

01-Spark的功能及特点
-
定义:基于内存式计算的分布式的统一化的数据分析引擎
-
功能:多语言数据分析引擎工具栈
- 实现离线数据批处理:类似于MapReduce、Pandas,写代码做处理
- 实现交互式即时数据查询:类似于Hive、Presto、Impala,使用SQL做即席查询分析
- 实现实时数据处理:类似于Storm、Flink实现分布式的实时计算
- 实现机器学习的开发:代替传统一些机器学习工具
-
场景:所有需要对数据进行分布式的查询、计算、机器学习都可以使用Spark来完成
-
模块:类似于Hadoop中有HDFS、YARN、MapReduce几个模块
- Spark Core:Spark核心模块,其他模块都是基于这个模块构建的,基于代码编程的模块
- Spark SQL:基于SparkCore之上构建的SQL模块,用于实现结构化数据处理,基于SQL或者DSL进行编程
- Spark Streaming:基于SparkCore之上构建的准实时计算的模块,用离线批处理来模拟实时计算,代码编程
- Struct Streaming:基于SparkSQL之上的真正的实时计算的模块,基于SQL或者DSL进行编程
- MLlib:提供的机器学习的算法库,主要偏向于推荐系统的算法库
- Graphx:图计算的模块
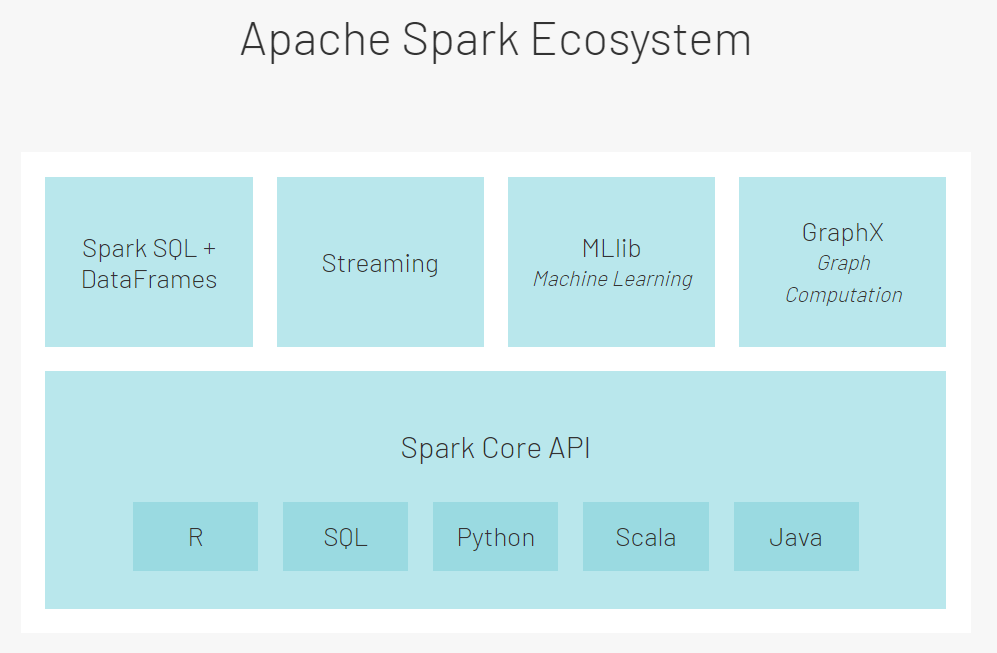
开发语言:Python、SQL、Scala、Java、R
-
Spark是用什么语言开发的:Scala语言开发的
-
- Batch/Streaming data:统一化离线计算和实时计算开发方式,支持多种开发语言
- SQL analytics:通用的SQL分析快速构建分析报表,运行速度快于大多数数仓计算引擎
- Data science at scale:大规模的数据科学引擎,支持PB级别的数据进行探索性数据分析,不需要使用采样
- Machine learning:可以支持在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到数千台机器的集群上
-
整体:功能全面、性能前列、开发接口多样化、学习成本和开发成本比较低


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构