Spring IoC 原理
与传统编程模式的区别:对象不用开发者创建而是框架自动创建统一放到容器中、要用对象时也不用写如何拿对象而是直接声明要什么对象即可。
可见,IoC的主要作用是 对象全生命周期管理(自动创建对象、对象依赖关系维护、统一保管对象、自动获取对象给需要者),提供声明式编程方式。
1 What
IoC (Inversion of Control,控制反转)与DI(Dependency Injecion,依赖注入)
用于对象间解耦,如在以前若对象A依赖B则需要在A中负责B的创建初始化等工作,现在有了IoC容器(如Spring的)专门负责对象的创建等生命周期的管理,A中只要声明一个B对象就可使用而不再需要负责初始化B(@Autowired等)。“反转”体现在A获得依赖对象B的过程由之前的主动行为变成了被动行为,即获得依赖对象的过程“反转了”。
IoC主要通过DI(Dependency Injection,依赖注入)实现,而DI在实现上主要是通过反射来动态创建代理对象完成的。
依赖注入的方式:
构造器注入
field注入(直接在定义的变量上注入)
property注入(通过field的setter方法来注入)
注:
Spring依赖注入可通过多种注解达到目的,区别:@Autowired、@Resource等用于引用对象的注入,@Value用于基本类型的的注入。
构造器注入比较容易引起一些问题(如循环依赖导致注入失败从而程序无法启动),实际场景中通常用field注入。
循环依赖问题可以通过setter延迟注入解决:循环依赖使得实例化Bean时因对彼此的依赖满足不了,从而实例化失败;通过延迟注入使得注入时Bean已经创建了,从而可注入成功。
IoC与DI的区别:
IoC表示对象的创建等生命周期由特定容器(如Spring容器)管理。"instantiating objects (beans)"
DI表示对象所依赖的其他“合作者”(其他对象)由容器负责注入到当前对象中。可能是创建对象时注入,也可能是用到依赖的对象时注入。"wiring up of collaborators (or dependencies)"
2 Spring IoC过程分析
三部分组成:
类定义:定义普通的POJO。
元数据定义:关于所要创建的Bean的一些元数据信息。定义方式有三种:xml、java注解、java代码。
创建和关联Bean:Spring容器将根据元数据信息及POJO创建出一系列Bean,并进行管理。
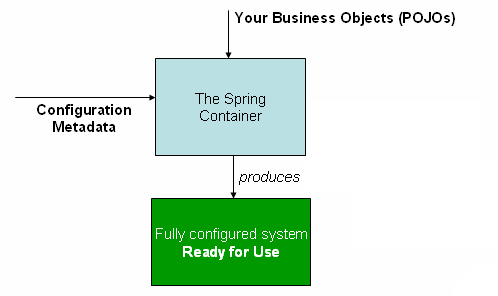
Bean 的生命周期:实例化、属性填充、初始化、使用、销毁。
主要过程:
定位Bean元数据:可在classpath、filesystem、network等位置;Bean可通过XML(beans、bean元素等)、Java注解(Congifuration、Bean注解等)、Java代码三种方式定
加载Bean元数据:读入后创建成BeanDefinition
注册:根据BeanDefinition创建Bean对象并注册到IoC容器(即ApplicationContext)。注意并不是一定都立马创建实例,未被用到的会延迟到等被使用时再创建。
依赖注入:对Bean中依赖其他Bean实例的属性赋值(AbstractAutoWireCapableBeanFactory.populateBean)
Spring IoC容器(Bean Container)、ApplicationContext、BeanFactory可以理解为同一个东西:ApplicationContext和BeanFactory为对容器概念的实现,只不过前者为读容器内容而后者可以读写容器内容,后者为容器内部实现所用而前者为面向使用Spring的开发者所用,前者包含后者。
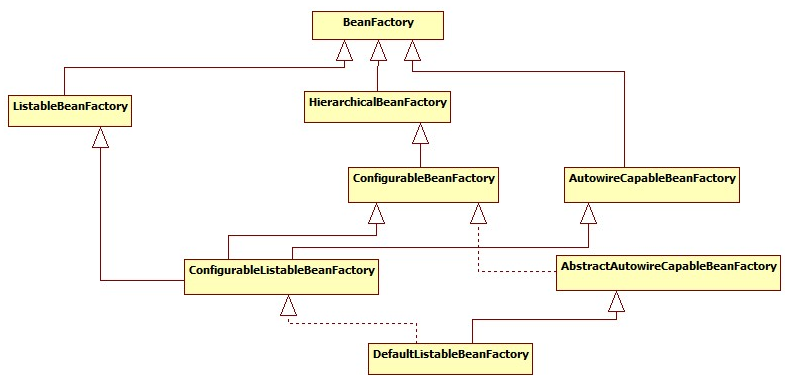
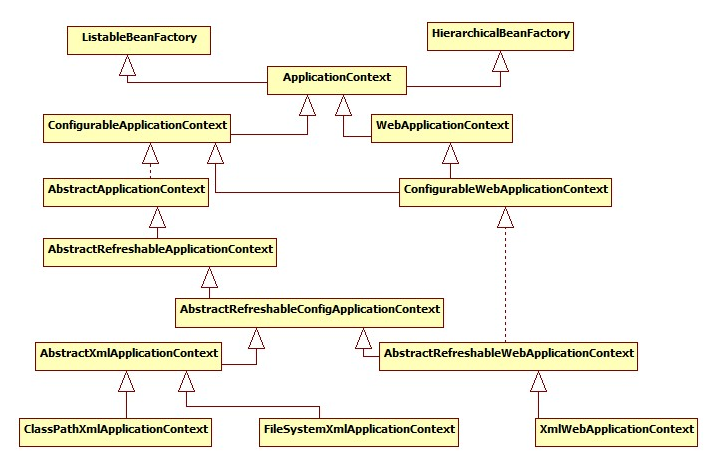
BeanFactory体系:
Bean体系:Spring中Bean对象用BeanDefinition描述
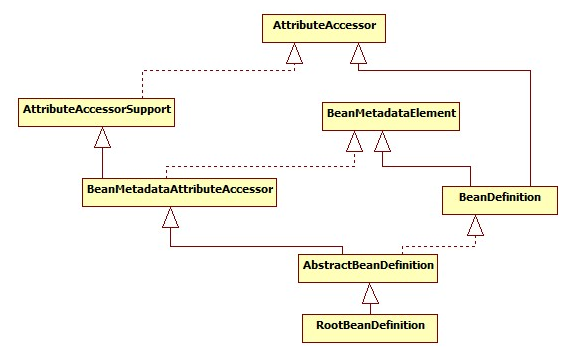
BeanDefinition包含如下信息:
-
-
A package-qualified class name: typically, the actual implementation class of the bean being defined.
-
Bean behavioral configuration elements, which state how the bean should behave in the container (scope, lifecycle callbacks, and so forth).
-
References to other beans that are needed for the bean to do its work. These references are also called collaborators or dependencies.
-
Other configuration settings to set in the newly created object — for example, the size limit of the pool or the number of connections to use in a bean that manages a connection pool.
-
BeanDefinition解析器:
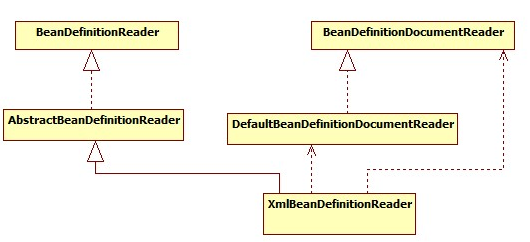
IoC容器体系:
3 Spring Core(IoC Container)doc阅记
官方文档链接:https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html
目录:

3.1 Customizing the Nature of a Bean
顺序:
bean Instantiate:
BeanPostProcessor.postProcessBeforeInitialization
bean Initialize:
BeanPostProcessor.postProcessAfterInitialization
@PostConstruct
InitializingBean.afterPropertiesSet
@Bean[initMethod]
bean destroy:
@PreDestroy
DisposableBean.destroy
@Bean[destroyMethod]
主要用途:配置参数的解析(BeanFactoryPostProcessor)、参数或依赖的注入(BeanPostProcessor)、类或方法参数的validation(BeanPostProcessor)
3.1.1 LifeCycle Callback - Bean initialization/destroy callback
定义某个Bean创建完和销毁前的操作,三种方式:
在Bean内通过注解指定方法:@PostConstruct、@PreDestroy
Bean实现特定接口:InitializingBean.afterPropertiesSet、DisposableBean.destroy
通过@Bean属性指定方法:initMethod、destroyMethod
The Spring container guarantees that a configured initialization callback is called immediately after a bean is supplied with all dependencies. Thus, the initialization callback is called on the raw bean reference, which means that AOP interceptors and so forth are not yet applied to the bean. A target bean is fully created first and then an AOP proxy (for example) with its interceptor chain is applied.
示例:


1 @Configuration 2 class CustomBeanLifecycle { 3 4 @Bean(initMethod = "myInit", destroyMethod = "myDestroy") 5 public AdminModel getAdminModel() { 6 return new AdminModel(); 7 } 8 9 // The Spring container guarantees that a configured initialization callback is 10 // called immediately after a bean is supplied with all dependencies. Thus, the 11 // initialization callback is called on the raw bean reference, which means that 12 // AOP interceptors and so forth are not yet applied to the bean. 13 public static class AdminModel implements InitializingBean, DisposableBean { 14 // 15 public void myInit() { 16 System.err.println(this + " @Bean[initMethod]"); 17 } 18 19 public void myDestroy() { 20 System.err.println(this + " @Bean[destroyMethod]"); 21 } 22 23 // 24 @Override 25 public void afterPropertiesSet() throws Exception { 26 System.err.println(this + " InitializingBean.afterPropertiesSet"); 27 } 28 29 @Override 30 public void destroy() throws Exception { 31 System.err.println(this + " DisposableBean.destroy"); 32 } 33 34 // 35 @PostConstruct 36 public void p1() { 37 System.err.println(this + " PostConstruct1"); 38 } 39 40 @PostConstruct 41 public void p2() { 42 System.err.println(this + " PostConstruct2"); 43 } 44 45 @PreDestroy 46 public void d1() { 47 System.err.println(this + " @PreDestroy1"); 48 } 49 50 @PreDestroy 51 public void d2() { 52 System.err.println(this + " @PreDestroy2"); 53 } 54 } 55 } 56 57 58 59 //启动时输出: 60 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe PostConstruct1 61 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe PostConstruct2 62 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe InitializingBean.afterPropertiesSet 63 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @Bean[initMethod] 64 65 //kill 9时输出 66 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @PreDestroy1 67 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @PreDestroy2 68 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe DisposableBean.destroy 69 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @Bean[destroyMethod]
当三种方式都存在时,为按上述所列三种方式的优先级;优先级高的initaialization callback、destroy callback先执行。如上述示例创建和销毁时的输出分别如下:
//启动时输出: com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe PostConstruct1 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe PostConstruct2 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe InitializingBean.afterPropertiesSet com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @Bean[initMethod] //kill 9时输出 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @PreDestroy1 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @PreDestroy2 com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe DisposableBean.destroy com.marchon.learn.store.config.CustomBeanLifecycle$AdminModel@264f18fe @Bean[destroyMethod]
当三种方式指定的initaialization callback方法名有重时,重名方法只会执行一次;destroy callback同理。
3.1.2 LifeCycle Callback - ApplicationContext start/shutdown callback
详情参阅该文档。
3.1.3 LifeCycle Callback - BeanPostProcessor callback
用于指定在Bean initialization前后做的动作(已经instantiate但尚未initailize),可见其比前面介绍的callback更早被调用。
对所有Bean都有效,即在每个Bean实例化前后都会调用BeanPostProcessor中指定的方法;
scope为per-container(即application);
可以有多个BeanPostProcessor,可以给其指定优先级,将按优先级调用;
The
BeanPostProcessorinterface defines callback methods that you can implement to provide your own (or override the container’s default) instantiation logic, dependency resolution logic, and so forth.The post-processor gets a callback from the container both before container initialization methods (such as
InitializingBean.afterPropertiesSet()or any declaredinitmethod) are called, and after any bean initialization callbacks.
示例:
@Bean public MyBeanPostProcessor getMyBeanPostProcessor() { return new MyBeanPostProcessor(); } // The BeanPostProcessor interface defines callback methods that you can // implement to provide your own (or override the container’s default) // instantiation logic, dependency resolution logic, and so forth. // public static class MyBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {//在每个Bean Initialization前将执行此方法 System.err.println(beanName + " BeanPostProcessor.postProcessBeforeInitialization"); return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {//在每个Bean Initialization后将执行此方法 System.err.println(beanName + " BeanPostProcessor.postProcessAfterInitialization"); return bean; } }
应用:可借此来扩展或修改Spring容器的功能,如:
Spring对Bean或方法进行参数验证是通过 BeanValidationPostProcessor、MethodValidationPostProcessor 完成的。
@Autowired、@Value、@Resource、@Inject等注解就是由BeanPostProcessor的实现类 AutowiredAnnotationBeanPostProcessor 处理的。故若自定义了BeanFactory并覆盖默认实现,则这些注解可能就不生效了。CommonAnnotationBeanPostProcessor类似。
Spring中为原对象创建代理对象也是借助BeanPostProcessor来实现的(AbstractAutoProxyCreator)。
3.1.4 LifeCycle Callback - BeanFactoryPostProcessor callback
BeanFactoryPostProcessor与BeanPostProcessor类似,区别:
BeanPostProcessor是在Bean instantiate之后在接下来的initialize前后执行。处理的对象是Bean,影响的是Bean的initialize过程。
BeanFactoryPostProcessor是在Bean instantiate前后执行,此时任何Bean都尚未instantiate。处理的对象是BeanFactory,影响的是Bean的instantiate过程。
可见BeanFactoryPostProcessor比BeanPostProcessor更早被调用。此外,BeanFactoryPostProcessor中的方法只会被执行一次(在所有Bean instantiate之前)。
作用:
用于修改Bean Definition(此时所有Bean Definition都已load到BeanFactory,但都未创建出Bean)。典型应用是Spring中配置文件的解析、配置类的增强,如 PropertyResourceConfigurer、PropertySourcesPlaceholderConfigurer、PropertyOverrideConfigurer(因为我们可能通过配置来指定Bean的加载行为,所以配置文件的解析是在Bean的实例化之前的,优先级很高)
BeanFactoryPostProcessoroperates on the bean configuration metadata. That is, the Spring IoC container lets aBeanFactoryPostProcessorread the configuration metadata and potentially change it before the container instantiates any beans
用于往容器添加Bean(手动注册Bean),示例:
法1:通过BeanFactoryPostProcessor手动添加Bean
public static class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor { @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { beanFactory.registerSingleton("myTestObj", new Object());//手动注册手动创建的对象到Spring容器,作为一个Bean。其他地方可以@Autowired取该Bean System.err.println(this + " BeanFactory PostProcessor beanFactory is " + beanFactory); } }
法2:直接通过ApplicationContext注入
ApplicationContext ctx = SpringApplication.run(new Class<?>[] { StoreMain.class }, args); System.err.println(ctx);// org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext String customBeanName = "myBeanA"; ((DefaultListableBeanFactory) ((ConfigurableApplicationContext) ctx).getBeanFactory()).registerBeanDefinition( customBeanName, BeanDefinitionBuilder.genericBeanDefinition(Object.class).getRawBeanDefinition());// 通过Application获取BeanFactory从而注入Bean System.err.println(ctx.getBean(customBeanName));// java.lang.Object@1e14ed59,读取到的注入的Bean
3.2 Aware Interfaces
作用:可以理解成一种设计模式,使得Bean能收到容器的通知,从而在Bean内部能够获得自身或外部的某些信息。Bean只要实现Aware接口就能收到对应的通知。
示例:ApplicationContextAware、BeanNameAware、MessageSourceAware等等。示例:
@Configuration class CustomBeanLifecycle { /** 以下为Aware(通知)模式 demo */ @Bean(name = "studentZhang") public StudentModel getStudetnModel() { return new StudentModel(); } public static class StudentModel implements BeanNameAware, BeanFactoryAware, ApplicationContextAware, BeanClassLoaderAware { @Override public void setBeanName(String name) { System.err.println(this + " beanName is " + name);//输出为 studentZhang } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { System.err.println(this + " applicationContext is " + applicationContext); } @Override public void setBeanFactory(BeanFactory beanFactory) throws BeansException { System.err.println(this + " beanFactory is " + beanFactory); } @Override public void setBeanClassLoader(ClassLoader classLoader) { System.err.println(this + " classLoader is " + classLoader); } } }
Note again that using these interfaces ties your code to the Spring API and does not follow the Inversion of Control style. As a result, we recommend them for infrastructure beans that require programmatic access to the container.
原理:对于一个Bean,如果实现了某Aware接口,则Spring容器会自动调用Bean实例中该接口的方法,从这角度看实际上相当于注册了个回调函数。
缺点及解决:使用这些接口违反了“IoC”原则——相当于由Bean负责设置依赖的对象。解决:可以不使用这些接口,而是直接通过Autowired等注入,如 @Autoweired private ApplicationContext ctx;
3.3 Annotation-based Container Configuration
@Configuration、@Bean、@Import、@Scope、@Lazy、@DependsOn、@ComponentScan。@ComponentScan用于指定扫描策略如路径等。
@PostConstruct、@PreDestroy
@Autowired、@Value、@Resource、@Primary、@Qualifiers
@Component、@Controller、@RestController、@Service、@Repository等(所谓sterotype annotation),被这些修饰的类会被自动扫描为Bean,可通过@ComponentScan useDefaultFilters=false禁用默认行为
详情可参阅该文档最后一部分:https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#beans-annotation
3.4 Java-based Container Configuration
AnnotationConfigApplicationContext、AnnotationConfigWebApplicationContext
4 其他
Spring 是如何解决循环依赖的
循环依赖是指多个对象间互相依赖(可能是直接依赖,也可能是间接依赖,这里以直接依赖为例)而形成闭环的情况。例如对象A依赖于B、B也依赖于A;A、B也可以是同一个对象,此时就是自己依赖自己。
Java对象和Spring Bean的创建过程
JVM创建Java对象的主要过程:
对象的实例化:通过构造器等创建Java对象实例。
对象的初始化:为该对象的field等赋值。
类似的,Spring容器创建Spring Bean的主要过程:
Bean的实例化(createBeanInstance):实际上就是上述Java对象的创建过程,包括对象的实例化、初始化。
Bean的初始化(populateBean、initializeBean):包括解析该Bean中依赖的其他Bean并进行注入(即DI,如@Autowired)、执行各种initialize callback(如 InitializingBean.afterPropertiesSet ,见前文)。
循环依赖的场景和支持情况
由于依赖注入有构造器注入、field注入、setter注入三种,故对应的循环依赖也有这三者情形。但Spring并不是支持每种循环依赖,先上结论:
对于Java对象的创建,三种情形都会因为循环依赖而栈溢出。示例:
public class Main { public static void main(String[] args) { new A();//Exception in thread "main" java.lang.StackOverflowError } } class A { private B b = new B(); } class B { private A a = new A(); }
对于Spring Bean,Spring只解决了单例Bean的field注入和setter注入的循环依赖问题。由于Bean的实例化和初始化是在代码层面完全分开的两个阶段,故理论上来说只要能把Bean对象实例成功创建出来就可以解决循环依赖,即理论上Spring Bean的field注入和setter注入的循环依赖都可以被解决,但实际上Spring只支持单例Bean的这两种循环依赖(可能是出于简单考虑?)。
@SpringBootApplication public class Main { public static void main(String[] args) { SpringApplication.run(Main.class, args).getBean("a"); } } //构造器循环依赖:会因循环依赖而启动失败 @Component class A { public A(@Autowired B b) { } } @Component class B { public B(@Autowired A a) { } } //field单例注入循环依赖:正常启动、正常work @Component class A { @Autowired private B b; } @Component class B { @Autowired private A a; } //setter单例注入循环依赖:正常启动、正常work @Component class A { private B b; @Autowired public void setB(B b) { this.b = b; } } @Component class B { private A a; @Autowired public void setA(A a) { this.a = a; } } //非单例的循环依赖(field或setter注入均如是):正常启动,但执行getBean("a")会报错(因为非单例的注入Spring不会在启动就注入而是使用时才注入):Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference? @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) @Component class A { @Autowired private B b; } @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) @Component class B { @Autowired private A a; }
Spring如何解决单例循环依赖
Spring能解决Bean的循环依赖,主要是因为将Bean的创建过程在代码层面分为了两个阶段,因此只要Bean实例化了,那么就可以在接下来初始化时进行循环依赖的解决(从这角度上看,如果JVM要解决Java对象的循环依赖其实也能做到)。
//假设是先创建Bean A再创建Bean B
@Component class A { @Autowired private B b; } @Component class B { @Autowired private A a; }
具体如何做到的呢?以上述 field单例注入(假设Bean A比B先创建)为例,最朴素直观的想法:
将Bean实例化了但未初始化完成(即未完全创建完成)的状态认为是半成品状态,在初始化A(解析依赖B)时,虽然Bean A尚未完全成功创建,但可以将半成品的A暂存起来(即所谓的缓存)认为是半创建完成;接下来去创建Bean B,此时又依赖A,可以去找完全创建完成的或半创建完成的A,能够找到,从而B能成功创建完成;A的依赖B创建完成了,那么A也能完成创建。
可见,解决循环依赖,本质上是利用“完成实例化但尚未完成初始化”的这个中间状态来搞事。其理论依据是“当获取对象的引用时对象的属性可以延后设置,但构造器必须是在获取引用之前执行”。构造器循环依赖的场景中,对象尚未实例化故无法解决该场景下的循环依赖问题。
实际上,Spring解决循环依赖的方式就是上述思路,其关键是用所谓的三级缓存来保存 完全创建完成的Bean、半创建完成的Bean、Bean的ObjectFactory实例。
关键的类是 AbstractAutowireCapableBeanFactory -> AbstractBeanFactory -> DefaultSingletonBeanRegistry, 前者继承后者。其中前两者是通用的关于Spring Bean生命周期管理实现(Bean的实例化、初始化等)的类,而最后一个是专门处理单例Bean的类,因此单例循环依赖主要由该类解决。
三级缓存:
DefaultSingletonBeanRegistry类中定义了三级缓存(singletonObjects、earlySingletonObjects、singletonFactories):
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { ... // 从上至下 分表代表这“三级缓存” private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); //一级缓存 private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); // 二级缓存 private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); // 三级缓存 ... /** Names of beans that are currently in creation. */ // 表示bean创建过程中都会在里面放着 // 它在Bean开始创建时放值,创建完成时会将其移出 private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16)); }
Map<String, Object> singletonObjects:一级缓存。存放完全初始化好了(也即完全创建完成了)的单例bean,从该缓存中取出的单例bean可直接使用。
Map<String, Object> earlySingletonObjects:二级缓存。存放实例化了但尚未进行Bean属性填充等初始化操作的单例bean(Spring中称为earlyExposteObject,提前暴露的对象),用于解决循环依赖。
Map<String, ObjectFactory<?>> singletonFactories:三级缓存。存放单例Bean的工厂对象,用于解决循环依赖。
当要从单例缓存中查某个Bean A时,A可能是尚未实例化的、也可能是已实例化但尚未初始化的、还可能是实例化初始化都完成了的。因此,从三级缓存中查询单例的主要逻辑:
@Nullable protected Object getSingleton(String beanName, boolean allowEarlyReference) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return singletonObject; }
case 1:优先从1级查A,查到则说明是之前完全创建好了(即实例化和初始化都完成了)的单例,直接返回(例如用户第二次从容器获取单例A就是此情况)。若查不到则:
case 2:若A不是正在创建(即未进行实例化和初始化)的状态,返回null(例如用户第一次从容器获取单例A时容器内部会先从缓存查单例A、查不到则创建单例A,前者就是此情况)。
case 3:若A是正在创建的(即已实例化但未初始化的),则从2级查,若查到则直接返回(例如解析A的依赖B时要进而解析B的依赖A,后者获取单例A时候就是此情况)。若查不到则:
case4:若允许循环依赖(allowEarlyReference)则从3级缓存中获取A的factory得到A的单例(这个factory生成A的逻辑是直接返回实例化但未初始化的A对象,即所谓的getEarlyBeanReference),并放入2级缓存(例如解析A的依赖B时要进而解析B的依赖A,后者获取单例A时候就是此情况)。
case5:若不允许循环依赖则返回null。
DefaultSingletonBeanRegistry还有个方法getSingleton(String beanName, ObjectFactory<?> singletonFactory),单例的创建由此方法完成。相关源码:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(beanName, "Bean name must not be null"); synchronized (this.singletonObjects) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null) { if (this.singletonsCurrentlyInDestruction) { throw new BeanCreationNotAllowedException(beanName, "Singleton bean creation not allowed while singletons of this factory are in destruction " + "(Do not request a bean from a BeanFactory in a destroy method implementation!)"); } if (logger.isDebugEnabled()) { logger.debug("Creating shared instance of singleton bean '" + beanName + "'"); } beforeSingletonCreation(beanName); boolean newSingleton = false; boolean recordSuppressedExceptions = (this.suppressedExceptions == null); if (recordSuppressedExceptions) { this.suppressedExceptions = new LinkedHashSet<>(); } try { singletonObject = singletonFactory.getObject(); newSingleton = true; } catch (IllegalStateException ex) { // Has the singleton object implicitly appeared in the meantime -> // if yes, proceed with it since the exception indicates that state. singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null) { throw ex; } } catch (BeanCreationException ex) { if (recordSuppressedExceptions) { for (Exception suppressedException : this.suppressedExceptions) { ex.addRelatedCause(suppressedException); } } throw ex; } finally { if (recordSuppressedExceptions) { this.suppressedExceptions = null; } afterSingletonCreation(beanName); } if (newSingleton) { addSingleton(beanName, singletonObject); } } return singletonObject; } }
该方法的主要逻辑:根据指定Bean名字从一级缓存查该单例,存在则直接返回,否则用指定的factory来创建实例对象并将该对象放入一级缓存。注:
与上述getSingleton方法的case4不同,这里是真正地创建对象,而上述case 4中是返回实例化但未初始化的对象的引用而已。
上述case2中,对象是否处于创建状态正是在此方法中进行标记的:会在singletonFactory执行前后将该Bean名字对应的Bean标记为创建中、创建完成。
上述流程中有些疑问,比如A的factory何时放入三级缓存的?下文解答。
流程概要:
以上述单例A、B互相依赖,且容器先创建A为例。
1 从单例缓存中查单例A(调用上述DefaultSingletonBeanRegistry.getSingleton方法),查不到;根据A的Bean Definition知A是单例,故调用DefaultSingletonBeanRegistry.getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法来创建单例A。相关源码:
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType, @Nullable final Object[] args, boolean typeCheckOnly) throws BeansException { ... // Eagerly check singleton cache for manually registered singletons. Object sharedInstance = getSingleton(beanName); if (sharedInstance != null && args == null) { ... bean = getObjectForBeanInstance(sharedInstance, name, beanName, null); } else { ... if (!typeCheckOnly) { markBeanAsCreated(beanName); } try { ... // Create bean instance. if (mbd.isSingleton()) { sharedInstance = getSingleton(beanName, () -> { try { return createBean(beanName, mbd, args); } catch (BeansException ex) { // Explicitly remove instance from singleton cache: It might have been put there // eagerly by the creation process, to allow for circular reference resolution. // Also remove any beans that received a temporary reference to the bean. destroySingleton(beanName); throw ex; } });//调用DefaultSingletonBeanRegistry.getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法来创建单例 bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd); } ... } ... return (T) bean; }
2 执行DefaultSingletonBeanRegistry.getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法(相关源码见上文),其内部主要逻辑:
2.1 先将A标记为创建中: beforeSingletonCreation(beanName); ;
2.2 接着调用singletonFactory.getObject方法得到实例化且初始化了的A对象: singletonObject = singletonFactory.getObject(); ;
2.3 然后将A标记为创建完成: afterSingletonCreation(beanName); ;
2.4 最后将A放入一级缓存,且若二、三级缓中也存在则从中删除A: addSingleton(beanName, singletonObject); 。可见,这步执行完后A就在一级缓存了。
由第一步所传实参知,2.2 的getObject即去执行AbstractAutowireCapableBeanFactory.createBean/doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)方法。该方法的主要逻辑:
// 抽象方法createBean所在地 这个接口方法是属于抽象父类AbstractBeanFactory的 实现在这个抽象类里 public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory implements AutowireCapableBeanFactory { ... protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args) throws BeanCreationException { ... // 创建Bean对象,并且将对象包裹在BeanWrapper 中 instanceWrapper = createBeanInstance(beanName, mbd, args); // 再从Wrapper中把Bean原始对象(非代理~~~) 这个时候这个Bean就有地址值了,就能被引用了~~~ // 注意:此处是原始对象,这点非常的重要 final Object bean = instanceWrapper.getWrappedInstance(); ... // earlySingletonExposure 用于表示是否”提前暴露“原始对象的引用,用于解决循环依赖。 // 对于单例Bean,该变量一般为 true 但你也可以通过属性allowCircularReferences = false来关闭循环引用 // isSingletonCurrentlyInCreation(beanName) 表示当前bean必须在创建中才行 boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); if (earlySingletonExposure) { if (logger.isTraceEnabled()) { logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references"); } // 上面讲过调用此方法放进一个ObjectFactory,二级缓存会对应删除的 // getEarlyBeanReference的作用:调用SmartInstantiationAwareBeanPostProcessor.getEarlyBeanReference()这个方法 否则啥都不做 // 也就是给调用者个机会,自己去实现暴露这个bean的应用的逻辑~~~ // 比如在getEarlyBeanReference()里可以实现AOP的逻辑~~~ 参考自动代理创建器AbstractAutoProxyCreator 实现了这个方法来创建代理对象 // 若不需要执行AOP的逻辑,直接返回Bean addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); } Object exposedObject = bean; //exposedObject 是最终返回的对象 ... // 填充属于,解决@Autowired依赖~ populateBean(beanName, mbd, instanceWrapper); // 执行初始化回调方法们~~~ exposedObject = initializeBean(beanName, exposedObject, mbd); // earlySingletonExposure:如果你的bean允许被早期暴露出去 也就是说可以被循环引用 那这里就会进行检查 // 此段代码非常重要~~~~~但大多数人都忽略了它 if (earlySingletonExposure) { // 此时一级缓存肯定还没数据,但是呢此时候二级缓存earlySingletonObjects也没数据 //注意,注意:第二参数为false 表示不会再去三级缓存里查了~~~ // 此处非常巧妙的一点:::因为上面各式各样的实例化、初始化的后置处理器都执行了,如果你在上面执行了这一句 // ((ConfigurableListableBeanFactory)this.beanFactory).registerSingleton(beanName, bean); // 那么此处得到的earlySingletonReference 的引用最终会是你手动放进去的Bean最终返回,完美的实现了"偷天换日" 特别适合中间件的设计 // 我们知道,执行完此doCreateBean后执行addSingleton() 其实就是把自己再添加一次 **再一次强调,完美实现偷天换日** Object earlySingletonReference = getSingleton(beanName, false); if (earlySingletonReference != null) { // 这个意思是如果经过了initializeBean()后,exposedObject还是木有变,那就可以大胆放心的返回了 // initializeBean会调用后置处理器,这个时候可以生成一个代理对象,那这个时候它哥俩就不会相等了 走else去判断吧 if (exposedObject == bean) { exposedObject = earlySingletonReference; } // allowRawInjectionDespiteWrapping这个值默认是false // hasDependentBean:若它有依赖的bean 那就需要继续校验了~~~(若没有依赖的 就放过它~) else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) { // 拿到它所依赖的Bean们~~~~ 下面会遍历一个一个的去看~~ String[] dependentBeans = getDependentBeans(beanName); Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length); // 一个个检查它所以Bean // removeSingletonIfCreatedForTypeCheckOnly这个放见下面 在AbstractBeanFactory里面 // 简单的说,它如果判断到该dependentBean并没有在创建中的了的情况下,那就把它从所有缓存中移除~~~ 并且返回true // 否则(比如确实在创建中) 那就返回false 进入我们的if里面~ 表示所谓的真正依赖 //(解释:就是真的需要依赖它先实例化,才能实例化自己的依赖) for (String dependentBean : dependentBeans) { if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } // 若存在真正依赖,那就报错(不要等到内存移除你才报错,那是非常不友好的) // 这个异常是BeanCurrentlyInCreationException,报错日志也稍微留意一下,方便定位错误~~~~ if (!actualDependentBeans.isEmpty()) { throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been " + "wrapped. This means that said other beans do not use the final version of the " + "bean. This is often the result of over-eager type matching - consider using " + "'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example."); } } } } return exposedObject; } // 虽然是remove方法 但是它的返回值也非常重要 // 该方法唯一调用的地方就是循环依赖的最后检查处~~~~~ protected boolean removeSingletonIfCreatedForTypeCheckOnly(String beanName) { // 如果这个bean不在创建中 比如是ForTypeCheckOnly的 那就移除掉 if (!this.alreadyCreated.contains(beanName)) { removeSingleton(beanName); return true; } else { return false; } } }
2.2.1 实例化A: createBeanInstance(beanName, mbd, args) ;
2.2.2 将A加入三级缓存: addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); ,可见factory逻辑是getEarlyBeanReference A,即获取半成品A的引用;
2.2.3 初始化A: populateBean(beanName, mbd, instanceWrapper); initializeBean(beanName, exposedObject, mbd); } ,前者是对A进行依赖注入、后者是对执行A的初始化callback。这里比较关键的是前者,将B注入A的主要流程如下:
由于B不存在,故与A类似,执行上述各步骤,得到半成品B。此时A、B都在第三级缓存。 ->
接下来解析B的依赖A:从缓存查到A(从第三级缓存查得A,A移到第二级缓存),故A成功注入到B,从而B创建成功,B进入第一级缓存。->
得到了Bean B,故B成功注入到A,从而A创建成功,A进入第一级缓存。
从上述流程可知:
Spring解决循环依赖的过程与前面所述最直观朴素的想法是相符的。
一个Bean不会同时在三级缓存中都同时存在,最多只会在其中一个。若是单例,则肯定会在其中之一,且最终是在一级缓存。
单例A是在容器实例化A后被放入三级缓存的、A是在解析B的依赖A时被放入二级缓存的、A是在初始化完成后进入一级缓存的。即单例是依次放入三级、二级、一级的。
当 Spring 为某个 Bean 填充属性的时候,它首先会寻找需要注入对象的名称,然后依次执行 getSingleton() 方法得到所需注入的对象,而获取对象的过程就是先从一级缓存中获取,一级缓存中没有就从二级缓存中获取,二级缓存中没有就从三级缓存中获取,如果三级缓存中也没有,那么就会去执行 doCreateBean() 方法创建这个 Bean。
Spring为什么用三级而非二级缓存:
与AOP相关,如果创建的 Bean 是有代理的,那么注入的就应该是代理 Bean,而不是原始的 Bean。但 Spring 一开始并不知道 Bean 是否会有循环依赖,通常情况下(没有循环依赖的情况下),Spring 都会在完成填充属性,并且执行完初始化方法之后再为其创建代理。但是,如果出现了循环依赖的话,Spring 就不得不为其提前创建代理对象,否则注入的就是一个原始对象,而不是代理对象。
所以Spring引入三级缓存的原因:为了在没有循环依赖的情况下延迟代理对象的创建以使 Bean 的创建符合 Spring 的设计原则。【Spring的设计原则是在对象初始化完成后才为对象创建代理对象,而在循环依赖场景下不得不提前(实例化后初始化前)创建代理否则注入的是错误的对象】,但Spring在实例化一个对象后并不知道会不会有循环依赖,所以引入了第三级缓存来确保没有循环依赖时代理对象的延迟创建。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { Object exposedObject = bean; if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof SmartInstantiationAwareBeanPostProcessor) { SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp; // 如果需要代理,这里会返回代理对象;否则返回原始对象 exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName); } } } return exposedObject; }
getEarlyBeanReference的效果是获取指定bean自身或该bean的代理对象。逻辑如上代码所示,最终是去调用了SmartInstantiationAwareBeanPostProcessor.getEarlyBeanReference 方法,该方法在框架内的实现如下:
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware { @Override public Object getEarlyBeanReference(Object bean, String beanName) { Object cacheKey = getCacheKey(bean.getClass(), beanName); // 记录已被代理的对象 this.earlyProxyReferences.put(cacheKey, bean); return wrapIfNecessary(bean, beanName, cacheKey); } }
其就是在需要代理时将指定的Bean进行代理包装。若此时生成了代理对象,则之后对象初始化完成后就不用再进行代理包装了。可见,当不存在循环依赖时,getEarlyBeanReference不会被执行,从而不会提早进行代理包装而是等初始化完成后才会代理包装。
如何改造为只用两个缓存?
如果不遵循延迟创建代理对象(对象初始化后再创建代理对象)的原则,则完全可以只用二级缓存,不会影响正确性,只不过可能启动速度慢些。只需要将半成品直接放入二级缓存即可(修改addSingletonFactory方法):
//原始方法 protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } } //改造后的方法 protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { // 判断一级缓存中不存在此对象 object o = singletonFactory.getObject(); // 直接从工厂中获取 Bean this.earlySingletonObjects.put(beanName, o); // 添加至二级缓存中 this.registeredSingletons.add(beanName); } } }
对于使用的启示:
业务代码中尽量不要使用构造器注入,即使它有很多优点。
业务代码中为了简洁,尽量使用field注入而非setter方法注入。
若你注入的同时,立马需要处理一些逻辑(一般见于框架设计中,业务代码中不太可能出现),可以使用setter方法注入辅助完成。
参考资料:
https://fangshixiang.blog.csdn.net/article/details/92801300#comments_16646446——YourBatman
https://juejin.cn/post/6882266649509298189
5 参考资料
(推荐阅读官方文档,写得比较全面易懂)
https://blog.csdn.net/ivan820819/article/details/79744797 (什么是IoC/DI)
https://blog.csdn.net/javazejian/article/details/54561302(Spring IoC使用)
https://www.cnblogs.com/ITtangtang/p/3978349.html(Spring IoC源码解读)
https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html(Spring IoC官方文档)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号