分类器设计方法:生成式模型和判别式模型
参考文献:http://blog.csdn.net/zouxy09/article/details/8195017
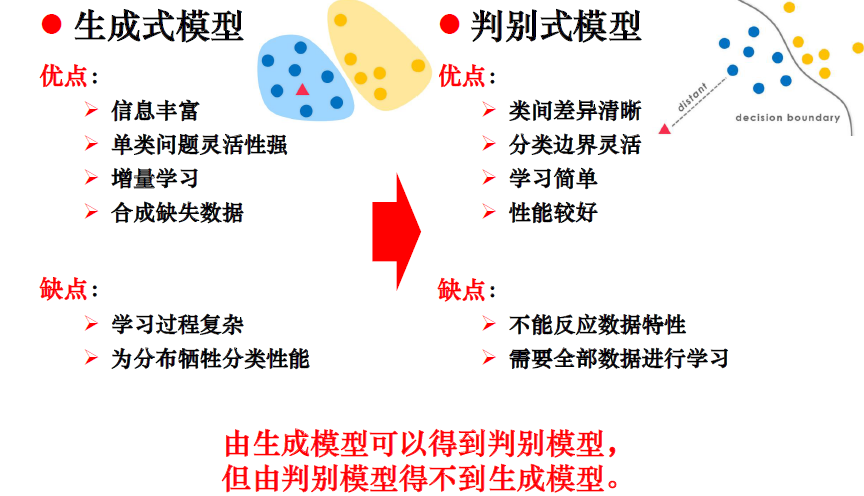
生成方法
- 由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类。
- 生成方法的特点:上面说到,生成方法学习联合概率密度分布P(X,Y),所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。但它不关心到底划分各类的那个分类边界在哪。生成方法可以还原出联合概率分布P(Y|X),而判别方法不能。生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快的收敛于真实模型,当存在隐变量时,仍可以用生成方法学习。此时判别方法就不能用。
- 典型的生成模型有:朴素贝叶斯和隐马尔科夫模型等。
Naive Bayes
Mixtures of Gaussians
Hidden Markov Models
Bayesian Networks
Deep Belief Network
判别方法
- 由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。
- 判别方法的特点:判别方法直接学习的是决策函数Y=f(X)或者条件概率分布P(Y|X)。不能反映训练数据本身的特性。但它寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。直接面对预测,往往学习的准确率更高。由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
- 典型的判别模型有:k近邻,感知级,决策树,支持向量机等。
Linear & Logistic Regression
Support Vector Machine
Nearest Neighbor
Conditional Random Fields
Boosting
区别
- 生成模型学习联合概率分布p(x,y),而判别模型学习条件概率分布p(y|x)。
- 生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
- 由生成模型可以得到判别模型,但由判别模型得不到生成模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号