链路追踪工具之Zipkin学习小记
(接触了Zipkin,权将所了解或理解的记于此,以备忘)
分布式追踪系统
随着业务发展,系统拆分多个微服务。此时对于一个前端请求可能需要调用多个后端端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的。此时就需要有某种方式来定位到故障位,这就是分布式系统调用跟踪的诞生。
分布式服务调用追踪的理论基础是Google 2010年发表的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》(译文:Dapper,大规模分布式系统的跟踪系统)。为了实现平台无关、厂商无关的分布式服务跟踪,CNCF(Cloud Native Computing Foundation,云原生计算基金会,一个厂商中立的基金会,致力于Github上的快速成长的开源技术的推广,如Kubernetes、Prometheus、Envoy等)发布了布式服务跟踪标准 Open Tracing。基于该标准有很多具体实现,如Google的Dapper、Twitter的Zipkin,国内的有淘宝的鹰眼、京东的Hydra、大众点评的CAT、新浪的Watchman等,其中使用的最广泛的是 Twitter 的 Zipkin。
几个概念
trace、span
Trace 表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span(意为持续时间?)。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,则每个处理请求的服务就可以理解为一个 Span(可包括 API 服务,缓存服务,数据库服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。
Zipkin - what
Zipkin是一个开源的分布式追踪系统,用于对服务间的调用链路进行监控追踪。在微服务架构下,用户的一个请求可能涉及到很多个后台服务间的调用,Zipkin可以追踪(trace)调用链路、收集在各个微服务上所花的时间等信息、并上报到Zipkin服务器。
Zipkin是根据Google Dapper设计的,由Twitter公司开发。
项目GitHub:https://github.com/openzipkin/zipkin
功能
Zipkin项目功能齐全,项目提供了链路追踪(trace)、数据上报(collector)、数据存储(server storage)、数据展示(server ui)等封装模块。
1、链路追踪(request trace):即Zipkin client,用于对用户的调用进行追踪,Zipkin提供了java、go、js等各种主流语言的追踪库:开箱即用,以少量代码且很少的业务代码侵入代价实现追踪。brave是zipkin提供的java下的trace library,其提供了针对rpc、http、kafka、mysql、jmx等很多调用类型的追踪(参阅:https://github.com/openzipkin/brave),从中收集到调用耗时等信息。
2、数据上报(collector/transport):即Zipkin server接收Zipkin client所收集信息的方式,Zipkin支持HTTP Restful API、Kafka、rabbitmq等形式来接收数据(参阅:https://github.com/openzipkin/zipkin/tree/master/zipkin-collector),默认为HTTP形式。
3、数据存储(server storage):即Zipkin server对client上传来的数据的存储形式,Zipkin提供了In-Memory、MySQL、Cassandra、Elasticsearch等形式(参阅:https://github.com/openzipkin/zipkin/tree/master/zipkin-storage)。默认为In-Memory形式。
4、数据展示(server ui):通过Zipkin server ui展示收集到的调用链信息。
5、... ...
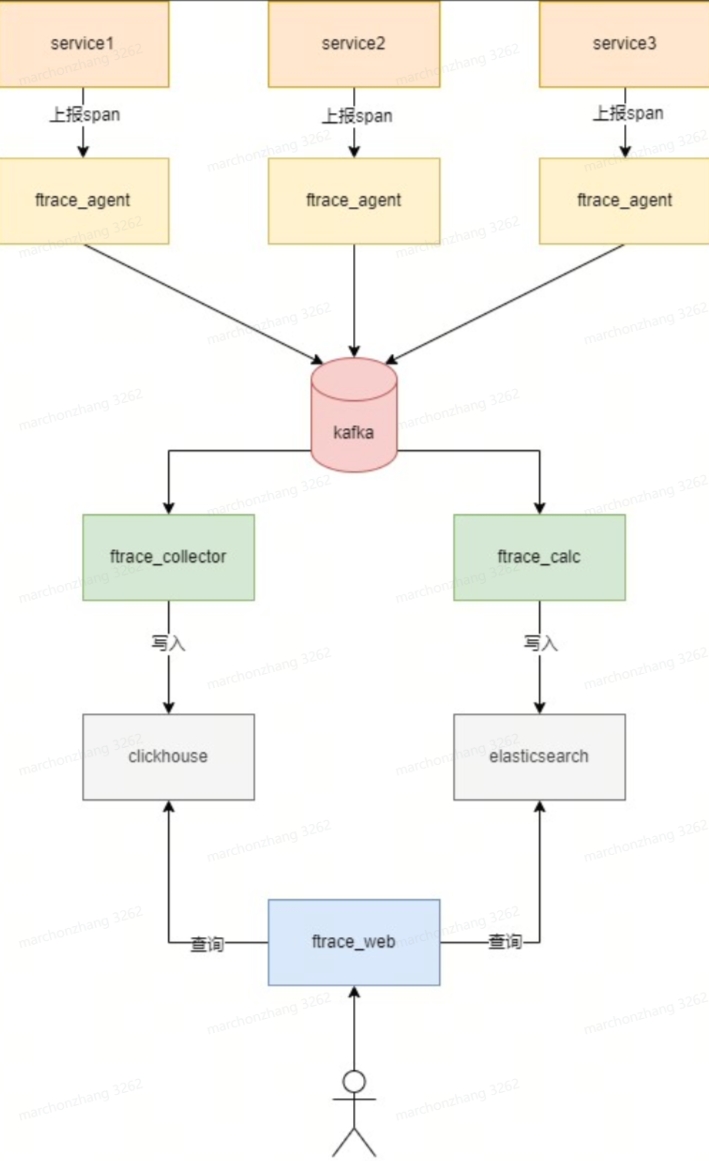
calc模块用于计算链路拓扑、方法/服务调用次数、错误次数、时延等信息,并写入es,用于查询、展示、分析。
可以预见,万变不离其宗,Zipkin client主要就是各种语言下的library、而一个Zipkin server则是对Collector、Storage、UI等的整合。
原理
用traceId、spanId、parentSpanId来完成一次请求中涉及到的多个服务的调用链追踪:
traceId:一次请求时各服务的traceId一样,表示是同一请求的不同服务过程
spanId:不同服务的spanId不同,表示本服务的标识
parentSpanId:用于表示本服务的调用者的spanId,这样就把各服务的调用顺序关系串起来了
sampled:标记本span是否采样
采样策略
更多参考资料:分布式服务跟踪及Spring Cloud的实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号