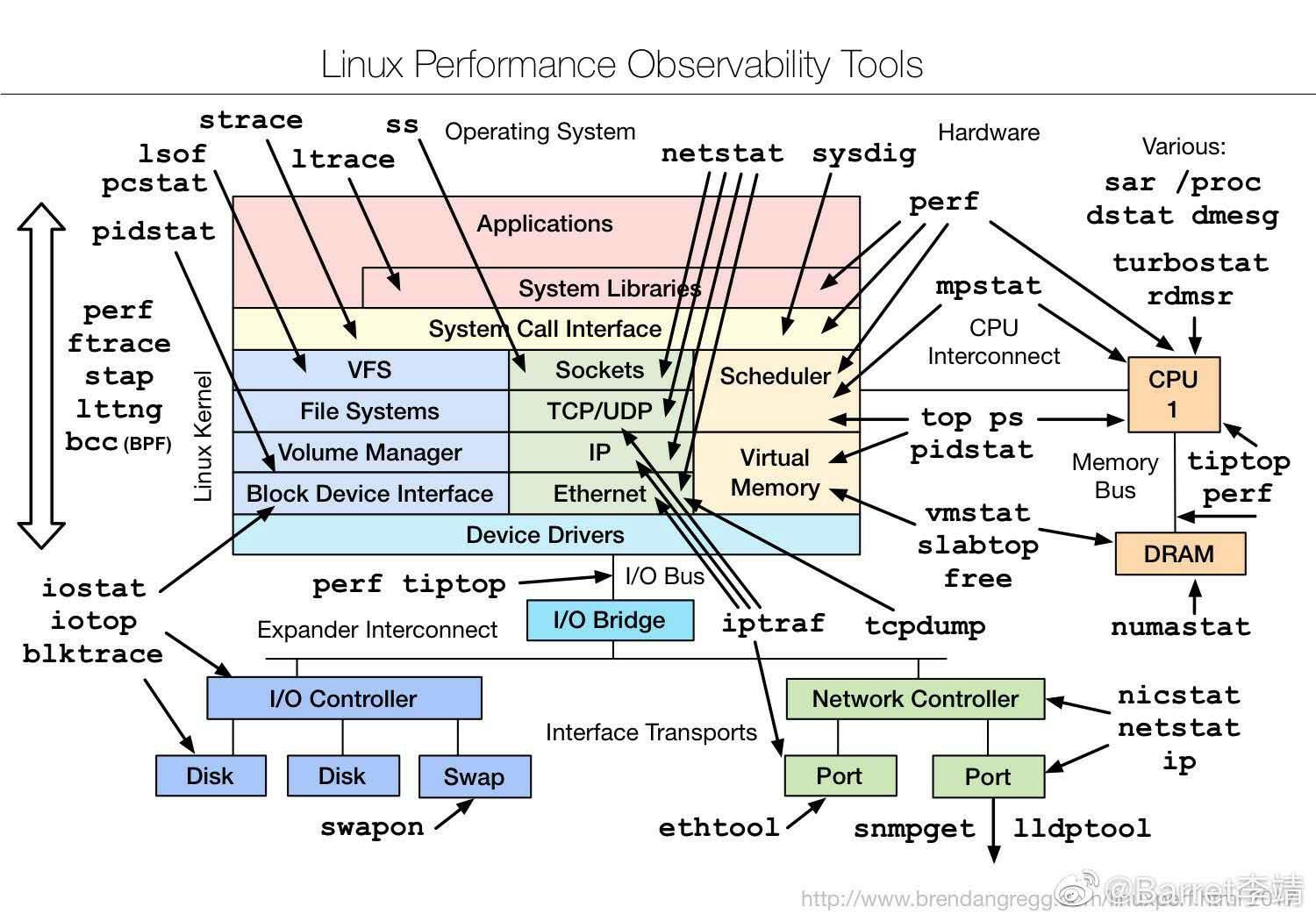
Linux 命令小记
更多可到 Linux命令搜索 检索查看
1、 pidof 进程名 :获取进程的pid,例如 pidof memcached 得到5333
2、 unset Shell变量 :取消设置一个shell变量,从内存和shell的导出环境中删除它,例如 unset JAVA_HOME
3、 cat test.txt 1 > /dev/null 2>&1 & :将标准输出重定向到回收站,并将错误输出重定向到标准输出,综合起来就是不输出任何信息。第一个1表示标准输出,可以省略;&1表示文件描述符1,若没有&则变成了文件1
# 以下四者等价 cat test.txt > log.txt 2 > log.txt cat test.txt 1 > log.txt 2 > log.txt cat test.txt > log.txt 2 > &1 cat test.txt &> log.txt # 空文件(size为0) : > log.txt M>N # "M" 是一个文件描述符,如果没有明确指定的话默认为 1。 # "N" 是一个文件名。 # 文件描述符 "M" 被重定向到文件 "N"。 M>&N # "M" 是一个文件描述符,如果没有明确指定的话默认为 1。 # "N" 是另一个文件描述符。 关闭文件描述符 文件描述符是可以关闭的,典型的写法有下面几种: n<&- # 关闭输入文件描述符 n 0<&-, <&- # 关闭 stdin n>&- # 关闭输出文件描述符 n 1>&-, >&- # 关闭 stdout
4、 iptables -I INPUT -p tcp --dport 8081 -j ACCEPT :开放指定端口。机器重启后会失效,可以保存配置,使开机自动加载。详见保存防火墙规则
5、 iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080 :端口转发(对80的请求转到8080)。机器重启后会失效,可以保存配置,使开机自动加载。详见保存防火墙规则
6、netcat命令(“网络工具中的瑞士军刀”,也可简写为 nc)。详见:http://www.oschina.net/translate/linux-netcat-command
使用示例:查看Zookeeper节点状态: echo stat | netcat localhost 2181
netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据。通过与其他工具结合和重定向,你可以在脚本中以多种方式使用它。使用netcat命令所能完成的事情令人惊讶。
netcat所做的就是在两台电脑之间建立链接并返回两个数据流,在这之后所能做的事就看你的想像力了。你能建立一个服务器,传输文件,与朋友聊天,传输流媒体或者用它作为其它协议的独立客户端。
7、查看端口被哪个进程占用: netstat -lnp|awk 'BEGIN{prt=":8086$"} {if ($4 ~ prt) print $0}'
推广:根据程序所用端口号kill掉程序的脚本:
1 #!/bin/sh 2 thisPort=8087 3 thisPid=`ps x |grep KafkaOffsetMonitor-assembly-0.2.0.jar |grep $thisPort | head -c 10 | grep -o "[0-9]\+"` 4 if [ $thisPid ]; then 5 echo pid is $thisPid , killling ... 6 kill $thisPid 7 echo killed 8 else 9 echo the program is not running, pid is null 10 fi
8、linux中shell变量$#,$@,$0,$1,$2等的含义:
$$ Shell本身的PID(ProcessID)
$! Shell最后运行的后台Process的PID
$? 最后运行的命令的结束代码(返回值)
$- 使用Set命令设定的Flag一览
$* 所有参数列表。如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
$@ 所有参数列表。如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。
$# 添加到Shell的参数个数
$0 Shell本身的文件名
$1~$n 添加到Shell的各参数值。$1是第1参数、$2是第2参数
9、lsof使用:(更多可参阅:https://www.cnblogs.com/sparkdev/p/10271351.html)
查看某普通文件被哪些进程打开: lsof /bin/bash 、 lsof /dev/sda1 ,Linux中一切皆文件。故这里的文件可以为文本文件、二进制文件、设备文件等
查看某目录及其下的目录或文件被哪些进程打开: lsof +d /var/log 、 lsof +D /var/log ,两者区别在于前者不会对指定目录递归查询而后者则会
查看某个进程打开了哪些文件: lsof -p 3332 ,数字为进程号
查看指定的若干进程打开了哪些文件: lsof -c cr # ^cr 、 cr[ao] ,查找进程名以cr开头的若干进程打开了哪些文件。(^cr表示不以cr开头、cr[a0]表示以cr或ao开头)
查看被打开的与网络相关的文件:
查看ipv4或ipv6打开的文件: lsof -i 、 lsof -i 4 、 lsof -i 6
查看被打开的与指定端口相关的文件: lsof -i:22 、 lsof -i:22-1024 、 lsof -i TCP:22 、 lsof -i TCP:22-1024 ,可以指定端口范围、后两者进一步加协议条件约束
查看某用户打开的所有文件: lsof -u syslog 、 lsof -u -i syslog ,后者进一步加条件约束
统计系统打开的文件总数: sudo lsof -P -n | wc -l ,-P表示不解析端口号、-n表示不解析主机名,从而加快命令执行速度
恢复删除的文件:详见http://www.cnblogs.com/z-sm/p/6108689.html
10、查看内存使用情况: free [-b/k/m/g/h] ,示例:
1 ivic@test39:~/imtg$ free 2 total used free shared buffers cached 3 Mem: 16367040 8483944 7883096 676 195008 6759508 4 -/+ buffers/cache: 1529428 14837612 5 Swap: 50128892 0 50128892
(1)、Mem为内存分配统计:
total为物理总内存、used为已分配内存(包括buffers、cached),可能部分缓存并未实际使用、free为未分配内存(不包括buffers、cached)
shared为共享内存一般用不到、buffers为系统已分配但未被使用的buffers内存、cached为系统已分配但未使用的cache内存
(2)、-/+ buffers/cache为实际使用内存统计:
used -buffers/cache为已分配的不包括buffers、cached部分的内存,即实际已使用的内存
free +buffers/cache为未分配的加上buffers、cached部分的内存即实际空余的内存。
(3)、swap为磁盘交换分区,当做虚拟内存使用,通常在Mem都被进程使用完时才会使用swap,其大小应不少于物理内存大小。(swap用途:内存不够时数据移到swap、不常用数据移到swap(linux休眠数据放在swap);优点:可运行更多或更大应用程序;缺点:速度比内存慢)
通常物理内存不足以供进程使用时,系统会清理buffers/cached来腾出内存,但这是个耗cpu的操作且不保证一定清理出内存。
在linux的内存分配机制中,优先使用物理内存,当物理内存还有空闲时(还够用),不会释放其占用内存,就算占用内存的程序已经被关闭了,该程序所占用的内存用来做缓存使用,对于开启过的程序、或是读取刚存取过得数据会比较快。
A buffer is something that has yet to be "written" to disk;
A cache is something that has been "read" from the disk and stored for later use.
相关可参考:http://blog.csdn.net/tianlesoftware/article/details/6459044
11、查看内存信息、CPU信息等
查看内存信息: cat /proc/meminfo
查看CPU型号: cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看CPU核数:通过查看 /proc/cpuinfo 得到:
1 # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 2 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 3 4 # 查看物理CPU个数 5 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l 6 7 # 查看每个物理CPU中core的个数(即核数) 8 cat /proc/cpuinfo| grep "cpu cores"| uniq 9 10 # 查看逻辑CPU的个数 11 cat /proc/cpuinfo| grep "processor"| wc -l
另外,通过 lscpu 命令也可以看到CPU的汇总信息。其中,Sockets表示物理CPU个数、Core(s) per socket表示每个物理CPU的核数、Thread(s) per core表示每个核支持的超线程数(为0则说明不支持超线程)。这些信息与上面通过查看/proc/cpuinfo得到的信息是一致的,示例如下:
1 ivic@test39:~/imtg$ lscpu 2 Architecture: x86_64 3 CPU op-mode(s): 32-bit, 64-bit 4 Byte Order: Little Endian 5 CPU(s): 8 6 On-line CPU(s) list: 0-7 7 Thread(s) per core: 2 8 Core(s) per socket: 4 9 Socket(s): 1 10 NUMA node(s): 1 11 Vendor ID: GenuineIntel 12 CPU family: 6 13 Model: 30 14 Stepping: 5 15 CPU MHz: 1197.000 16 BogoMIPS: 5852.63 17 Virtualization: VT-x 18 L1d cache: 32K 19 L1i cache: 32K 20 L2 cache: 256K 21 L3 cache: 8192K 22 NUMA node0 CPU(s): 0-7
11、查看带宽:安装工具ethtool,然后通过 ethtool eth0(网卡名) 查看,结果示例如下:
1 ivic@test39:~/imtg$ ethtool em1 2 Settings for em1: 3 Supported ports: [ TP ] 4 Supported link modes: 10baseT/Half 10baseT/Full 5 100baseT/Half 100baseT/Full 6 1000baseT/Full 7 Supported pause frame use: No 8 Supports auto-negotiation: Yes 9 Advertised link modes: 10baseT/Half 10baseT/Full 10 100baseT/Half 100baseT/Full 11 1000baseT/Full 12 Advertised pause frame use: No 13 Advertised auto-negotiation: Yes 14 Speed: 1000Mb/s 15 Duplex: Full 16 Port: Twisted Pair 17 PHYAD: 2 18 Transceiver: internal 19 Auto-negotiation: on 20 MDI-X: on (auto) 21 Cannot get wake-on-lan settings: Operation not permitted 22 Current message level: 0x00000007 (7) 23 drv probe link 24 Link detected: yes
12、top命令,可以用来查看CPU使用情况、 内存占用情况等。详见:top命令参数及显示内容含义详解
ivic@test38:~/imtg$ top top - 14:19:40 up 13 days, 4:22, 1 user, load average: 0.00, 0.01, 0.05 //任务队列信息。load average为系统负载,实际是CPU使用队列的长度的统计信息 Tasks: 146 total, 1 running, 145 sleeping, 0 stopped, 0 zombie //进程数信息。总进程数、正在运行进程数、睡眠进程数、停止的进程数、僵尸进程数 %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st //CPU占用信息。用户空间占用、内和空间占用、用户空间中改变过优先级的进程占用CPU、空闲CPU时间、等待IO的CPU时间、硬件CPU中断占用、软中断占用、虚拟机占用 的百分比。 KiB Mem: 16367040 total, 853116 used, 15513924 free, 181692 buffers //与下行同为内存信息 KiB Swap: 50128892 total, 0 used, 50128892 free. 368584 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 16815 ivic 20 0 105656 2060 1068 S 0.3 0.0 0:00.37 sshd 16893 ivic 20 0 24964 1664 1156 R 0.3 0.0 0:00.07 top 1 root 20 0 33508 2852 1440 S 0.0 0.0 0:01.06 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.14 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.61 ksoftirqd/0 4 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root 20 0 0 0 0 S 0.0 0.0 0:26.18 rcu_sched 8 root 20 0 0 0 0 S 0.0 0.0 0:07.34 rcuos/0 9 root 20 0 0 0 0 S 0.0 0.0 0:17.18 rcuos/1
命令格式: top [-] [d] [p] [q] [c] [C] [S] [s] [n]
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名
交互命令(在top命令执行过程中可用这些命令,都是单字母的,若top命令加了s参数,则此交互命令会被屏蔽):
Ctrl+L 擦除并且重写屏幕。 h或者? 显示帮助画面,给出一些简短的命令总结说明。 k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。 i 忽略闲置和僵死进程。这是一个开关式命令。 q 退出程序。 r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。 S 切换到累计模式。 s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。 f或者F 从当前显示中添加或者删除项目。 o或者O 改变显示项目的顺序。 l 切换显示平均负载和启动时间信息。 m 切换显示内存信息。 t 切换显示进程和CPU状态信息。 c 切换显示命令名称和完整命令行。 M 根据驻留内存大小进行排序。 P 根据CPU使用百分比大小进行排序。 T 根据时间/累计时间进行排序。 W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
注意 CPU利用率与load average不同:(详情可见:CPU load和CPU利用率的关系)
前者是针对从CPU使用的角度来看的,为统计周期内使用CPU的时间(不是占有时间,占有时间内有可能等待,等待的时间不算在这里的使用时间内)的占比.
后者指的在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。
CPU有可能是 低利用率但高load状态,也有可能是高利用率但低load状态。两者没有必然联系。所以仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。
(墙鈡时间wall clock指操作开始到结束所用时间,通常包括各种非运算的等待耗时如等待IO、等待线程阻塞等,详见:GC类型中第5部分与时间有关的部分)
13、统计文档中每个字符出现的次数(通过脚本,详见:http://blog.csdn.net/yutianzuijin/article/details/65627931)


1 #!/bin/sh 2 #运行命令时需要两个参数,分别为文档名、输出文件名 3 for line in `cat $1`; do 4 count=`echo $line|wc -m` 5 echo $count $line 6 7 i=1; 8 while [ "$i" -lt "$count" ]; do 9 one_word=`echo $line|cut -c$i` 10 #echo $i $one_word 11 echo "$one_word" >>temp 12 ((i++)) 13 done 14 done 15 16 sort temp|uniq -c|sort -k1nr > $2 17 18 rm -f temp
14、硬链接、软连接。(详见:理解inode-阮一峰、理解Linux的硬链接与软连接)
在Unix/Linux中,一切皆文件。文件内部由 inode和文件内容 两部分组成,分别存储 除文件名外的元数据(文件大小、创建、修改、最后访问时间、执行权限、文件内容在磁盘上的位置等)、文件内容。目录文件的文件内容比较简单,是一系列目录项每个目录项包含文件名和文件名对应的inode号。对于普通文件和目录文件,读、写、执行权限对文件内容部分的影响不同:
普通文件:读时可读取文件内容、写时可添加文件内容、执行时可执行文件内容。
目录文件:读时可读取目录项列表但只能读到目录项文件名、写时可添加目录项、执行时可读取目录项inode号。
文件都有文件名与数据,数据在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接或快捷方式,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。
硬链接:若一个 inode 号对应多个文件名,则称这些文件为硬链接,即硬链接就是同一个文件使用了多个别名。对oldfile创建硬链接的命令: link oldfile newfile 或 ln oldfile new file 。
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能对目录进行创建,只可对文件创建(.和..目录其实就是硬链接。若系统允许再对目录创建硬链接,则可能会产生目录环);
- 不能交叉文件系统进行硬链接的创建(不同文件系统的inode空间可能有重叠,故此);
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
软连接:若文件用户数据块中存放的内容是另一文件的完整路径名,则该文件就是软连接。软链接就是一个普通文件,有自己的inode号及用户数据块,因此其创建与使用没有类似硬链接的诸多限制。创建命令:加上 -s 参数。(软连接类似于Windows下创建的快捷方式)
- 软链接有自己的文件属性及权限等;
- 软链接可对文件或目录创建;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接),此时打开时会报"No such file or directory"的错。
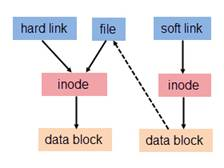
注:Linux下的bind mount效果与hard link很像,但它们原理不同——bind mount将关联信息存于内存因此机器重启后即丢失,而hard link的关联信息是持久化的;此外bind mount可以将源目录或文件挂载到已存在的目录或文件上(此时目标目录或文件会被隐藏,unmount后会复现),而hard link目标只能是文件且文件事先不能存在;写文件内容后,会产生新的inode来关联新的文件内容。
两者区别的总结:本质是别名还是文件(前者指向inode后者指向其他文件路径)、是否可对不存在的文件创建链接、是否可跨文件系统创建链接、是否可对目录创建链接、删除的效果。
inode的特殊作用:
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
15、Linux下截图软件:scrot。通过 scrot -s 命令可以截取指定区域。
16、Linux命令行中将命令的运行结果拼接到已有串上,示例: echo my-$(uname -r) ,结果为 my-3.16.0-77-generic 。
17、Linux下分区调整,可以用工具GParted(可通过sudo apt-get install gparted安装),Window下可以用分区助手等。
18、Linux下装新Linux系统:可以用管理员身份运行工具unetbootin来制作启动U盘,再用该U盘启动即可安装。(注意为了上传文件这里将该文件加了后缀.css,下载下来后去掉即可)
19、Linux启动项相关
1、删除多余的启动项:可以编辑/boot/grub/grub.cfg,借助启动项名称删掉对应相关的项(会有BEGIN、END注释,删掉其间的即可);此外,调节该文件里启动项配置文本的先后顺序可以达到调整启动项先后顺序的目的。
2、启动项修复:如本人在一台机子上装另一Ubuntu系统时,启动项列表里没有第二个系统的启动项,解决方法是借助工具“Boot Repair”工具,具体见双系统Ubuntu引导修复。
20、查看自己当前的公网IP: curl -s ip.cn ,结果示例: 当前 IP:183.62.236.90 来自:广东省深圳市 电信
21、source 和 . 的功能类似,通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。
其区别是:(本质上地看,source用于执行一个脚本,并使得脚本内的变量定义、函数生命等在当前环境内生效;而 . 命令仅用于执行一个脚本)
- 后者要求文件有执行权限而前者不需要;
- 后者在执行某个脚本时是在子shell里执行所以执行结果不会反应到父shell,而前者是在当前shell执行所以会看到执行结果。如对于包含export age=2的脚本test.sh,后者执行后看不到变量$age而前者可以。
示例:对于如下两个脚本文件info.bash和app.bash,执行 source app.bash 后在当前目录下会有log1.txt、log2.txt、log.txt三个文件,可见在app.bash中执行source命令后info.bash中的my_info函数在app.bash中也可见了。
info.bash文件: #!/bin/bash function my_info() { lscpu >> $1 uname -a >> $1 free -h >>$1 } my_info log1.txt my_info log2.txt app.bash文件: #!/bin/bash source info.bash my_info log.txt
用哪个?:执行脚本命令还要sh、bash等,推荐用 . ,因为sh、bash等要求被执行文件是个shell脚本,若是二进制程序就执行不了了。
22、Bash小计(更多参阅 快速学习Bash-Vamei )
变量赋值: name1=Libai 或者 name2="Zhang Xiaoming" 等
变量引用: echo $name1 ;可拼接: echo Hello you$name1 #得到Hello youLibai 、把拼接串紧挨放变量后则不可,可改用${}: echo ${name1}Hello #得到 LibaiHello 、 echo Hello you${name1} #得到Hello youLibai ,可统一用${}避免混淆。
其他: echo "Hello ${name1}" #得到 Hello Libai , echo 'Hello ${name1}' #得到 Hello {name1} 。可见双引号时会解析变量引用而单引号不会。
数学运算:用$(( ))括起表达式即可。如 echo $(( 2*(2+3) ))
返回值:Bash下执行任何命令都有返回值,执行脚本也有返回值,类似于C语言,正常执行结束的话返回0。可以通过$?查看命令的返回值,,如: pwd; echo $? ,会输出当前目录还会输出0。
脚本参数:$0、$1、$2等,含义与C语言main函数的参数类似,分别表示程序名、程序第一参数、第二参数等。如对于如下脚本info.bash,可以执行info.bash log.txt,会把相关信息写入指定名字的文件中。
#!/bin/bash echo "Information of Vamei's computer:" > $1 lscpu >> $1 uname –a >> $1 free –h >> $1
函数:function funcname(){},function关键字可省略。示例:
#!/bin/bash function my_info (){ lscpu >> $1 uname –a >> $1 free –h >> $1 } my_info output.file my_info another_output.file
执行上述脚本,会把相关信息写入到指定的两个.file文件中
跨脚本调用:要在一个脚本s1.bash中调研另一个脚本s2.bash中的函数,可以在s1.bash中通过source s2.bash将其函数有效范围扩展到当前脚本,随后即可使用该函数。
多命令执行:可通过分号将各命令串联执行,将会依次执行各命令,即使前一个命令有错,如 ls -lt ; pwd; echo end 。也可通过 && 或 || 串联各命令,区别是前者只有前一命令执行成功才会执行后一命令,而后者是前一执行成功则不执行后一个。
逻辑判断:test命令,用于判断真假,如两数关系、文本关系等。与C语言不同的是,C语言中0为假非0为真,Bash下正好相反。
判断两数关系:如 test 3 -gt 2; echo $? 判断3>2。类似的还有 -lt、-ge、-le、-eq、-nq等;
判断单者关系:如 test -e a.out ; echo $$? 判断文件是否存在。类似的还有-d、-f、-L、-r、-w、-x。分别表示是否存在指定目录、是否存在指定普通文件、是否存在指定软连接、指定文件是否可读、可写、可执行。
选择结构:可以用if或case语句。可以使用通配符。
if [...] ,这是test的简化版。注意: if 和 [ ] 之间要有空格,[ ]内首尾也要有空格;也可以不用[ ]。示例:
#!/bin/bash curCMD=$1 if [ "$curCMD" = "zsm" ] then echo you are zsm elif [ "$curCMD" = "root" ] then echo you are root else echo you are not zsm and root fi
case语句:示例:
#!/bin/bash curUser="zsm" case $curUser in root) echo you are root ;; zsm) echo you are zsm ;; *) echo you are not zms and root ;; esac
简单示例: if [ ` systemctl is-active docker` != "active" ]; then `sudo systemctl start docker` ; fi
循环结构:while xxx ; do .... done 或者 for xx in yy ; do ... done 。示例:
#!/bin/bash now=`date +'%Y%m%d%H%M'` deadline=`date --date='1 hour' +'%Y%m%d%H%M'` while [ $now -lt $deadline ] do date echo "not yet" sleep 5 now=`date +'%Y%m%d%H%M'` done echo "now,deadline reached"
#!/bin/bash for var in `ls` do echo $var done echo for var in zsm root guest do echo $var done echo total=0 for number in `seq 1 1 100` # 3 args for seq command:start,step,end do total=$(($total+$number)) done echo $total echo #calcute the sum of integers which cann't be divided by 3 total=0 for number in `seq 1 1 100` do if (($number%3==0)) then continue fi total=$(($total+$number)) done echo $total
20201110更新:推荐参阅 Bash脚本教程-阮一峰
23、Bash Set命令:出错打印信息、出错退出不执行之后命令。(参考:Bash脚本set命令教程-阮一峰)
一个Bash脚本如run.sh默认在一个新的Shell里执行,Shell默认给定了此环境的各种参数,可以通过set命令改变Shell环境运行参数,一般放在脚本头部(设置set后引用脚本参数$1等获取不到值了,why)。
set:显示当前Shell环境的所有环境变量和shell函数
set -x:在运行某条命令之前先输出将要运行的该命令。可以在要作用对象的前后分别加上 set -x set+x
set -u 或 set -o nounset :出错打印
set -e 或 set -o errexit:只要执行脚本中某条命令出错时就退出,不继续执行之后的命令。不适用于管道:会把最后一个子命令的返回值作为整个命令的返回值。也就是说,只要最后一个子命令不失败,管道命令总是会执行成功,因此它后面命令依然会执行。示例及结果:
#!/usr/bin/env bash set -e foo | echo a echo bar 结果如下: a ./mysql_docker.sh: line 4: foo: command not found bar
set -o pipefail:解决 set -e 不适用于管道的问题。
使用:通常四个参数一起用,放在脚本头部:
# 写法一 set -euxo pipefail # 写法二 set -eux set -o pipefail
# 写法三,通常用这个,见名知意
set -o nounset
set -o errexit
set -o pipefail
也可以作为Bash脚本参数传入: $ bash -euxo pipefail script.sh
24、获取某个进程的进程号:借助awk,如: ps -ef|grep java|grep 8081|awk '{print $2}' ,awk命令逐行读入内容、以空格为分隔符打断字符串从而可引用每个单词。
25、Linux截图工具:之前一直用scrot发现很鸡肋,后来发现了shutter,非常强大。
26、命令替换(command substitution)
如 echo `pwd` 和 echo $( pwd),效果一样。推荐用后者,因为后者不容易跟引号等混淆,且后者在嵌套时更直观。如 res=$(echo $(pwd))
命令执行结果赋值给变量问题:
tmpPid=`ps -ef|grep java|grep sensestudy| awk '{print $2}'`
if [ "$tmpPid" != "" ]
上述语句中若ps结果为空,则赋值语句执行完后就停止了,不执行后面的了。why?
解决:
法1:if [ "`ps -ef|grep java|grep sensestudy| awk '{print $2}'`" != "" ]
法2:tmpPid=$(`ps -ef|grep java|grep sensestudy| awk '{print $2}'`)
推荐后者
27、将多个文件中的指定内容替换为新内容: find -name '*.txt' | xargs perl -pi.bak -e 's|good|perfect|g' ,会将当前目录下所有.txt文件中的good替换为perfect。两个|直接的是源串,包含空格,源串可以是正则表达式。
若要在替换前先保存源文件内容,可以 find -name '*.txt' | xargs perl -pi.bak -e 's|good|perfect|g' ,会将源文件保存为.txt.bak文件。
28、更改时区: ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
29、获取IP: ping -c 1 $HOSTNAME|head -n 1 |grep -Eo "([0-9]{1,3}[\.]){3}[0-9]{1,3}" ,更好的方式(需要联网): ip -4 rout get 8.8.8.8 | awk '{print $7}' |tr -d '\n'
30、查看OS发行版本及版本号: lsb_release -a ,结果示例:
LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 7.4.1708 (Core) Release: 7.4.1708 Codename: Core
31、xx
32、sudo命令
sudo是一种权限管理机制,允许一个已授权用户以超级用户或者其它用户的角色运行某些命令,而不需要指定root密码。
为用户添加sudo权限:
法1:通过将用户加入sudo组来实现。Linux系统中有个默认sudo组,组定义于文件 /etc/group 文件中,只要把一个用户加入sudo组,用户就具有sudo权限。添加方法:将用户名添加到sudo组后面,以逗号分隔,如: sudo:x:27:zsm, sensetime ,也可通过命令添加,如: sudo usermod -a -G sudo sensetime
法2:为用户配置sudo权限:在文件 /etc/sudoers 中配置添加一行,语法遵循格式 who where whom command ,表示允许哪个用户在哪个主机以谁的身份执行哪些命令。示例: zsm ALL=(ALL:ALL) ALL 、 zsm 192.168.10.0/24=(root) /usr/sbin/useradd ,前者表示允许zsm在任何主机以任何人的身份来执行所有命令、后者表示只允许zsm在 192.168.10.0/24 网段上连接主机并且以 root 权限执行 useradd 命令。
通过法2添加sudo权限的用户在执行sudo命令时需要输入密码,可通过在配置行中添加 NOPASSWD: 解决,示例: zsm ALL=(ALL:ALL) NOPASSWD: ALL
sudo日志:执行sudo命令时相关命令日志都会被记录下来,位于文件 /var/log/auth.log 中
33、sed命令:sed是一个流编辑器(stream editor),以行为单位对文本进行批量插入、删除、替换等处理。主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
原理:处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。在这过程中源文件的内容不会改变,除非使用重定向将输出存储到源文件。
使用简明教程可参阅:https://www.cnblogs.com/sparkdev/p/7138073.html、http://man.linuxde.net/sed
34、awk命令:awk是处理文本文件的一个应用程序,几乎所有 Linux 系统都自带这个程序。 它依次处理文件的每一行,并读取里面的每一个字段。对于日志、CSV 那样的每行格式相同的文本文件,awk可能是最方便的工具。
使用简明教程:参阅 https://www.cnblogs.com/z-sm/p/10229280.html
35、mount命令:用于挂载文件系统。参阅:
Linux mount命令(挂载磁盘、虚拟磁盘、光驱、文件夹、Windows文件夹、虚拟文件系统等): mount -t type [-o options] device tardir ,将指定类型的设备挂载到指定目录
bind mount: mount --bind srcFileOrDir tarFileOrDir ,目录或文件挂载,与硬链接效果一样但bind mount的关联关系存于内存而硬链接是持久化的。
Shared subtree
36、sftp登录命令: sftp -oPort=xxxx username@ip
37、xargs命令
命令格式: xxx | xargs [xargs options] command
示例: $ echo "one two three" | xargs mkdir ,等价于 $ mkdir one two three
作用:以指定的分隔符(默认为空格、换行符)将标准输入的内容转化为多个命令行参数,xargs后紧跟要执行的命令(不指定则默认为echo),故效果是将分割后得到的命令行参数作为命令的参数(默认是所有命令行参数整体作为后面的命令参数,可通过-n指定)来执行其后的命令。
xargs选项:
-p:打印并让用户确认转换后将要执行的命令
-t:打印并直接执行转换后的命令
-d:指定所用的分隔符,如-d "\t"
-0:指定用null作为分隔符(不是字符串null)
-I:将命令行参数传递给多个命令执行。示例: cat foo.txt | xargs -I myword sh -c 'echo myword; mkdir myword' ,myword相当于变量,存命令行参数值
-L:指定转换后多少行作为一个命令行参数,默认是所有行作为命令行参数。示例:
echo -e "a\nb\nc" | xargs echo #结果为:a b c echo -e "a\nb\nc" | xargs -L 2 echo #结果为:a b # c
-n:指定转换后多少个参数作为一个命令行参数,默认为所有参数作为一个命令行参数。若指定为1则相当于依次取一个命令行参数去执行后面的命令。示例:
echo -e "a\nb\nc" | xargs echo #结果为:a b c echo -e "a\nb\nc" | xargs -n 2 echo #结果为:a b # c echo {0..9}|xargs -n 2 echo #结果为: #0 1 #2 3 #4 5 #6 7 #8 9
更多可参阅:http://www.ruanyifeng.com/blog/2019/08/xargs-tutorial.html
38、 echo "zhangsan M 22 18610213322" | sort -k 3 -n :将输入的若干条数据按第三字段排序,排序时将值视为数字。
39、只读模式查看文件内容,view、cat(tail、head)、more、less 等,后三个用得最多、且出现时间依次更晚、功能也依次更强大。
cat 默认会读取文件所有内容打印到屏幕。taiil、head 类似,只不过只打印尾部或头部的若干行,在只需要看头部或尾部若干行时可分别用这两个命令。
more 每次读取屏幕一页大小的内容打印到屏幕,按空格进入下一页,无法回退显示前页内容
less 与more类似,只不过更强大,包括:可以回退显示前页内容、可以搜索等。因此,更推荐用 less 查看文件内容。主要命令:
上下箭头:上或下移动
up、down 键:上翻或下翻半屏
b、空格 键:上翻或下翻一屏
q 键:退出
= 键:显示当前的阅读进度。示例: conf/conf.toml lines 38-72/140 byte 7069/11442 62% (press RETURN) ,表示了当前屏幕的行数范围、总行数等信息。
/ 键盘:搜索字符串。然后可分别通过 n、N 键搜索下、前一个。
h 键:命令帮助
vi 或 vim 当然也可查看文件内容,但在读文件的需求下通常为了安全考虑不用该命令,因为其默认是以可写模式打开文件的,容易误操作导致文件被修改。另一方面,其会读取文件全部内容到内存,故若文件大则容易导致占用过多机器资源。
列出当前目录下各文件或子目录的大小: du --max-depth=1 -B G
40、SIGINT、SIGTERM、SIGQUIT 和 SIGKILL 四种信号总结:
|
信号名称
|
信号编号
|
常见触发方式
|
能否被捕获 / 阻塞
|
默认行为
|
典型使用场景
|
核心特点
|
|
SIGINT
|
2
|
终端输入
Ctrl + C |
能
|
终止进程(可自定义处理,如资源清理)
|
手动终止前台交互式进程(如命令行程序)
|
用户主动请求中断,给进程优雅退出的机会
|
|
SIGTERM
|
15
|
kill <PID> 命令默认 |
能
|
终止进程(可自定义处理,如释放资源)
|
正常终止后台服务或进程(如
systemd 管理) |
系统或用户发出的 “友好终止指令”,推荐用于常规关闭
|
|
SIGQUIT
|
3
|
终端输入
Ctrl + \ |
能
|
终止进程并生成 核心转储文件(core dump)
|
需要调试的进程终止(分析崩溃原因)
|
除终止外,额外生成内存快照,便于调试,比 SIGINT 更 “强制” 但仍可被处理
|
|
SIGKILL
|
9
|
kill -9 <PID> 命令 |
不能
|
强制终止进程,无任何清理操作
|
处理无响应的 “僵尸进程” 或无法正常终止的进程
|
终极强制手段,进程无法抵抗,可能导致资源泄漏
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号