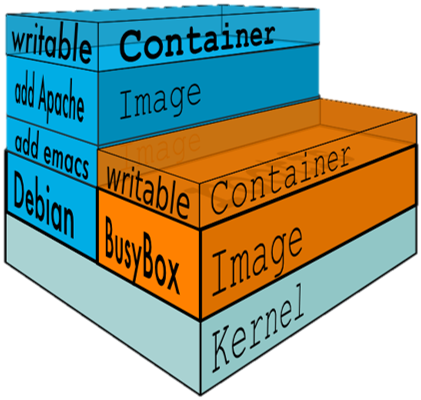
镜像( Image )和容器( Container )的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。容器实质是个进程。
容器和镜像的最大区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。
仓库Repository:就是一个集中存储、分发镜像的地方,类似于Maven的Repository。分为公共仓库和私有仓库,目前最大的公共仓库是官方提供的Docker Hub,此外国内的阿里云、腾讯云等也提供了公共仓库。
注册服务器Registry:管理仓库Repository的具体服务器。每个服务器上可以有多个仓库,每个仓库下面有多个镜像。Docker Hub、DaoCloud等就是Registry,也可以在本地搭建Registry供团队间分享镜像,公司内部通常有自己的Registry。内网搭建Registry可参阅:https://www.cnblogs.com/sparkdev/p/6890995.html
其他:
宿主机:运行Docker引擎的OS所在的服务器。
3 Docker架构
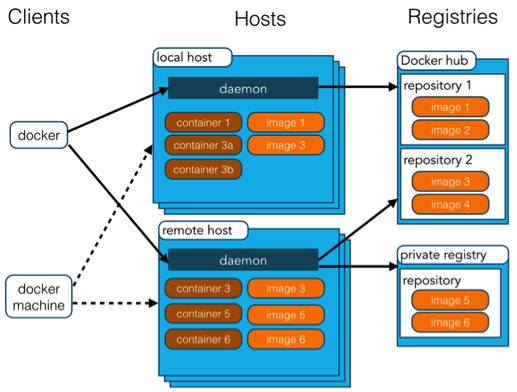
Docker 采用了 C/S 架构,包括客户端和服务端。客户端和服务端既可以运行在一个机器上,也可通过 socket 或者 RESTful API 来进行通信。
- Docker 守护进程 (Daemon)作为服务端接受来自客户端的请求,并处理这些请求(创建、运行、分发容器)。Docker 守护进程一般在宿主主机后台运行。
- Docker 客户端则为用户提供一系列可执行命令,用户用这些命令实现跟 Docker 守护进程交互。
|
Docker 镜像(Images) |
Docker 镜像是用于创建 Docker 容器的模板。 |
|
Docker 容器(Container) |
容器是独立运行的一个或一组应用。 |
|
Docker 客户端(Client) |
Docker 客户端通过命令行或者其他工具使用 Docker API (https://docs.docker.com/reference/api/docker_remote_api) 与 Docker 的守护进程通信。 |
|
Docker 主机(Host) |
一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
|
Docker 仓库(Registry) |
Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。 Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。 |
由于采用CS架构,因此可以通过修改环境变量DOCKER_HOST来操作远程的Docker Daemon,默认是localhost
4 安装Docker
Docker分为社区版CE和企业版EE,前者免费。不同OS及同种OS的不同版本上安装Docker的方法各异,详见 Docker安装。
这里以Ubuntu16.04为例。
1. apt源使用HTTPS以确保软件下载过程中不被篡改,故先安装HTTPS传输及CA证书相关:
sudo apt-get update sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ software-properties-common
2. 为确认所下载软件包的合法性,需添加软件源的GPG密钥: curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
3. 向/etc/apt/source.list添加Docker软件源:
sudo add-apt-repository \ "deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu \ $(lsb_release -cs) \ stable"
4. 更新apt软件包缓存,安装Docker CE: sudo apt-get update && sudo apt-get install docker-ce
5. 启动Docker CE:
设置docker服务开机启动: sudo systemctl enable docker
启动docker服务: sudo systemctl start docker
6. 测试是否正确安装: sudo docker run hello-world ,该命令首次运行会从Docker仓库下载hello-world镜像,输出如下信息表示运行成功:
Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world ca4f61b1923c: Pull complete Digest: sha256:be0cd392e45be79ffeffa6b05338b98ebb16c87b255f48e297ec7f98e123905c Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://cloud.docker.com/ For more examples and ideas, visit: https://docs.docker.com/engine/userguide/
7. 由于国内网络原因,拉取镜像会很慢,可以设置为国内仓库服务器:在 /etc/docker/daemon.json 添加如下内容(若文件不存在则先建之):
{ "registry-mirrors": [ "https://registry.docker-cn.com" ] }
然后重启服务:
sudo systemctl daemon-reload sudo systemctl restart docker
执行 docker info ,若看到 Registry Mirrors: https://registry.docker-cn.com/ 则说明修改成功。
8、普通用户加入Docker用户组
默认情况下,docker 命令会使用 Unix socket 与 Docker 引擎通讯。而只有 root 用户和 docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,更好地做法是将需要使用 docker 的用户加入 docker 用户组。
建立Docker用户组(一般安装完Docker后就默认创建了): $ sudo groupadd docker
将普通用户加入Docker用户组: $ sudo usermod -aG docker $USER
退出当前终端并重新登录即可。
5 镜像与容器操作
各命令具体用法可以通过 docker 命令 --help 或 docker help you_command 查看。下面稍做总结。
5.0 查找与推送镜像
查找示例: docker search centos ,会从镜像仓库中查找指定镜像。
推送示例: docker push yourhubusername/ubuntu:16.04 ,会推送到镜像服务器。不过需要事先注册镜像服务器账号,且只能传到自己账号的下面,因此需将待传的镜像标签改为账号前缀。详见:https://ropenscilabs.github.io/r-docker-tutorial/04-Dockerhub.html
5.1 拉取镜像
命令格式: docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签] ,如 $ docker pull ubuntu:16.04 。不写标签的话默认是latest,即最新版。在 Docker 1.13+ 版本中推荐使用 docker image 来管理镜像。
此外,也可以通过 docker import 导入容器,会创建相应的镜像。
具体可参见:获取镜像
5.2 容器创建与容器操作
运行示例: $ docker run -it --rm ubuntu:16.04 bash ,表示在终端交互式操作、容器退出后删除掉,运行的是linux下的bash,若不指定运行的命令则默认运行/bin/bash;可以指定运行其他命令,如: docker run -it ubuntu cat /etc/os-release
另一示例: docker run --label version=1.5 --name zsmserver -d -p 80:80 nginx , #从镜像nginx启动名为zsmserver的容器,监听80短口,若镜像不存在则会下载 。-p参数指定本机端口映射到容器的哪些端口,其本质是在宿主机iptable的nat表添加相应的规则;--label用于给容器加一些metadata如license、vendor等。通过docker inspect 可以看到这些信息。
当利用 docker run 来创建容器时,Docker 在后台运行的标准操作包括:
- 检查本地是否存在指定的镜像,不存在就从公有仓库下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行完毕后容器被终止
注:容器隔离指的是容器之间互相看不到对方容器内的进程、容器内也看不到宿主机进程。但容器启动后,在宿主机 ps 是可以看到容器内的进程的。
5.2.1 关于后台运行
可以通过-d参数让Docker在后台运行(守护态运行)而不是把命令执行结果输出到当前宿主主机下(即这里的后台是相对于宿主主机而言的)。但是,容器是否会长久运行,是和 docker run 指定的命令有关,和 -d 参数无关。
当以后台模式(-d)运行 run Dokcer容器时,容器内必须有一个前台进程(如top、tail等)否则容器就会结束退出(如service nginx start默认以后台模式运行),因为Docker觉得没事可做了。其本质原因是:docker 容器默认会把容器内部第一个进程,也就是pid=1的程序作为docker容器是否正在运行的依据,若该程序结束了则认为docker 容器挂了,从而docker容器便会直接退出,docker run的时候正是把command作为容器内部命令。
因此,要想避免容器运行就退出,可以在多个命令的最后加上top等命令,如 service nginx start && top 。详见:https://blog.csdn.net/meegomeego/article/details/50707532
5.2.2 其他容器操作命令
docker help your_command 或 docker your_command --help #查看命令详细用法
docker cp xxx xxx #files/folders between a container and the local filesystem
docker run 镜像名 [运行的程序命令及参数] #从镜像新建容器并启动,若镜像不存在则先下载
docker ps -a #查看所有容器,包括正在运行的、已终止的等
docker container ls #查看正在运行的容器,加 -a 参数与上个命令同效果
docker [container] start/stop/restart containerid_or_name #启动/停止/重启 已存在的容器
docker logs containerid_or_name #获取后台运行的容器的输出
docker exec -it containerid 命令 #重新进入后台运行的容器,也可以通过命令 docker attach containerid 进入,但这种方式下进入再退出时容器会跟着终止,所以推荐用exec方式。
docker inspect containerid_or_name #查看容器信息。为了查看容器ip,可以:docker inspect --format '{{ .NetworkSettings.IPAddress }}' containerid_or_name
docker [container] rm [-f -v] containerid #删除指定的容器。-f参数可删除运行中的容器 Docker会发SIGKILL信号给容器、-v参数删除容器关联的数据卷
docker container prune #删除所有终止状态的容器,也可以 docker rm $(docker ps -aq),括号里的命令功能是获取所有container的id
docker tag src_image_name new_image_name #为镜像重命名,如docker tag ubuntu:1.0 zsm/ubuntu:1.0
docker network create/connnect/disconnect/inspect/ls/prune/rm #网络管理
更多命令guide可参阅官方文档:https://docs.docker.com/engine/reference/run/
5.3 查看本地镜像
列出已下载镜像: docker images 或 docker image ls 。
- 显示的镜像大小是解压后的,官网Docker Hub上显示的则是压缩了的;
- 由于镜像是分层存储的,可以继承使用,因此总占用空间并不是各镜像占用大小的和;
- 该命令列出顶层镜像,如果要列出包括中间层镜像的所有,可以加-a参数。可以看出,这里的ls跟Linux下的ls命令用法类似,可以部分匹配等、还支持强大的过滤器参数,具体可输入help命令查看。如列出redis镜像的镜像ID: docker image ls -q redis
查看镜像、容器、数据卷所占用的空间: docker system df ,结果如下:

5.4 移除虚悬镜像
命令: docker image prune
实际上,可以通过 docker image/container/volumn/network prune 来删除不再被使用的镜像/容器/卷/网络,亦可用命令 docker system prune 一次移除这四者
5.5 删除本地镜像
命令: docker image rm [选项] <镜像1> [<镜像2> ...] 或 docker rmi [选项] <镜像1> [<镜像2> ...] ,这里的镜像标识可以是ID、镜像名、镜像摘要等。
- 删除镜像时实际上是在要求删除某个标签的镜像,由于一个镜像可对应多个标签,因此若删除指定标签的镜像后仍有其他标签指向该镜像则实际上不会删除该镜像,而只是标记指定标签被删除。
- 同样地,对于要删除的镜像,若有从该镜像启动的容器存在,则即使容器没在运行,该镜像也不会被删除,除非加 -f 参数指示强制删除。
5.6 定制docker镜像
可以通过commit命令(具体参见利用-commit-理解镜像构成),但是不推荐,因为会产生不必要的修改使得镜像臃肿;
通常通过Dockerfile定制镜像。文件Dockerfile的内容示例如下:
1 FROM debian:jessie 2 RUN buildDeps='gcc libc6-dev make' \ 3 && apt-get update \ 4 && apt-get install -y $buildDeps \ 5 && wget -O redis.tar.gz "http://download.redis.io/releases/redis-3.2.5.tar.gz" \ 6 && mkdir -p /usr/src/redis \ 7 && tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \ 8 && make -C /usr/src/redis \ 9 && make -C /usr/src/redis install \ 10 && rm -rf /var/lib/apt/lists/* \ 11 && rm redis.tar.gz \ 12 && rm -r /usr/src/redis \ 13 && apt-get purge -y --auto-remove $buildDeps
RUN指令用来执行命令行命令:
- 可以是shell 格式: RUN <命令> ,像直接在命令行输入命令一样,如 RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html ;
- 也可以是exec 格式: RUN ["可执行文件", "参数1", "参数2"] ,像是函数调用中的格式。
Dockerfile 中每一个指令都会建立一层新存储层, RUN指令也不例外(即每一个RUN指令都对应一个新容器。将包括如下指令的Dockerfile构建运行后会提示找不到txt文件就是因为这个原因,若在中间加上WORKDIR则没问题),并且Docker中有层数的限制。比较好的做法是用一个RUN指令和多个&&将多个命令连接起来。
RUN cd /app
# WORKDIR /app RUN echo "hello" > world.txt
此外,这组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 apt 缓存文件。这是很重要的一步,镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像。 因此镜像构建时,一定要确保每层只添加真正需要添加的东西,任何无关的东西都应该清理掉。
5.7 构建镜像
(具体可参见 镜像构建上下文 )
写了上节所述的Dockerfile后,执行命令生成Docker镜像: docker build [选项] <上下文路径/URL> 。假设Dockerfile在./dockertest/下,则命令为: Docker build -t zsmserver ./dockertest
- docker build的工作原理:Docker在运行时分为 Docker 引擎(即服务端守护进程)和客户端工具。Docker 引擎提供了一组 REST API,被称为 Docker Remote API,而如 docker 命令这样的客户端工具则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,docker build 命令构建镜像其实并非在本地构建,虽表面上像是在本机执行各种 docker 功能,但实际上一切都是通过远程调用在服务端(Docker 引擎)完成。
- 上下文路径:该路径是宿主机上的某个路径,Docker构建实际上是把指定上下文下的文件打包上传到服务端,在服务端进行构建,服务端以上传上来的该文件夹为上下文(即根目录)。故应确保该路径下无无用的多余文件。进行镜像构建时并非所有定制都会通过 RUN 指令完成,经常需将一些本地文件复制进镜像,如通过 COPY 指令、ADD 指令等,这些指令指定的路径参数以给定的上下文路径作为根目录。
- 一般将Dockerfile置于空目录或项目根目录,若不希望目录下的一些东西构建时传给Docker引擎,可以用与Git的.gitignore一样的语法写个.dockerignore文件加以剔除。
- 构建命令中并没有指定Dockerfile的名字,服务端构建时默认会查找名字为“Dockerfile”的文件进行构建,也可以通过-f参数指定Dockerfile文件。如: docker build -t zsmnginx -f MyDockerFile2 .
其他构建方式(详见其他Docker Build方法):
- 直接用 Git repo 进行构建,要求repo内有Dockerfile
- 用给定的 tar 压缩包构建,要求压缩包内有Dockerfile
- 从标准输入中读取 Dockerfile 进行构建
- 从标准输入中读取上下文压缩包进行构建等
构建镜像应使得镜像尽可能小,方法有:用一个RUN指令和多个&&将多个命令连接起来外、多阶段构建、选择Alpine作为基础镜像等。可参阅:https://www.cnblogs.com/sparkdev/p/8594602.html
5.8容器和镜像的保存与恢复
(更多可参考 https://jingsam.github.io/2017/08/26/docker-save-and-docker-export.html)
docker save / load 用于保存与恢复镜像
save时参数可以是镜像或容器,参数为容器时实际保存的仍是容器对应的镜像而不是容器
可以指定多个镜像名以将多个镜像保存到一个压缩文件中
适用场景:如要部署的客户服务器不能连外网,此时可以先将若干个镜像打包,再复制到客户服务器上并通过 docker load 导入。
示例:
docker save -o images.tar postgres:9.6 mongo:3.4 # 将两个镜像打包为images.tar文件。亦可 docker save postgres:9.6 mongo:3.4 > images.tar
docker load -i images.tar # 从文件中恢复镜像
docker export / import 用于将容器(的文件系统)打包为文件、从文件恢复为一个镜像
import时可以为镜像指定新名称
适用场景:制作基础镜像。如从一个ubuntu镜像启动一个容器,然后安装一些软件和进行一些设置后,使用docker export保存为一个基础镜像,就可把这个镜像分发给其他人使用(比如作为基础的开发环境)
示例:
docker export -o zsmredis.tar redis_sensestudy # 将容器打包成tar文件。亦可 docker export redis_sensestudy > zsmredis.tar docker import zsmredis.tar myredis:latest # 从文件导入为镜像 docker import saved_container_filename_or_url_image_name
注:docker load 和 docker import 的区别在于后者将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。
6 Dockerfile指令
(详见Dockerfile指令详解)
在一个Dockerfile中,CMD、ENTRYPOINT、HEALTHCHECK等只可出现一次,若出现多次则只有最后一次生效。
6.1 COPY
格式: COPY <源路径>... <目标路径> 或 COPY ["<源路径1>",... "<目标路径>"] 。如: COPY package.json zh* /usr/src/app/
作用:将构建上下文目录中 <源路径> 的文件/目录复制到新的一层镜像内的 <目标路径> 位置,复制时源文件的各种元数据都会保留。
注意:若被复制的文件是个目录,则不会复制该目录自身,只会复制其下的文件或目录,如 COPY ./* ./ ,若 ./ 下有doc目录,则只会复制doc下的文件或目录而不会复制doc。解决:改为 copy . ./
6.2 ADD
与COPY类似,只不过源文件可以为URL或压缩包,会自动下载或解压。推荐优先使用COPY。
6.3 CMD
作用:指定容器启动时的默认执行程序。上面的示例 docker run -it ubuntu cat /etc/os-release 指定启动时显示系统信息,该默认操作可通过Dockerfile里的CMD指令指定(注:若在启动容器时指定默认执行程序,则会覆盖Dockerfile里CMD指定的,ENTRYPOINT指定的则不会覆盖,见后文)
格式: shell 格式:CMD <命令> 或 exec 格式:CMD ["可执行文件", "参数1", "参数2"...] 。如: CMD cat /etc/os-release ,第一种格式实际上会被包装为 sh -c 的参数 的形式执行,即: CMD [ "sh", "-c", "cat /etc/os-release" ] 。注:
1、推荐用exec格式的命令。
2、两种命令的本质区别:exec格式指定的命令在容器内的进程号为1,而shell格式指定的则不是(此时进程号为1的进程为sh进程)
Docker 不是虚拟机,容器中的应用都应该以前台执行,而不是像虚拟机、物理机里面那样, 用 upstart/systemd 去启动后台服务,容器内没有后台服务的概念。如 CMD service nginx start 并不会使得容器一直在运行,其实际上会被理解为 CMD [ "sh", "-c", "service nginx start"] ,此时主进程实际上是 sh。则当 service nginx start 命令结束后,sh 也就结束了,sh 作为主进程退出了,自然就会令容器退出。正确做法是直接以前台形式执行nginx: CMD ["nginx", "-g", "daemon off;"]
6.4 ENTRYPOINT
目的和 CMD 一样,都是在指定容器启动时执行的默认程序及参数,命令格式也一样。不同的是ENTRYPOINT功能更强大,使用ENTRYPOINT指定的默认程序,可以接收在启动容器时给定的参数,从而使容器像个可执行程序一样。
应用场景1:让镜像如一个命令般可执行。”An ENTRYPOINT allows you to configure a container that will run as an executable.“
示例如下,功能为显示当前的公网IP:
FROM ubuntu:16.04 RUN apt-get update \ && apt-get install -y curl \ && rm -rf /var/lib/apt/lists/* #CMD [ "curl", "-s", "http://ip.cn" ] ENTRYPOINT [ "curl", "-s", "http://ip.cn" ]
经构建 docker build -t myip . 后,若Dockerfile中使用CMD则只能 docker run myip 运行,无法为curl指定其他参数;若用ENTRYPOINT则可以 docker run myip -i 为curl进一步指定参数(-i表示curl结果输出响应头)。
从上面可见CMD和ENTRYPOINT的区别:后者在运行容器时指定的参数(即-i)会拼接到ENTRYPOINT指定的命令上(变成curl -s http://ip.cn -i);前者则不会拼接而是替换,即把 -i 当成默认命令替换掉 curl -s http//ip.cn 进行执行,从而报错。
另一示例: ENTRYPOINT ["/bin/echo"] ,假设build成镜像echoimage,则可以执行 docker run -it imageecho “this is a test” 就会输出字符串,使得镜像像个echo可执行程序。
应用场景2:应用运行前的准备工作。
借助ENTRYPOINT指定一个脚本文件作为默认程序,完成系统配置、初始化等预处理工作。由于启动docker时指定的参数会拼接到ENTRYPOINT指定的默认程序后,因此参数被当成脚本的参数,脚本里可以根据这些参数作一些处理工作。用CMD则无法达到此功能。
注:
1、对于ENTRYPOINT只有为exec格式时默认命令才不会被创建容器时指定的参数覆盖而是附加,shell格式则照样会被覆盖。对于exec格式,也可以在创建容器时通过--entrypoint command覆盖默认命令,如 docker run -it --entrypoint pwd imageecho
2、一个Dockerfile中CMD和ENTRYPOINT须至少出现一个,其组合效果如下:

总结:
CMD、ENTRYPOINT都可用于指定容器启动时指向的默认程序和参数。
它们有 shell、exec 两种格式来执行该程序,前者在内部会被包装成后者故前者指定的程序运行后的进程号不是1而后者是,推荐用exec格式。
ENTRYPOINT的exec格式指定的默认程序可接收容器启动时指定的其他参数而不会覆盖掉默认程序,shell格式的则会覆盖。
6.5 ENV
设置环境变量,格式为: ENV <key> <value> 或 ENV <key1>=<value1> <key2>=<value2>... ,Docker里后面的指令(如RUN)以及运行时的应用都可以用此定义的变量,引用方式示例:$filename。
6.6 ARG
与ENV类似,定义环境变量及默认值。不同的是定义的环境变量在容器构建时存在、运行时不存在;此外,该默认值可在构建命令 docker build 中用 --build-arg <参数名>=<值> 来覆盖。
6.7 VOLUMN
定义匿名卷及其挂载位置,格式为: VOLUME ["<路径1>", "<路径2>"...] 或 VOLUME <路径> ,如 VOLUMN /data ,容器运行时会自动将宿主机上的某个匿名路径挂载到该指令指定的目录,这样宿主机和容器内都可读写该目录。
定义命名卷:也可在容器运行时指定数据卷的位置,覆盖匿名卷设置,如 docker run -d -v mydata:/data echo 将本机的命名卷mydata挂载到容器内的目录 /data 下。
注:
容器运行时应尽量保持容器存储层不发生写操作,对于数据库类需要保存动态数据的应用,其数据库文件应该保存于卷(volume)中。定义匿名卷后,Docker容器启动时会将指定的路径关联到宿主机的匿名卷,这样向该路径写入的数据不会写入容器存储层,从而保证容器存储层无状态化。
对于 匿名卷 和 非绝对路径的 命名卷,默认都存于宿主机的 /var/lib/docker/volumes/ 下。对于匿名卷,会在宿主机上的该目录下随机产生一个名类似于uuid的子目录。
可以通过命令 docker inspect --type container -f '{{range $i, $v := .Mounts }}{{printf "%v\n" $v}}{{end}}' $containerName 查看容器的卷信息。
更多相关见下文的 数据卷操作 一节。
6.8 EXPOSE
格式: EXPOSE <端口1> [<端口2>...] 。作用:声明容器运行时可以使用的端口。这只是声明容器打算使用的端口,在运行时并不会因为这个声明容器就去开启指定的端口,容器启动时通过 -p <宿主端口>:<容器端口> 可启用对应端口。
6.9 RUN
见5.6节
6.10 WORKDIR
格式: WORKDIR <工作目录路径> 。作用:指定工作目录(或称为当前目录),以后各层的“当前目录”就被改为该指定的目录,若该目录不存在,WORKDIR 会建立之。
6.11 USER
格式: USER <用户名> 。作用:与WORKDIR类似,切换为指定的用户,改变之后执行 RUN、CMD、ENTRYPOINT 这类命令的身份。指定的用户需要事先存在。
6.12 HEALTHCHECK
作用:周期性运行给定的命令以判断容器主程序是否正常运行。详见 healthcheck-健康检查。格式如下:
HEALTHCHECK [选项] CMD <命令> :设置检查容器健康状况的命令
HEALTHCHECK NONE :如果基础镜像有健康检查指令,使用这行可以屏蔽掉其指令
6.13 ONBUILD
格式: ONBUILD <其它Dockerfile指令> 。作用:用来设定触发器,在当前镜像build时不会执行ONBUILD指定的指令,只有在当前镜像的直接子镜像(即不包括孙镜像)build时才会执行ONBUILD指定的指令。
ONBUILD指令相当于创建一个模板镜像,后续可根据该模板镜像创建不同的特定子镜像,需要在子镜像构建过程中执行的一些通用操作就可以在模板镜像对应的Dockerfile文件中用ONBUILD指令指定,从而减少dockerfile文件的重复内容编写。
示例:
Dockerfile1:
FROM ubuntu
ONBUILD RUN mkdir mydir
构建为onbuild_image1: docker build -t onbuild_image -f Dockerfile1 . ,此时不会执行ONBUILD指定的指令。
Dockerfile2:
FROM onbuild_image1
CMD echo
构建为onbuild_image2: docker build -t onbuild_image2 -f Dockerfile2 . ,此时会执行ONBUILD指定的指令。如下:

分别查看是否有mydir目录: docker run --rm onbuild_image2 ls |grep mydir ,可以得到onbuild_image2有mydir目录而onbuild_image1没有。
6.14 多阶段构建
作用:从Docker 17.05.0-ce版本起,官方提供了简便的多阶段构建(multi-stage build) 方案,允许在同一Dockerfile中书写多阶段构建指令。
示例:
(关键在于AS关键字和 --from 选项。也可以不用AS关键字,此时在from关键字后不是阶段的名字而是阶段的下标,按出现顺序从0起)
FROM muninn/glide:alpine AS build-env # AS关键字给此阶段起名
ADD . /go/src/app
WORKDIR /go/src/app
RUN glide install
RUN go build -v -o /go/src/app/app-server
FROM alpine
RUN apk add -U tzdata
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
COPY --from=build-env /go/src/app/app-server /usr/local/bin/app-server # --from 指定从指定阶段的镜像复制文件
EXPOSE 80
CMD ["app-server"]
在多阶段构建的支持下,可以在build时加上 --target 阶段名 选项来只构建某阶段的镜像,如: docker build --target build-env -t go/helloworld:v1 .
此外,借助多阶段构建,可以将多个项目的二进制文件集成到一个镜像里,伪码示例如下:
from debian as build-essential arg APT_MIRROR run apt-get update run apt-get install -y make gcc workdir /src from build-essential as foo copy src1 . run make from build-essential as bar copy src2 . run make from alpine copy --from=foo bin1 . copy --from=bar bin2 . cmd ...
7 私有仓库
Docker Hub、DaoCloud等是公共的Registry,人们可以在上面创建Repository。有时候公共仓库不方便或者网络环境差,可以搭建私有仓库供私人或团队使用。构建私有镜像仓库可以借助官方工具docker-registry。详见 私有仓库 。
8 数据卷与挂载
数据卷的作用在于把宿主机上的指定目录挂载到容器内的某个位置(目录)上,即把宿主机的指定目录共享给容器,因此容器内对该目录的操作会反应到宿主机,从而操作永久有效,即使容器被删除了。
在Docker中管理数据的方式有两种:挂载数据卷(Volumes)和挂载主机目录(Bind mounts)。前者本质上就是后者,因为创建数据卷就是在本机上创建一个目录(默认在本机的 /var/lib/docker/volumes/ 下创建目录)并此后将该目录关联到容器内的指定目录。这两种方式都使得可以在主机和容器间共享文件夹或文件。
数据卷:
数据卷是一个可供一个或多个容器使用的特殊目录,类似于 Linux 下对目录或文件进行 mount,镜像中的被指定为挂载点的目录中的文件会隐藏掉,转而展示出的是挂载的数据卷的内容。
数据卷绕过 UFS,可以提供很多有用的特性:
- 数据卷可以在容器之间共享和重用
- 对数据卷的修改会立马生效
- 对数据卷的更新,不会影响镜像
- 数据卷默认会一直存在,即使容器被删除
数据卷操作:
docker volumn create vol_name #创建数据卷,名字中的字符只能是[a-zA-Z0-9_.-] docker volumn ls #查看所有数据卷 docker volumn inspect vol_name #查看指定数据卷 docker volumn rm vol_name #删除指定数据卷 docker volumn prune #删除无主数据卷
数据卷 是被设计用来持久化数据的,其生命周期独立于容器,Docker不会在容器被删除后自动删除数据卷,也不存在垃圾回收这样的机制来处理没有任何容器引用的数据卷。若需要在删除容器的同时移除数据卷,可在删除容器时加 -v 参数。
挂载操作:将本机上的目录或创建的数据卷挂载到容器内的指定路径上,两种:一种是用 --mount 参数、另一种是用-v(或--volumn)参数,大同小异。数据卷可以不用事先创建,指定挂载时若数据卷不存在则会创建之。
法1: -v vol_name_or_absolute_path:target_dir ,对于挂载数据卷或挂载本机目录命令一样,如 -v my-vol:/webapp 或 -v /home/zsm/data:/webapp ,卷或源目录不存在时会创建。
法2: --mount [type=bind] source=vol_name_orabsolute_path,target=target_dir [,readonly] 。卷不存在时会创建、源目录不存在时会报错。当挂载本机目录时需要 type=bind 选项,当启用readonly时在容器内的挂载目录内只有读权限。示例:
docker run -d -p 80:80 \ --name web \ # -v my-vol:/wepapp \ --mount source=my-vol,target=/webapp \
#--mount type=bind source=/home/zsm/data,target=/webapp,readonly\ training/webapp python app.py
通过命令 docker inspect web 查看容器信息,数据卷信息在“Mounts”key下,可见my-vol被创建在了 /var/lib/docker/volumns/ 下:
"Mounts": [ { "Type": "volume", "Name": "my-vol", "Source": "/var/lib/docker/volumes/my-vol/_data", "Destination": "/webapp", "Driver": "local", "Mode": "z", "RW": true, "Propagation": "" } ]
也可以将主机的一个文件挂载到容器中,示例如下(下例使得主机可以记录在容器中输入过的命令):
docker run --rm -it \ # -v $HOME/.bash_history:/root/.bash_history \ --mount type=bind,source=$HOME/.bash_history,target=/root/.bash_history \ ubuntu:17.10 \ bash
注意:在docker run 等命令中指定挂载路径时,若路径含有空格则会因被当成多个参数而出错,故最好将路径用引号括起来。如 -v "$logDirInHost":"$logDirInContainer"
查看数据卷信息(包括匿名卷): docker inspect --type container -f '{{range $i, $v := .Mounts }}{{printf "%v\n" $v}}{{end}}' $containerName ,结果示例:
{bind /etc/hosts /etc/hosts rw true rprivate}
{volume 62a13e0bc4a63a88de20a2c6c33dc347f542ebdfcbac5278fa082dbf790c3bff /var/lib/docker/volumes/62a13e0bc4a63a88de20a2c6c33dc347f542ebdfcbac5278fa082dbf790c3bff/_data /var/lib/mysql local true }
9 Docker网络
(其他可参阅 使用网络、高级网络设置、Docker网络实现)
9.1 原理
Docker利用Linux的namespace来实现资源隔离,如pid namespace、mount namespace、network namespace分别用来隔离进程、文件系统、网络。Docker 的网络实现就是利用了 Linux 上的network namespace和虚拟网络设备(特别是 veth pair)。
首先,要实现网络通信,机器需要至少一个网络接口(物理接口或虚拟接口)来收发数据包;此外,如果不同子网之间要进行通信,需要路由机制。
Docker 中的网络接口默认都是虚拟的接口。虚拟接口的优势之一是转发效率较高。 Linux 通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包被直接复制到接收接口的接收缓存中。对于本地系统和容器内系统看来就像一个正常的以太网卡,只是它不需要真正同外部网络设备通信,速度要快很多。
Docker 容器网络就利用了这项技术,它在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通(这样的一对接口叫做 veth pair)。
Docker创建一个容器时,会进行如下与网络相关的操作:
- 创建一对虚拟接口,分别放到本地主机和新容器中;
- 本地主机一端桥接到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 veth65f9;
- 虚拟接口一端放到新容器中,并修改名字作为 eth0,这个接口只在容器的命名空间可见;
- 从网桥可用地址段中获取一个空闲地址分配给容器的 eth0,并配置默认路由到桥接网卡 veth65f9。
完成这些之后,容器就可以使用 eth0 虚拟网卡来连接其他容器和其他网络。
9.2 网络设置
可在 docker run 时通过 --net 参数来指定容器的网络配置(若在docker-compose中配置则用 "network-mode: xxx "),有4个可选值:
- bridge模式:--net=brige,默认值,且最常用,连接到默认的网桥(即docker0),做到了不同容器间的网络隔离。
- host模式:--net=host,采用宿主机的网络。
- container模式:--net=container:NAME_or_ID ,在docker-compose中通过 network-mode:service:${service-name} 指定。加入到指定容器的网络中从而实现两者的网络共享。
- none模式:--net=none
9.2.1 bridge模式
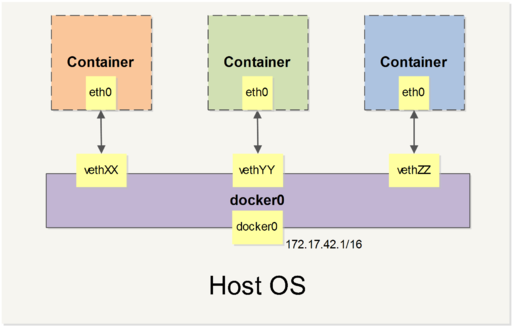
当 Docker server启动时,会自动在主机上创建一个 docker0 虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
同时,Docker 随机分配一个本地未占用的私有网段(在 RFC1918 中定义)中的一个地址给 docker0 接口。比如典型的 172.17.0.1,掩码为 255.255.0.0。此后启动的容器内的网口也会自动分配一个同一网段(172.17.0.0/16)的地址。
当创建一个 Docker 容器的时候,同时会创建了一对 veth pair 接口(当数据包发送到一个接口时,另外一个接口也可以收到相同的数据包)。这对接口一端在容器内,即 eth0;另一端在本地并被挂载到 docker0 网桥,名称以 veth 开头(例如 vethAQI2QT)
通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。Docker 就创建了在主机和所有容器之间一个虚拟共享网络。
9.2.2 host模式
一个Docker容器一般会分配一个独立的network namespace。但若启动容器的时候使用host模式,则此容器将不会获得一个独立的network namespace,而是和宿主机共用一个network namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。此时在容器中执行任何类似ifconfig命令查看网络环境时,看到的都是宿主机上的信息;外界访问容器应用时直接使用宿主机地址,不会进行NAT转换。从这也可看出Docker和传统虚拟机的一个区别,Docker在容器内可看到宿主机的IP、卷等信息而传统虚拟机则和主机完全隔离故看不到。
此外,容器进程跟主机其它 root 进程一样可以打开低范围的端口,可以访问本地网络服务比如 D-bus,还可以让容器做一些影响整个主机系统的事情,比如重启主机。因此使用这个选项的时候要非常小心。
然而,容器除了网络外的其他方面如文件系统、进程等还是和宿主机隔离的。
9.2.3 container模式
此模式下,创建的容器和已存在的一个容器共享一个network namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡、配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
注意,在这种模式下,假设容器A指定了network-mode为container B的,则出于安全等方面考虑A就不能通过 -p 向外暴露端口了,从而访问不到A上的服务。解决方法:这种模式本质上就是指定了A和B用同一个网络,它们在内部网络共享,故在被依赖者即B指定暴露端口即可。(相关可参阅:https://cizixs.com/2016/06/12/docker-network-modes-explained/)示例:
version: '2' services: storage: image: openzipkin/zipkin-mysql container_name: zipkin-mysql_sensestudy ports: - 9411:9411 restart: always zipkin: image: openzipkin/zipkin container_name: zipkin_sensestudy environment: - STORAGE_TYPE = mysql - MYSQL_HOST = localhost - SCRIBE_ENABLED=true # - JAVA_OPTS=-Dlogging.level.zipkin=DEBUG -Dlogging.level.zipkin2=DEBUG # ports: # Port used for the Zipkin UI and HTTP Api # - 9411:9411 # Uncomment if you set SCRIBE_ENABLED=true # - 9410:9410 network_mode: "service:storage" depends_on: - storage restart: always # Adds a cron to process spans since midnight every hour, and all spans each day # For more details, see https://github.com/openzipkin/docker-zipkin-dependencies dependencies: image: openzipkin/zipkin-dependencies container_name: zipkin-dependencies_sensestudy entrypoint: crond -f environment: - STORAGE_TYPE=mysql - MYSQL_HOST=localhost - MYSQL_USER=zipkin - MYSQL_PASS=zipkin # Uncomment to see dependency processing logs # - ZIPKIN_LOG_LEVEL=DEBUG # Uncomment to adjust memory used by the dependencies job # - JAVA_OPTS=-verbose:gc -Xms1G -Xmx1G network_mode: "service:storage" depends_on: - storage restart: always
9.2.4 none模式
此模式下,创建的容器拥有自己的network namespace,但并不会进行任何网络配置。即这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
10 Docker-Compose
Docker三剑客:
Docker-Machine:管理基础设置:用于在多台机器上快速部署和管理Docker环境(即Docker主机)
Docker-Compose:管理应用:用于组织、编排、管理属于同一个应用的多个容器
Docker-Swarm:管理集群:用于将多个机器上的Docker主机抽象成一个大的虚拟主机加以管理
10.1 是什么
“Docker-Compose is a tool for defining and running multi-container Docker applications”。
Docker-Compose是一个用来组织多个容器运行的工具(容器编排?orchestration),用Python编写而成。其与shell脚本类似,只需要编写一个yml文件就能组织并运行多个容器并对它们进行管理。
关于编排和部署的区别:
编排(orchestration)
编排指根据被部署的对象之间的耦合关系,以及被部署对象对环境的依赖,制定部署流程中各个动作的执行顺序,部署过程所需要的依赖文件和被部署文件的存储位置和获取方式,以及如何验证部署成功。这些信息都会在编排工具中以指定的格式(比如配置文件或特定的代码)来要求运维人员定义并保存起来,从而保证这个流程能够随时在全新的环境中可靠有序地重现出来。
部署(deployment)
部署是指按照编排所指定的内容和流程,在目标机器上执行环境初始化,存放指定的依赖文件,运行指定的部署动作,最终按照编排中的规则来确认部署成功。
简单理解,编排是规划、部署是规划的实施。类比地看,编排是一个指挥家,他的大脑里存储了整个乐曲此起彼伏的演奏流程,对于每一个小节每一段音乐的演奏方式都了然于胸。而部署就是整个乐队,他们严格按照指挥家的意图用乐器来完成乐谱的执行。最终,两者通过协作就能把每一位演奏者独立的演奏通过组合、重叠、衔接来形成高品位的交响乐。
10.2 使用
使用:编写docker-compose.yml文件即可,可以定义Docker环境变量文件(不指定文件的话默认查找当前目录的.env文件并解析成环境变量),这些变量会传给Docker容器、也可以在yml文件中使用。
示例:
1 fversion: "3" 2 services: 3 ss_manager: # global unique 4 image: marchonzsm/sensestudy_manage_server 5 env_file: 6 - .env # still default to this even not given 7 container_name: manage_server_sensestudy_${serverPortOfJava}_${serverPortOfWebsocket} 8 environment: 9 POSTGRES_PASSWORD: 1q2w3e4R 10 SERVICE_8081_NAME: ss_backend_service 11 SERVICE_8091_NAME: ss_queue_service 12 SERVICE_8081_TAGS: sensestudy,backend,java 13 SERVICE_8091_TAGS: sensestudy,backend,websocket 14 SERVICE_8081_CHECK_TCP: "true" 15 SERVICE_8091_CHECK_TCP: "true" 16 # network_mode: "host" 17 ports: 18 - ${serverPortOfJava}:8081 19 - ${serverPortOfWebsocket}:8091 20 volumes: 21 - $configFileDirPath/$configFileNameOfService:/home/$configFileNameOfService 22 - $configFileDirPath/$configFileNameOfDB:/home/$configFileNameOfDB 23 - "$logDirPath/port_$serverPortOfJava:$logDirPath/port_$serverPortOfJava" 24 command: --server.port=8081 --sensestudy.websocket.port=8091 25 restart: unless-stopped
1 serverPortOfJava=8085 2 serverPortOfWebsocket=8095 3 4 configFileDirPath=./config_file 5 configFileNameOfService=application.yml 6 configFileNameOfDB=application-prod.yml 7 logDirPath=/sensestudy_logs/javaserver_logs
docker-compose scale可以启多个容器,但若容器需要占用端口则启多个时会端口冲突。可以通过在yml中为不同容器指定多个端口来解决。然而yml的一个不足是key不能含有变量,解决:借助模板,如python的jinja、java的jsp等,Linux下显然前者更方便。这里以jinja为例,将上述yml改造成jinja模板如下:
1 version: "3" 2 services: 3 {% set numberOfContainerInstance = 3 %} 4 {% set firstServerPort = 12001 %} 5 {% for i in range(numberOfContainerInstance) %} 6 {% set serverPortOfJava = firstServerPort + 2*i %} 7 {% set serverPortOfWebsocket = firstServerPort + 2*i+1 %} 8 {% set configFileDirPath = "./config_file" %} 9 {% set configFileNameOfService = "application.yml" %} 10 {% set configFileNameOfDB = "application-prod.yml" %} 11 {% set logDirPath = "/sensestudy_logs/javaserver_logs/port_" ~ serverPortOfJava %} 12 ss_manager_server_{{ serverPortOfJava }}_{{ serverPortOfWebsocket }}: 13 image: marchonzsm/sensestudy_manage_server 14 container_name: manage_server_sensestudy_{{ serverPortOfJava }}_{{ serverPortOfWebsocket }} 15 environment: 16 SERVICE_{{ serverPortOfJava }}_NAME: ss_backend_service 17 SERVICE_{{ serverPortOfWebsocket }}_NAME: ss_queue_service 18 SERVICE_{{ serverPortOfJava }}_TAGS: sensestudy,backend,java 19 SERVICE_{{ serverPortOfWebsocket }}_TAGS: sensestudy,backend,websocket 20 SERVICE_{{ serverPortOfJava }}_CHECK_TCP: "true" 21 SERVICE_{{ serverPortOfWebsocket }}_CHECK_TCP: "true" 22 network_mode: "host" 23 ports: 24 - {{ serverPortOfJava }}:{{ serverPortOfJava }} 25 - {{ serverPortOfWebsocket }}:{{ serverPortOfWebsocket }} 26 volumes: 27 - {{ configFileDirPath }}/{{ configFileNameOfService }}:/home/{{ configFileNameOfService }} 28 - {{ configFileDirPath }}/{{ configFileNameOfDB }}:/home/{{ configFileNameOfDB }} 29 - {{ logDirPath }}:{{ logDirPath }} 30 command: --server.port={{ serverPortOfJava }} --sensestudy.websocket.port={{ serverPortOfWebsocket }} 31 restart: unless-stopped 32 {% endfor %}
1 from jinja2 import Environment, FileSystemLoader 2 env = Environment(loader=FileSystemLoader('.')) 3 template = env.get_template('docker-compose.yml.jinja') 4 output_from_parsed_template = template.render() 5 print output_from_parsed_template 6 7 # to save the results 8 with open("docker-compose.yml", "wb") as fh: 9 fh.write(output_from_parsed_template)
10.3 原理
可参阅:https://www.cnblogs.com/sparkdev/p/9787915.html
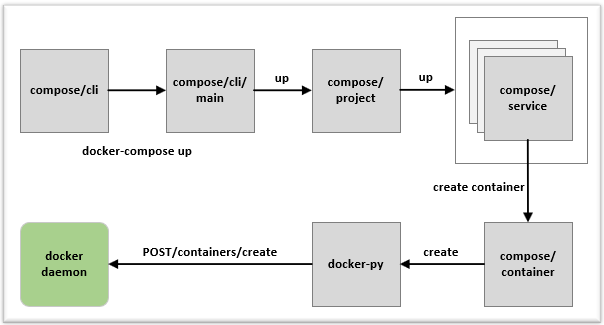
Docker-Compose中有两个概念:
- 服务 (service):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
- 项目 (project):由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。
Docker-Compose 的默认管理对象是项目。
Docker-Compose使用Python编写,实际上调用了Docker服务的API来管理容器。
更多使用方法,详见:
https://docker_practice.gitee.io/compose/install.html
https://blog.csdn.net/pushiqiang/article/details/78682323
遇到的坑:docker-compose.yml中若不指定network-mode则默认为bridge模式,且与docker run不同的是每个compose服务都会创建一个虚拟网桥而不是使用默认的docker0网桥,这样多个网桥分别占用一个地址段,很容易与本机的地址冲突出问题。
解决:显式指定network-bridge: "bridge",这样就不会创建多个bridge而是都使用默认的bridge(docker0)。
11 进阶_底层实现
11.1 核心技术
(见 底层实现官方文档、深入浅出的底层原理概述,推荐阅读后者快速以过一遍)
Docker 底层的核心技术包括 Linux 上的命名空间(Namespaces)、控制组(Control groups)、联合文件系统(Union file systems)和容器格式(Container format)。
命名空间:命名空间是 Linux 内核一个强大的特性。每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。命名空间保证了容器之间彼此互不影响。包括pid命名空间、net命名空间、ipc命名空间、mnt命名空间、uts命名空间、user命名空间等。
控制组:是 Linux 内核的一个特性,主要用来对容器的内存、CPU、磁盘IO等共享资源进行隔离、限制、审计等。只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。
联合文件系统:是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像;另外,不同 Docker 容器就可以共享一些基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。Docker 目前支持的联合文件系统(存储驱动)包括 OverlayFS, AUFS, Btrfs, VFS, ZFS 和 Device Mapper,overlay2 是目前 Docker 默认的存储驱动,以前则是 aufs。
容器格式:最初,Docker 采用了 LXC(即Linux Container) 中的容器格式。从 0.7 版本以后开始去除 LXC,转而使用自行开发的 libcontainer,从 1.11 开始,则进一步演进为使用 runC 和 containerd。
Docker利用命名空间来做权限的隔离控制(文件系统、网络、进程隔离等)、利用 cgroups 来做资源分配(CPU、内存、IO等)、利用UnionFS来层次化组织镜像、利用Container Format来设计容器实现虚拟化。
Docker 底层的核心技术包括 Linux 上的命名空间(Namespaces)、控制组(Control groups)、Union 文件系统(Union file systems)和容器格式(Container format)。 我们知道,传统的虚拟机通过在宿主主机中运行 hypervisor 来模拟一整套完整的硬件环境提供给虚拟机的操作系统。虚拟机系统看到的环境是可限制的,也是彼此隔离的。 这种直接的做法实现了对资源最完整的封装,但很多时候往往意味着系统资源的浪费。 例如,以宿主机和虚拟机系统都为 Linux 系统为例,虚拟机中运行的应用其实可以利用宿主机系统中的运行环境。 我们知道,在操作系统中,包括内核、文件系统、网络、PID、UID、IPC、内存、硬盘、CPU 等等,所有的资源都是应用进程直接共享的。 要想实现虚拟化,除了要实现对内存、CPU、网络IO、硬盘IO、存储空间等的限制外,还要实现文件系统、网络、PID、UID、IPC等等的相互隔离。 前者相对容易实现一些,后者则需要宿主机系统的深入支持。 随着 Linux 系统对于命名空间功能的完善实现,程序员已经可以实现上面的所有需求,让某些进程在彼此隔离的命名空间中运行。大家虽然都共用一个内核和某些运行时环境(例如一些系统命令和系统库),但是彼此却看不到,都以为系统中只有自己的存在。这种机制就是容器(Container),利用命名空间来做权限的隔离控制,利用 cgroups 来做资源分配。

11.2 日志原理
Docker在运行一个容器时会启动一个goroutine(协程),该goroutine绑定了整个容器内所有进程的标准输出文件描述符,故容器内应用的标准输出会被该routine接收并写入到与该容器一一对应的日志文件中。日志文件位于 /var/lib/docker/containers/<container_id> ,文件名为 <container_id>-json.log。
可通过 docker logs 命令打印输出到容器标准输出的日志信息,其本质就是展示上述日志文件中的内容。
12 其他
12.1 重启
docker run通过 --restart 参数来指定重启策略,有 no、on-failure[:max-retries]、unless-stopped、always几种策略,几种策略见名知意。后两个都用于在容器退出时重启容器,不同之处在于Docker Daemon还会在启动时重启restart模式为always的容器。这点很特殊,可以借助之实现应用容器开机自启动。
13 结语
Docker的技术并不神秘,只是整合了前人积累的各种成果实现的应用级的容器化技术,它利用各种Linux发行版中使用了版本兼容的内核容器化技术,来实现镜像一次构建到处运行的效果,并且利用了容器内的基础操作系统镜像层,屏蔽了实际运行环境的操作系统差异,使用户在开发应用程序时,只需确保在选定的操作系统和内核版本上能正确运行即可,几乎不需要关心实际的运行环境的系统差异,大大提高效率和兼容性。但随着容器运行得越来越多,容器管理将会称为另一个运维的难题,这时候就需要引入Kubernetes、Mesos或Swarm这些容器管理系统。
14 Kubernetes(k8s/kube)
(详情可参阅这篇文章)
Kubernetes(也称 k8s 或 “kube”)是一个用于大规模运行分布式应用和服务的开源容器编排平台,可以自动完成在部署、管理和扩展容器化应用过程中涉及的许多手动操作。
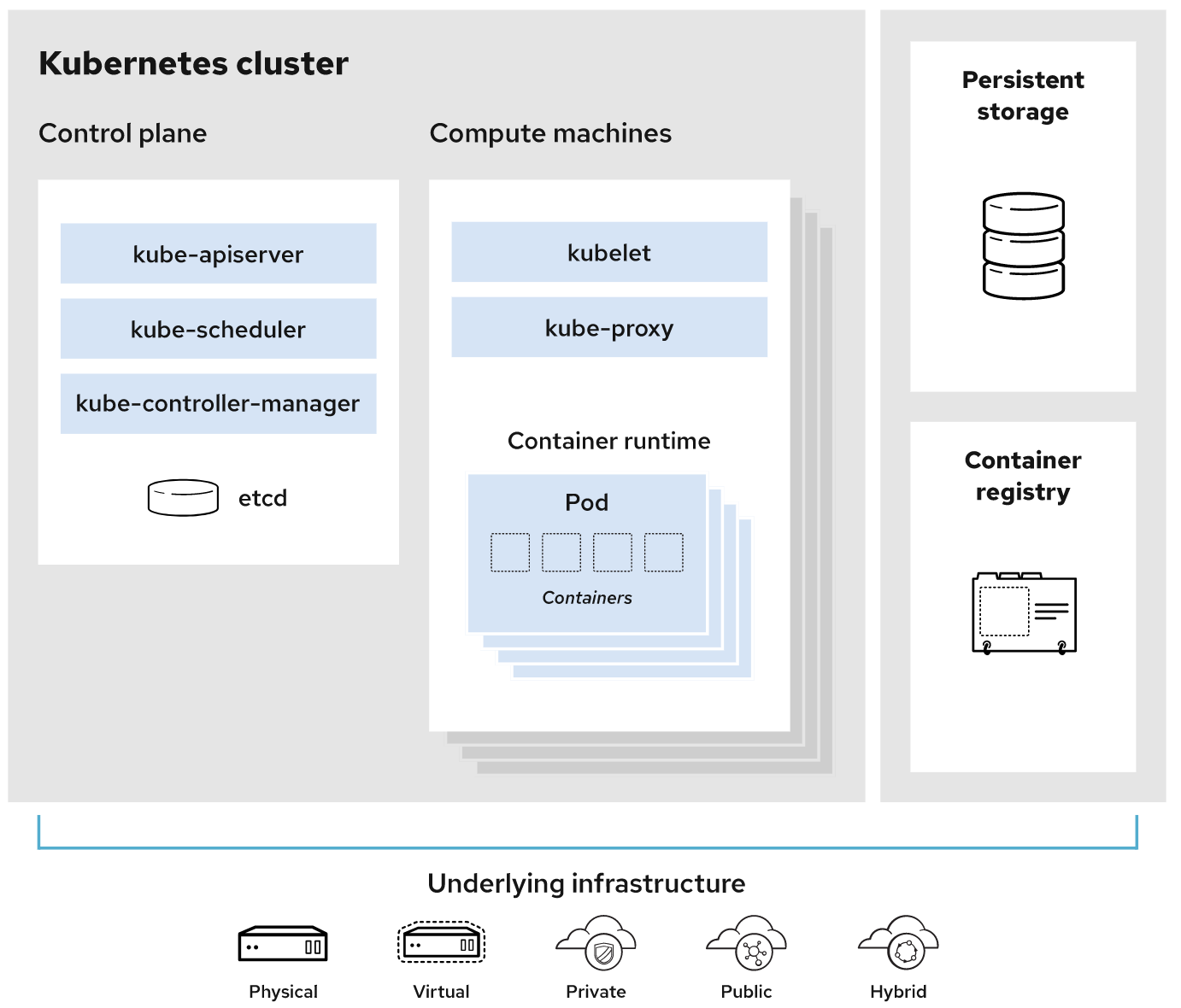
控制平面(Control Plane):控制 Kubernetes 节点的进程的集合。所有任务分配都来自于此。
节点(Node):这些机器负责执行由控制平面分配的请求任务。
容器集(Pod):部署在单个节点上的一个或多个容器组成的容器组。同一容器集中的所有容器共享同一个 IP 地址、IPC、主机名称及其它资源。容器集会将网络和存储从底层容器中抽象出来。这样,您就能更加轻松地在集群中移动容器。
复制控制器(Replication controller):用于控制容器集在集群上运行的实例数量。
服务(Service):将工作定义与容器集分离。Kubernetes 服务代理会自动将服务请求分发到正确的容器集——无论这个容器集会移到集群中的哪个位置,甚至可以被替换掉。
Kubelet:运行在节点上的服务,可读取容器清单(container manifest),确保指定的容器启动并运行。
kubectl:Kubernetes 的命令行配置工具。
15 参考资料
Docker
面面俱到的Docker专题:https://www.cnblogs.com/sparkdev/category/927855.html
最好最权威的资料无疑是 官方文档
深入浅出、简洁干练、提纲掣领的内部原理介绍(推荐!):https://segmentfault.com/a/1190000019462392
其他:
http://dockone.io/question/512
https://www.cnblogs.com/sparkdev/p/8998546.html Docker生态概览
Kubernetes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号