

先看一个需求
from collections import defaultdict """ 需求: 统计user_list中字母出现的次数 """ user_dict = {} user_list = ['A', 'B', 'C', 'A', 'C', 'C'] # 第一种方式 for item in user_list: if item not in user_dict: user_dict[item] = 1 else: user_dict[item] += 1 print(user_dict) # {'A': 2, 'B': 1, 'C': 3} # 第二种方式 user_dict = {} user_list = ['A', 'B', 'C', 'A', 'C', 'C'] for item in user_list: user_dict.setdefault(item, 0) # 如果user_dict无item这个key,添加{item:0} , 如果有,不管. 而且这个方法性能比第一种方式好 user_dict[item] += 1 # item的value值累加1 print(user_dict) # {'A': 2, 'B': 1, 'C': 3} # 第三种方式.使用defaultdict default_dict = defaultdict(int) user_list = ['A', 'B', 'C', 'A', 'C', 'C'] for item in user_list: default_dict[item] += 1 # 使用这种方式,代码更简单,性能也更好 print(default_dict) # defaultdict(<class 'int'>, {'A': 2, 'B': 1, 'C': 3})
defaultdict的使用

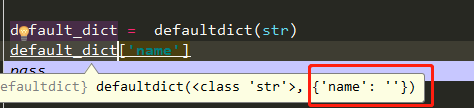

由上面的示例可知,defaultdict会根据创建实例参数的类型生成一个对应类型的默认值,
这对于dict类型的数据结构而言,可以很好避免KeyError类型的错误 .
此外,我们还可以自定义defaultdict调用对象的数据结构,以满足我们实际需要
def person(): '''自定义一个可调用对象''' return { 'name': '', 'age': 0 } default_dict = defaultdict(person) default_dict['p'] pass
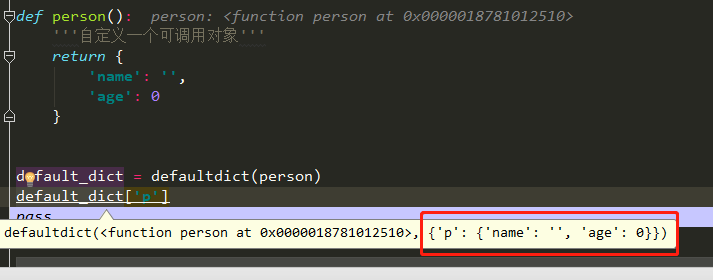
是不是很赞....
日拱一卒无有尽,功不唐捐终入海
