Java 解释执行与JIT小记
解释执行
https://www.cnblogs.com/z-sm/p/6239377.html
Java代码是解释执行的,先编译成字节码,这些字节码在JVM实例上被一行行解释执行。有两种解释执行的实现方式:
基于内存栈——在软件层面基于内存栈解释执行,传统的字节码解释器。
基于CPU寄存器——在硬件层面基于CPU寄存器解释执行,模板函数解释器:事先把字节码指令集一个个对应成一个包含CPU指令的函数,这样执行时直接找对应的函数执行即可,效果就是把字节码“翻译”成CPU硬件指令执行。
两者对比:前者与硬件无关故跨平台好,但缺点是效率低(一方面是相同的操作用栈实现需要更多的指令、另一方面是CPU比内存块);后者效率高且根据不同CPU架构进行优化,但跨平台性差。
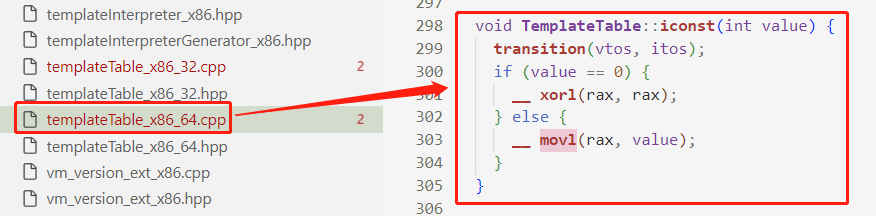
每个字节码指令对应一个函数:
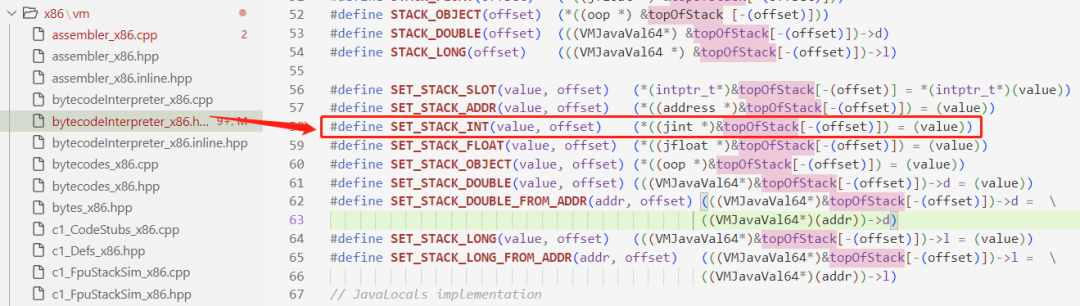 、
、 、
、
函数内容是把字节码对应成CPU指令。应成的指令在不同的CPU架构可能有差异,需要对该架构下的CPU指令熟悉,显然这是个苦力活、怎么对应也是个难活。关于不同CPU架构下的指令集,有兴趣可参阅:https://github.com/sunym1993/computer-all
g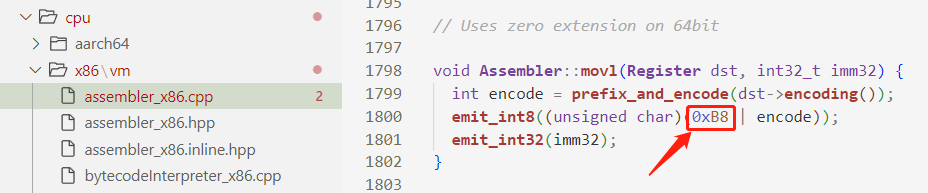
即时编译(JIT)
(来自这篇文章的小总结)
Java程序的大致执行流程:
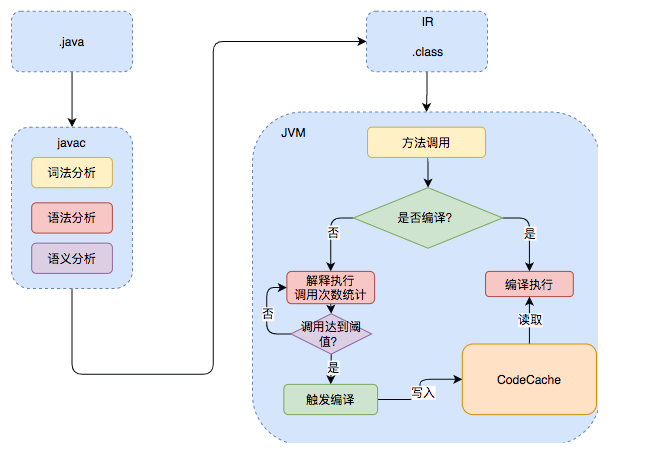
两类即时编译器,对比:
Client Compiler:启动快、运行慢(因为只注重简单的局部编译优化),例如HotSpot虚拟机的 C1 Compiler。适合客户端程序。
Server Compiler:启动慢、运行快(进行全局的编译优化),例如Hotspot虚拟机中的 C2 Compiler、Graal Compiler(JDK9起),默认为前者。适合长时间运行或对峰值性能要求高的后台程序。性能通常比Client Compiler高30%以上。
Graal是用Java写编译器,与ZGC垃圾收集器不兼容,只能与G1收集器搭配使用。
Tier Compiler(分层编译):JDK7开始引入分层编译的概念,即C1、C2综合使用,以追求启动和执行效率两者的平衡。JDK8起默认开启分层编译。
JVM会统计方法或循环等代码块的执行次数,当达到设置的阈值时会进行即时编译。
非分层编译时由参数-XX:CompileThreshold指定阈值(使用C1时,默认值为1500;使用C2时,默认值为10000)
分层编译时触发条件: i > TierXInvocationThreshold * s || (i > TierXMinInvocationThreshold * s && i + b > TierXCompileThreshold * s) i为调用次数,b是循环回边次数
当然,作为编译器,即时编译做的事并不仅仅是将字节码转为机器码,在转成机器码前还会做通常编译器所做的 【去除dead code、表达式免重复计算、方法内联、逃逸分析(及基于逃逸分析的锁消除、栈上分配以及标量替换)、Loop Transformations、窥孔优化与寄存器分配】等各种优化。
JVM即时编译器主要参数:
-XX:+TieredCompilation:开启分层编译,JDK8之后默认开启 -XX:+CICompilerCount=N:编译线程数,设置数量后,JVM会自动分配线程数,C1:C2 = 1:2 -XX:TierXBackEdgeThreshold:OSR编译的阈值 -XX:TierXMinInvocationThreshold:开启分层编译后各层调用的阈值 -XX:TierXCompileThreshold:开启分层编译后的编译阈值 -XX:ReservedCodeCacheSize:codeCache最大大小 -XX:InitialCodeCacheSize:codeCache初始大小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号